HBase之CF持久化系列(续3——完结篇)
相信大家在看了该系列的前两篇文章就已经对其中的持久化有比较深入的了解。相对而言,本节内容只是对前两节的一个巩固。与持久化相对应的是打开文件并将其内容读入到内存变量中。而在本节,我就来介绍这一点。
本节我从方法HStore.validateStoreFile开始分析。在本节的末尾,我将会为大家带来CF目录下某个文件的文件结构。也算是本系列的一个完整结尾。
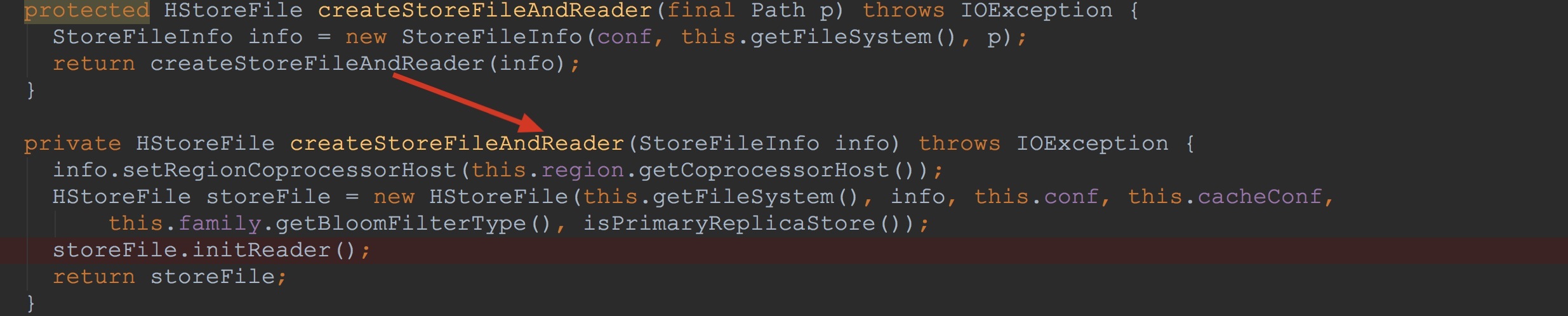
在该方法内部调用了方法createStoreFileAndReader。如下图所示。这里首先构造了StoreFileInfo。在构造StoreFileInfo时,由于我们这里的path既非HFileLink,亦非HStoreFile reference,仅仅是HFile,因此,其成员变量link与reference值都为null。
如下图所示。在构造了StoreFileInfo后,将其作为入参,调用了同名方法。
1.构造了HStoreFile,在构造HStoreFile中,入参有fileInfo
2.调用了storeFile.initReader,该方法比较复杂,也是本节的重点。我在后面将会详细介绍。![]() 下面,让我们来到HStoreFile.initReader。在该方法中仅仅调用了方法open。接着,在open方法内部,调用了fileInfo.open,这里的fileInfo实际类型为StoreFileInfo,也就是上图所介绍的。
下面,让我们来到HStoreFile.initReader。在该方法中仅仅调用了方法open。接着,在open方法内部,调用了fileInfo.open,这里的fileInfo实际类型为StoreFileInfo,也就是上图所介绍的。
 下面,让我们来到HStoreFile.initReader。在该方法中仅仅调用了方法open。接着,在open方法内部,调用了fileInfo.open,这里的fileInfo实际类型为StoreFileInfo,也就是上图所介绍的。
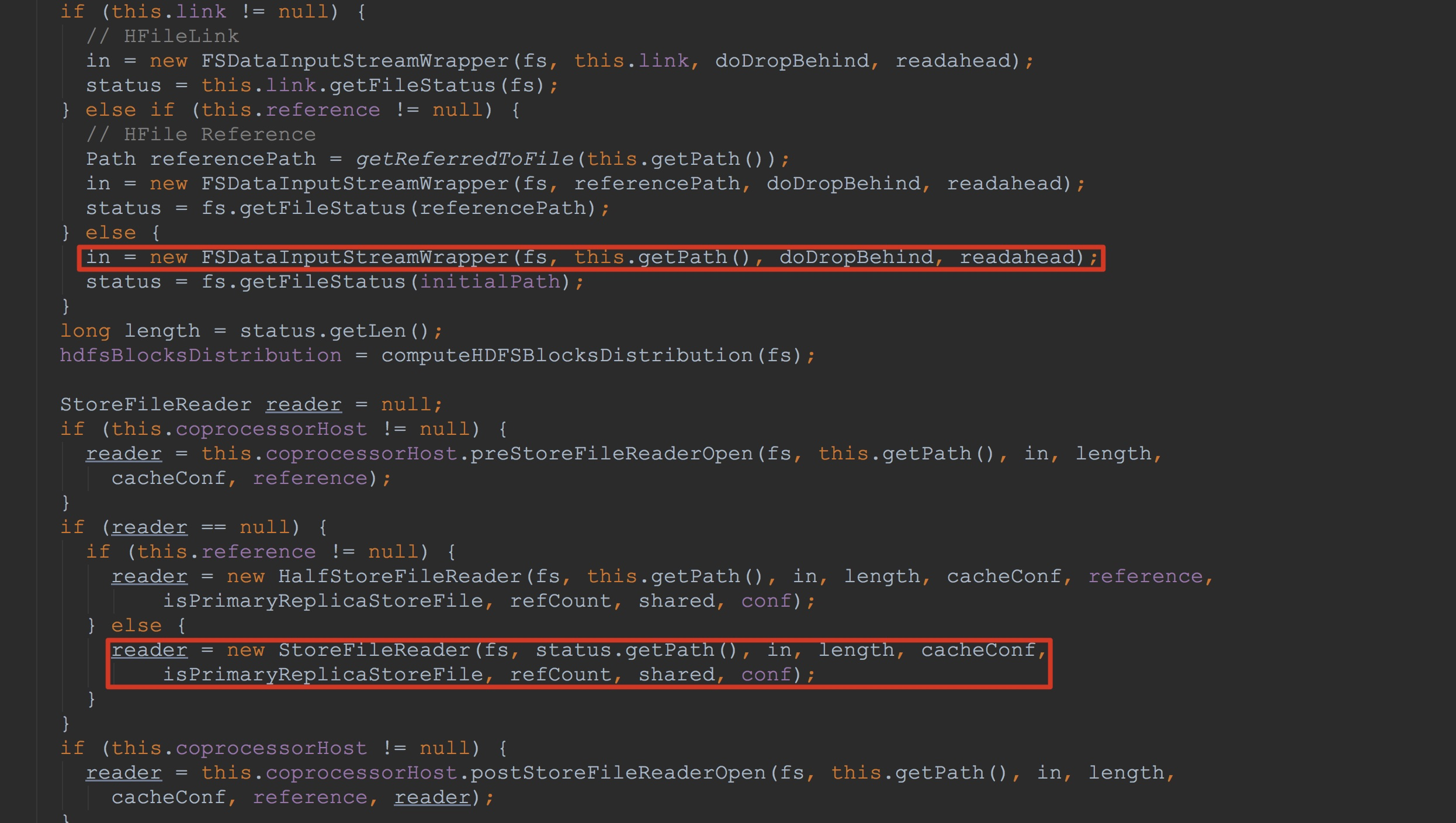
下面,让我们来到HStoreFile.initReader。在该方法中仅仅调用了方法open。接着,在open方法内部,调用了fileInfo.open,这里的fileInfo实际类型为StoreFileInfo,也就是上图所介绍的。 接下来让我们来到StoreFileInfo.open,该方法比较长,为了突出重点,我只将方法中比较重要的地方截图并做了简单标示。如下图所示。
