
空域图卷积模型
1)spatial-based methods define graph convolutions based on a node’s spatial relations
基于空间的方法根据节点的空间关系定义图卷积
2)the spatial-based graph convolutions convolve the central node’s representation with its neighbors’ representations to derive the updated representation for the central node
基于空间的图卷积将中心节点的表示与其邻居的表示进行卷积,从而得到中心节点的更新表示
3)The spatial graph convolutional operation essentially propagates node information along edges. (information propagation/message passing)
空间图卷积操作本质上是沿边传播节点信息。 (信息传播/消息传递)
GNNs follow a neighborhood aggregation scheme, where the representation vector of a node is computed by recursively aggregating and transforming representation vectors of its neighboring nodes.
GNNs broadly follow a recursive neighborhood aggregation (or message passing) scheme, where each node aggregates feature vectors of its neighbors to compute its new feature vector. After k iterations of aggregation, a node is represented by its transformed feature vector, which captures the structural information within the node’s k-hop neighborhood. The representation of an entire graph can then be obtained through pooling, for example, by summing the representation vectors of all nodes in the graph.
- 真正的难点聚焦于邻居结点数量不固定上,1)提出一种方式把非欧空间的图转换成欧式空间;2)找出一种可处理变长邻居结点的卷积核在图上抽取特征。
- 图卷积的本质是想找到适用于图的可学习卷积核。
- 卷积操作关心每个结点的隐藏状态如何更新
- 核心在于聚合邻居结点的信息
- GCN中通过级联的层捕捉邻居的消息,层与层之间的参数不同
一、部分空域模型:
1、NN4G [“Neural network for graphs: A contextual constructive approach,” Mar. 2009. ]
NN4G通过每一层具有独立参数的组合神经结构来学习图的相互依赖性。节点的邻域可以通过架构的增量构建来扩展。NN4G通过直接总结节点的邻域信息来执行图的卷积。它还应用residual connections和skip connections来记忆每一层的信息。因此,NN4G的下一层节点状态:
![]() 矩阵形式:
矩阵形式:![]()
2、CGMM (Contextual graph Markov model)[“Contextual graph Markov model: A deep and generative approach to graph processing,” in Proc. ICML, 2018 ]
建立一个由概率模型层组成的深层架构的方法,这些概率模型学会以递增的方式编码结构化信息。上下文以一种有效且可伸缩的方式扩散到图的顶点和边缘。
处理结构化数据需要迎合改变规模大小和连接性的样本,从这种可变性模式中提取有用的预测或探索性分析。They are able to learn both the hidden representation (state encoding) and the output function for classification or regression tasks.
基本的CGMM组件使用离散的隐藏状态变量来建模一个图,这些变量对顶点及其上下文的信息进行编码。在保持空间局部性的同时,CGMM具有概率可解释性的优点。
3、Diffusion CNN (DCNN) [ “Diffusion-convolutional neural networks,” in Proc. NIPS, 2016]
将图的卷积看作是一个扩散过程。假设信息以一定的转移概率从一个节点转移到相邻节点,使信息分布经过几轮后达到均衡。
DCNN defines the diffusion graph convolution (DGC) as
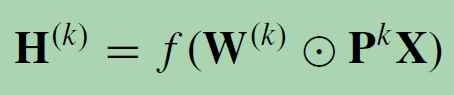
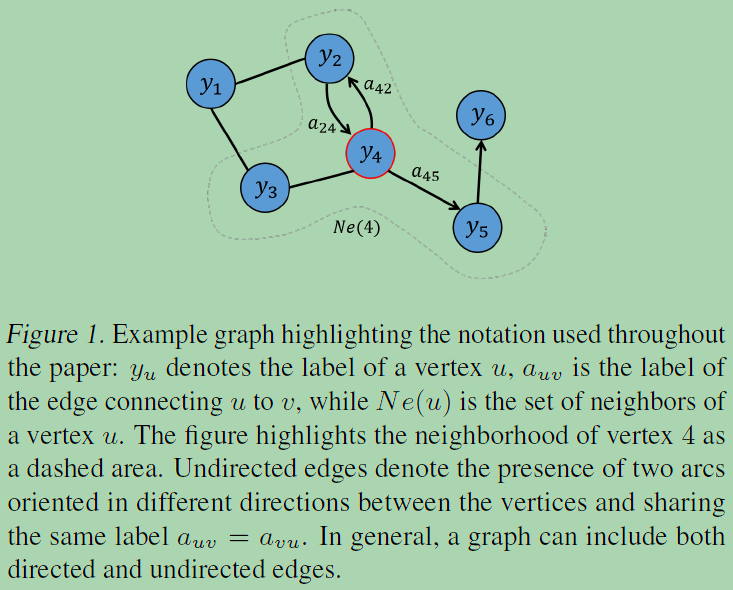
the probability transition matrix P : Rn×n is computed by P = D−1A. 对于一张graph而言,有N个node,每个node有F个feature,每个节点关注H hop以内的信息。此类模型刻画了节点之间的高阶信息,但是由于PK (表示两个节点在随机行走下K 跳可达概率)的计算复杂度为O(n2K),难以扩展到大图上.
