


1. Data exchanging with LOAD
To move data, Hive uses the LOAD statement. Move here means the original data is moved to the target table/partition and does not exist in the original place anymore. The LOCAL keyword in the LOAD statement specifies where the files are located on the client host. If the LOCAL keyword is not specified, the files are loaded from the full Uniform Resource Identifier (URI) specified after INPATH (most of the time, hdfs path ) or the value from the fs.default.name property defined in hdfs-site.xml by default. The path after INPATH can be a relative path or an absolute path. The path either points to a file or a folder (referring to all files in the folder) to be loaded, but the subfolder is not allowed in the path specified. If the data is loaded into a partition table, the partition column must be specified. The OVERWRITE keyword is used to decide whether to replace the existing data in the target table/partition or not. The following is an example of how to move data to the table or partition from local or HDFS files:
--1. Load local data in a table, internal or external. --The load statement is not repeatable since the files to be loaded are moved LOAD DATA LOCAL INPATH '/home/lenmom/Downloads/employee_hr.txt' OVERWRITE INTO TABLE employee_hr; --2. Load the local data to a partition LOAD DATA LOCAL INPATH '/home/lenmom/Downloads/employee.txt' OVERWRITE INTO TABLE employee_partitioned PARTITION (year=2018, month=12); --3. Load data from HDFS to a table using the URI --3.1. Use default fs path which is defined in core-site.xml, fs.defaultFS property. LOAD DATA INPATH '/tmp/hivedemo/data/employee.txt' INTO TABLE employee; -- Without OVERWRITE, it appends data --3.2. Use full URI LOAD DATA INPATH 'hdfs://localhost:9000/tmp/hivedemo/data/employee.txt' OVERWRITE INTO TABLE employee;
2. Data exchange with INSERT
To extract data from tables/partitions, we can use the INSERT keyword. Like other relational databases, Hive supports inserting data into a table by selecting data from another table. This is a very common ETL (a term in data warehousing for Extract,Transform, and Load) pattern used to populate an existing or new table from another table or dataset. The HQL INSERT statement has the same syntax as a relational database's INSERT . However, HQL has improved its INSERT statement by supporting data overwrittening, multi-insert, dynamic partition insert, as well as inserting data into files.The following are a few examples of INSERT statements in HQL:
-- Populate data from query while "INTO" will append data INSERT INTO TABLE employee SELECT * FROM ctas_employee; INSERT INTO TABLE emp_simple (name) -- Specify which columns to insert SELECT name FROM employee WHERE name = 'Will'; INSERT INTO TABLE emp_simple VALUES -- Insert constant values ('Michael', 'Toronto'),('Lucy', 'Montreal'); WITH a as ( SELECT * FROM ctas_employee ) FROM a INSERT OVERWRITE TABLE employee SELECT *; --Run multi-insert by only scanning the source table once for better performance --The INSERT OVERWRITE statement will replace the data in the target table/partition, while INSERT INTO will append data. FROM ctas_employee INSERT OVERWRITE TABLE employee SELECT * INSERT OVERWRITE TABLE employee_internal SELECT * INSERT OVERWRITE TABLE employee_partitioned PARTITION (year=2018, month=9) -- Insert to static partition SELECT *
When inserting data into the partitions, we need to specify the partition columns. Instead of specifying static partition values, Hive also supports dynamically giving partition values. Dynamic partitions are useful when it is necessary to populate partitions dynamically from data values. Dynamic partitions are disabled by default because a careless dynamic partition insert could create many partitions unexpectedly. We have to set the following properties to enable dynamic partitions:
SET hive.exec.dynamic.partition=true;
By default, the user must specify at least one static partition column. This is to avoid accidentally overwriting partitions. To disable this restriction, we can set the partition mode to nonstrict from the default strict mode before inserting into dynamic partitions as follows:
SET hive.exec.dynamic.partition.mode=nonstrict; -- Partition year, month are determined from data INSERT INTO TABLE employee_partitioned PARTITION(year, month) SELECT name, array('Toronto') as work_place, named_struct("gender","Male","age",30) as gender_age, map("Python",90) as skills_score, map("R&D",array('Developer')) as depart_title, year(start_date) as year, month(start_date) as month FROM employee_hr eh WHERE eh.employee_id = 102;