1.这里构造FSDataInputStreamWrapper用来初始化变量in。在后面,我会简单介绍一下FSDataInputStreamWrapper的构造方法。
2.将初始化好的in作为入参用来构造StoreFileReader,并将其赋给变量reader,然后返回。这里是重点,我在后面会详细介绍。![]()
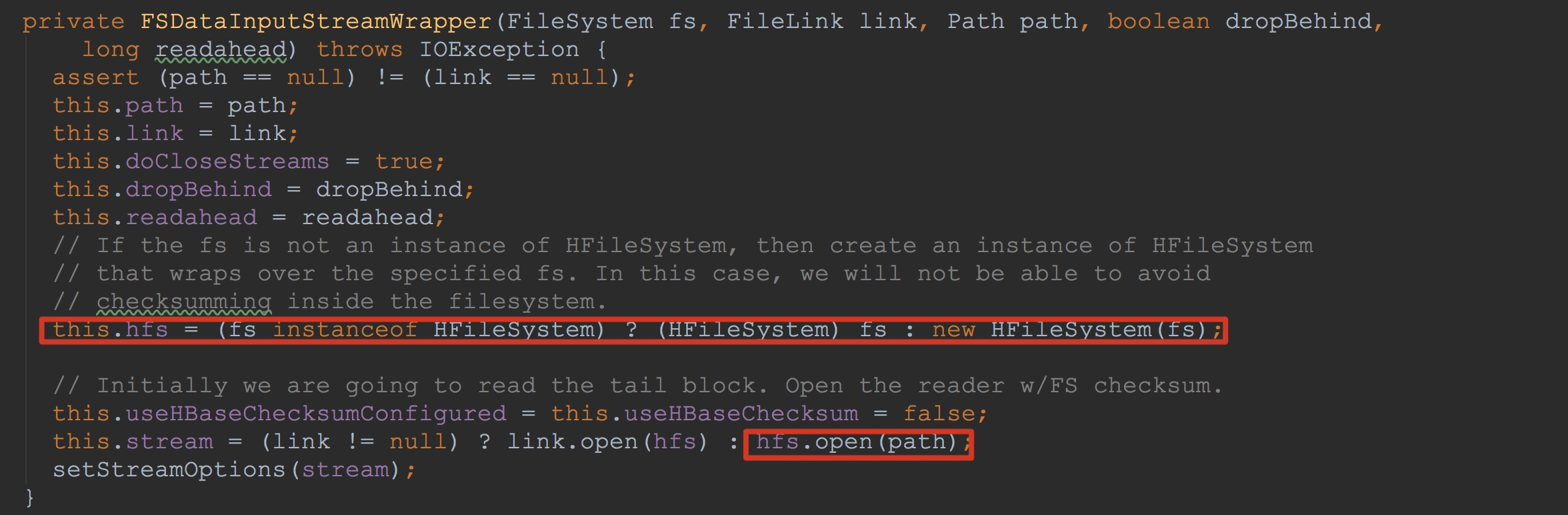
首先,让我们来到FSDataInputStreamWrapper的构造方法中。
1.这里首先判断入参fs类型是否为HFileSystem,如果不是,则使用HFileSystem将其封装并用来初始化成员变量hfs。
2.这里的入参link值为null,因此,其调用hfs.open,获得入参path的输入流。
也就是说,这里,我们已经拿到了指定文件的输入流,也就是我在上一节提到的持久化的文件。![]()
接下来让我们来到StoreFileReader的构造方法中。如下图所示,这里调用了HFile.createReader。该方法间接调用了方法openReader。![]()

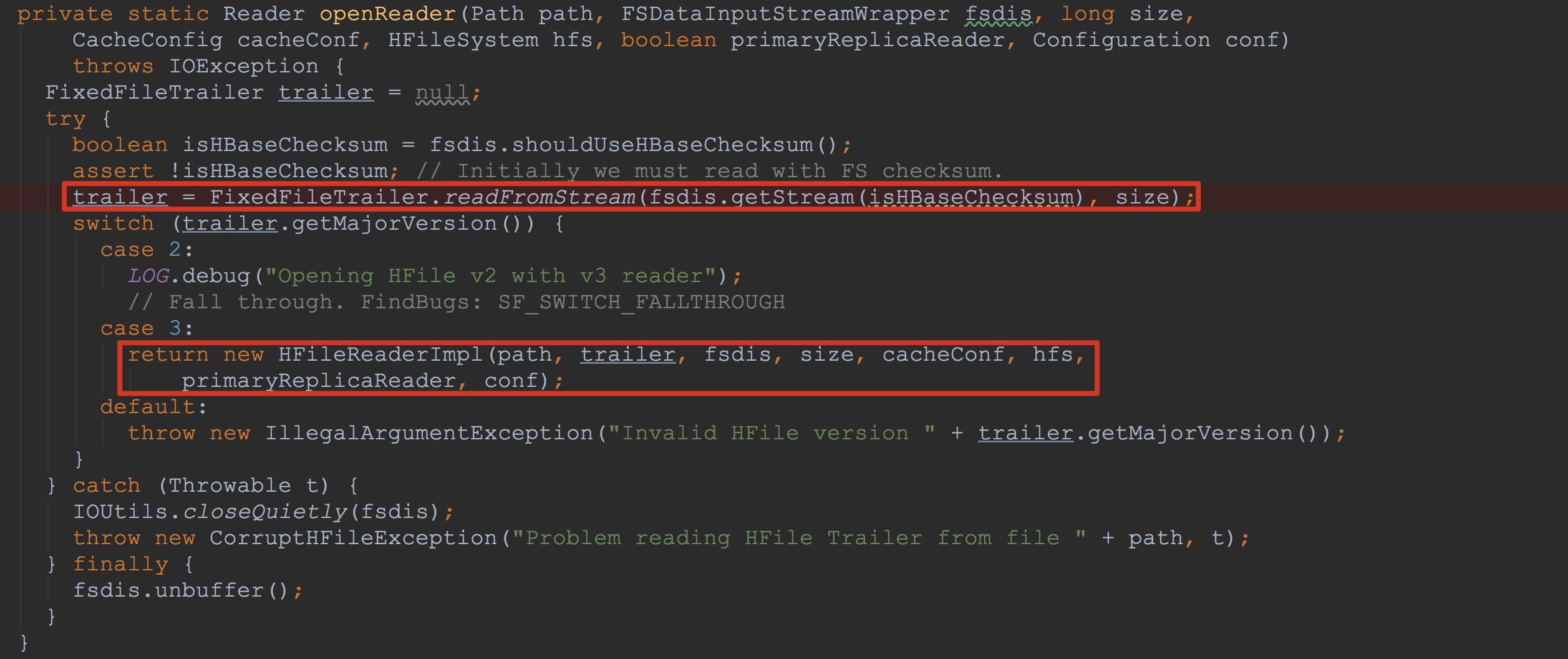
让我们来到方法openReader,如下图所示。
1.调用FixedFileTrailer.readFromStream。这里首先调用fsdis.getStream获得我们在上面打开的输入流。然后调用FixedFileTrailer.readFromStream,将输入流中的内容用来构造FFT,也就是FixedFileTrailer。该方法比较重要,我将在后面详细分析。
2.由于我这里使用的是3.0版本,因此,接下来构造了HFileReaderImpl。该方法将我在上一节提到的索引信息等等都用来初始化HFileReaderImpl的成员变量,也是我在本节主要讲解的内容。![]()
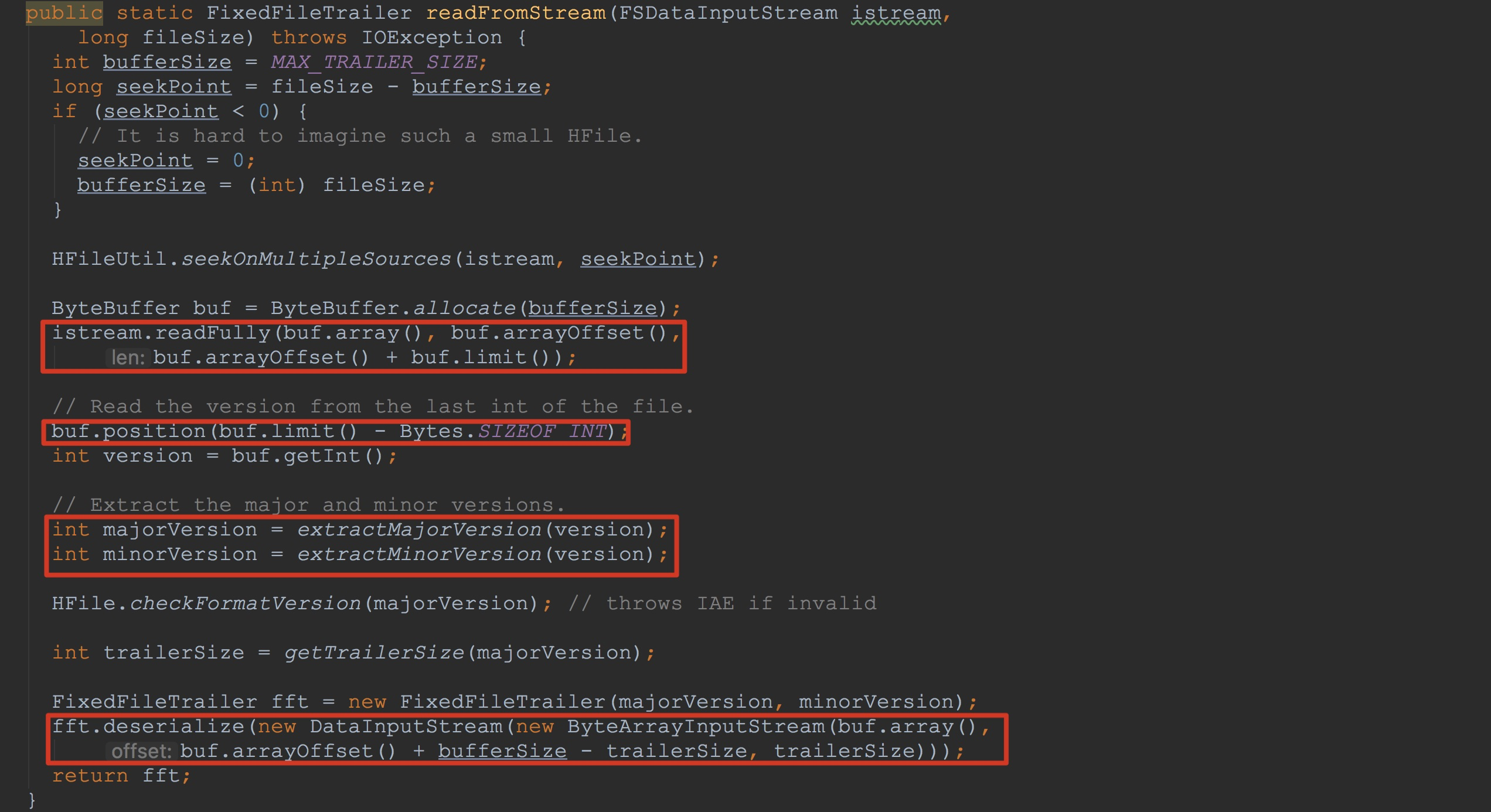
我们首先来到FixedFileTrailer.readFromStream,如下图所示。这里实现了将输入流中的信息用来构造FixedFileTrailer,作为本节的第一个内存化类型,还是值得详细了解的。
在介绍下图的标示之前,我先介绍一下FixedFileTrailer的功能,以便大家能够更好的理解后面的内容。其实根据其名称我们就可以猜个大概,FixedFileTrailer 也就是 fixed trailer of a file。就是文件中的固定长度的,用来存放文件基本元数据的信息。trailer硬译过来预告片的意思,这里我们可以理解为文件信息的预知。由于我这里是3.0的版本,这里的MAX_TRAILER_SIZE也就是固定长度4096。