注意,在DCNN中,隐藏表示矩阵H(k)与输入特征矩阵X保持相同维数,而不是之前隐藏表示矩阵H(k−1)的函数。DCNN连接H(1),H(2),…,H(K)一起作为最终模型输出。
如何从图形结构数据中学习基于扩散的表示,并将其用作节点分类的有效基础。the diffusion-convolution operation builds a latent representation by scanning a diffusion process across each node in a graph-structured input. 图扩散可以被表示为一个矩阵幂级数,提供了一个直接的机制,包括实体的上下文信息,可以在多项式时间计算和有效地在GPU上实现。
DCNN的核心操作是从节点及其特性映射到从该节点开始的扩散过程的结果。与标准的CNNs不同,DCNN的参数是根据扩散搜索深度而不是它们在网格中的位置来绑定的。
4、DGC [ “Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,” in Proc. ICLR, 2018]
由于扩散过程的平稳分布是概率转移矩阵的幂级数的总和,DGC对每个扩散步骤的输出进行求和而不是串联。
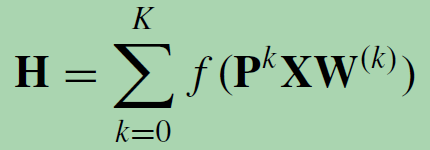
使用转移概率矩阵的幂意味着遥远的邻居对中心节点贡献很少的信息。
5、PGC-DGCNN [“On filter size in graph convolutional networks,” in Proc. IEEE Symp. Ser. Comput. Intell. (SSCI), Nov. 2018]
PGC-DGCNN基于最短路径增加了遥远邻居的贡献。它定义了一个最短路径邻接矩阵S(j)。如果节点v到节点u的最短路径长度为j,则S(j) v,u = 1,否则为0。用超参数r来控制感受野的大小,PGC-DGCNN引入了一个图卷积操作,如下所示:
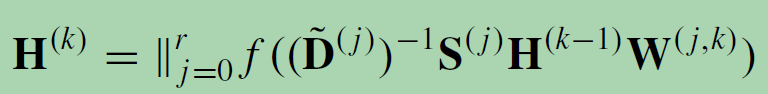
H(0) = X, and || represents the concatenation of vectors. The calculation of the shortest-path adjacency matrix can be expensive with O(n3) at maximum.
本质上更换了邻接矩阵A,将不同路径长度(最短)的结点进行分组聚合(|| 拼接),这样最近的结点和最远的结点的贡献是均匀的。
6、PGC, Partition Graph Convolution [ “Spatial-temporal graph convolutional networks for skeleton-based action recognition,” in Proc. AAAI, 2018]
PGC根据一定的准则将节点的邻居划分为Q组,而不局限于最短路径。PGC根据每组定义的邻域构造Q个邻接矩阵。然后, PGC将具有不同参数矩阵的GCN应用于每个相邻组,并对结果进行求和:
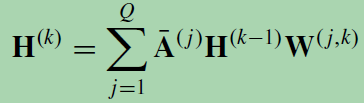
H(0) = X, ¯A( j ) = (˜D( j ))−(1/2)˜A( j )(˜D( j ))−(1/2), and ˜A( j ) = A( j ) + I.
7、MPNN, Message-Passing Neural Network [“Neural message passing for quantum chemistry,” in Proc. ICML, 2017]
消息传递神经网络(MPNN)概述了基于空间的图卷积的一般框架。消息传播网络(MPNN)立足于节点之间的信息传播聚合,通过定义聚合函数的通用形式提出框架。它将图卷积视为一种消息传递过程,在此过程中,信息可以沿着边直接从一个节点传递到另一个节点。MPNN运行k步消息传递迭代,以让信息进一步传播。消息传递函数(即空间图卷积)定义为:
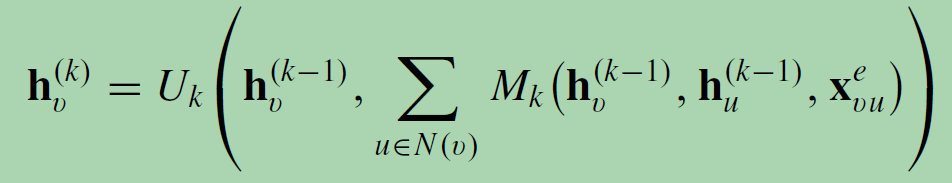
Mk (·)为聚合函数, Uk (·)为更新函数。聚合函数作用于每个节点及其相邻节点,得到节点的局部结构表达式。消息传播网络指出图卷积的核心在于定义节点之间的聚合函数,基于聚合函数,每个节点可以表示为周围节点和自身的信息叠加。
因此,该模型通过定义通用的聚合函数提出图卷积网络的通用框架.消息传播网络分为两个步骤,
首先将聚合函数作用在每个节点及其邻近节点上,得到节点的局部结构表达;
然后,将更新函数作用在自身和局部结构表达上,得到当前节点的新表达。
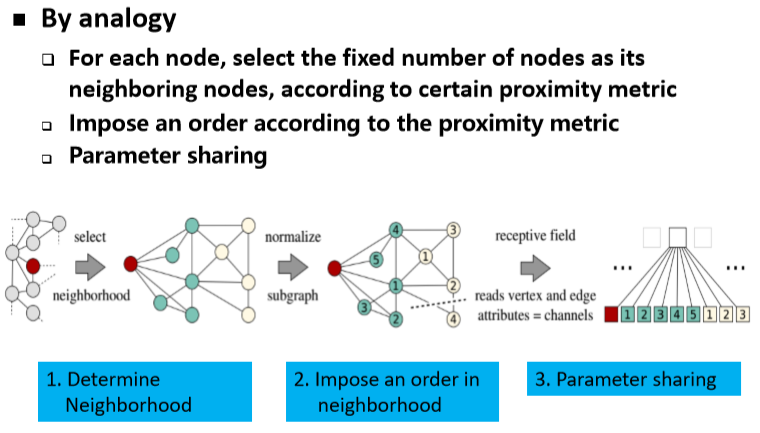
➢1)通过采样,得到邻域节点。
➢2)使用聚合函数来聚合邻居节点的信息,获得目标节点的embedding;
➢3) 利用节点上聚合得到的信息,来预测节点/图的label;
最终学习到的结点表示可以进行结点级别任务,或者通过图池化函数进行图级别任务。
读出函数根据节点隐藏表示生成整个图的表示:
![]() ,where T denotes the total time steps.
