

对数据集进行最优分箱和WOE转换
对数据集分箱的方式三种,等宽等频最优,下面介绍对数据集进行最优分箱,分箱的其他介绍可以查看其他的博文,具体在这就不细说了:
大体步骤:
- 加载数据;
- 遍历所有的feature, 分别处理离散和连续特征;
- 得到IV树;
- 递归遍历IV树,得到分割点构成的列表;
- 去掉不符合条件的分割点,得到最优分割点列表;
- 遍历最优分割点列表,将最优分割点信息注入到InfoValue对象中;
- 将每个特征构成的对象放到规则集中(是一个列表);
- 通过规则集对test进行WOE转换;
- 将规则集存一份到csv中,可以直观的查看;
- dump一份形成model以供转换数据集使用。
woe.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
import os
import numpy as np
import pandas as pd
import copy
from sklearn.externals import joblib
from sklearn.model_selection import KFold
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
__all__ = ["WoeFeatureProcess"]
class DisInfoValue(object):
"""
用来存储离散特征woe转化信息
"""
def __init__(self):
self.var_name = None
self.origin_value = []
self.woe_before = []
class Node(object):
"""
Tree Node Class
"""
def __init__(self, var_name=None, iv=0, split_point=None, right=None, left=None):
self.var_name = var_name
self.iv = iv
self.split_point = split_point # split points list
self.right = right # right sub tree
self.left = left # left sub tree
class InfoValue(object):
def __init__(self):
self.var_name = []
self.split_list = []
self.iv = 0
self.woe_list = []
self.iv_list = []
self.is_discrete = 0
self.sub_total_sample_num = []
self.positive_sample_num = []
self.negative_sample_num = []
self.sub_total_num_percentage = []
self.positive_rate_in_sub_total = []
self.negative_rate_in_sub_total = []
def init(self, civ):
self.var_name = civ.var_name
self.split_list = civ.split_list
self.iv = civ.iv
self.woe_list = civ.woe_list
self.iv_list = civ.iv_list
self.is_discrete = civ.is_discrete
self.sub_total_sample_num = civ.sub_total_sample_num
self.positive_sample_num = civ.positive_sample_num
self.negative_sample_num = civ.negative_sample_num
self.sub_total_num_percentage = civ.sub_total_num_percentage
self.positive_rate_in_sub_total = civ.positive_rate_in_sub_total
self.negative_rate_in_sub_total = civ.negative_rate_in_sub_total
class WoeFeatureProcess(object):
def __init__(self, continuous_fillna=-1, discrete_fillna='missing', alpha=0.05,
train_start='2017-09-01', train_end='2017-12-01', test_start='2017-12-01', test_end='2017-12-31'):
self.__conf = None
self.__dataset_all = None
self.__dataset_train = None
self.__dataset_test = None
self.__dataset_rest = None
self.__variable_type = None
self.__bin_var_list = []
self.__discrete_var_list = []
self.__identify_var_list = []
self.__model_var_list = []
self.__rule_list = [] # 里面方的是InfoValue对象
self.__continuous_fillna = continuous_fillna
self.__discrete_fillna = discrete_fillna
self.__train_start = train_start
self.__train_end = train_end
self.__test_start = test_start
self.__test_end = test_end
self.__alpha = alpha
def load_file(self, config_path=None, data_path=None):
"""
load dataset and split dataframe into train , test subsets and rest set
:param config_path:
:param data_path:
:return:
"""
if os.path.isfile(config_path) and os.path.isfile(data_path):
config_path = config_path
data_path = data_path
else:
raise ValueError("some file path does not exist, please check config_path, data_path")
self.__conf = pd.read_csv(config_path)
self.__variable_type = dict(zip(self.__conf['var_name'], self.__conf['var_dtype']))
self.__bin_var_list = self.__conf[(self.__conf['is_candidate'] == 1)