1.通过公式seekPoint = fileSize - bufferSize,获得了文件中除去固定长度后的内容,也就是非FFT的长度。
2.调用HFileUtil.seekOnMultipleSources将istream中的pos指向seekPoint,也就是说,从这里开始读,读到的内容都持久化的FFT的信息。
3.分配空间,并且调用istream.readFully将其中的信息都写到刚刚分配的buf中。
4.调用buf.position,将其pos定位到最后四个字节,以便解析其majorVersion与minorVersion
5.将解析后的majorVersion与minorVersion用来构造FixedFileTrailer
6.调用fft.deserialize,解析buf中的内容,并且将其中的内容初始化FixedFileTrailer的成员变量。
这里大家可能对下面的一个公式比较模糊buf.arrayOffset() + bufferSize - trailerSize。由于我这是3.0的版本,我就当前版本为大家简单介绍一下。
从ByteBuffer.allocate的调用初始化buf,一直到后面fft.deserialize的调用,这里的buf.arrayOffset() 都没有改变,一直是0。另外,上面bufferSize初始化时为MAX_TRAILER_SIZE = 4096,而且通过调用getTrailerSize返回的trailerSize = 4096,所以,上面的公式其实为0。![]()
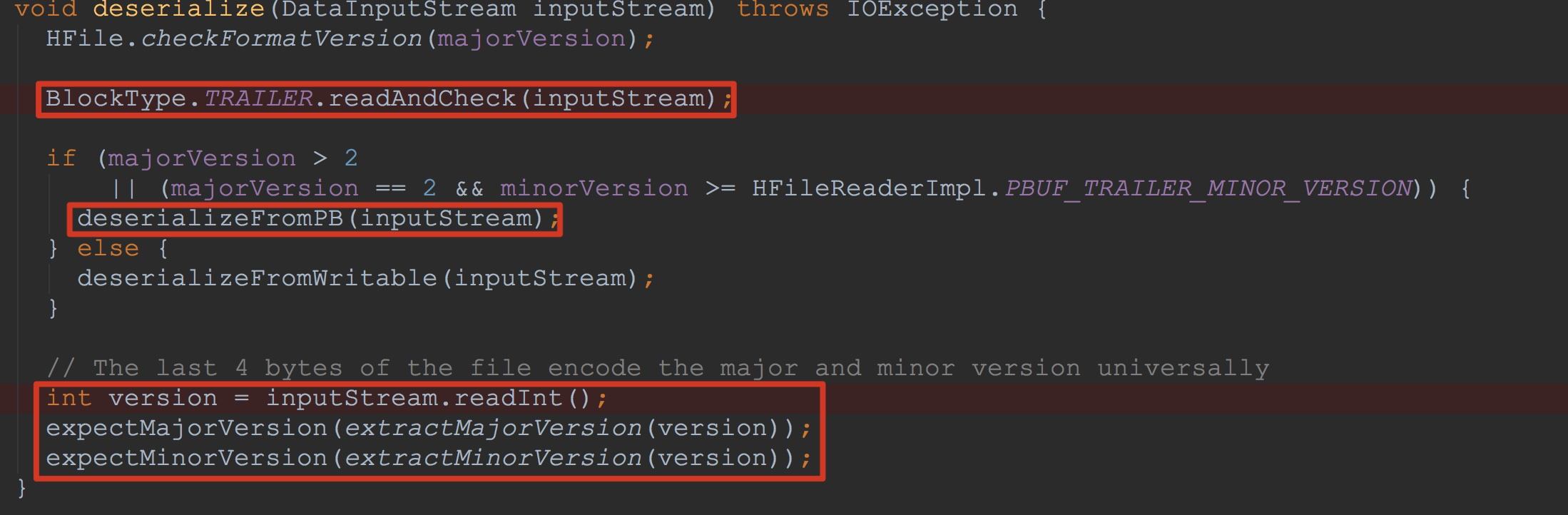
接下来,让我们来到FixedFileTrailer.deserialize,如下图所示。
1.调用BlockType.TRAILER.readAndCheck,将8个字节的magic值读入到8个字节的buf中,并进行校验
2.然后调用deserializeFromPB,将PB序列化后的信息反序列化,置于相应的成员变量中,并且,将输入流中的pos置于getTrailerSize() - NOT_PB_SIZE - size(这里我在上一节内容提到过,这一节就不赘述了)。
3.读取最后4个字节的version信息,并且进行校验对比。![]()
关于方法deserializeFromPB,虽然比较简单,不过,我在这里还是简单介绍一下。
1.首先,我们需要意识到,这里的入参inputStream在上面已经将magic信息读出,因此相比一开始,这里的inputStream.available少了8个字节