,where T denotes the total time steps.
MPNN通过假设Uk(·)、Mk(·)和R(·)的不同形式,可以覆盖许多现有的GNN。
因此,MPNN框架可以通过不同的函数设置泛化几种不同的模型。这里给出一个一般化GGNN(Gated Graph Neural Networks)的例子,GGNNs的函数设置是:
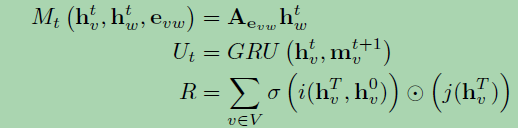
Aevw is the adjacency matrix, one for each edge label e. The GRU is the Gated Recurrent Unit. i and j are neural networks in function R.
8、GIN, graph isomorphism network [“How powerful are graph neural networks,” in Proc. ICLR, 2019]
图同构网络(GIN)发现,以往基于MPNN的方法无法根据图区分不同的图结构嵌入表示。为了修正这个缺点,GIN通过一个可学习的参数来调整中心节点的权值e(k),通过进行图卷积:

其中MLP(·)表示一个多层感知机。
Ideally, a maximally powerful GNN could distinguish different graph structures by mapping them to different representations in the embedding space.
if the neighbor aggregation and graph-level readout functions are injective(单射), then the resulting GNN is as powerful as the WL test.
