人工智能、机器学习和深度学习的区别?
作为一个大数据从业人员,相信大家整天都在被AI、机器学习、深度学习等一些概念轰炸。有时候甚至有点诚惶诚恐,一方面作为一个“业内人士”而自豪,二方面觉得新概念一个接一个,自己不甚了解,有点恐惧。现在就来拆解一下这三个名词:
人工智能(Artificial Intelligence)
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门技术科学。“人工智能”是“一门技术科学”,它研究与开发的对象是“理论、技术及应用系统”,研究的目的是为了“模拟、延伸和扩展人的智能”。我们现在看到的貌似很高端的技术,如图像识别、NLP,其实依然没有脱离这个范围,就是“模拟人在看图方面的智能”和“模拟人在听话方面的智能”,本质上和“模拟人在计算方面的智能”没啥两样,虽然难度有高低,但目的是一样的——模拟、延伸和扩展人的智能。另外,人工智能在50年代就提出了。
机器学习
随着人对计算机科学的期望越来越高,要求它解决的问题越来越复杂,已经远远不能满足人们的诉求了。于是有人提出了一个新的思路——能否不为难码农,让机器自己去学习呢?
机器学习就是用算法解析数据,不断学习,对世界中发生的事做出判断和预测的一项技术。研究人员不会亲手编写软件、确定特殊指令集、然后让程序完成特殊任务;相反,研究人员会用大量数据和算法“训练”机器,让机器学会如何执行任务。这里有三个重要的信息:1、“机器学习”是“模拟、延伸和扩展人的智能”的一条路径,所以是人工智能的一个子集;2、“机器学习”是要基于大量数据的,也就是说它的“智能”是用大量数据喂出来的;3、正是因为要处理海量数据,所以大数据技术尤为重要;“机器学习”只是大数据技术上的一个应用。常用的10大机器学习算法有:决策树、随机森林、逻辑回归、SVM、朴素贝叶斯、K最近邻算法、K均值算法、Adaboost算法、神经网络、马尔科夫。
深度学习
相较而言,深度学习是一个比较新的概念,严格地说是2006年提出的。深度学习是用于建立、模拟人脑进行分析学习的神经网络,并模仿人脑的机制来解释数据的一种机器学习技术。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。最显著的应用是计算机视觉和自然语言处理(NLP)领域。显然,“深度学习”是与机器学习中的“神经网络”是强相关,“神经网络”也是其主要的算法和手段;或者我们可以将“深度学习”称之为“改良版的神经网络”算法。深度学习又分为卷积神经网络(Convolutional neural networks,简称CNN)和深度置信网(Deep Belief Nets,简称DBN)。其主要的思想就是模拟人的神经元,每个神经元接受到信息,处理完后传递给与之相邻的所有神经元即可。所以看起来的处理方式有点像下图(想深入了解的同学可以自行google)。
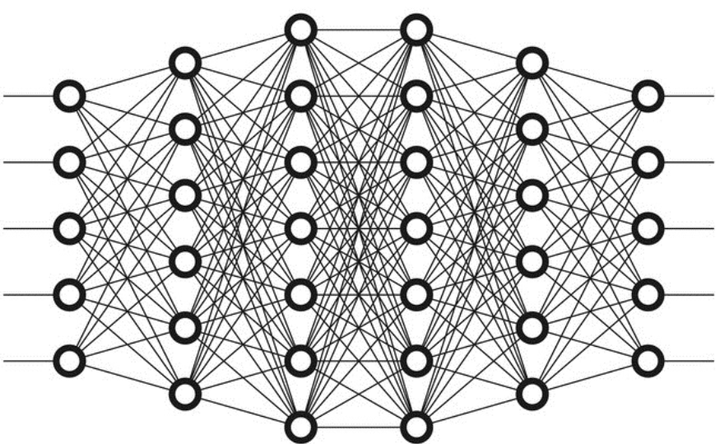
神经网络的计算量非常大,事实上在很长时间里由于基础设施技术的限制进展并不大。而GPU的出现让人看到了曙光,也造就了深度学习的蓬勃发展,“深度学习”才一下子火热起来。击败李世石的Alpha go即是深度学习的一个很好的示例。Google的TensorFlow是开源深度学习系统一个比较好的实现,支持CNN、RNN和LSTM算法,是目前在图像识别、自然语言处理方面最流行的深度神经网络模型。事实上,提出“深度学习”概念的Hinton教授加入了google,而Alpha go也是google家的。