2.然后调用HFileProtos.FileTrailerProto.PARSER.parseDelimitedFrom将inputStream中的内容反序列化。
3.公式getTrailerSize() - NOT_PB_SIZE - size比较费解。我来为大家一一解析。首先getTrailerSize返回4096,然后NOT_PB_SIZE = 12,再然后size = 4096 - 8 - FileTrailerProto.size。首先,inputStream.pos = 8,start = 4096 - 8。然后调用方法HFileProtos.FileTrailerProto.PARSER后,inputStream.pos = 8 + FileTrailerProto.size,size = FileTrailerProto.size。
这里我们就可以得到pos + 4096 - 12 - FileTrailerProto.size = 8 + FileTrailerProto.size + 4096 - 12 - FileTrailerProto.size = 4096 - 12 + 8 = 4092。也就是说调用完方法inputStream.skip后,inputStrem.pos = 4092。这样,也就解释了上图中调用inputStream.readInt中,为什么读取到的是version。![]()

介绍完FFT,让我们来到构造方法HFileReaderImpl,这里是本节的重中之重,希望大家耐心看完。如下图所示。HFileReaderImpl的构造方法比较长,但是关键流程并不多,所以大家没有必要慌。
这里我就比较关键的调用做一个简介,关于其中比较重要的流程,我将在后面一一讲解。
1.调用HFileBlock.FSReaderImpl构造方法初始化成员变量fsBlockReader,需要注意的是,这里的入参有fsdis。这里将fsdis.stream关闭,重新打开流,并用来初始化其streamNoFsChecksum。这里我会在后面的流程中详细讲到。
2.分别初始化成员变量dataBlockIndexReader与metaBlockIndexReader,这里只是调用了其构造方法,并没有对其中的成员变量进行初始化。
3.调用fsBlockReader.blockRange构造了用于迭代获取信息的HFileBlock.BlockIterator,方便后面从流中获取信息。
4.调用blockIter.nextBlockWithBlockType将从文件中读取到的信息封装到HFileBlock,然后调用dataBlockIndexReader.readMultiLevelIndexRoot将其中的信息读取出来用于初始化其成员变量。