INSERT also supports writing data to files, which is the opposite operation compared to LOAD . It is usually used to extract data from SELECT statements to files in the local/HDFS directory. However, it only supports the OVERWRITE keyword, which means we can only overwrite rather than append data to the data files. By default, the columns are separated by Ctrl+A and rows are separated by newlines in the exported file. Column, row, and collection separators can also be overwritten like in the table creation statement. The following are a few examples of exporting data to files using the INSERT OVERWRITE ... directory statement
--1. insert to local files with default row separators INSERT OVERWRITE LOCAL DIRECTORY '/tmp/output1' SELECT * FROM employee; --2. Insert into local files with specified row separators INSERT OVERWRITE LOCAL DIRECTORY '/tmp/output2' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' SELECT * FROM employee; --3. Use multi-insert statements to export data from the same table FROM employee INSERT OVERWRITE DIRECTORY '/user/dayongd/output3' SELECT * INSERT OVERWRITE DIRECTORY '/user/dayongd/output4' SELECT name ;
Combined HQL and HDFS shell commands, we can extract data to local or remote files with both append and overwrite supported. The hive -e quoted_hql_string or hive -f <hql_filename> commands can execute a HQL query or query file. Linux's redirect operators and piping can be used with these commands to redirect result sets. The following are a few examples:
#Append to local files: $hive -e 'select * from employee' >> test #Overwrite local files: $hive -e 'select * from employee' > test #Append to HDFS files: $hive -e 'select * from employee'|hdfs dfs -appendToFile - /tmp/test1 #Overwrite HDFS files: $hive -e 'select * from employee' |hdfs dfs -put -f - /tmp/test2
3. Data exchange with [EX|IM]PORT
When working on data migration or release deployment, we may need to move data between different environments or clusters. In HQL, EXPORT and IMPORT statements are available to move data between HDFS in different environments or clusters. The EXPORT statement exports both data and metadata from a table or partition. Metadata is exported in a file called _metadata . Data is exported in a subdirectory called data, as follows:
EXPORT TABLE employee TO '/tmp/output5'; dfs -ls -R /tmp/output5/; +--------------------------------+ |DFS Output | +--------------------------------+ | ... /tmp/output5/_metadata | | ... /tmp/output5/data | | ... /tmp/output5/data/000000_0 | +--------------------------------+
For EXPORT , the database name can be used before the table name without any syntax error, but the database is useless and ignored by the IMPORT statement.
Once exported, we can copy exported files to other clusters manually or with the hadoop distcp <srcurl> <desturl> command. Then, we can import data in the following ways:
--1. Import data into a new table. If the table exists, it will throw an error IMPORT TABLE FROM '/tmp/output5'; -- By default, use exported table name Error: Error while compiling statement: FAILED: SemanticException [Error 10119]: Table exists and contains data files (state=42000,code=10119) IMPORT TABLE empolyee_imported -- Specify a table imported FROM '/tmp/output5'; --2. Import data to an external table, where the LOCATION property is optional IMPORT EXTERNAL TABLE empolyee_imported_external FROM '/tmp/output5' LOCATION '/tmp/output6'; --3. Export and import partitions EXPORT TABLE employee_partitioned partition (year=2018, month=12) TO '/tmp/output7'; IMPORT TABLE employee_partitioned_imported FROM '/tmp/output7';
4. Data sorting
Another aspect of manipulating data is properly sorting it in order to clearly identify important facts, such as top the N values, maximum, minimum, and so on. HQL supports the following keywords for data sorting:
4.1 ORDER BY [ASC|DESC]
It is similar to the SQL ORDER BY statement. When using ORDER BY , a sorted order is maintained across all of the output from every reducer. It performs a global sort using only one reducer, so it takes longer to return the result. The direction specifier after ORDER BY can be either ASC for ascending (low to high) or DESC for descending (high to low). If you do not provide a direction specifier, the default of ascending is used. Since v2.1.0, the ORDER BY statement supports specifying the sorting direction for the NULL value, such as NULL FIRST or NULL LAST . By default, NULL stays at the first place in the ASC direction and the last place in the DESC direction:
SELECT name FROM employee ORDER BY name DESC; -- By columns SELECT name FROM employee -- Order by expression ORDER BY CASE WHEN name = 'Will' THEN 0 ELSE 1 END DESC; SELECT * FROM emp_simple ORDER BY work_place NULL LAST;
Using LIMIT with ORDER BY is strongly recommended. When the hive.mapred.mode = strict property is set (the default value for hive.mapred.mode is nonstrict in Hive v1.* and strict in Hive v2.* ), it throws exceptions when using ORDER BY without LIMIT .
