

P4 actor-critic methods
Actor—Critic Methods
(actor可以看成策略网络 critic可以看成价值网络 两者关系可以比较运动员和打分的裁判员,关系可以如下:
回顾之前价值学习和策略学习的内容,带入到actor-critic方法中,状态价值函数可以有下图中的改写:

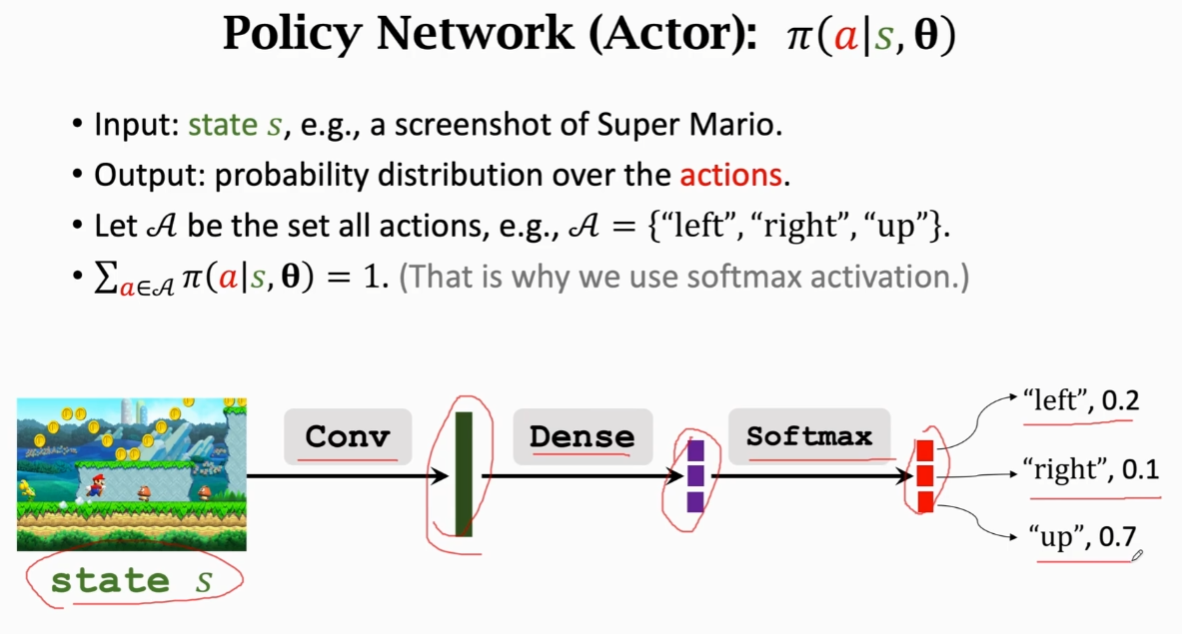
构造策略神经网络:(见P3
构造价值神经网络:

\[1.输入状态s和动作a\\
2.分别用一个卷积层和一个全连接层从输入得到特征,得到两个向量\\
3.将这两个向量拼接得到一个更高的特征向量\\
4.通过一个全连接层输出一个实数,这个数就是所谓的打分
\]
同时训练价值网络和策略网络就是actor-critic method
训练网络:

\[状态价值函数使用神经网络改写成v(s;\theta,w)\\
训练是为了更新θ和w,更新θ是为了让V的值更高(也就是对动作的评价越好),而更新\\w目的则是为了让π函数的评价越好,而\theta的更新又是依赖于π函数的
\]
步骤概况如下:

\[1.输入当前状态s_t\\
2.通过π函数随机抽样得到动作a_t\\
3.执行a_t之后得到下一次的状态s_{t+1}和奖励r_t\\
4.通过TD算法梯度下降更新w\\
5.根据梯度下降更新\theta
\]
回顾一下TD算法更新w和用蒙特卡洛近似来更新θ:(具体见P2和P3)


总结整个流程步骤:

\[1.观察状态s_t,并在π函数中根据当前动作s_t来随机抽样得到动作a_t\\
2.执行动作a_t,然后环境得到下一步的状态s_{t+1}和奖励r_t\\
3.从π函数中随机抽样得到动作a_{t+1} (注意,这里只是随机得到动作,并不执行这个动作)\\
4.执行两次价值神经网络得到两次的q值\\
5.根据两次q值得到TD误差\\
6,7,8,9 更新w_{t+1}和\theta_{t+1}\\
PS:在第九步中,有些论文会用的是\delta_t而不是q_t,这两种方法都是正确的,而用\delta_t的\\方法称为policy\ gradient\ with\ baseline(这种方法的精确度更加高一点,因为用了\\baseline的方法可以减低方差,让算法的收敛更加快
\]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号