5.调用metaBlockIndexReader.readRootIndex,与上面的处理流程类似。
6.调用fileInfo.read将文件中的信息用来初始化fileInfo的成员变量![]()

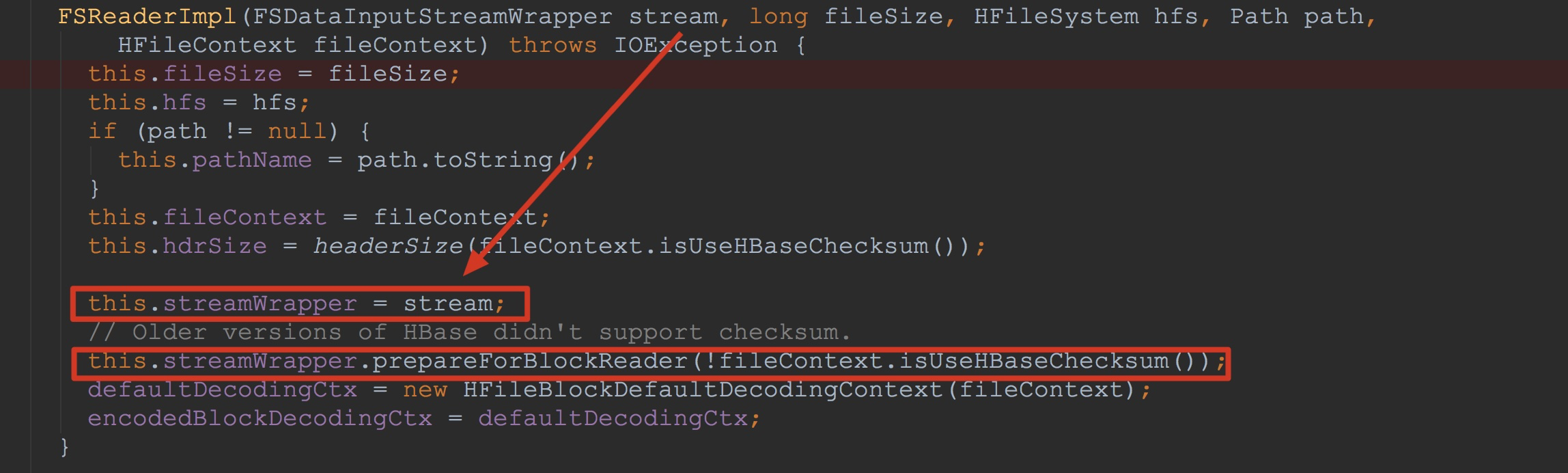
这里,我首先介绍HFileBlock.FSReaderImpl。首先让我们来到FSReaderImpl的构造方法中。这里我可能介绍的比较啰嗦,但为了讲解的尽可能清楚,还请大家谅解。如下图所示。
1.将入参stream赋给成员变量streamWrapper
2.调用streamWrapper.prepareForBlockReader,也就是FSDataInputStreamWrapper.prepareForBlockReader。![]()
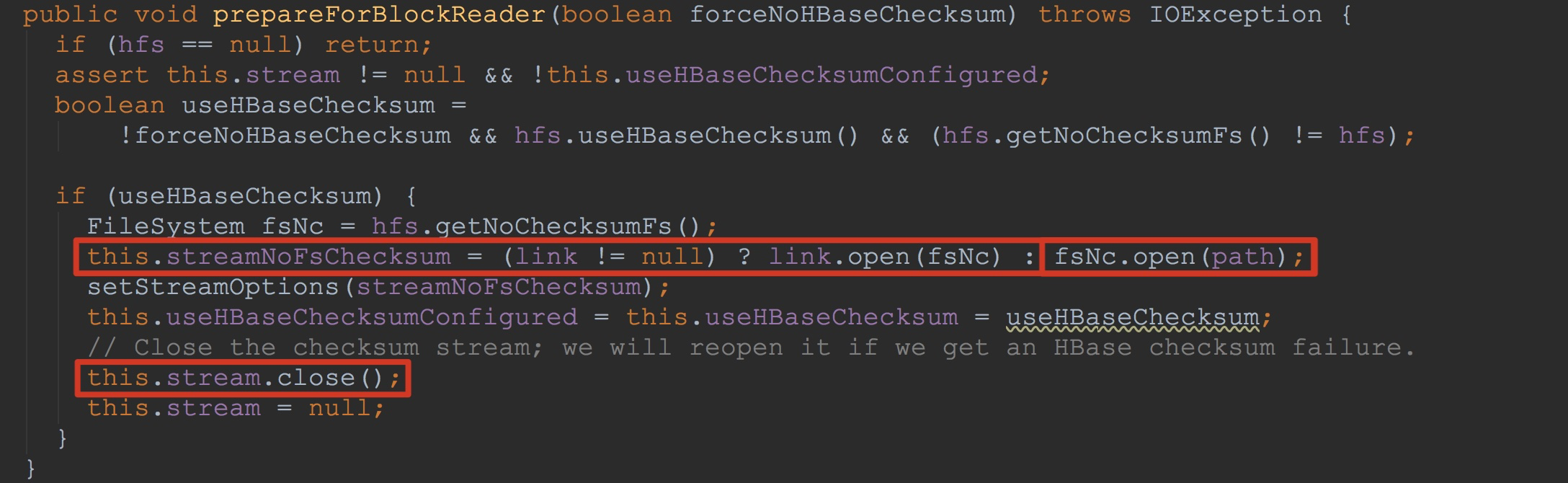
接下来,让我们来到FSDataInputStreamWrapper.prepareForBlockReader,如下图所示。我在下图做了两个标示。
1.调用fsNc.open,将文件重新打开,并赋给成员变量streamNoFsChecksum
2.将之前使用的stream流关闭。
也就是说,由于我们在这里不依赖hdfs的checksum,而依赖hbase自己计算填充的checksum,因此,其成员变量streamNoFsChecksum得以初始化。这里也就是说,从这里以后的流程所要调用的有stream更换为streamNoFsChecksum。![]()
接下来,让我们来看一下方法blockIter.nextBlockWithBlockType,也就是HFileBlock.BlockIterator.nextBlockWithBlockType。
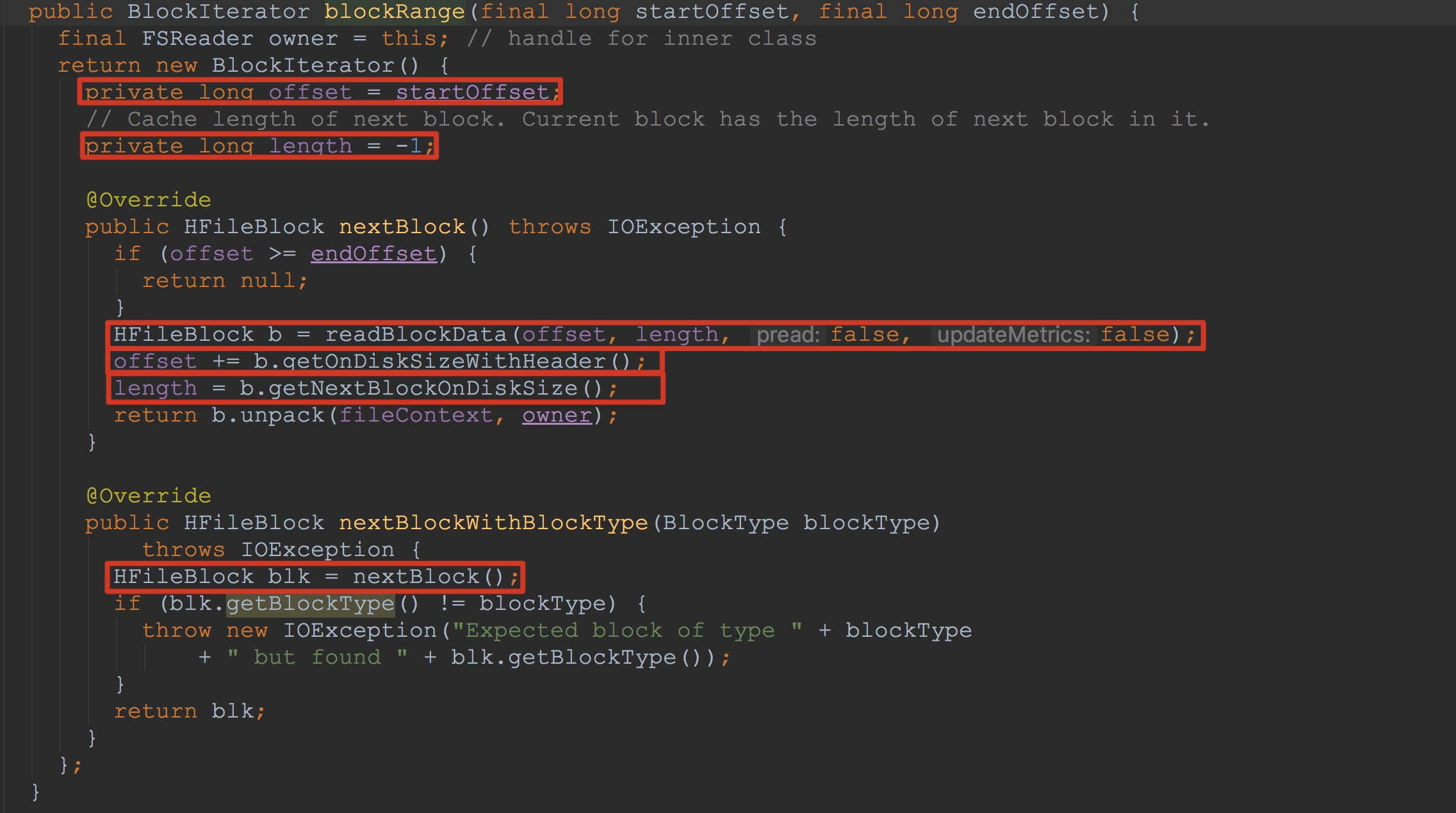
首先让我们来看一下方法fsBlockReader.blockRange。如下图所示。
1.这里将入参中的两个值都保存在了匿名类中。
2.方法nextBlockWithBlockType主要调用了方法nextBlock
3.方法nextBlock调用readBlockData从上面打开的输入流中读取数据并且将其封装到HFileBlock
4.记录偏移量与长度
然后,我们大概就明白了HFileBlock.BlockIterator.nextBlockWithBlockType的大致调用流程。虽然其关键方法readBlockData的调用我们还没有讲到。![]()