对于可数集,单射性很好地表征了一个函数是否保持了输入的特殊性。

The WL test iteratively (1) aggregates the labels of nodes and their neighborhoods, and (2) hashes the aggregated labels into unique new labels. The algorithm decides that two graphs are non-isomorphic if at some iteration the labels of the nodes between the two graphs differ.
WL测试迭代地(1)将节点及其邻域的标签进行聚合,(2)将聚合的标签散列成唯一的新标签。该算法判定两个图的非同构,如果在某个迭代时两个图之间节点的标签不同。
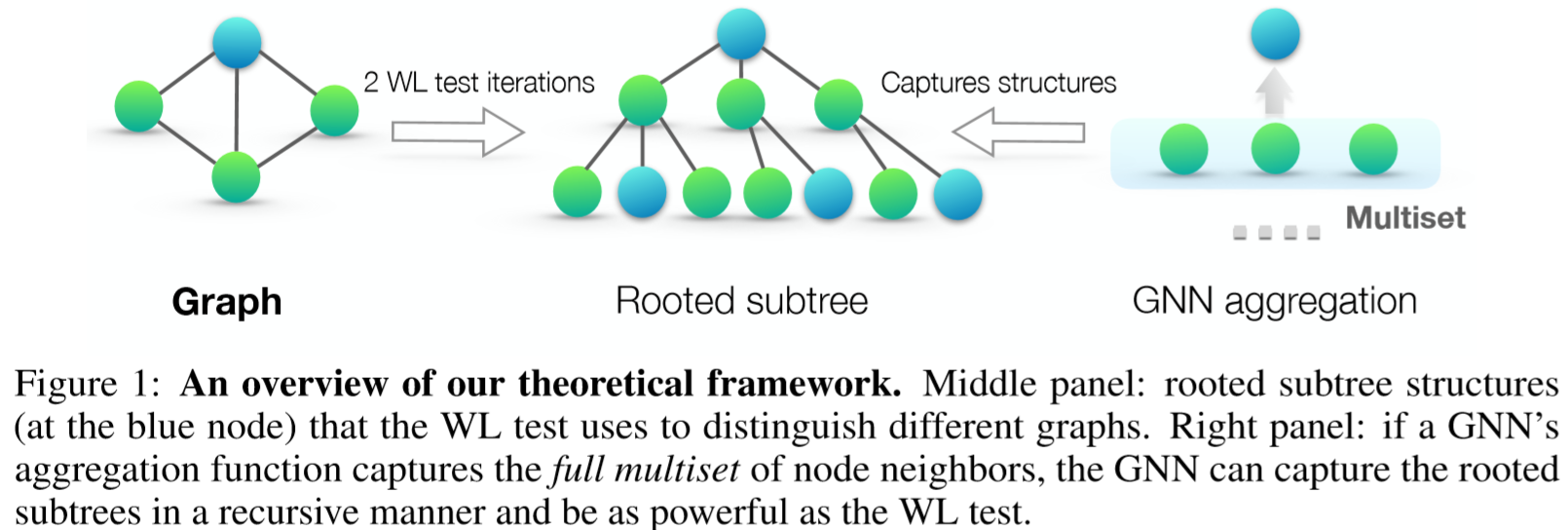
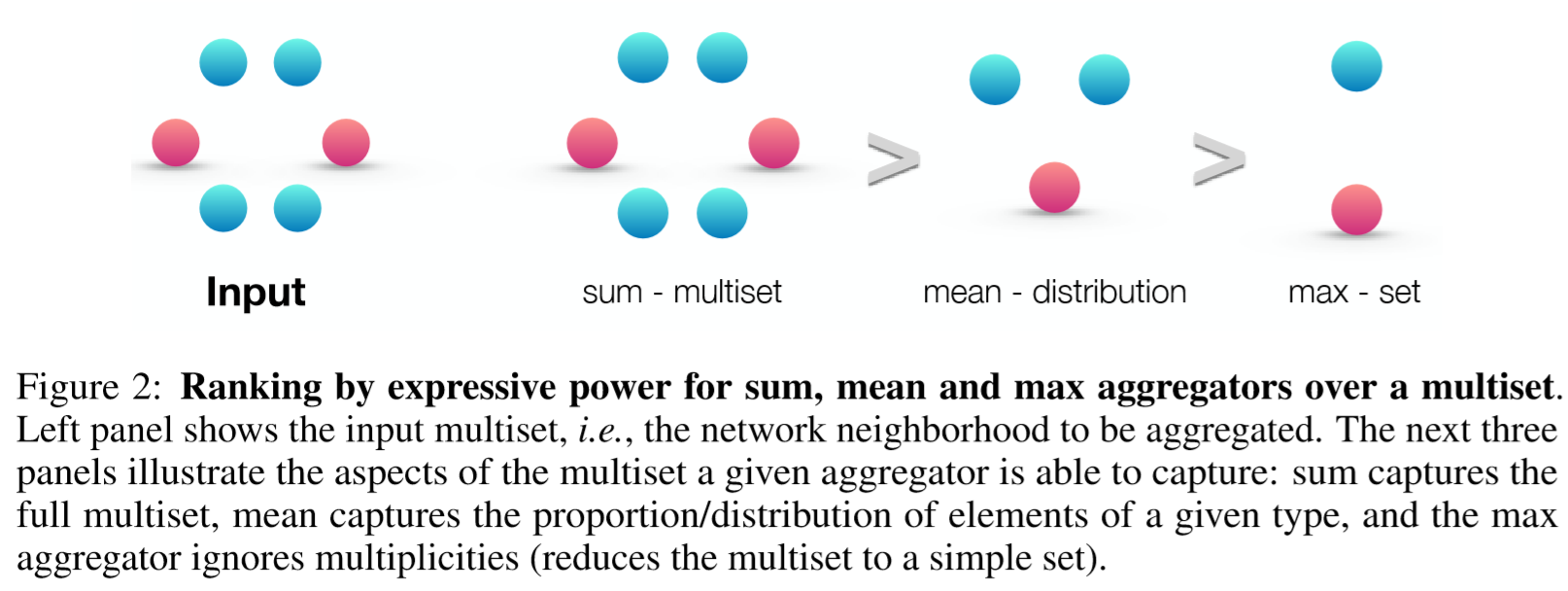
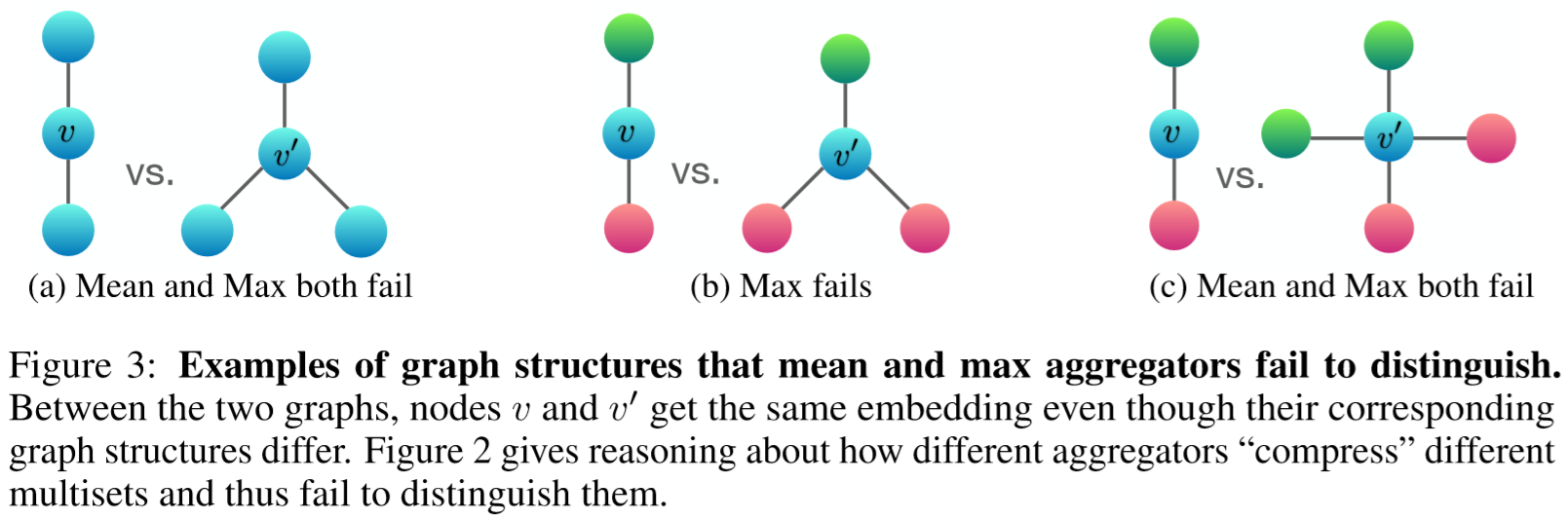
均值聚合的能力大于最大值聚合的能力,小于求和聚合的能力。
9、GraphSage [ “Inductive representation learning on large graphs,” in Proc. NIPS, 2017]
由于节点的邻居的数量可以从1个到1000个甚至更多,因此取节点邻居的完整大小是低效的。GraphSage采用均匀随机采样的方法,为每个节点获得固定数量的邻居。它执行图的卷积:
![]()
fk (·) is an aggregation function, and SN(v) is a random sample of the node v’s neighbors.
