


ACID (Atomicity, Consistency, Isolation, and Durability) is a long-expected Hive feature,and builds a foundation for relational databases; it has been available since Hive v0.14.0.Full ACID support in Hive is implemented through row-level transactions and locks. This
makes it possible for Hive to deal with use cases such as concurrent read/write, data cleaning, data modification, complex ETL/SCD (Slow Changing Dimensions), streaming data ingest, bulk data merge, and so on. In this section, we'll introduce them in more detail.
1. Transactions
For now, all transactions in HQL are auto-committed without supporting BEGIN , COMMIT ,and ROLLBACK , like as with relational databases. Also, the table that has a transaction feature enabled has to be a bucket table with the ORC file format. The following configuration parameters must be set appropriately in hive-site.xml or beeline connection string to turn on transaction support:
SET hive.support.concurrency = true; SET hive.enforce.bucketing = true; SET hive.exec.dynamic.partition.mode = nonstrict; SET hive.txn.manager =org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; SET hive.compactor.initiator.on = true; SET hive.compactor.worker.threads = 1;
When a transaction is enabled, each transaction-related operation, such as INSERT , UPDATE , and DELETE , stores data in delta files. At read time, the reader merges the base and delta files, applying any updates and deletes.Both base and delta directory names contain the transaction IDs.Occasionally, these changes need to be merged into the base files by compactors, which are background processes in the metastore , for better performance and smaller file size. To see a list of all tables/partitions currently being compacted or scheduled for compaction, use the SHOW COMPACTIONS statement.
Then, create a table with transactions enabled in the table properties and populate the data:
CREATE TABLE employee_trans ( emp_id int, name string, start_date date, quit_date date, quit_flag string ) CLUSTERED BY (emp_id) INTO 2 BUCKETS STORED as ORC TBLPROPERTIES ('transactional'='true'); -- Also need to set this
Insert data into the table:
INSERT INTO TABLE employee_trans VALUES (100, 'Michael', '2017-02-01', null, 'N'), (101, 'Will', '2017-03-01', null, 'N'), (102, 'Steven', '2018-01-01', null, 'N'), (104, 'Lucy', '2017-10-01', null, 'N');
For a table with transactions enabled, we can perform UPDATE , DELETE , and MERGE operations on data.
1.1 UPDATE statement
The UPDATE statement is used to update one or more columns in a table when certain conditions are met. Here, the updated columns cannot partition columns or bucket columns. The value used for updating should be an expression or constant rather than a subquery:
UPDATE employee_trans SET quite_date = current_date, quit_flag = 'Y' WHERE emp_id = 104;
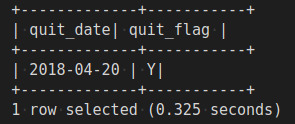
select and verify the update
SELECT quit_date, quit_flag FROM employee_trans WHERE emp_id = 104; -- Verify the update
1.2 DELETE statement
The DELETE statement is used to remove one or more rows from a table when a certain condition is met as follows:
DELETE FROM employee_trans WHERE emp_id = 104;
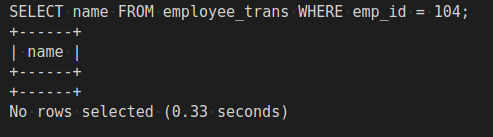
select and verify the deletes:
-- Verify the result, deleted SELECT name FROM employee_trans WHERE emp_id = 104;
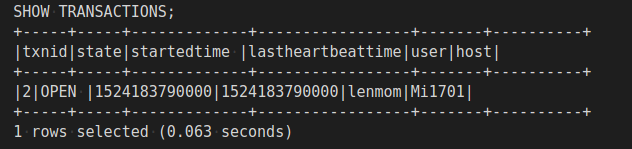
In HQL, the SHOW TRANSACTIONS statement is available to show currently open and aborted transactions in the system. When we run the previous queries, we can open another Hive connection and issue this statement to see the current transactions:
SHOW TRANSACTIONS;
The ABORT TRANSACTIONS transaction_id statement has been used to kill a transaction with a specified ID since Hive v2.1.0.
2. Locks
Locks ensure data isolation as described in the ACID principle. Hive has supported concurrency access and locking mechanisms since v0.7.0 and updated to a new lock manager in v0.13.0. There are two types of lock provided as follows:
- Shared lock: Also called S lock, it allows being shared concurrently. This is acquired when a table/partition is read.
- Exclusive lock: Also called X lock. This is acquired for all other operations that modify the table/partition.
For partition tables, only a shared lock is acquired if the change is only applicable to the newly-created partitions. An exclusive lock is acquired on the table if the change is applicable to all partitions. In addition, an exclusive lock on the table globally affects all partitions. For more information regarding locks, see https://cwiki.apache.org/confluence/display/Hive/Locking .
To enable locking, make sure the two properties are set in a Hive session or hive-site.xml (refer 1. Transaction, section above):
SET hive.support.concurrency = true SET hive.txn.manager =org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
Any query must acquire proper locks before being allowed to perform corresponding lock-permitted operations. When the query is SELECT , it will get an S lock. Concurrent SELECT statements on the same table will get multiple S locks and run in parallel. When the query is INSERT , it will get an X lock. Concurrent INSERT statements will only get one X lock, so an INSERT has to wait until the lock is released by the other INSERT . In addition, a table can only have one X lock. When trying to get an X lock, there should no other locks on the table, or else the operation that requires an X lock, such as INSERT , ALTER , has to wait and retry (the hive.lock.sleep.between.retries property controls the retry time).
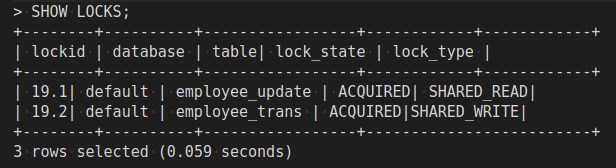
By using the new lock manager, DbTxnManager , locks can only be acquired/released from a query implicitly. To see the locks on the table, use the SHOW LOCKS / SHOW LOCKS table_name statement:
-- Show all locks when running merge into above > SHOW LOCKS;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号