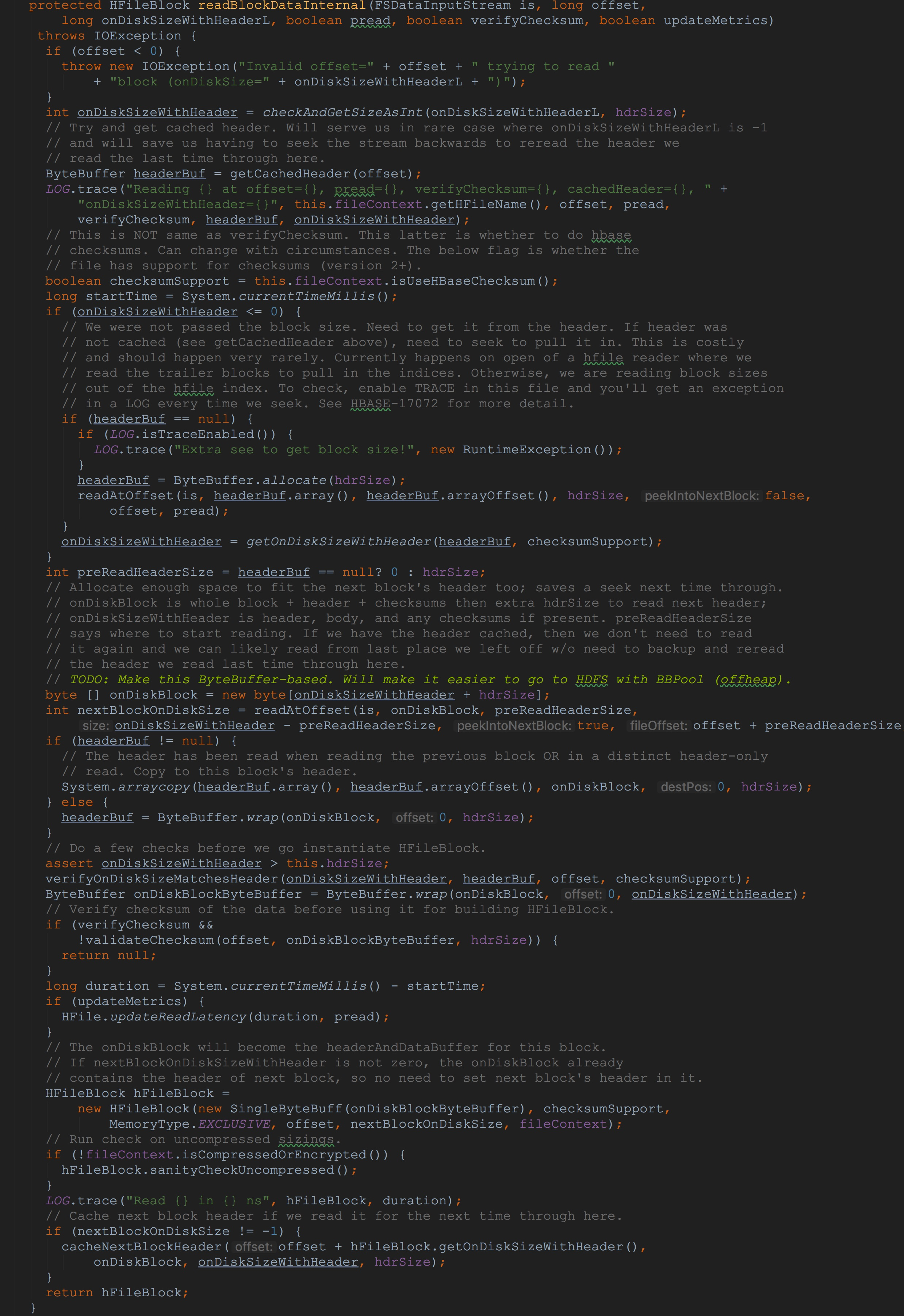
在方法readBlockData方法中,比较重要的只是调用了方法readBlockDataInternal,因此,我在这里就不贴方法readBlockData的图。而专注于本节中最为重要的方法readBlockDataInternal。大家看了该方法可能会被吓到,没有关系。我会为大家一一讲解。只要大家耐心看下去,就会发现,其内容并不难。
1.调用方法getCachedHeader。由于这里的是第一次调用,因此,这里返回的值为null。至于其中的流程,我会在后面为大家详细介绍。
2.在第一次调用的时候入参onDiskSizeWithHeaderL = -1。也就是说onDiskSizeWithHeader = -1。因此这里的判断onDiskSizeWithHeader <= 0 为true。其代码块中的逻辑也得以执行。
我在这里就其代码块中的逻辑简单描述一下,至于其中比较重要的方法,我将放在后面来讲解。
这里首先调用ByteBuffer.allocate分配了33个字节。因为默认情况下使用的是含checksum的header。
接下来调用readAtOffset。这里将入参is指定偏移量offset长度hdrSize写入到headerBuf.array中。
然后,调用getOnDiskSizeWithHeader获得当前要读取的块的大小,含header与checksum。
3.分配onDiskSizeWithHeader + hdrSize长度个字节用来存放当前block与下一个header,赋给变量onDiskBlock。
4.接着调用方法readAtOffset,这里是将当前block与下一个header写入到onDiskBlock,关于其入参,由于上面已经提到过,我这里就不再赘述了。这里的返回值为下一个block块所占用的大小。
5.然后调用System.arraycopy将我们第一次调用方法readAtOffset读到的信息写入到变量onDiskBlock中。
6.调用方法ByteBuffer.wrap将变量onDiskBlock中的信息封装为ByteBuffer类型。
7.将刚刚初始化的onDiskBlockByteBuffer作为入参,用来构造HFileBlock,最后用于返回。
8.调用cacheNextBlockHeader缓存下一个block的header。![]()
这里我们首先来介绍方法readAtOffset。如下图所示。这个方法比较长,我只截取其中比较关键的部分。
1.调用HFileUtil.seekOnMultipleSources,其内部调用了istream.seek将当前istream.pos值为入参fileOffset。