总结:人工智能是一个很老的概念,机器学习是人工智能的一个子集,深度学习又是机器学习的一个子集。机器学习与深度学习都是需要大量数据来“喂”的,是大数据技术上的一个应用,同时深度学习还需要更高的运算能力支撑,如GPU。
书单推荐:
1.Deep Learning

这本书介绍很全面,由深度学习领域的专家撰写。被称为 AI 圣经,因为它将这个领域多年的研究汇集到一本书中。
如果你是一个有抱负的学生想要掌握深度学习并深入研究,或者你想教授深度学习课程,那么这本书肯定会对你有帮助。这本书可能是目前关于深度学习最全面的图书。
2.Deep Learning: A Practitioner's Approach

本书使用了 DL4J 这个 Java 库来训练和实现深度神经网络。针对初学者,如果你在 Java 或深度学习领域已经很有经验,可以直接去看它的例子。如果你没有深度学习的经验,但有很好的 Java 基础,建议你逐页阅读本书。如果你不了解 Java,则需要先去入门 Java。
通过阅读这本书,你将大致了解机器学习,特别是深度学习的基本概念。你将了解深度神经网络是如何从基本的神经网络演化而来。了解一些深度网络的架构,例如卷积神经网络(CNN)和循环神经网络(RNN)。
3.深度学习入门:基于 Python 的理论与实现

本书是深度学习真正意义上的入门书,深入浅出地剖析了深度学习的原理和相关技术。书中使用 Python3,尽量不依赖外部库或工具,从基本的数学知识出发,带领读者从零创建一个经典的深度学习网络,使读者在此过程中逐步理解深度学习。
4.模式识别与机器学习

作者是 Christopher M. Bishop。本书提出了近似推理算法和用于描述概率分布的图模型等多种最新分类方法。在阅读本书之前,最好有多变量微积分和基本线性代数等数理基础,面向人群为高年级本科生、研究生和相关研究人员。
人工智能、机器学习、神经网络、深度学习之间是包含的关系。
「神经网络」是人工智能领域「机器学习」一部分,在今天就是「深度学习」的意思。
就好像我们人体的神经元、神经系统一样。人工智能的「神经网络」就是由一个个「神经元」搭建的系统,多层的「神经网络」就叫做「深度学习」。「神经网络」需要通过大量的数据提取相关性来进行「学习」。
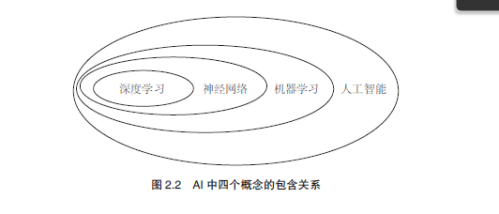
人工智能是最大的一个圈,它除了包含机器学习,还包含非机器学习。
什么是非机器学习? 就是人教机器学。过去叫专家系统。举个例子,如果我们做自动驾驶,就把人类驾驶经验全部总结出来:红灯停,绿灯走,等等, 然后一一输入到电脑里,结果就是告诉机器,「如果遇到这种情况,则那样处理」。但问题是我们驾驶遇到的情况多到根本无法穷尽,这条路最终证明走不通,所以专家系统在 80 年代热了一阵就冷下去了。
而现在人工智能的主流,是机器学习,它的特点就是把历史数据「喂」给机器,机器从数据中自己找规律。机器学习有五大流派,神经网络是其中的一个流派。这是现今最火的一个学派。人学习知识是通过神经元的连接,科学家通过模仿人脑机理发明了人工神经元。技术的进一步发展,多层神经元的连接,就形成了神经网络。
那么神经网络是怎么搭建起来的呢?
