spark、IDEA ,接收端口9999数据进行单词统计
本文基于官网:Spark 流式处理 - Spark 2.4.1 文档 (apache.org)
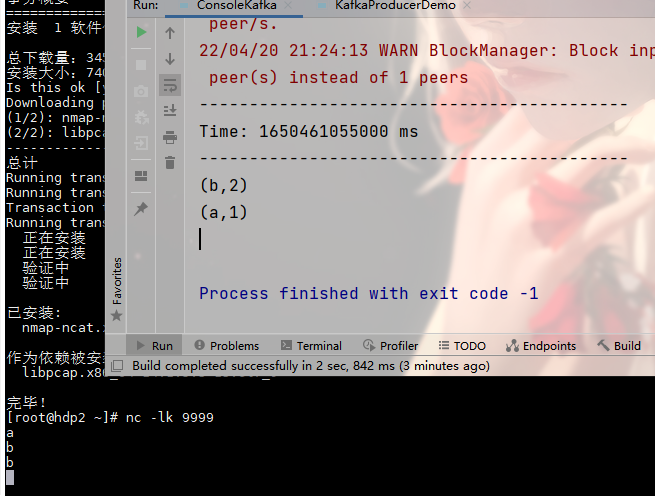
在linux一台机器上使用此命令:
nc -lk 9999 如果没有此命令,使用 yum install nc 下载
在linux端简单数据数据,IDEA端开启数据接收,统计单词数量
import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.{Seconds, StreamingContext} object ConsoleKafka { def main(args: Array[String]): Unit = { //初始化streamingContext val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(5)) //批次时间 五秒一次 //设置日志群权限 ssc.sparkContext.setLogLevel("WARN") //使用机器hdp1 指定接收端口 9999 的数据 val lines = ssc.socketTextStream("hdp2", 9999) //读取的是每行的数据 所以使用空格进行切割 val words = lines.flatMap(_.split(" ")) //给每个字段进行统计 返回key value 格式的数据 val pairs = words.map(word => (word, 1)) //根据key对数据进行叠加 val wordCounts = pairs.reduceByKey(_ + _) // Print the first ten elements of each RDD generated in this DStream to the console //输出值 wordCounts.print() ssc.start() // Start the computation ssc.awaitTermination() // Wait for the computation to terminate } }
我有一杯酒,足以慰风尘。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号