2.调用IOUtils.readFully将istream.pos起,长度为size的数据copy到dest中。
3.调用readWithExtra(该方法与上面的方法不会同时调用,我这里只是将二者放在了一起讲解)。
如果该方法将长度为size + hdrSize全部写入到了dest,则返回值为true。否则,返回false。
4.调用Bytes.toInt(dest, destOffset + size + BlockType.MAGIC_LENGTH) + hdrSize获取下一个block长度。![]()

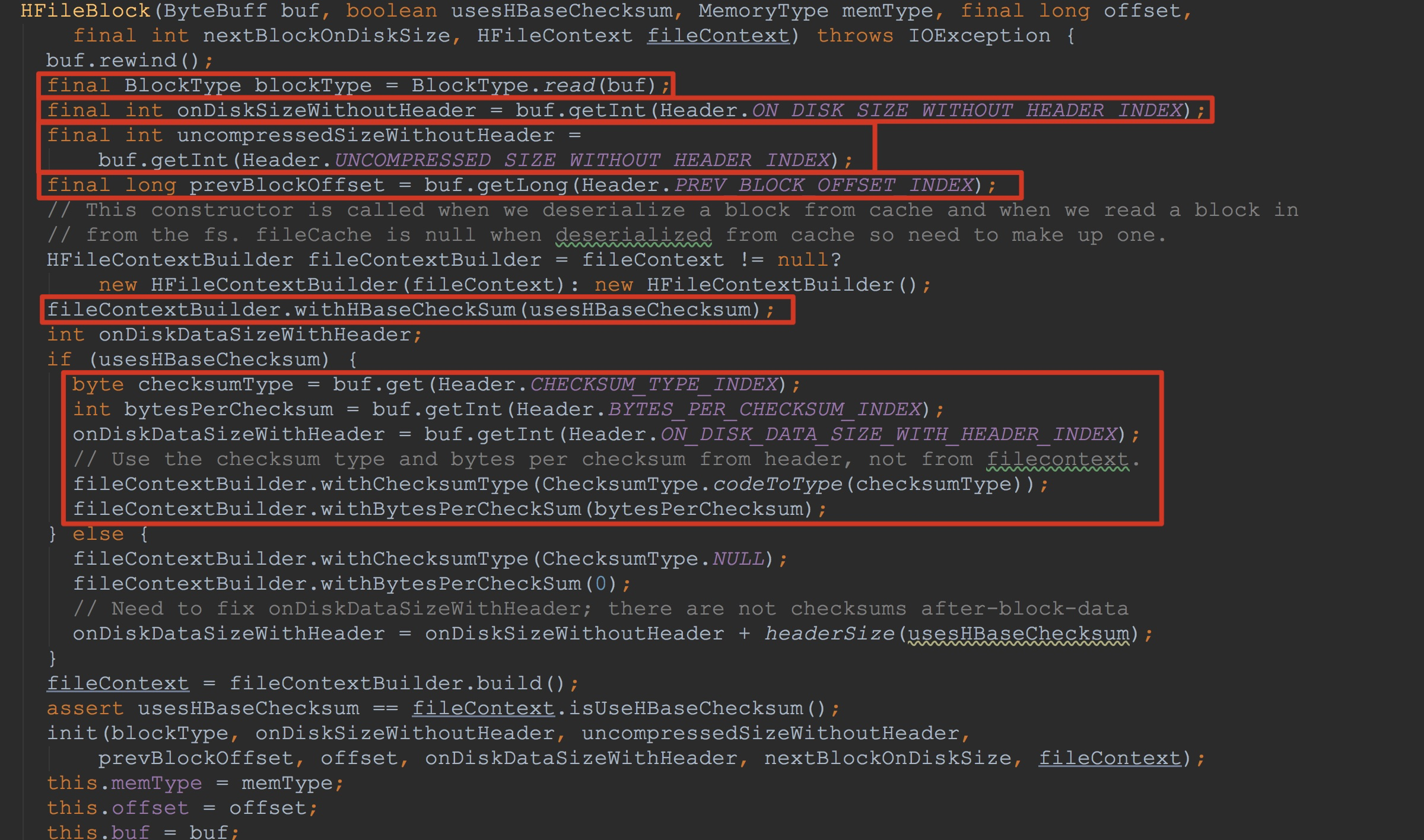
接下来让我们来到HFileBlock的构造方法中。这里虽然不是很难,却也是一个知识点。如下图所示。这里标示的东西比较多。大家看了这里的方法可能会比较懵逼,这里的Header中的各个静态量是什么意思。没有关系,让我们接着往下走。
这里,我们需要注意的是,其入参buf用于初始化其成员变量buf。![]()
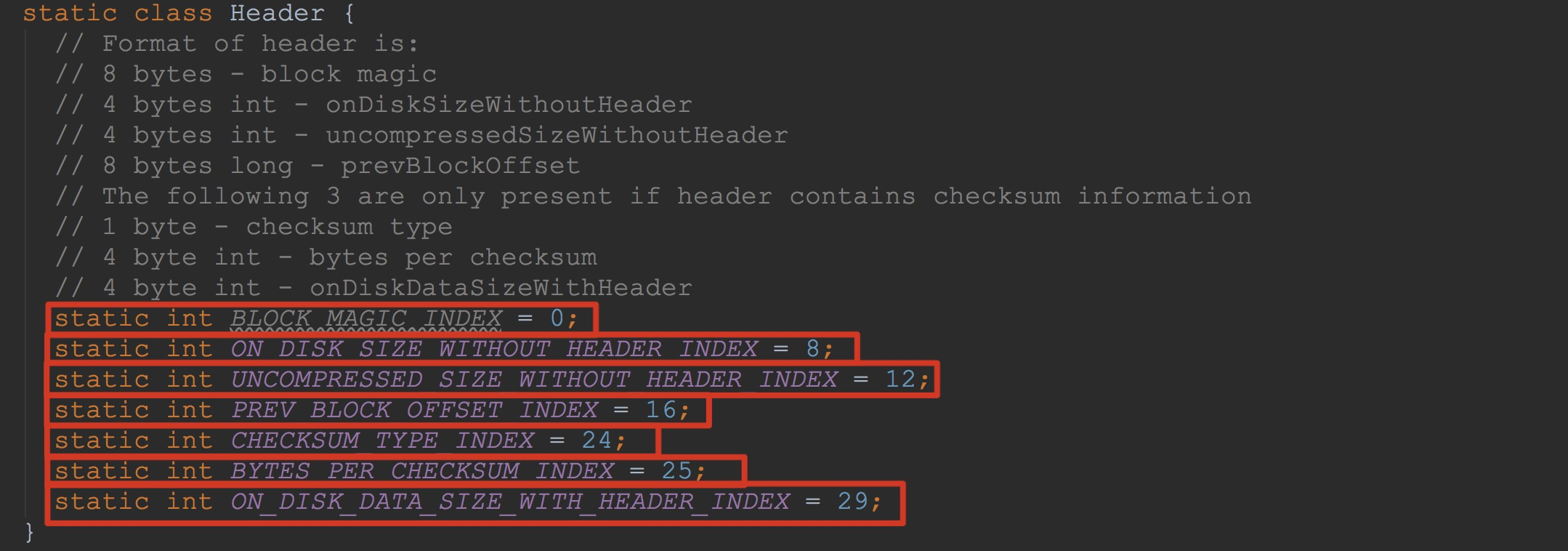
如下图所示,这里是Header中的各个静态量。这里中也有注释。不过,我还是再简单介绍一下。
1.首先是8个字节的MAGIC值,其实也就是枚举BlockType中的值。BlockType的每个枚举类型中的magic值都是8个字节。
2.接下来就是4个字节不含header的block大小,这里是block压缩后的大小。注意,这里包含checksum。
3.然后是4个字节的没有压缩后的大小。这里不包含header,也不包含checksum。
4.然后是8个字节相同类型的前一个block的偏移量。他主要用于导航到上一个块而无需转到块索引。
5.1个字节表示checksum type,其对应的类型为枚举ChecksumType
6.然后是4个字节每个校验和值的字节数
7.最后4个字节是包括header,但是不包含checksums的block大小。
相信有了这里的了解,大家就对于HFileBlock的构造方法就不再迷惑了。![]()
到此为止,相信大家对于HFileBlock.BlockIterator.nextBlockWithBlockType方法调用的流程已经有了一个清晰的了解。
接下来,我以dataBlockIndexReader.readMultiLevelIndexRoot为例,简单说明一下这里如何将入参HFileBlock用来初始化其中的成员变量。
在dataBlockIndexReader.readMultiLevelIndexRoot方法中,主要调用了方法readRootIndex。如下图所示。