聚合函数应该对节点顺序的排列不变,例如均值、和或最大值函数。图采样聚合网络也提出用分批量(Mini-Batch)处理数据的方法训练模型,在每个批量输入数据下只需要加载对应节点的局部结构,避免了整张网络的加载,这使得在大规模数据集上搭建图卷积神经网络成为可能.对于LSTM聚合函数,由于需要一种邻居顺序,所以采用了一种简单的随机顺序。
10、GAT,Graph attention network [“Graph attention networks,” in Proc. ICLR, 2017]
GAT假设邻近节点对中心节点的贡献既不像GraphSage那样完全相同,也不像GCN那样预先确定。GAT采用注意机制来学习两个连通节点之间的相对权值。根据GAT的图卷积操作定义为:
![]()
![]()
g(·) is a LeakyReLU activation function and a is a vector of learnable parameters. The softmax function ensures that the attention weights sum up to one overall neighbors of the node v.
利用注意力系数对邻域节点进行有区别的信息聚合,完成图卷积操作。注意力权重将周围节点(一阶邻域)的表达以加权和的形式聚合到自身。
对于多种注意力机制下的计算结果,图注意力网络提供了拼接和均值两种计算方式。由GAT开始,节点之间的权重计算开始从依赖于网络的结构信息转移到依赖于节点的特征表达。
One of the challenges of these approaches is to define an operator which works with different sized neighborhoods and maintains the weight sharing property of CNNs.
One of the benefits of attention mechanisms is that they allow for dealing with variable sized inputs, focusing on the most relevant parts of the input to make decisions.
The attention architecture has several interesting properties: (1) the operation is efficient since it is parallelizable across node neighbor pairs; (2) it can be applied to graph nodes having different degrees by specifying arbitrary
weights to the neighbors; and (3) the model is directly applicable to inductive learning problems, including tasks where the model has to generalize to completely unseen graphs.
11、 GeniePath [ “GeniePath: Graph neural networks with adaptive receptive paths,” in Proc. AAAI Conf. Artif. Intell., Jul. 2019]
GeniePath进一步提出了一种类似lstm的门控机制来控制跨图卷积层的信息流。提出了自适应感受野的 GNN 算法。但是该算法的并不是通过调整节点的领域来实现的,而将距离多跳(k-hop)的节点的信息存储在 LSTM 的 memory 中,由神经网络进行学习自动判断哪些信息对于自己完成下游任务是有利的,而进行提取和过滤。🔗
一种学习基于排列不变图数据的神经网络自适应接受域的可扩展方法。在GeniePath中,提出了一种自适应路径层,它由两个互补的功能组成,分别用于广度和深度的探索,前者学习不同大小邻域的重要性,而后者则从不同跳点的邻域中提取和过滤聚合的信号。提出的自适应路径层直观地指导了接受域的广度和深度探索。因此,将这种自适应学习的接受领域称为接受路径。
To summarize, the major effort put on this area is to design effective aggregator functions that can propagate signals around the T-th order neighborhood for each node.
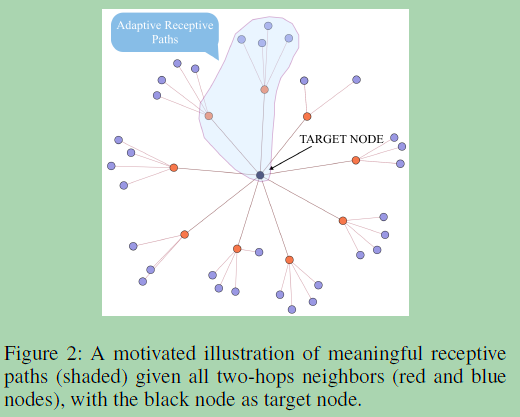
目标是学习对目标节点贡献最大的有意义的接受路径(阴影区域),而不是聚集所有的2跳邻居来计算目标节点的嵌入。有意义的路径可以看作是与目标节点相关联的子图。需要做的是进行广度/深度的探索,过滤有用的/有噪声的信号。宽度探索决定了哪些邻居是重要的,即引导探索的方向,而深度探索决定了有多少跳的邻居仍然有用。这种子图上的信号滤波本质上是学习接收路径。
在置换不变图的情况下,假设学习任务是独立于邻居的顺序。目标是学习接受路径,同时沿着已学习的路径传播信号,而不是预先定义的路径。这个问题相当于通过对每个节点展开宽度(哪一个单跳邻居重要)和深度(第t跳之外的邻居的重要性)来确定合适的子图。
我们可以将本文和 GAT 或者 GraphSAGE 等常用的非频域的 GNN 框架的区别认为是在它们的基础上加了 memory(通过 LSTM 实现)。存储通过一阶邻域进行的信息传递得到的高阶领域节点的信息。所谓的自适应,自学习,其实就是通过 LSTM 的门对 LSTM 的 memory 所存储的高阶领域信息的提取和过滤 (分别对应遗忘门和输出门)所体现的。而一阶邻域和高阶领域的信息交互体现在 LSTM 的输入门。
12、MoNet, Mixture model network [“Geometric deep learning on graphs and manifolds using mixture model CNNs,” (CVPR), Jul. 2017]
该方法可以有效地将CNN结构引入到图上。提出了一个统一的框架,允许将CNN体系结构推广到非欧几里得域(图和流形),并学习局部、平稳和合成任务特定的特征。
The main contribution of this paper is a generic spatial domain framework for deep learning on non-Euclidean domains such as graphs and manifolds.