& (self.__conf['is_tobe_bin'] == 1)]['var_name'] # 连续特征
self.__discrete_var_list = self.__conf[(self.__conf['is_candidate'] == 1)
& (self.__conf['is_tobe_bin'] == 0)]['var_name'] # 离散特征
self.__model_var_list = self.__conf[self.__conf['is_modelfeature'] == 1]['var_name'] # 入模特征
self.__identify_var_list = self.__conf[self.__conf['is_user_identify'] == 1][
'var_name'] # 用户标识
self.__dataset_all = pd.read_csv(data_path, nrows=50000).rename(columns={'overdue_day': 'target'})
self.__dataset_all['target'] = self.__dataset_all['target'].apply(lambda x: 1 if x > 7 else 0)
self.__dataset_all['create_time'] = self.__dataset_all['create_time'].astype(str)
self.__dataset_all['create_time'] = self.__dataset_all['create_time'].apply(
lambda x: x[:4] + '-' + x[4:6] + '-' + x[6:])
self.__fillna()
self.__change_var_dtype()
self.__dataset_train = self.__dataset_all[(self.__dataset_all['create_time'] >= self.__train_start)
& (self.__dataset_all['create_time'] < self.__train_end)]
self.__dataset_test = self.__dataset_all[(self.__dataset_all['create_time'] >= self.__test_start)
& (self.__dataset_all['create_time'] < self.__test_end)]
self.__dataset_rest = self.__dataset_all[(self.__dataset_all['create_time'] < self.__train_start)
| (self.__dataset_all['create_time'] >= self.__test_end)]
print('train: test = {}:{}'.format(self.__dataset_train.shape[0], self.__dataset_test.shape[0]))
train_bad = self.__dataset_train[self.__dataset_train['target'] == 1].shape[0]
test_bad = self.__dataset_test[self.__dataset_test['target'] == 1].shape[0]
# 训练机和测试机中坏用户占比
print('train_p: test_p = {}:{}'.format(train_bad * 1.0 / self.__dataset_train.shape[0],
test_bad * 1.0 / self.__dataset_test.shape[0]))
def fit(self, woed_train_path=None, woed_test_path=None, feature_detail_path=None, rule_pkl_path=None):
"""
根据给定的数据训练出woe规则
:param woed_train_path:
:param woed_test_path:
:param feature_detail_path:
:param rule_pkl_path:
:return:
"""
bin_var_list = [x for x in self.__bin_var_list if x in list(self.__dataset_train.columns)]
discrete_var_list = [x for x in self.__discrete_var_list if x in list(self.__dataset_train.columns)]
bad_cnt = sum(self.__dataset_train['target'])
good_cnt = len(self.__dataset_train) - sum(self.__dataset_train['target'])
min_sample = int(self.__dataset_train.shape[0] * self.__alpha)
for var in bin_var_list:
self.__rule_list.append(
self.__proc_woe_continuous(self.__dataset_train, var, bad_cnt, good_cnt, min_sample))
for var in discrete_var_list:
self.__rule_list.append(self.__proc_woe_discrete(self.__dataset_train, var, bad_cnt, good_cnt, min_sample))
# print('rule_list: ', self.__rule_list)
# test集是通过train训练出来的规则来转换的
woed_dataset_test = self.transform(self.__dataset_test, self.__rule_list)
woed_dataset_test.to_csv(woed_test_path, index=False, encoding='utf-8', float_format='%.4f') # 如果是浮点型,则保留4位有效数字
# the data that not in train and test
woed_dataset_rest = self.transform(self.__dataset_rest, self.__rule_list)
self.__eval_feature_detail(self.__rule_list, feature_detail_path)
joblib.dump(self.__rule_list, rule_pkl_path)
woed_dataset_train = self.__kfold_fit()
woed_dataset_train.to_csv(woed_train_path, index=False, encoding='utf-8', float_format='%.4f')
