PY_RE(py字典)
题目:
start.py
import Test
Dict = {}
key = "A"
value = 26
for i in range(1, 27):
Dict.setdefault(key, value)
print(Dict)
key = chr(ord(key) + 1)
value = value - 1
print("===================Py_Reverse====================")
def main():
Input_Str = input("Please Input Str:\n")
Input_Str = list(Input_Str)
print(Input_Str)
Test.EnData1(Input_Str, Dict)
Test.Judge(Input_Str)
main()
test.py
def EnData1(Input_Str, Dict):
for i in range(int(len(Input_Str) / 2), len(Input_Str)):
for dict in Dict:
if Input_Str[i] == str(dict):
Input_Str[i] = Dict[dict]
# print(Input_Str)
break
def Judge(Input_Str):
FLAG = ["H", "E", "L", "L", "O", "_", "_", 11, 2, 7, 19, 12, 13]
if str(Input_Str) == str(FLAG):
print(str(Input_Str))
print(str(FLAG))
print("YES!")
else:
print(str(Input_Str))
print(str(FLAG))
print("NO!")
all_data = []
def EnData(Input_Str, Dict):
for i in range(int(len(Input_Str) / 2), len(Input_Str)):
flag = 0
for dict in Dict:
if Input_Str[i] == dict:
all_data.append(Dict[dict])
flag = 1
if flag == 0:
all_data.append(Input_Str[i])
思路:
分析EnData1,发现他把输入的数据的后半部分和字典的键作比较,并将对应的键的值赋予后半部分
类似于
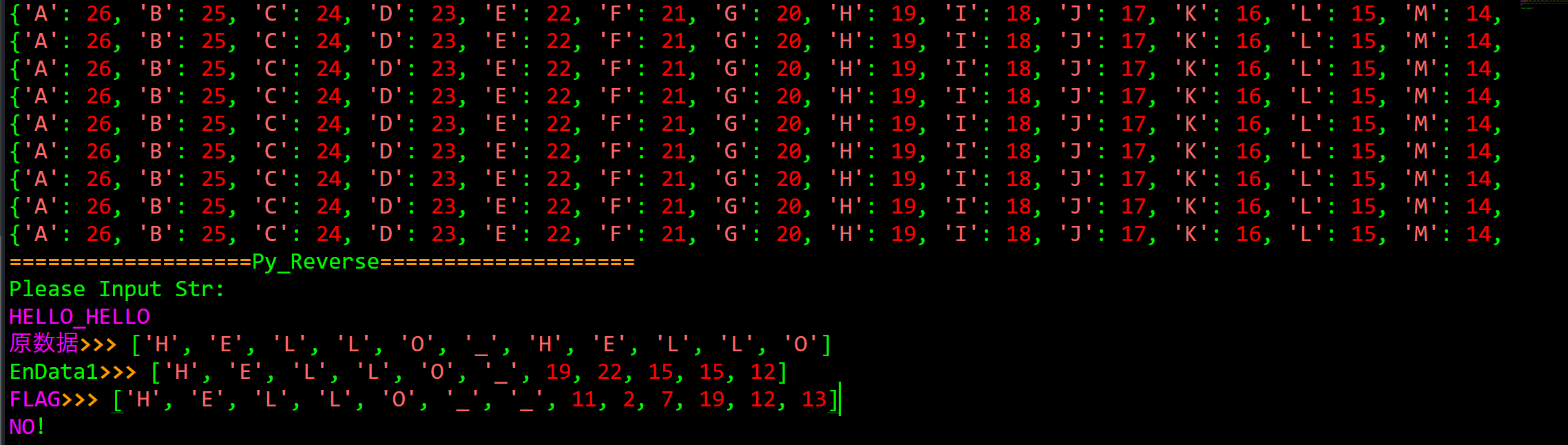
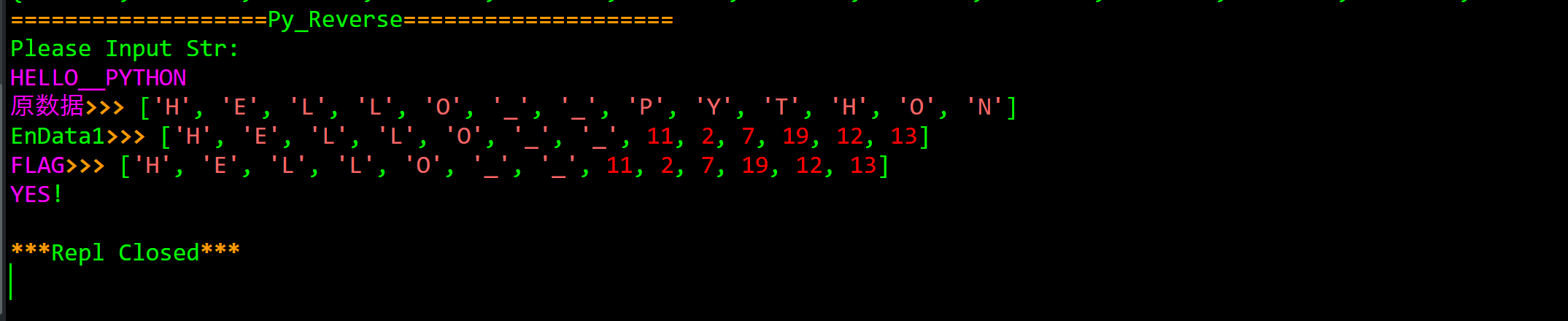
所以根据FLAG = ["H", "E", "L", "L", "O", "", "", 11, 2, 7, 19, 12, 13],只需找到后面数字对于的键
HELLO__PYTHON

 浙公网安备 33010602011771号
浙公网安备 33010602011771号