

所谓算法——就是要比别人观察的更多。
算法是一步一步来的,不是说你一开始就必须想到正确的算法,而是想到一个大概的方向,然后慢慢优化,慢慢朝正确答案靠拢。
就拿整数划分这道题来举例。
题意:
任何一个大于1的自然数n,总可以拆分成若干个小于n的自然数之和。 当n=7共14种拆分方法:
7=1+1+1+1+1+1+1
7=1+1+1+1+1+2
7=1+1+1+1+3
7=1+1+1+2+2
7=1+1+1+4
7=1+1+2+3
7=1+1+5
7=1+2+2+2
7=1+2+4
7=1+3+3
7=1+6
7=2+2+3
7=2+5
7=3+4
这道题一开始我想到的只是递归,从7开始,枚举1~7的所有自然数,比如一开始枚举1,然后算出7-1=6,又将6加入到递归之中……不断重复上述过程。
然后就可以得到:
可以看到第二个和第三个是重复的……我要怎么解决那些重复的元素呢?
首先我第一个想到的办法是用一个二维数组vis[i][j]来记录每一条7=x+x+……+x之中所有自然数出现的次数,其中i代表那个自然数,j代表第几条数据,比如第一条vis[1][1]=7,第二条vis[1][2]=5,vis[2][2]=1。
然后对于当前的那一条数据,遍历之前所有的数据,发现一模一样的就不输出。
比如说:vis[1~7][2] = 5 1 0 0 0 0 0
vis[1~7][3] = 5 1 0 0 0 0 0
他们两个是一样的,所以第三条就不用输出。
然后——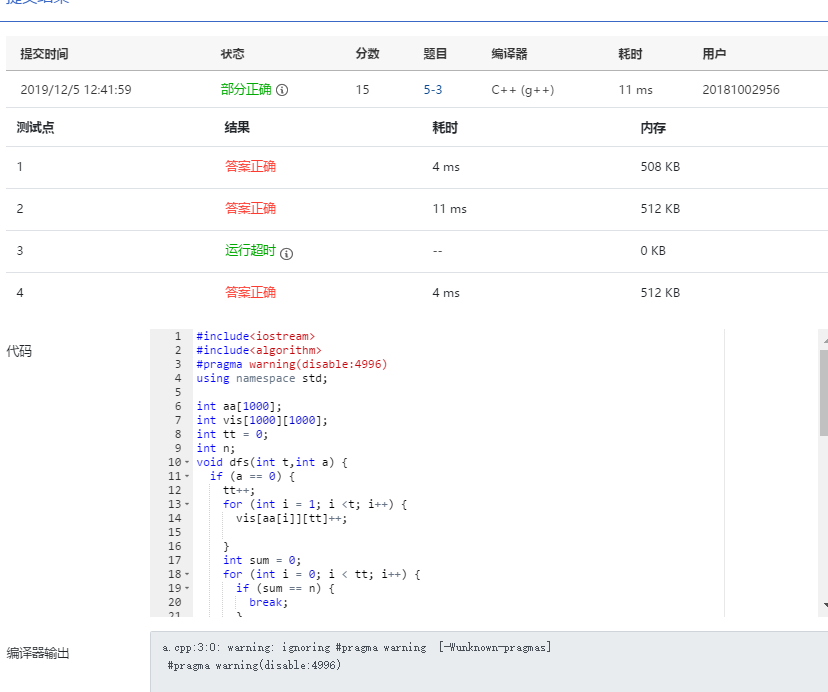
就超时了。
后面我就没有思路了。
直到看了某个人的博客。
他说——
对于每一组数据,都要保证后面的数字比前面的大(避免重复)。
然后我就醒悟了。
我突然觉得:“卧槽,我怎么那么蠢!”
(也就是说,只要保证每一组数据都是递增的,就可以将重复的筛去了,不需要用到vis数组来记录。)
我就大概将一下修改代码的过程吧。
一开始我在循环那里加了一个判断,if(枚举到的i < 之前的那个数)break;
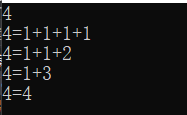
然后发现出问题了!!
我就将递归的每一次出现的pre输出看一下。

发现每次的pre其实都是当前的数字,并不是之前的数字。
我将pre和aa[t-1]比较了一下,发现他们两个是一样的。
也就是说,pre现在是当前的数据。
所以只要将pre真正改成前一个数据就好了。
为了防止溢出,我没敢用aa[t-2]和aa[t-1]比较。
还是用了pre,不过放进pre的数据变成了aa[t-1](一开始是i),然后就对了。
贴一下AC代码:
#include<iostream>
#include<algorithm>
#pragma warning(disable:4996)
using namespace std;
int aa[1000];
int n;
void dfs(int t, int a, int pre) {
if (pre > aa[t - 1]) return;
if (a == 0 && aa[1] != n) {//aa[1]!=n的判断是为了消去最后输出的7=7
printf("%d=", n);
for (int i = 1; i < t; i++) {
printf("%d", aa[i]);
if (i != t - 1) printf("+");
}
cout << endl;
}
for (int i = 1; i <= a; i++) {
int k = a - i;
if (k >= 0) {
aa[t] = i;
dfs(t + 1, k, aa[t - 1]);
}
}
}
int main() {
cin >> n;
dfs(1, n, 0);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号