return pd.concat([woed_dataset_train, woed_dataset_test, woed_dataset_rest], ignore_index=1), \
woed_dataset_train, woed_dataset_test, self.__model_var_list, self.__identify_var_list
def fit_notrain(self, woed_train_path=None, woed_test_path=None, feature_detail_path=None, rule_pkl_path=None):
"""
根据训练的规则转换rest数据集
:param woed_train_path:
:param woed_test_path:
:param feature_detail_path:
:param rule_pkl_path:
:return:
"""
woed_dataset_test = pd.read_csv(woed_test_path)
woed_dataset_train = pd.read_csv(woed_train_path)
woe_rule_list = joblib.load(rule_pkl_path)
woed_dataset_rest = self.transform(self.__dataset_rest, woe_rule_list)
return pd.concat([woed_dataset_train, woed_dataset_test, woed_dataset_rest], ignore_index=1), \
woed_dataset_train, woed_dataset_test, self.__model_var_list, self.__identify_var_list
def __kfold_fit(self):
"""
train集自己跟自己玩,根据K折交叉进行循环赋值
训练出来的规则仅仅对留下来的一折有用,也仅限在这个方法里
:return:
"""
bin_var_list = [x for x in self.__bin_var_list if x in list(self.__dataset_train.columns)]
discrete_var_list = [x for x in self.__discrete_var_list if x in list(self.__dataset_train.columns)]
count = 0
kf = KFold(n_splits=3)
woed_dataset_train = pd.DataFrame()
for train_index, test_index in kf.split(self.__dataset_train):
print("count = %d" % count)
count += 1
sub_rule_list = []
sub_dataset_train = self.__dataset_train.iloc[train_index, :]
sub_dataset_test = self.__dataset_train.iloc[test_index, :]
sub_bad_cnt = sum(sub_dataset_train['target'])
sub_good_cnt = len(sub_dataset_train) - sum(sub_dataset_train['target'])
sub_min_sample = int(sub_dataset_train.shape[0] * self.__alpha)
for var in bin_var_list:
sub_rule_list.append(self.__proc_woe_continuous(
sub_dataset_train, var, sub_bad_cnt, sub_good_cnt, sub_min_sample))
for var in discrete_var_list:
sub_rule_list.append(self.__proc_woe_discrete(
sub_dataset_train, var, sub_bad_cnt, sub_good_cnt, sub_min_sample))
woed_sub_dataset_test = self.transform(sub_dataset_test, sub_rule_list)
woed_dataset_train = woed_dataset_train.append(woed_sub_dataset_test, ignore_index=True)
return woed_dataset_train
@staticmethod
def transform(df, rule_list):
"""
对数据集进行woe变换
:param df:
:param rule_list:
:return:
"""
df_copy = copy.deepcopy(df) # 完完全全开拓一个新的内存空间,原来对象任何改变对深copy之后的对象不产生任何影响
for rule in rule_list:
# continuous variable
if not rule.is_discrete:
if len(rule.woe_list) > 1:
split_list = []
split_list.append(float("-inf"))
split_list.extend(rule.split_list)
split_list.append(float("inf"))
for i in range(len(rule.woe_list)):
df_copy[rule.var_name][(df_copy[rule.var_name] > split_list[i])
& (df_copy[rule.var_name] <= split_list[i + 1])] = rule.woe_list[i]
else:
print(rule.var_name, rule.split_list)
df_copy[rule.var_name] = rule.woe_list[0]
# discrete variable
else:
split_map = {}
for i in range(len(rule.split_list)):
for j in range(len(rule.split_list[i])):
split_map[rule.split_list[i][j]] = rule.woe_list[i]
df_copy[rule.var_name] = df_copy[rule.var_name].map(split_map)
return df_copy
def __fillna(self):
"""
处理缺失值
:return: null value,replace null value inplace
"""
for var in [tmp for tmp in self.__bin_var_list]:
self.__dataset_all.loc[self.__dataset_all[var].isnull(), var] = self.__continuous_fillna
for var in [tmp for tmp in self.__discrete_var_list]:
self.__dataset_all.loc[self.__dataset_all[var].isnull(), var] = self.__discrete_fillna
def __change_var_dtype(self):
"""
通过配置文件改变特征的数据类型
:return:
"""
for vname, dtype in self.__variable_type.items():
try:
self.__dataset_all[vname] = self.__dataset_all[vname].astype(dtype)
except Exception as e:
print('[error]', vname, dtype, e)
@staticmethod
def __eval_feature_detail(info_value_list, feature_detail_path):
"""
将 InfoValue list 变成 Dataframe,作用是存一份规则的集合到csv文件中
:param info_value_list: Instance list of Class InfoValue
:param feature_detail_path:specify the Dataframe to csv file path
:return:
"""
rst = info_value_list
format_rst = []
for kk in range(0, len(rst)):
split_list = []
if rst[kk].split_list:
if not rst[kk].is_discrete:
split_list.append('(-INF,' + str(rst[kk].split_list[0]) + ']')
for i in range(0, len(rst[kk].split_list) - 1):
split_list.append('(' + str(rst[kk].split_list[i]) + ',' + str(rst[kk].split_list[i + 1]) + ']')
split_list.append('(' + str(rst[kk].split_list[len(rst[kk].split_list) - 1]) + ',+INF)')
else:
split_list = rst[kk].split_list
else:
split_list.append('(-INF,+INF)')
# merge into dataframe
columns = ['var_name', 'split_list', 'sub_total_sample_num', 'positive_sample_num', 'negative_sample_num',
'sub_total_num_percentage', 'positive_rate_in_sub_total', 'negative_rate_in_sub_total', 'woe_list', 'bin_iv', 'iv']
rowcnt = len(rst[kk].iv_list)
if rowcnt < len(split_list):
split_list = split_list[:rowcnt]
var_name = [rst[kk].var_name] * rowcnt
iv = [rst[kk].iv] * rowcnt
iv_list = rst[kk].iv_list
woe_list = rst[kk].woe_list
r = pd.DataFrame({'var_name': var_name,
'bin_iv': iv_list,
'woe_list': woe_list,
'split_list': split_list,
'iv': iv,
'sub_total_sample_num': rst[kk].sub_total_sample_num,
'sub_total_num_percentage': rst[kk].sub_total_num_percentage,
'positive_sample_num': rst[kk].positive_sample_num,
'negative_sample_num': rst[kk].negative_sample_num,
'positive_rate_in_sub_total': rst[kk].positive_rate_in_sub_total,
'negative_rate_in_sub_total': rst[kk].negative_rate_in_sub_total
}, columns=columns)
format_rst.append(r)
cformat_rst = pd.concat(format_rst).sort_values(by=['iv'], ascending=0)
file_name = feature_detail_path if isinstance(feature_detail_path, str) else None
cformat_rst.to_csv(file_name, index=False, encoding='utf-8', float_format='%.4f')
@staticmethod
def __check_point(df, var, split, min_sample):
"""
检测分割点会不会造成一些节点样本量过小;
如果样本量的大小小于总样本量的5%,就会merge相邻的两个节点知道样本量大小超过5%
"""
new_split = []
if split is not None and len(split) > 0:
new_split.append(split[0])
# 不符合条件的分割点会从split集里面去掉形成新的split集
pdf = df[df[var] <= split[0]]
if pdf.shape[0] < min_sample or len(pdf['target'].unique()) <= 1:
new_split.pop()
for i in range(len(split) - 1):
pdf = df[(df[var] > split[i]) & (df[var] <= split[i + 1])]
if pdf.shape[0] < min_sample or len(pdf['target'].unique()) <= 1:
continue
else:
new_split.append(split[i + 1])
# 如果剩下的样本量太小或者仅仅只含有一个正例样本或者一个负例样本,那么就去掉最后一个分割点
if len(new_split) > 1 and (df[df[var] >= new_split[-1]].shape[0] < min_sample or
len(df[df[var] >= new_split[-1]]['target'].unique()) <= 1):
new_split.pop()
# 如果分割列表只有一个值,直接赋值给新的分割列表
if not new_split:
new_split = split
else:
pass
return new_split
@staticmethod
def __calulate_iv(df, bt, gt):