4.2 SORT BY [ASC|DESC]
It specifies which columns to use to sort reducer input records. This means the sorting is completed before sending data to the reducer. The SORT BY statement does not perform a global sort (but ORDER BY does) and only ensures data is locally sorted in each reducer. If SORT BY sorts with only one reducer ( set mapred.reduce.tasks=1 ), it is equal to ORDER BY , as the following example shows. Most of the time, SORT BY itself is useless but is used with DISTRIBUTE BY , which is introduced next:
--1. use more than 1 reducer SET mapred.reduce.tasks = 2; -- Sort by with more than 1 reducer SELECT name FROM employee SORT BY name DESC; +---------+ |name | +---------+ | Shelley | -- Once result is collected to client, it is order-less | Michael | | Lucy | | Will | +---------+ --2. use only one reducer SET mapred.reduce.tasks = 1; -- Sort by one reducer > SELECT name FROM employee SORT BY name DESC; +----------+ |name | +----------+ | Will | -- Same result to ORDER BY | Shelley | | Michael | | Lucy | +----------+
4.3 DISTRIBUTE BY
It is very similar to GROUP BY when the mapper decides to which reducer it can deliver the output. Compared to GROUP BY , DISTRIBUTE BY will not work on data aggregations, such as count(*) , but only directs where data goes. In this case, DISTRIBUTE BY is quite often used to reorganize data in files by specified columns. For example, we may need to use DISTRIBUTE BY after a UNION result set to reorganize data in higher granularity. When used with SORT BY to sort data within specified groups, DISTRIBUTE BY can be used before SORT BY in one query. In addition, the columns after DISTRIBUTE BY must appear in the select column list as follows:
-- Error when not specify distributed column employee_id in select SELECT name FROM employee_hr DISTRIBUTE BY employee_id; Error: Error while compiling statement: FAILED: SemanticException [Error 10004]: Line 1:44 Invalid table alias or column reference 'employee_id': (possible column names are: name) SELECT name, employee_id FROM employee_hr DISTRIBUTE BY employee_id; +----------+--------------+ | name | employee_id | +----------+--------------+ | Lucy | 103 | | Steven | 102 | | Will | 101 | | Michael | 100 | +----------+--------------+ -- Used with SORT BY to order name started on the same day SELECT name, start_date FROM employee_hr DISTRIBUTE BY start_date SORT BY name; +----------+--------------+ | name | start_date | +----------+--------------+ | Lucy | 2010-01-03 | | Michael | 2014-01-29 | | Steven | 2012-11-03 | | Will | 2013-10-02 | +----------+--------------+
4.4 CLUSTER BY
It is a shortcut operator you can use to perform DISTRIBUTE BY and SORT BY operations on the same group of columns. The CLUSTER BY statement does not allow you to specify ASC or DESC yet. Compared to ORDER BY , which is globally sorted, the CLUSTER BY statement sorts data in each distributed group:
SELECT name, employee_id FROM employee_hr CLUSTER BY name; +----------+--------------+ | name | employee_id | +----------+--------------+ | Lucy | 103 | | Michael | 100 | | Steven | 102 | | Will | 101 | +----------+--------------+
When we have to do a global sort, we can do CLUSTER BY first and then ORDER BY . In this way, we can fully utilize all the available reducers ahead of ORDER BY and have better performance, for example:
SELECT * FROM ( SELECT * FROM employee CLUSTER BY name ) base ORDER BY name;
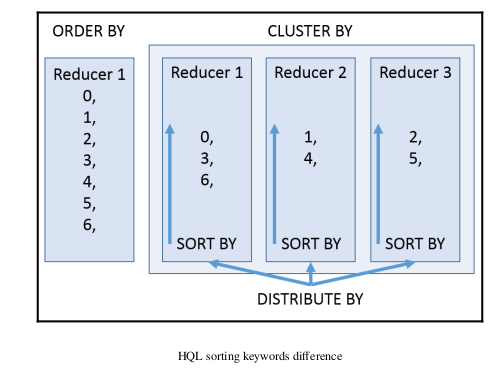
the difference between these sorting keywords is shown as follows:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号