神经元是构建神经网络的最基本单位, 这张图就是一个人工神经元的原理图,非常简单,一个神经元由一个加法器和一个门限器组成。
加法器有一些输入,代表从其他神经元来的信号,这些信号分别被乘上一个系数后在加法器里相加,如果相加的结果大于某个值,就「激活」这个神经元,接通到下个神经元,否则就不激活。
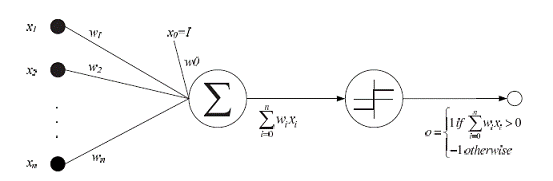
原理就这么简单,做起来也很简单。今天所有的神经网络的基本单元都是这个。
输入信号乘上的系数,我们也叫「权重」,就是网络的参数,玩神经网路就是调整权重,让它做你想让它做的事。
一个神经元只能识别一个东西,比如,当你训练给感知器会「认」数字「8」,你给它看任何一个数字,它就会告诉你,这是「8」还不是「8」。
为了让机器识别更多更复杂的图像,我们就需要用更多的神经元。人的大脑由 1000 亿个神经元构成,人脑神经元组成了一个很复杂的三维立体结构, 这么复杂的连接在芯片上做不出来。所以只能简化, 三维太复杂,我们就只能两维,神经元不能到处去连接,我们把它们分层,只允许每一层的神经元连接下一层的。
最初科学家只做出了单层的神经网络,后来做出了双层。而多层神经网络的突破发生在 2012 年,在每年一次的图像识别大赛 Image Net 比赛中,多伦多大学的杰弗里·辛顿(Geoffrey Hinton)教授, 就是 2019 年图灵奖的获得者之一,和他的博士生阿列克斯·克里杰夫斯基(Alex Krizhevsky)使用神经网络的机器学习,令图像识别的准确率大幅突破了原先人们认为的极限。
我们来看,这个博士生阿列克斯用的 AlexNet 的神经网络有 5 层,而三年后微软研究院的 Resnet 神经网络到了 152 层。层数越越多就能学会认越复杂的图形,比如人脸、X-光片子等。所谓神经网络就是像这张图,把很多神经元一层层连接起来。多层的神经网络,我们就它叫深度学习。
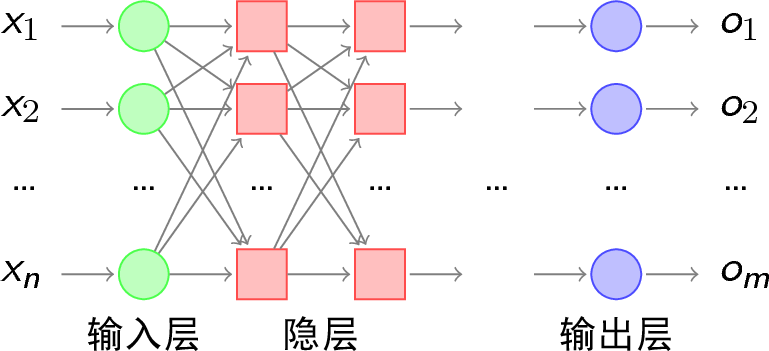
所以人工智能、机器学习、神经网络、深度学习是逐次包含的关系。但今天大家用这四个词的时候,大多数情况下说的是一回事,就是神经网络或深度学习。我们甚至可以说,这几年人工智能的大爆发,其实是神经网络的大爆发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号