"""
计算没有分割点的iv和woe
:param df:
:param bt:
:param gt:
:return:
"""
groupdetail = {}
bt_sub = sum(df['target'])
bri = (bt_sub + 0.0001) * 1.0 / (bt + 1e-6)
gt_sub = df.shape[0] - bt_sub
gri = (gt_sub + 0.0001) * 1.0 / (gt + 1e-6)
groupdetail['woei'] = np.log(bri / gri)
groupdetail['ivi'] = (bri - gri) * np.log(bri / gri)
groupdetail['sub_total_num_percentage'] = df.shape[0] * 1.0 / (bt + gt)
groupdetail['positive_sample_num'] = bt_sub
groupdetail['negative_sample_num'] = gt_sub
groupdetail['positive_rate_in_sub_total'] = bt_sub * 1.0 / df.shape[0]
groupdetail['negative_rate_in_sub_total'] = gt_sub * 1.0 / df.shape[0]
return groupdetail
@staticmethod
def __calculate_iv_split(df, var, split_point, bt, gt):
"""
计算给点特征和分割点的iv值
:param df:
:param var: 需要计算的特征
:param split_point:
:param bt:
:param gt:
:return:
"""
dataset_r = df[df.loc[:, var] > split_point][[var, 'target']]
dataset_l = df[df.loc[:, var] <= split_point][[var, 'target']]
r1_cnt = sum(dataset_r['target'])
r0_cnt = dataset_r.shape[0] - r1_cnt
l1_cnt = sum(dataset_l['target'])
l0_cnt = dataset_l.shape[0] - l1_cnt
if r0_cnt == 0 or r1_cnt == 0 or l0_cnt == 0 or l1_cnt == 0:
return 0, 0, 0, dataset_l, dataset_r
lbr = (l1_cnt + 0.0001) * 1.0 / bt
lgr = (l0_cnt + 0.0001) * 1.0 / gt
woel = np.log(lbr / lgr)
ivl = (lbr - lgr) * woel
rbr = (r1_cnt + 0.0001) * 1.0 / bt
rgr = (r0_cnt + 0.0001) * 1.0 / gt
woer = np.log(rbr / rgr)
ivr = (rbr - rgr) * woer
iv = ivl + ivr
return iv, ivl, ivr, dataset_l, dataset_r
def __binning_split(self, df, var, bt, gt, min_sample):
"""
对指定的特征在给定的条件下进行最优划分,构造该特征的分割树(由Node对象构成)
:param df:
:param var: 需要分箱的特征
:param bt: bad_cnt
:param gt: good_cnt
:param min_sample:
:return:
"""
# iv_var = InfoValue()
# 计算当前节点没有切分之前的IV值
groupdetail = self.__calulate_iv(df, bt, gt)
woei, ivi = groupdetail['woei'], groupdetail['ivi']
# 如果连续变量的取值小于5,不适合最优分箱算法,直接将特征的取值当作分割点即可
if np.unique(df[var]).__len__() <= 5:
split = list(np.unique(df[var]))
split.sort()
# 分割点检测和处理
split = self.__check_point(df, var, split, min_sample)
split.sort()
# iv_var.split_list = split
return Node(split_point=split, iv=ivi)
# 默认对每个节点分100箱,遍历分箱,找到这个节点的最优左子树和右子树,分割点
percent_value = list(np.unique(np.percentile(df[var], range(100))))
percent_value.sort()
if percent_value.__len__() <= 2:
# iv_var.split_list = list(np.unique(percent_value)).sort()
return Node(split_point=percent_value, iv=ivi)
bestSplit_iv = 0
bestSplit_ivl = 0
bestSplit_ivr = 0
bestSplit_point = []
bestSplit_dataset_l = None
bestSplit_dataset_r = None
for point in percent_value:
# 如果仅仅有一个样本或者一个负例样本,则直接跳过
if len(df[df[var] > point]['target'].unique()) == 1 \
or len(df[df[var] <= point]['target'].unique()) == 1 \
or df[df[var] > point].shape[0] < min_sample \
or df[df[var] <= point].shape[0] < min_sample:
continue
iv, ivl, ivr, dataset_l, dataset_r = self.__calculate_iv_split(df, var, point, bt, gt)
if iv > bestSplit_iv:
bestSplit_iv = iv
bestSplit_ivl = ivl
bestSplit_ivr = ivr
bestSplit_point = point
bestSplit_dataset_l = dataset_l
bestSplit_dataset_r = dataset_r
# 如果符合最优分割的条件,则进行递归迭代,直到满足条件退出,由此递归构建出整棵树
if bestSplit_iv > ivi * (1 + self.__alpha) and bestSplit_dataset_r.shape[0] > min_sample \
and bestSplit_dataset_l.shape[0] > min_sample:
presplit_right = Node()