混合模型网络(MoNet)采用了不同的方法对节点的相邻节点分配不同的权值。它引入节点伪坐标来确定节点与相邻节点的相对位置。一旦知道了两个节点之间的相对位置,权重函数将相对位置映射为这两个节点之间的相对权重。这样,图过滤器的参数可以在不同的位置共享。MoNet还提出了一个参数可学习的高斯核来自适应地学习权函数。特别地,证明了patch算子可以被构造成局部图的函数或流形伪坐标,并研究了一组用高斯核混合表示的函数。
13、PATCHY-SAN🔗 [“Learning convolutional neural networks for graphs,” in Proc. ICML, 2016]
PATCHY-SAN根据每个节点的图标签对其邻居进行排序,并选择顶部的q邻居。图标签本质上是节点评分,可以通过节点度、中心性和Weisfeiler Lehman (WL)颜色来推导。由于每个节点现在都有固定数量的有序邻居,因此可以将图结构数据转换为网格结构数据。PATCHY-SAN应用一个标准的1-D卷积滤波器来聚合邻域特征信息,其中滤波器权重的顺序对应于节点的邻域的顺序。PATCHY-SAN的排序准则只考虑图的结构,图的数据处理需要大量的计算量。
14、LGCN [ “Large-scale learnable graph convolutional networks,” ACM SIGKDD, Aug. 2018]
large-scale GCN (LGCN)根据节点特征信息对节点的邻居进行排序。对于每个节点,LGCN组装一个由其邻域组成的特征矩阵,并沿着每列对该特征矩阵进行排序。将排序后的特征矩阵的q行作为中心节点的输入数据。LGCN也利用cnn作为聚合器。对节点邻域矩阵进行最大pooling,得到top-k特征元素,然后应用1-D CNN计算隐藏表示。
15、 FastGCN
FastGCN对每个图的卷积层采样固定数量的节点,而不是像GraphSage那样对每个节点采样固定数量的邻居。它将图的卷积解释为节点嵌入函数在概率测度下的积分变换。采用蒙特卡罗近似和方差减少技术来简化训练过程。由于FastGCN为每一层独立地采样节点,层间连接可能是稀疏的。Huang等人提出了一种自适应分层抽样方法,下层节点的抽样条件是上层节点的抽样。与FastGCN相比,该方法获得了更高的精度,但采用了更复杂的采样方案。
PinSage提出了基于重要抽样方法(importance-based sampling)。通过模拟从目标节点开始的随机行走,该方法选择具有最高标准化访问次数的T个节点。FastGCN进一步改进了采样算法。FastGCN不是对每个节点进行邻居采样,而是直接对每一层的接受域进行采样。FastGCN使用重要性抽样,其重要性因子计算如下
![]()
16、 StoGCN
通过使用历史节点表示作为控制变量,StoGCN进行随机训练,将图卷积的接受野减小到任意小的规模。即使每个节点有两个邻居,StoGCN也可以获得相当的性能。然而,StoGCN仍然需要保存所有节点的中间状态,这对于大型图来说是消耗内存的。
17、 Cluster-GCN
Cluster-GCN使用图聚类算法对一个子图进行采样,并对采样的子图内的节点进行图卷积。由于邻域搜索也被限制在采样的子图中,因此Cluster-GCN能够同时处理更大的图,使用更深层的架构,并且用更少的时间和更少的内存。值得注意的是,Cluster- GCN为现有ConvGNN训练算法的时间复杂度和内存复杂度提供了一个直观的比较。
二、 图池化操作(downsampling strategy)
1)pooling operation:池化操作的目的是通过降低节点采样以生成更小的表示,从而减少参数的大小,从而避免过拟合、置换不变性和计算复杂度问题。
2)readout operation:读取操作主要用于基于节点表示生成graph-level表示。它们的机制非常相似。
池化算子一方面能够减少学习的参数,另外一方面能反应输入数据的层次结构.在图结构中使用池化操作,主要目的是刻画出网络的等级结构.
图上的池化操作通常对应的是图分类任务,对于图G=(A,X),其中A 为邻接矩阵,X 为节点的特征矩阵,给定一些标注的图数据D={(G1,y1),(G2,y2),…}和图对应的标签集合Y,通过一个映射函数f:G→Y,能够将图结构映射到对应的标签.