1.调用blk.getByteStream,这里虽然不太复杂,但还是值得我简单讲解一下。
2.调用用来填充其成员变量。![]()

接下来,让我们首先来到方法HFileBlock.getByteStream。
1.调用buf.duplicate,这里buf的实际类型为SingleByteBuff,因此,其调用了SingleByteBuff.duplicate。
2.将返回的dup的pos定到33,也就是header后的第一个字节
3.将其中dup封装为DataInputStream并返回![]()

关于方法SingleByteBuff.duplicate的调用,我在这里简单截图说明一下。如下图所示。这里的buf类型为java.nio.ByteBuffer。调用其duplicate方法并将其封装为一个新的对象返回。![]()

然后,让我们来到方法readRootIndex,这里完成了root index的读取。相信看过上一篇博文《HBase之CF持久化系列(续2)》的大家应该能够理解这里的内容,因为当时写入的逻辑与现在读入的逻辑是一样的,我在这里就不赘述了。![]() 接下来,让我们来到方法fileInfo.read。如下图所示。
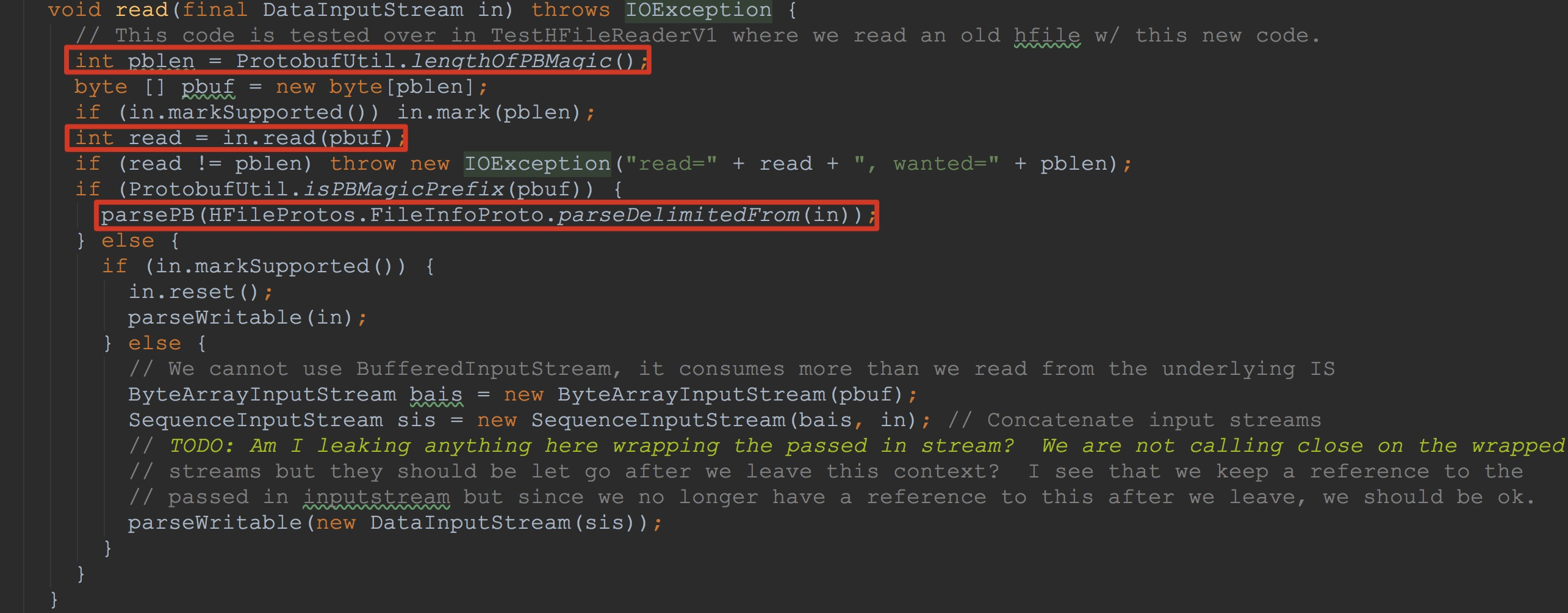
接下来,让我们来到方法fileInfo.read。如下图所示。
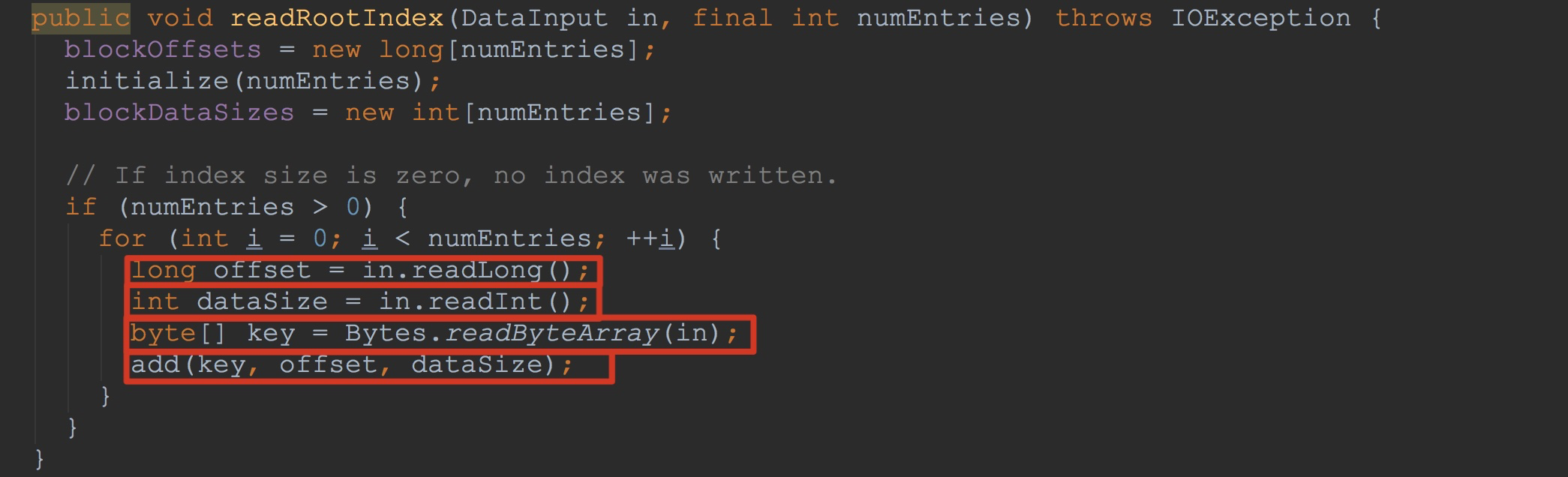 接下来,让我们来到方法fileInfo.read。如下图所示。
接下来,让我们来到方法fileInfo.read。如下图所示。 1.分配4个字节用来存放其magic值。这里的magic为PBUF
2.将输入流中的值写入到刚刚初始化的pbuf中
3.调用方法HFileProtos.FileInfoProto.parseDelimitedFrom将输入流中的信息反序列化
4.调用方法parsePB将其中的入参HFileProtos.FileInfoProto类型的值用来填充其成员变量map![]()
然后,就是loadOnOpenBlocks成员变量完成其值的添加了。这里只是调用了blockIter.nextBlock,该方法在上面已经介绍过,我在这里就不赘述了。
到此为止,本节的内容就介绍完了。
下面,我画一个图简单描述一下文件存放的各种信息。如果不对,还希望大家指正。![]()

到这里,该系列——CF持久化系列就画上了句号,希望大家喜欢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号