presplit_left = Node()
if bestSplit_dataset_l.shape[0] < min_sample \
or len(bestSplit_dataset_l['target'].unique()) == 1:
presplit_left.iv = bestSplit_ivl
left = presplit_left
else:
left = self.__binning_split(bestSplit_dataset_l, var, bt, gt, min_sample)
if bestSplit_dataset_r.shape[0] < min_sample \
or len(bestSplit_dataset_r['target'].unique()) == 1:
presplit_right.iv = bestSplit_ivr
right = presplit_right
else:
right = self.__binning_split(bestSplit_dataset_r, var, bt, gt, min_sample)
# 中间节点,证明其还能满足条件形成左右子树,此处形成的是内部节点
return Node(var_name=var, split_point=bestSplit_point, iv=ivi, left=left, right=right)
else:
# 返回当前节点作为叶子节点
return Node(var_name=var, iv=ivi)
def __search(self, tree, split_list):
"""
递归调用查询树节点,返回叶子节点的分割点
:param tree:
:param split_list:
:return: split points list
"""
if isinstance(tree.split_point, list):
split_list.extend(tree.split_point)
else:
split_list.append(tree.split_point)
if tree.left is not None:
self.__search(tree.left, split_list)
if tree.right is not None:
self.__search(tree.right, split_list)
return split_list
def __format_iv_split(self, df, var, split_list, bt, gt):
"""
给定dataset DataFrame和分割点计算相关指标值放在InfoValue实例中
简单来说是将规则注入到InfoValue对象中
:param df:
:param var:
:param split_list:
:param bt:
:param gt:
:return:
"""
civ = InfoValue()
civ.var_name = var
civ.split_list = split_list
civ.sub_total_sample_num = []
civ.positive_sample_num = []
civ.negative_sample_num = []
civ.sub_total_num_percentage = []
civ.positive_rate_in_sub_total = []
for i in range(len(split_list)):
dfi = df[df[var] <= split_list[i]]
gd = self.__calulate_iv(dfi, bt, gt)
woei, ivi = gd['woei'], gd['ivi']
civ.woe_list.append(woei)
civ.iv_list.append(ivi)
civ.sub_total_sample_num.append(dfi.shape[0])
civ.positive_sample_num.append(gd['positive_sample_num'])
civ.negative_sample_num.append(gd['negative_sample_num'])
civ.sub_total_num_percentage.append(gd['sub_total_num_percentage'])
civ.positive_rate_in_sub_total.append(gd['positive_rate_in_sub_total'])
civ.negative_rate_in_sub_total.append(gd['negative_rate_in_sub_total'])
# the last split point
dfi = df[df[var] > split_list[-1]]
if dfi.shape[0] > 0:
gd = self.__calulate_iv(dfi, bt, gt)
woei, ivi = gd['woei'], gd['ivi']
civ.woe_list.append(woei)
civ.iv_list.append(ivi)
civ.sub_total_sample_num.append(dfi.shape[0])
civ.positive_sample_num.append(gd['positive_sample_num'])
civ.negative_sample_num.append(gd['negative_sample_num'])
civ.sub_total_num_percentage.append(gd['sub_total_num_percentage'])
civ.positive_rate_in_sub_total.append(gd['positive_rate_in_sub_total'])
civ.negative_rate_in_sub_total.append(gd['negative_rate_in_sub_total'])
civ.iv = sum(civ.iv_list)
return civ
def __proc_woe_discrete(self, df, var, bt, gt, min_sample):
"""
离散变量的woe转换
:param df:
:param var:
:param bt: bad_cnt
:param gt: good_cnt
:param min_sample:
:return:
"""
print('process discrete variable: {}'.format(var).center(80, '-'))
df = df[[var, 'target']]
div = DisInfoValue()
div.var_name = var
rdict = {}
cpvar = df[var]
for var_value in np.unique(df[var]):
df_temp = df[df[var] == var_value]
gd = self.__calulate_iv(df_temp, bt, gt)
woei, ivi = gd['woei'], gd['ivi']
div.origin_value.append(var_value)
div.woe_before.append(woei)