1、graph coarsening algorithms
在一些早期的研究中,图粗化算法利用特征分解对图进行基于拓扑结构的粗化。然而,这些方法都存在时间复杂度问题。Graclus算法是对原始图进行特征分解计算聚类版本的一种替代方法。
2、mean/max/sum pooling
目前,由于在池窗口中计算均值/最大值/总和的速度快,均值/最大值/总和池是实现下采样最原始、最有效的方法:
![]()
K is the index of the last graph convolutional layer.
Henaff等人表明,在网络开始时执行一个简单的max/mean pooling对于降低图域的维数和减少昂贵的图傅里叶变换操作的代价尤为重要。此外,一些工作也使用了注意机制来增强均值和池。即使有注意机制,减少操作(如和池)也不能令人满意,因为它使嵌入效率低下;无论图的大小如何,都会生成固定大小的嵌入。
3、 Set2Set method
Set2Set方法来生成随着输入大小增加的记忆。随后它实现一个LSTM,用于在下采样可能破坏信息之前,将依赖序列顺序的信息集成到内存嵌入中。
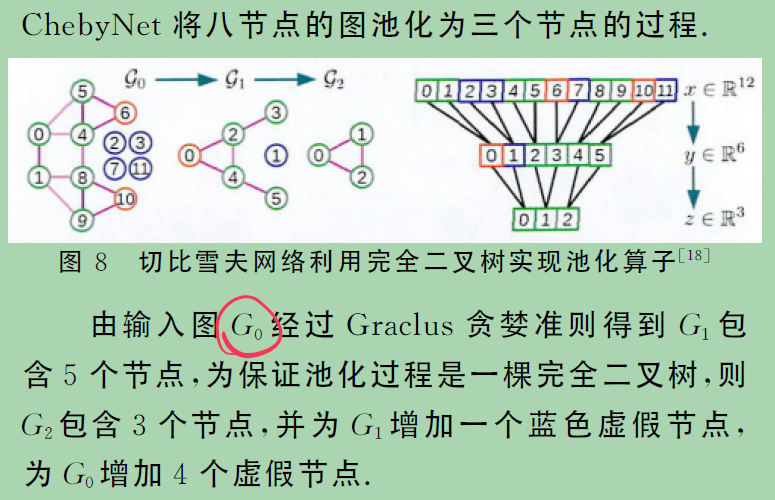
4、 ChebNet
Defferrard等人用另一种方式解决了这个问题,即以一种有意义的方式重新排列图中的节点。他们在他们的方法ChebNet中设计了一个有效的集中策略,即首先将输入图粗化到多个层次。粗化后,输入图及其粗化版本的节点被重新排列成平衡二叉树。任意地从下到上聚合平衡二叉树会将相似的节点排列在一起。将这样重新安排的信号合用比将原始信号合用效率高得多。
5、 SortPooling
Zhang等人提出了具有类似池策略的DGCNN,名为SortPooling,即通过将节点重新安排到一个有意义的顺序来执行池化。与ChebNet不同,DGCNN根据节点在图中的结构角色对节点进行排序。空间图卷积产生的图的无序节点特征被视为连续的WL颜色,然后使用它们对节点进行排序。除了对节点特征进行排序,它还通过截断/扩展节点特征矩阵将图的大小统一到 q。如果有 n>q,则删除最后的 n−q 行,否则添加 q−n 行。
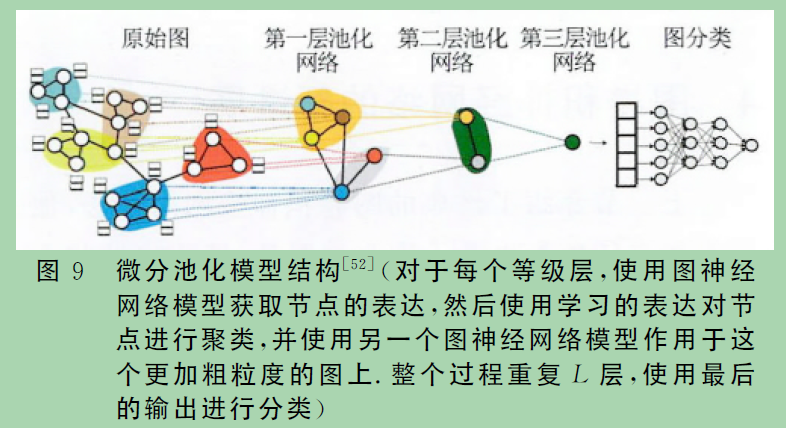
6、 DiffPooling
上述的pooling方法主要考虑图的特征,而忽略了图的结构信息。最近一种可微池(DiffPool)被提出,它可以生成图的层次表示。与之前所有粗化方法相比,DiffPool并不是简单地对图中的节点进行聚类,而是学习第 k层上的聚类分配矩阵 .
其核心思想是学习综合考虑图的拓扑和特征信息的节点分配,因此上述等式可以用任何标准图卷积神经网络实现。然而,DiffPool的缺点是池化后生成稠密图,计算复杂度变成O(n2)。该模型被用来做软聚类和网络节点表示学习,其需要存储分配矩阵,因此空间复杂度为O(kV2),k为池化比例.
