Filebeat工作过程(二)
Filebeat简介
Filebeat是一个轻量级的收集日志和传输日志的工具(一直以为Filebeat是存储数据,并不是的它只是做一个收集传输功能);Filebeat安装在每一个你想要收集日志的服务器上,相当于客户端。Filebeat监控你指定的日志文件或者路径,收集日志事件向Elasticsearch或者Logstach进行索引。
简单理解Filebeat是如何工作的
当你启动Filebeat,它开始监视你指定的一个或多个文件或路径。Filebeat定位的每个日志,Filebeat开始启动一个harvester。每个harvester读取到一个日志的新内容就发送到libbeat,聚合起来然后把聚合的数据发送到你设置输出的地方,如elasticsearch,logstach等。如图:
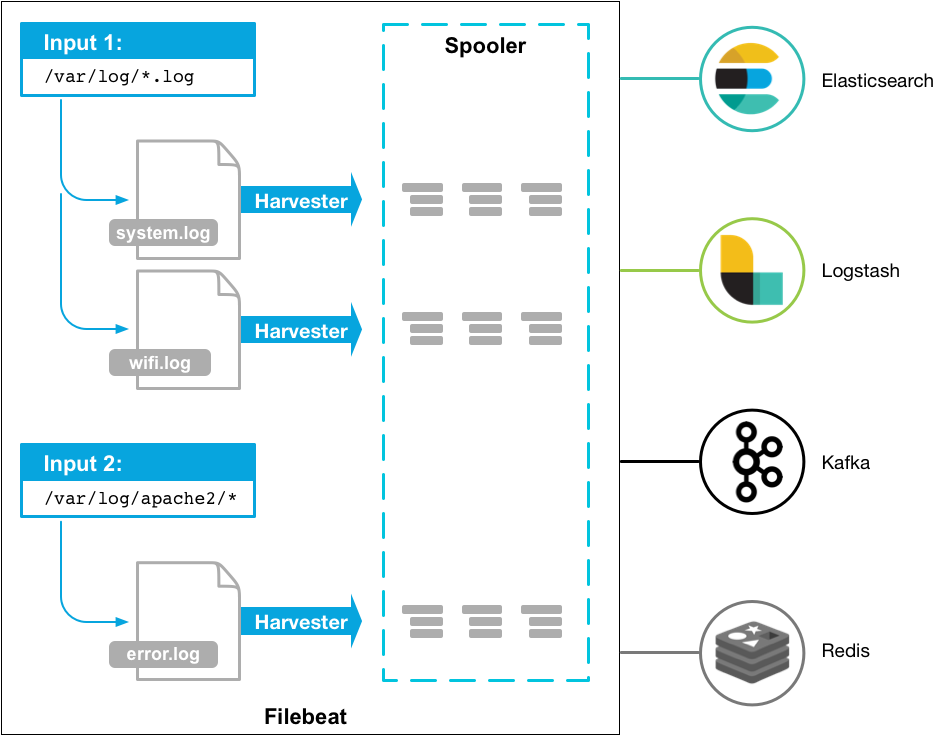
Filebeat是如何工作的
两个组件:inputs harvesters 这两个组件一起工作跟踪文件并将事件发送到指定的输出。
harvesters(收割机,谷歌翻译的,哈哈,也可以这么理解,因为是去收集文件并传输确认也像收割机)
职责:harvesters负责收取单个文件的内容。harvesters读取文件,一行一行的读取文件,并将内容发送到Output。
每个文件启动一个harvester,harvester负责打开或关闭一个文件,这意味着当harvest运行时文件描述符处于打开状态。如果文件在获取过程中被移走了或者被重名了,Filebeat会继续读取文件,这样做的副作用是磁盘上的空间被一直占用着直到harvester被关闭。默认情况下,Filebeat会保持打开状态直到close_inactive信号到达。
input
职责:找到所有的读取来源和管理harvesters
假如文件来源是log,那么input会找到所有定义下匹配的文件并且给每个文件开启一个harvester,如:
filebeat.inputs: - type: log paths: - /var/log/*.log - /var/path2/*.log
Filebeat目前支持的输入类型
Log、Stdin、Redis、UDP、Docker、TCP、Syslog、NetFlow,每个输入类型可以定义多次,log输入会检查每个文件是否需要启动harvester,是否已经启动或者可以忽略这个文件,当harvester关闭后只有文件大小被改变新的行才会拾取新的行。
Filebeat如何保持文件的状态
1、Filebeat保持每个文件的状态,并经常将该状态刷新到磁盘上的注册表文件;这个状态用于记住harvester的最后偏移量,并确保发送所有日志行。如果对于Output像Elasticsearch或者Logstach,送达不到,那么Filebeat继续跟踪最后的发送行,一旦Output再次可用,它将继续读取文件。
2、Filebeat运行时,状态信息也会保存在每个input的内存中;当Filebeat重启后,注册表文件中的状态用于重建数据,Filebeat在最后已知的位置使harvester继续收集日志。
3、对于每一个输入,Filebeat保存每个找到的文件的状态。因为文件可能会被重命名或者移动,文件名和路径不足以标识文件。对于每一个文件,Filebeat会存储唯一标识符以检测文件是否在之前获取。
Filebeat是如何确保至少一次交付的
1、Filebeat保证事件将至少一次传输到配置的输出并且不会有数据丢失,Filebeat能够实现这种行为是因为他将每个事件的传递状态存储存储在注册表文件中。
2、在定义的Output被阻塞且未确认所有的事件的情况下,Filebeat将会继续尝试发送事件直到输出确认接收到事件为止。
3、如果Filebeat在发送事件的过程中关闭,他不会在关闭之前等待Output确认所有事件。发送到Output的任何事件,在Filebeat关闭之前没有得到确认,当Filebeat重新启动时会再次发送。这就确保任何事件至少被发送了一次,但有可能你会发送重复的事件到Output。可以通过设置shutdown_timeout选项让Filebeat在关闭之前等待一定的时间。
4、Filebeat的至少一次交互有一个限制当涉及到日志轮训和删除旧文件时,如果日志文件被写入磁盘轮询的速度快于Filebeat的处理的速度,或者当output不能使用的时候删除了文件,数据可能会丢失。在Linux上,Filebeat也有可能会因为inode的重用跳过一些行。
自己想的的几个问题(暂时未去验证)
1、Input正常,Output不正常,当Output正常后,是怎么发送收集到的数据的,是从Output不正常时最后确认收到的文件事件后,从没有确认的那一个开始传送,还是从不正常之后,到正常这段时间的数据都不会再有?
2、Input不正常,Output正常,当Input正常后,数据是怎么发送的
官方文档:https://www.elastic.co/guide/en/beats/filebeat/current/how-filebeat-works.html#harvester
作者:李先生
-------------------------------------------
个性签名:在平凡中坚持前行,总有一天会遇见不一样的自己!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!



微信公众号 微信打赏 支付宝打赏
posted on 2019-02-23 09:50 Captain_Li 阅读(1758) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号