C语言II博客作业01
1.作业头
| 这个作业属于哪个课程 | <https://edu.cnblogs.com/campus/zswxy/SE2020-2> | | ----------------- |--------------- | | 这个作业要求在哪里| <https://edu.cnblogs.com/campus/zswxy/SE2020-2/homework/11769> | | 这个作业的目标 | <了解文件的使用> | | 学号 | <20209127> |
一、本周教学内容&目标
第6章 回顾数据类型和表达式,第12章 文件
二、本周作业
2.1 题目:给定一个十进制正整数N,写下从1开始,到N的所有整数,然后数一下其中出现的所有“1”的个数。
例如:
N=2,写下1,2。这样只出现了1个”1“。
N=12,我们会写下1,2,3,4,5,6,7,8,9,10,11,12。这样,1的个数是5。
问题是:
1.写出一个函数f(N),返回1到N之间出现的”1“的个数,比如f(12)=5;
2.满足条件”f(N)=N“的最大的N是多少?
要求:
1.贴出代码图片,写出解题思路,列出测试数据(5分)
(1)代码如下:
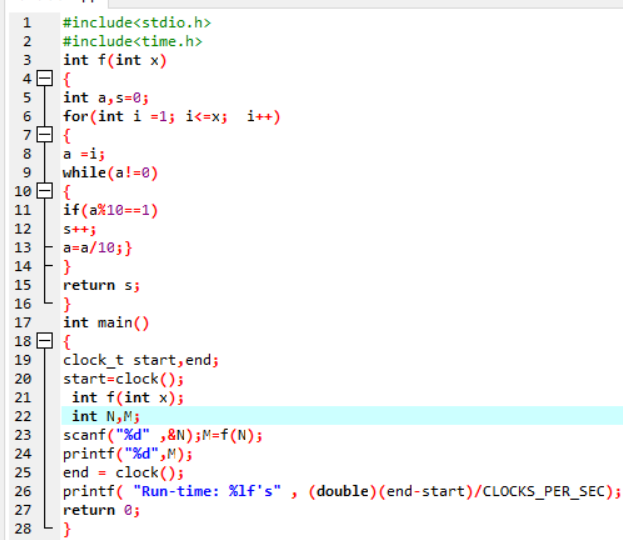
(2)解题思路:
1.首先看了看题目,是要写出一个函数来求1的个数,既然是要写函数,那么联系所学函数知识那一章,首先想到的就是先要自定义一个函数再来调用它计算并反馈出结果。稍微看了看后面的题目,所以就先放弃定义浮点型变量,因为要留有改进空间。使用for循环做一个数数器,在其中增加while循环,用取余的方法使得一个数的每一位都会被判断是否满足条件,如果满足条件那么最终结果会加1,不满足条件最终结果不会加1,一直到数数器数到最后一位,以此循环。
(3)测试数据![]()
![]()
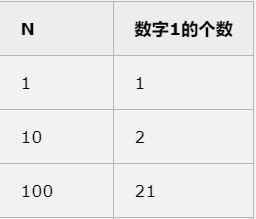
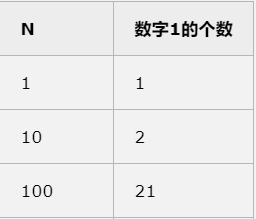
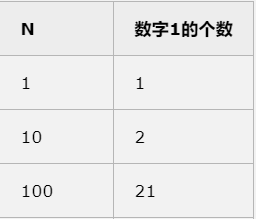
2.给出不同测试数据的运算时间,如果你的运算时间不变,说明你的测试数据不够大

3.思考针对足够大的数据,如何减少运算时间,并给出在原有算法基础上的改进算法和改进思路。
针对足够大的数据,减少变量的定义,改变原来使用调用函数的方法,压缩代码尽量精简。
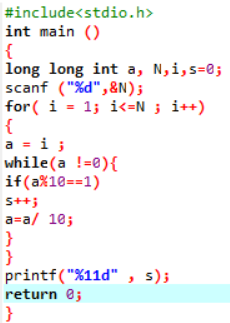
2.2 将上题中多组测试数据写入文件,并给出测试程序以检测你的代码有没有问题,贴出你的代码、运行结果和文件内容
 1.
1.

2.
3.

2.3 用自己的语言回答两个问题,并给出所查阅资料的引用
1.什么是文件缓冲系统?工作原理如何?
目前C 语言所使用的磁盘文件系统有两大类:一类称为缓冲文件系统,又称为标准文 件系统;另一类称为非缓冲文件系统。 缓冲文件系统的特点是:系统自动地在内存区为每一个正在使用的文件开辟一个缓冲 区。从磁盘向内存读入数据时,则一次从磁盘文件将一些数据输入到内存缓冲区(充满缓 冲区),然后再从缓冲区逐个地将数据送给接收变量;向磁盘文件输出数据时,先将数据 送到内存中的缓冲区,装满缓冲区后才一起送到磁盘去。用缓冲区可以一次读入一批数据, 或输出一批数据,而不是执行一次输入或输出函数就去访问一次磁盘,这样做的目的是减 少对磁盘的实际读写次数,因为每一次读写都要移动磁头并寻找磁道扇区,花费一定的时 间。缓冲区的大小由各个具体的C 版本确定,一般为512 字节。缓冲文件系统的读写
参考-百度问答
2.什么是文本文件和二进制文件?
二进制文件可以存放类型的变量,而文本文件只能存放字符变量。文本文件是给人看的,二进制文件是给机器看的。
参考-知乎
2.4 请给出本周学习总结
1 学习进度条
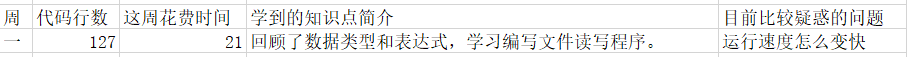
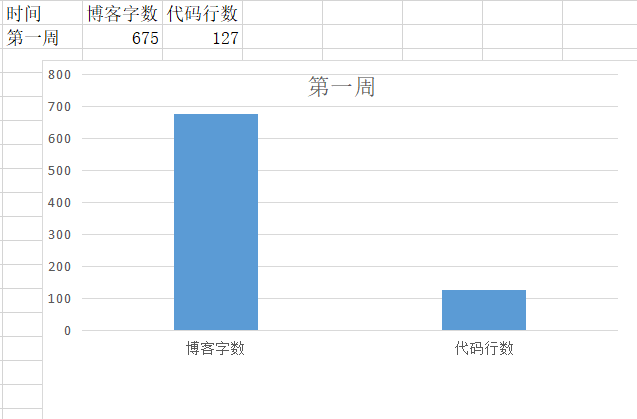
2 累积代码行和博客字数
3 学习内容总结和感悟


 浙公网安备 33010602011771号
浙公网安备 33010602011771号