
《The Google File System》 笔记
《The Google File System》 笔记
一、Introduction
- 错误是不可避免的,应当看做正常的部分而不是异常。因此需要设计持续监控,错误检查,容错,自动恢复的系统。
- 传统标准的文件是巨大的,GB以上都是正常的。当数据快速增长的时候,直接管理大文件是不明智的。因此需要重新考虑 assumptions 和 parameters 比如 I/O操作 和 块大小。
- 大部分文件的修改是新数据的追加而不是对已有数据的覆写
- 放宽GFS的一致性来简化文件系统,把追加操作变成原子性,防止并发问题。
二、设计概述
2.1 Assumptions 假设
- 便宜的商用设备,易发生故障
- 存储大文件,但是也要支持小文件
- 工作负载:流水读, 和随机读
- 工作负载: 大量的顺序写, 对文件的任意写操作也支持,但是可能不高效
- 支持多个客户端, 生产着消费者
- 大带宽比低通量重要
2.2 接口
- 文件通过文件夹组织,并且由路径名唯一定义
- snapshot(快照)、record append
2.3 架构
-
一个master 和 多个 chunkservers(块服务器)
-
chunk handle大小为 64 bit
-
chunk 在不同机器上有备份。默认为3个备份。
-
master保存所有文件系统的元数据, 包括 namespace(命名空间), 访问记录, 从文件到chunk的映射以及块的当前位置。
-
master控制chunk释放, 回收未分配的chunk, chunk迁移。
-
master周期性和chunkservers通信 通过 心跳信息, 来发送命令 以及 收集chunkservers的状态
-
client通过api和master 以及 chunkserver 通信
-
client 和 chunkserver 都不需要缓存数据,可以避免缓存一致性问题。但是 client缓存元数据, chunkserver不需要缓存数据的原因是,因为数据存在本地,linux缓存机制自动缓存了。

2.4 单一master
- client 不需要从master来 读数据
- client 从master知道chunkserver的位置信息, 然后从后者取数据
2.5 块大小(chunk size)
- 64MB
- chunk 副本存储为纯linux文件
- 采用懒空间分配,可以避免空间浪费(碎片)
large chunk size 好处:
- 减少client和master的交互
- 对一个特定的块更容易实现操作
- 减小存储在master上的元数据(可以将元数据存储在内存里)
坏处:
- 对于小文件, 热点数据。如果是序列化读文件不会出现这个问题, batch-queue系统会有。
- 可以通过存储更多的备份
- 长期解决方案是允许client直接从其他client读数据
2.6 元数据
master存了:
- file
- chunk namespaces
- 文件到chunks 的映射
- chunks 的位置(不持久化, 在master启动的时候询问chunkserver)
log(持久化, 并且有远程备份):
- namespaces
- 文件到chunks 的映射
2.6.1 内存数据结构
- master周期性扫描内存:chunk回收, 重新备份chunk, chunk 迁移
- 元数据收到master内存大小影响, 扩展性受影响
2.6.2 chunk 位置
- master在启动的时候询问chunkserver位置
- 在之后就是通过心跳来保证chunk 位置信息最新
2.6.4 操作日志
- 元数据的持久化
- 并发操作的时间线(file, chunk, 版本)
- log 在远程有备份
- master通过replay 操作日志
- checkpoints 被组织成b树,方便查找namespace
2.7 一致性模型
- GFS采用弱一致性模型提高性能
三、系统交互
3.1 leases 和 muitation order
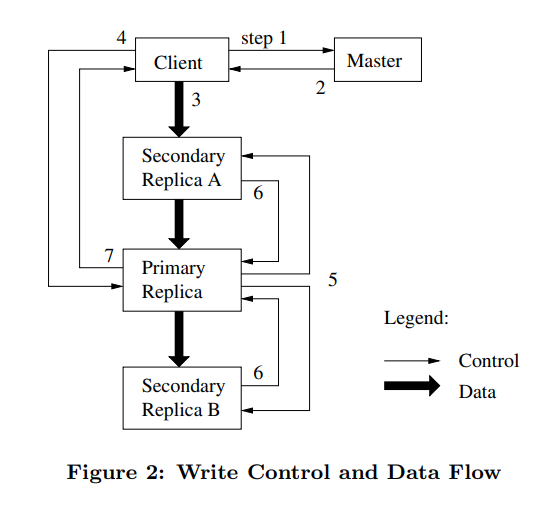
- 使用leases来维持mutation order 跨越备份
3.2 数据流
使用线性数据流, 充分利用网络带宽。而不是拓补结构。机器和最近的机器进行交换数据。
只要节点接收到数据就立即同步给其他节点。
3.3 原子性记录追加
- 在一般的工作负载里面, 我们采用多生产者/单消费者队列
- client先把数据发送到chunkservers, 然后primary(lease)检查记录的大小是否超过chunk size
- 一般记录追加的大小不超过1/4chunk size
3.4 snapshot
- 文件或者目录树的备份
- 使用copy-in-write 实现snapshot
- 撤销chunkserver 的租约
四、master操作
4.1 namespace 管理 和 锁
- master 执行namespace操作
- 管理chunk副本
- 使用lock来允许很多操作
- namespace 作为映射pathnames 到元数据的查找表
- 通过读写锁来维护namespace
4.2 备份的位置
- 最大化数据的可靠性和可用性
- 最大化带宽的使用
- 跨越机架备份
4.3 创建 重新复制 重新平衡
- 创建chunk:
- 磁盘利用率较低的机器已(平衡磁盘使用率)
- 限制最近creation的数量
- 跨越rack来分配chunk的备份
- 重新复制chunk:
- chunkserver不可用
- 通过阻塞客户端来提高重新复制chunk的优先级
- 复制的chunk原则:
- 平衡磁盘使用率
- 限制活动的克隆操作
- 跨rack
4.4 垃圾回收
- 当一个文件被删除的时候,GFS不能立即更新可用的物理空间。采用懒垃圾回收的策略,在这时才会更新。
- 删除文件, master 记录下删除操作。然后将文件重新命名为一个隐藏文件,包含了删除的时间戳。
- 当master定期扫描文件系统的时候, 删除这样命名的文件, 当文件真正被删除的时候, 元数据才会被删除。
- chunk server通过心跳机制报告master它的文件集合,然后master发送对比结果, master没有的文件集合,这样chunkserver就可以删除这些文件了。
4.5 陈旧的副本检测(stale replica detection)
- 当chunkserver错过了mutations, chunk replica 就会变成 stale。
- 对于每一个chunk, master维护了一个chunk version number,来区别最新的chunk
- master在垃圾回收的时候删除stale replica
- client 以及 chunkserver 在每次执行操作的时候都会验证版本
五、容错和诊断
-
高可用:
- 快速恢复: master 和chunkserver可以存储它们的状态, 重连服务器。
- 备份:
- 用户可以指定不同namespace的备份等级
-
master备份:
- log 和 checkpoints 在多台机器有备份
- mutation的状态只有当log持久化到本地和备份中才被认定成功
-
数据完整性:
- 使用校验和来检验存储的数据损坏
- chunkserver必须独立地校验数据完整性
- 每个chunk被分为64KB大小的blocks
- 每个chunk有32bit的校验和
- 如果发现校验和不匹配, master从其他备份里面克隆chunk, 然后删除本备份
-
诊断工具:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号