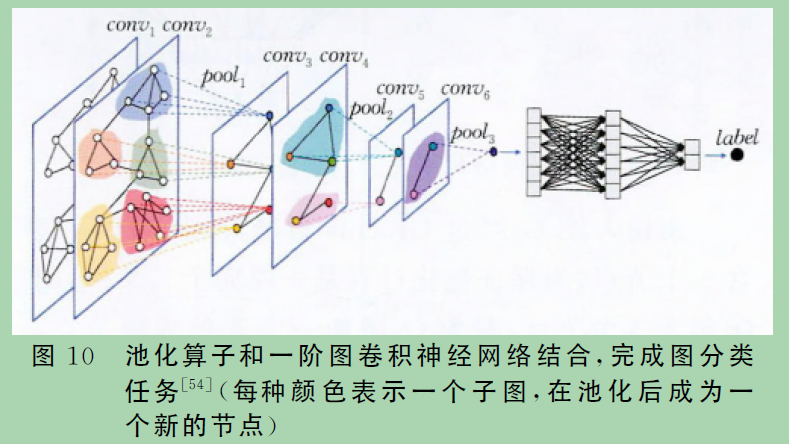
7、EignPooling
为了在池化过程中充分利用节点特征和局部结构,谱池化(EignPooling)利用谱聚类将整个大图划分成几个不存在重叠的子图,而每个子图即作为池化后的一个新节点,新节点间的连边则基于原子图连边产生.EignPooling可以控制每次划分后的子图个数,进而控制每一层的池化比例.下图展示了将EignPooling池化算子和一阶图卷积神经网络结合,完成图分类任务的框架。
8、ASGPool
基于注意力机制的池化算子(ASGPool )同样着眼于在池化过程中同时考虑节点属性信息和结构信息,ASGPool 基于注意力机制通过结构和属性信息为每个节点学到一个标量,以此标量表征对应节点在整个图上的重要性,并对此标量进行排序,根据排序结果保留最重要的一部分节点及其连边进而完成池化操作.

池化算子是为了学到图的等级结构,进而完成图级别的任务.起初的池化算子基于图的拓扑结构,启发式的定义一些节点的舍弃或者融合方式,近期,池化算子不仅依赖于拓扑结构,同样依赖于节点的属性信息,同时池化过程也开始通过注意力机制参数学习等由模型指导完成.
General Frameworks:
不同的综述有不同的分类,这里结合参考[1]和[2]:
1)Message Passing Neural Networks (MPNN):见前面分析,
2)Non-local Neural Networks(NLNN)
提出了利用深度神经网络捕获远程依赖关系的非局部神经网络。非局部运算是计算机视觉中经典的非局部平均运算的推广。非局部运算将某一位置的响应计算为所有位置特征的加权和。位置集可以是空间、时间或时空。因此,NLNN可以看作是不同的“self-attention”的统一。
the general definition of non-local operations:

where i is the index of an output position and j is the index that enumerates all possible positions. f(hi; hj) computes a scalar between i and j representing the relation between them. g(hj) denotes a transformation of the input hj and a factor 1/C(h) is utilized to normalize the results.
有几个实例化具有不同的f和g设置。为了简单起见,使用线性变换作为函数g,即g(hj) =Wghj,其中wg是一个学习过的权值矩阵。下面我们列出函数f的选项。
①高斯函数Gaussian.。高斯函数是根据非局部均值和双边滤波器的自然选择。因此
![]() ,dot-product similarity
,dot-product similarity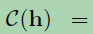
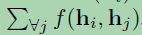
②Embedded Gaussian:通过计算嵌入空间中的相似度,可以很直观地扩展高斯函数
![]()

③Dot product:The function f can also be implemented as a dot-product similarity:
![]() ,
,![]()
④ Concatenation
![]() ,
,![]() ,wf is a weight vector projecting the vector to a scalar
,wf is a weight vector projecting the vector to a scalar
3)Graph Networks
图网络(GN)框架是对各种图神经网络、MPNN和NLNN方法的总结和扩展。GN核心计算单元GN块及其计算步骤:
Graph networks (GNs) proposed a more general framework for both GCNs and GNNs that learned three sets of representations: ![]() as the representation for nodes, edges, and the entire graph, respectively. These representations were learned using three aggregation and three updating functions:
as the representation for nodes, edges, and the entire graph, respectively. These representations were learned using three aggregation and three updating functions:


综上所述,卷积运算已经从频谱域发展到空间域,从多步邻域发展到直接邻域。目前,从最近邻收集信息并遵循上述的框架,是图卷积操作最常见的选择。
Applications:
图神经网络已经在监督,半监督,无监督和强化学习设置的问题领域的广泛探索。
简单地将应用划分为三种场景:
(1)数据具有显式关系结构的结构化场景,如物理系统、分子结构和知识图;
(2)关系结构不明确的非结构化场景,包括图像、文本等;
(3)生成模型、组合优化问题等其他应用场景。
对于Non-structural Scenarios 将图神经网络应用于非结构化场景的方法大致有两种:
(1)结合其他领域的结构化信息来提高性能,例如利用知识图信息来缓解图像任务中的零射击问题;
(2)推断或假设场景中的关系结构,然后应用模型解决定义在图上的问题,如模型文本化为图的方法。
参考:
1: A Comprehensive Survey on Graph Neural Networks
2:Deep Learning on Graphs: A Survey
2::图卷积神经网络综述
其他总结:🔗
GNN 教程(特别篇):一文遍览GNN的代

 浙公网安备 33010602011771号
浙公网安备 33010602011771号