rdict[var_value] = woei
cpvar = cpvar.map(rdict)
df[var] = cpvar
iv_tree = self.__binning_split(df, var, bt, gt, min_sample)
# Traversal tree, get the segmentation point
split_list = []
self.__search(iv_tree, split_list)
split_list = list(np.unique([x for x in split_list if x is not None]))
split_list.sort()
# Segmentation point checking and processing
split_list = self.__check_point(df, var, split_list, min_sample)
split_list.sort()
civ = self.__format_iv_split(df, var, split_list, bt, gt)
civ.is_discrete = 1
split_list_temp = []
split_list_temp.append(float("-inf"))
split_list_temp.extend(split_list)
split_list_temp.append(float("inf"))
a = []
for i in range(len(split_list_temp) - 1):
temp = []
for j in range(len(div.origin_value)):
if (div.woe_before[j] > split_list_temp[i]) \
and (div.woe_before[j] <= split_list_temp[i + 1]):
temp.append(div.origin_value[j])
if temp != []:
a.append(temp)
civ.split_list = a
return civ
def __proc_woe_continuous(self, df, var, bt, gt, min_sample):
"""
连续变量的woe转换
:param df:
:param var:
:param bt: bad_cnt
:param gt: good_cnt
:param min_sample: 最小样本数
:return:
"""
print('process continuous variable: {}'.format(var).center(80, '-'))
df = df[[var, 'target']]
iv_tree = self.__binning_split(df, var, bt, gt, min_sample)
# 遍历树得到分割点
split_list = []
self.__search(iv_tree, split_list)
split_list = list(np.unique([x for x in split_list if x is not None]))
split_list.sort()
# 不同情况都要check一下,去掉不符合条件的分割点
split_list = self.__check_point(df, var, split_list, min_sample)
split_list.sort()
civ = self.__format_iv_split(df, var, split_list, bt, gt)
return civ
conf.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
import os
import datetime
class PathConf(object):
"""
有些配置没什么用,自己舍去
"""
def __init__(self, date=str(datetime.date.today()), f_conf='test.conf', source='test.csv'):
self.conf = os.path.join(os.getcwd(), 'conf')
self.source = os.path.join(os.getcwd(), 'source')
self.result = os.path.join(os.getcwd(), 'result')
self.tmp = os.path.join(os.getcwd(), 'tmp')
self.rec_date = date
self.config_path = os.path.join(self.conf, f_conf)
self.data_path = os.path.join(self.source, source)
self.woed_train_path = os.path.join(self.tmp, 'woed_train.csv')
self.woed_test_path = os.path.join(self.tmp, 'woed_test.csv')
self.feature_detail_path = os.path.join(self.result, 'detail.csv')
self.rule_pkl_path = os.path.join(self.result, 'woe_rule.pkl')
self.model_pkl_path = os.path.join(self.result, 'model.pkl')
self.user_score_path = os.path.join(self.result, 'score_%s.csv' % self.rec_date)
self.user_score_nohead_path = os.path.join(self.result, 'score_%s_nohead.csv' % self.rec_date)
self.user_score_stat_path = os.path.join(self.result, 'score_stat_%s.csv' % self.rec_date)
self.report_name = '%s_report.html' % self.rec_date
self.report_path = os.path.join(self.result, '%s_report.html' % self.rec_date)
woe_executor.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
from woe import WoeFeatureProcess
from conf import PathConf
import datetime
from sklearn.externals import joblib
pd.options.mode.chained_assignment = None
pd.set_option('precision', 4)
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
if __name__ == '__main__':
date = str(datetime.date.today() - datetime.timedelta(days=1))
"""
basic = datetime.datetime.strptime(date, "%Y-%m-%d").date() - datetime.timedelta(days=105)
train_start = str(basic - datetime.timedelta(days=120))
train_end = str(basic - datetime.timedelta(days=31))
test_start = str(basic - datetime.timedelta(days=30))
test_end = str(basic - datetime.timedelta(days=0))
"""
train_start = '2017-07-01'
train_end = '2018-06-15'
test_start = '2018-06-16'
test_end = '2018-07-15'
path = PathConf(date=date, f_conf='b_card_config.conf', source="b_card_features_df_head.csv")
logger = logger(log_name='logs', log_level=logging.INFO, log_dir='logs', file_name='log_python.log').getlog()
logger.info('starting...')
logger.info('start loading data...')
print('start loading data'.center(80, '='))
woe = WoeFeatureProcess(train_start=train_start, train_end=train_end,
test_start=test_start, test_end=test_end, alpha=0.05)
woe.load_file(path.config_path, path.data_path)
logger.info('start training woe rule...')
print('start training woe rule'.center(80, '='))
dataset_all, dataset_train, dataset_test, model_var_list, identify_var_list = woe.fit(path.woed_train_path,
path.woed_test_path,
path.feature_detail_path,
path.rule_pkl_path)
print('model features: %s' % len(model_var_list))
test.conf (head的详细解释看代码内部注释)
is_modelfeature,is_candidate,is_tobe_bin,is_user_identify,var_dtype,var_name 0,0,0,1,float64,user_id 1,1,0,0,int64,1000001 1,1,1,0,float64,1000002 1,1,0,0,int64,1000017 1,1,0,0,int64,004 1,1,1,0,float64,1005001 1,1,1,0,float64,1007005 1,1,1,0,float64,1007006 1,1,1,0,float64,1007007 1,1,1,0,float64,1007008 1,1,1,0,float64,1007009 1,1,1,0,float64,1007011 1,1,1,0,float64,1007012 1,1,1,0,float64,014 1,1,0,0,int64,015 1,1,0,0,int64,017 1,1,0,0,int64,019 1,1,1,0,float64,1003111 1,1,1,0,float64,1003112 1,1,1,0,float64,1003106 1,1,1,0,float64,1003108 1,1,1,0,float64,030 1,1,1,0,float64,1001000 1,1,1,0,float64,1002004 1,1,1,0,float64,1001005 1,1,1,0,float64,1001007 1,1,1,0,float64,1001008 1,1,1,0,float64,1001009 0,0,0,0,int64,target
根据树进行最优分箱的逻辑图如下:
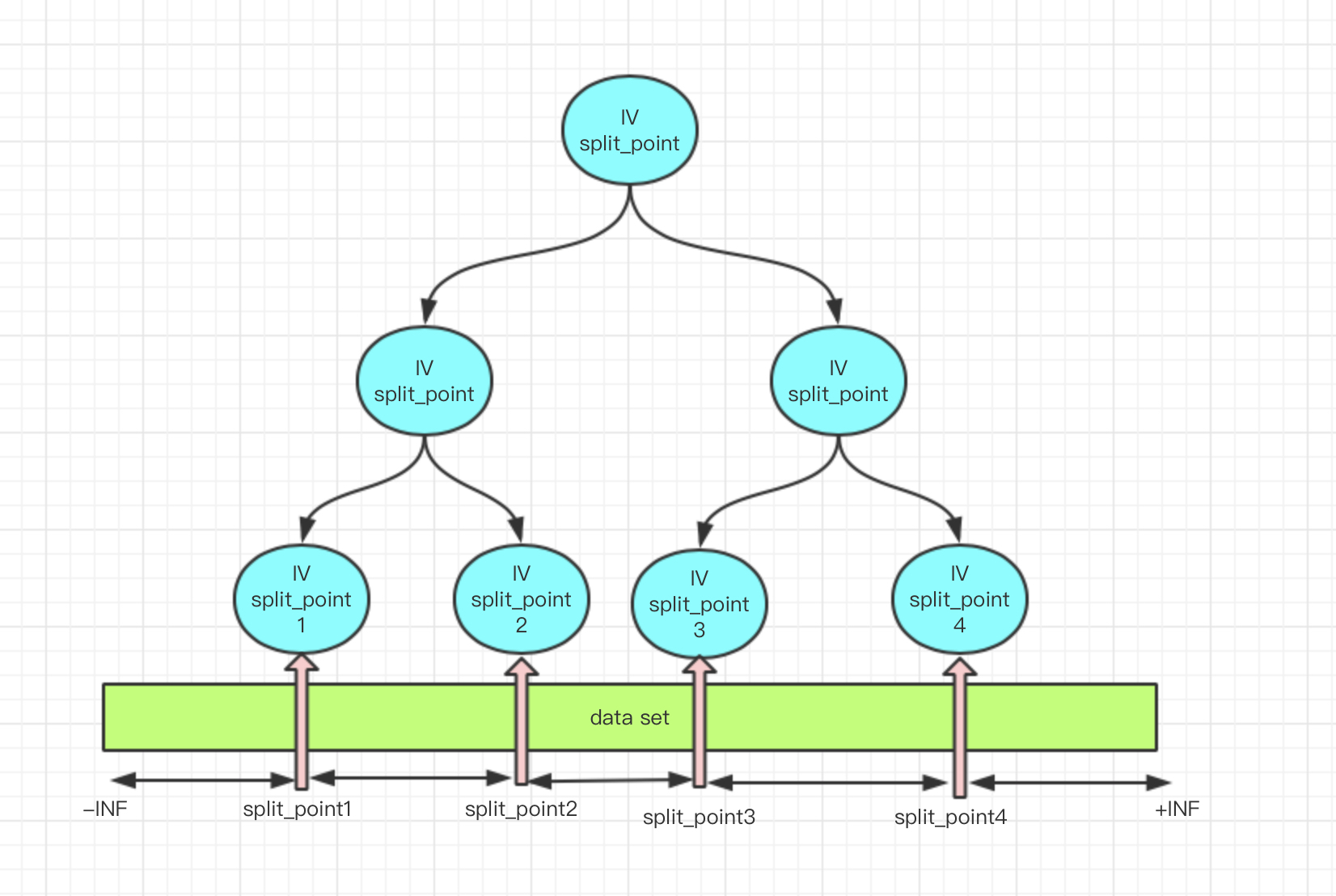
分箱结果示例:
var_name,split_list,sub_total_sample_num,positive_sample_num,negative_sample_num,sub_total_num_percentage,positive_rate_in_sub_total,negative_rate_in_sub_total,woe_list,bin_iv,iv 1001008,"(3.0,4.0]",10515,435,10080,0.2246,0.0414,0.9586,-0.8707,0.1202,1.2219 1001008,"(21.0,31.0]",43355,3505,39850,0.9260,0.0808,0.9192,-0.1586,0.0218,1.2219 1001008,"(8.0,9.0]",26336,1413,24923,0.5625,0.0537,0.9463,-0.5978,0.1579,1.2219 1001008,"(7.0,8.0]",21634,1120,20514,0.4621,0.0518,0.9482,-0.6355,0.1444,1.2219 1001008,"(6.0,7.0]",19284,954,18330,0.4119,0.0495,0.9505,-0.6833,0.1461,1.2219 1001008,"(5.0,6.0]",16777,791,15986,0.3583,0.0471,0.9529,-0.7339,0.1437,1.2219 1001008,"(4.0,5.0]",13787,625,13162,0.2945,0.0453,0.9547,-0.7750,0.1296,1.2219 1001008,"(2.0,3.0]",7025,278,6747,0.1500,0.0396,0.9604,-0.9169,0.0875,1.2219 1001008,"(-INF,2.0]",3392,126,3266,0.0724,0.0371,0.9629,-0.9827,0.0473,1.2219 1001008,"(31.0,+INF)",3465,870,2595,0.0740,0.2511,0.7489,1.1795,0.1624,1.2219 1001008,"(9.0,21.0]",39747,2863,36884,0.8489,0.0720,0.9280,-0.2836,0.0609,1.2219
参考:
https://github.com/boredbird/woe/tree/master/woe

 浙公网安备 33010602011771号
浙公网安备 33010602011771号