


Spark安装
Spark环境搭建-Local
基本原理
在本地使用单机多线程模拟Spark集群中的各个角色

Local模式就是常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task
- 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。
- 通常Cpu有几个Core,就指定几个线程,最大化利用计算能力.
- 其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N,则默认是1个线程(该线程有1个core)。
- 如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.按照Cpu最多的Cores设置线程数
图解:

安装包下载
目前Spark最新稳定版本:课程中使用目前Spark最新稳定版本:3.1.x系列
https://spark.apache.org/docs/3.1.2/index.html
★注意1:
Spark3.0+基于Scala2.12
http://spark.apache.org/downloads.html

★注意2:
目前企业中使用较多的Spark版本还是Spark2.x,如Spark2.2.0、Spark2.4.5都使用较多,但未来Spark3.X肯定是主流,毕竟官方高版本是对低版本的兼容以及提升
http://spark.apache.org/releases/spark-release-3-0-0.html

基础操作
- 下载:server1上下载spark压缩包
|
cd /usr/local wget https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz --no-check-certificate |
2.解压:
3.改权限:如果有权限问题,可以修改为root,方便学习时操作,实际中使用运维分配的用户和权限即可
|
chown -R root spark-3.1.2-bin-hadoop3.2 chgrp -R root spark-3.1.2-bin-hadoop3.2 |
注意:chgrp命令用来改变文件或目录所属的用户组
4.改名或创建软链接:方便后期升级
|
ln -s /usr/local/spark-3.1.2-bin-hadoop3.2 /usr/local/spark |
5.更新环境变量
|
vim /etc/profile export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin |
查看目录结构:其中各个目录含义如下:
|
bin 可执行脚本 conf 配置文件 data 示例程序使用数据 examples 示例程序 jars 依赖 jar 包 python pythonAPI sbin 集群管理命令 yarn 整合yarn需要的东东 |
测试
运行spark-shell
●开箱即用:直接启动bin目录下的spark-shell:
|
/usr/local/spark/bin/spark-shell |
●运行成功以后,有如下提示信息:

sc:SparkContext实例对象:
spark:SparkSession实例对象
4040:Web监控页面端口号
●Spark-shell说明:
1.直接使用./spark-shell
表示使用local 模式启动,在本机启动一个SparkSubmit进程
2.还可指定参数 --master,如:
spark-shell --master local[N] 表示在本地模拟N个线程来运行当前任务
spark-shell --master local[*] 表示使用当前机器上所有可用的资源
3.不携带参数默认就是
spark-shell --master local[*]
4.后续还可以使用--master指定集群地址,表示把任务提交到集群上运行,如
./spark-shell --master spark://server1:7077,agent2:7077
5.退出spark-shell
使用 :quit
运行pyspark-shell
为什么学习PySpark?
Python 现在是 Spark 上使用最广泛的语言。PySpark 在 PyPI(Python 包索引)上的每月下载量超过 500 万次。此版本改进了其功能和可用性,包括重新设计带有 Python 类型提示的 Pandas UDF API、新的 Pandas UDF 类型和更多 Pythonic 错误处理。
参考链接:https://spark.apache.org/releases/spark-release-3-0-0.html
执行pyspark也就是使用python语言操作Spark集群,在安装完Spark基础环境之后,我们还需要安装python环境,而今支持python环境最佳的环境就是Anaconda,避免再去安装的单独的python发行版,因此Anaconda也称之为数据学科必备python环境。
接下来首先学习PySpark安装以及Anaconda安装及基本使用。
PySpark安装
PySpark安装
首先PySpark需要从PyPi上面安装,如下URL:https://pypi.org/project/pyspark/#files

若安装PySpark需要首先具备Python环境,这里使用Anaconda环境,安装过程如下:
Linux的Anaconda安装
安装版本:https://www.anaconda.com/distribution/#download-section
Python3.8.8版本:Anaconda3-2021.05-Linux-x86_64.sh
PySpark Vs Spark
同学们可能有疑问, 我们不是学的Spark框架吗? 怎么会安装一个叫做PySpark呢?
这里简单说明一下:
PySpark: 是Python的库, 由Spark官方提供. 专供Python语言使用. 类似Pandas一样,是一个库
Spark: 是一个独立的框架, 包含PySpark的全部功能, 除此之外, Spark框架还包含了对R语言\ Java语言\ Scala语言的支持. 功能更全. 可以认为是通用Spark。
|
功能 |
PySpark |
Spark |
|
底层语言 |
Scala(JVM) |
Scala(JVM) |
|
上层语言支持 |
Python |
Python\Java\Scala\R |
|
集群化\分布式运行 |
支持 |
支持 |
|
定位 |
Python库 (客户端) |
标准框架 (客户端和服务端) |
|
是否可以Daemon运行 |
No |
Yes |
|
使用场景 |
生产环境集群化运行 |
生产环境集群化运行 |
我们先从安装PySpark开始
Anaconda安装步骤
cd /usr/local 2.安装anaconda,执行下列命令 bash Anaconda3-2024.02-1-Linux-x86_64.sh 3.在安装过程中会显示配置路径 Prefix=/root/anaconda3/ 4.安装完之后,配置环境变量 vim /etc/profile ##增加如下配置 export ANACONDA_HOME=/root/anaconda3/bin export PATH=$PATH:$ANACONDA_HOME/bin source /etc/profile 5.重启所有的Crt窗口,运行python,如果仍是Centos自带的python信息,必须重启Crt窗口 |
该部分通过下述步骤完成安装。Anaconda是一个数据科学环境,可以不需要在安装任何python环境支持下使用,而且Anaconda内部集成了多达180+多的工具包可以很好帮助到数据分析和数据科学任务的处理。
Anaconda启动并测试
输入Python启动:

测试:

注意:如果有问题请切记修改
|
sudo vim ~/.bashrc export PATH=~/anaconda3/bin:$PATH |
Anaconda相关组件介绍
Anaconda(水蟒):是一个科学计算软件发行版,集成了大量常用扩展包的环境,包含了 conda、Python 等 180 多个科学计算包及其依赖项,并且支持所有操作系统平台。
- 安装包:pip install xxx,conda install xxx
- 卸载包:pip uninstall xxx,conda uninstall xxx
- 升级包:pip install upgrade xxx,conda update xxx
Jupyter Notebook:启动命令
|
jupyter notebook |
功能如下:
- Anaconda自带,无需单独安装
- 实时查看运行过程
- 基本的web编辑器(本地)
- ipynb 文件分享
- 可交互式
- 记录历史运行结果
修改jupyter显示的文件路径:
通过jupyter notebook --generate-config命令创建配置文件,之后在进入用户文件夹下面查看.jupyter隐藏文件夹,修改其中文件jupyter_notebook_config.py的202行为计算机本地存在的路径。
IPython:
命令:ipython,其功能如下
1.Anaconda自带,无需单独安装
2.Python的交互式命令行 Shell
3.可交互式
4.记录历史运行结果
5.及时验证想法
Spyder:
命令:spyder,其功能如下
1.Anaconda自带,无需单独安装
2.完全免费,适合熟悉Matlab的用户
3.功能强大,使用简单的图形界面开发环境
下面就Anaconda中的conda命令做详细介绍和配置。
conda环境安装及配置[了解]
- conda命令及pip命令
conda管理数据科学环境,conda和pip类似均为安装、卸载或管理Python第三方包。
|
conda install 包名 pip install 包名 conda uninstall 包名 pip uninstall 包名 conda install -U 包名 pip install -U 包名 |
(2) Anaconda设置为国内下载镜像
|
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes |
(3)conda创建虚拟环境
|
conda env list conda create xxx python=版本号 #创建python3.8.8环境 activate 环境 #激活环境 deactivate 环境 #退出环境 |
PySpark安装
这里介绍三种安装方式,方式1最为简单,大家可以尝试使用。
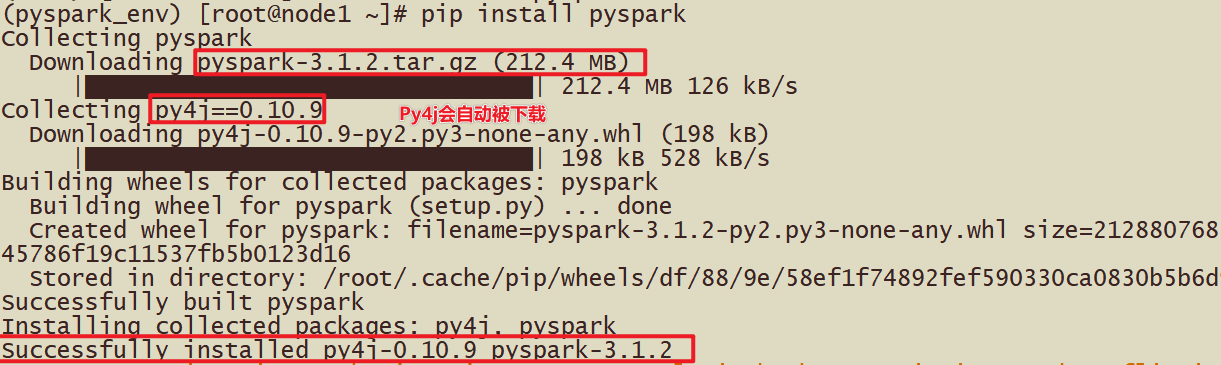
[动手安装]方式1:直接安装PySpark
安装如下:
|
使用PyPI安装PySpark如下:也可以指定版本安装 pip install pyspark 或者指定清华镜像(对于网络较差的情况): pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark # 指定清华镜像源 如果要为特定组件安装额外的依赖项,可以按如下方式安装(此步骤暂不执行,后面Sparksql部分会执行): pip install pyspark[sql] |
截图如下:

[动手安装]方式2:创建Conda环境安装PySpark
|
#从终端创建新的虚拟环境,如下所示 conda create -n pyspark_env python=3.8 #创建虚拟环境后,它应该在 Conda 环境列表下可见,可以使用以下命令查看 conda env list #现在使用以下命令激活新创建的环境: conda activate pyspark_env #您可以在新创建的环境中通过使用PyPI安装PySpark来安装pyspark,例如如下。它将pyspark_env在上面创建的新虚拟环境下安装 PySpark。 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark # 指定清华镜像源 #或者,可以从 Conda 本身安装 PySpark: conda install pyspark |
如下截图:


初体验-PySpark shell方式
前面的Spark Shell实际上使用的是Scala交互式Shell,实际上 Spark 也提供了一个用 Python 交互式Shell,即Pyspark。
启动命令
链接如下:http://spark.apache.org/docs/3.1.2/index.html
我们可以看到PySpark提供了对应启动脚本位于bin目录下,可以执行bin/pyspark执行

启动:
这里采用单机方式,命令如下:
|
bin/pyspark --master local[*] |
截图如下:

WordCount案例
1.准备数据
上传文件到hdfs
hadoop fs -put /root/words.txt /pydata/input/words.txt
目录如果不存在可以创建
hadoop fs -mkdir -p /pydata/input
结束后可以删除测试文件夹
hadoop fs -rm -r /pydata
2.执行WordCount
|
# 第一步、读取本地数据 封装到RDD集合,认为列表List wordsRDD = sc.textFile("hdfs://server1:8020/pydata/input/words.txt") # 第二步、处理数据 调用RDD中函数,认为调用列表中的函数 # a. 每行数据分割为单词 flatMapRDD = wordsRDD.flatMap(lambda line: line.split(" ")) # b. 转换为二元组,表示每个单词出现一次 mapRDD = flatMapRDD.map(lambda x: (x, 1)) # c. 按照Key分组聚合 resultRDD = mapRDD.reduceByKey(lambda a, b: a + b) # 第三步、输出数据 res_rdd_col2 = resultRDD.collect() # 输出到hdfs文件系统中 resultRDD.saveAsTextFile("hdfs://server1:8020/pydata/output2/") |
关键步骤截图如下:

3.查看结果文件
hadoop fs -text /pydata/output2/part*

监控页面
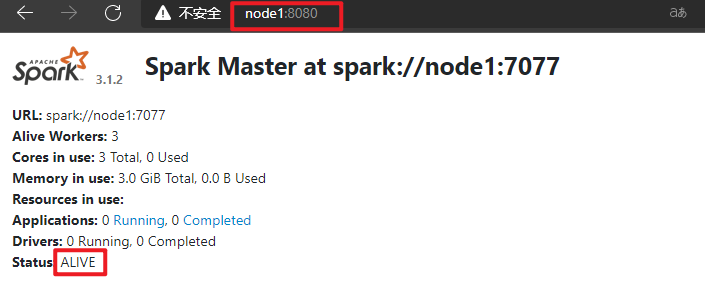
每个Spark Application应用运行时,都有一个WEB UI监控页面,默认端口号为4040,可以使用浏览器打开页面,
如下为完成的Job截图。

运行圆周率
Spark框架自带的案例Example中涵盖圆周率PI计算程序,可以使用【$SPARK_HOME/bin/spark-submit】提交应用执行,运行在本地模式。
- 自带案例jar包:【/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar】
|
SPARK_HOME=/usr/local/spark ${SPARK_HOME}/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ ${SPARK_HOME}/examples/jars/spark-examples_2.12-3.1.2.jar \ 10 |

- 提交运行PI程序
|
SPARK_HOME=/usr/local/spark ${SPARK_HOME}/bin/spark-submit \ --master local[2] \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10 |
环境搭建-Standalone
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
Standalone 架构
Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。
在StandAlone模式下, Master角色和Worker角色各自有各自的进程, 这些进程连接在一起,形成一个Spark环境, 其中:
http://spark.apache.org/docs/latest/cluster-overview.html
|
|
|
主要组件如下: |


Spark Standalone集群,类似Hadoop YARN,管理集群资源和调度资源:
- 主节点Master:
- 管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
- 从节点Workers:
- 管理每个机器的资源,分配对应的资源来运行Task;
- 每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
- 历史服务器HistoryServer(可选):
- Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
角色分析
如下图:
|
|

Master角色, 启动一个名为Master的进程, Master进程有且仅有1个(HA模式除外)
Worker角色, 启动一个名为 Worker的进程., Worker进程最少1个, 最多不限制
Master进程负责资源的管理, 并在有程序运行时, 为当前程序创建管理者Driver
Worker进程负责干活, 向Master汇报状态, 并听从程序Driver的安排,创建Executor干活
其中, 职责分配上:
- - Master进程负责资源的管理
- - 程序运行后的Driver运行在Master进程内, 负责任务的管理
- - 程序运行后的Executor运行在Worker进程内, 负责任务的计算

-
- Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。

集群规划

Standalone集群安装服务规划与资源配置:
|
server1:master agent1:worker agent2:worker agent3:worker |
官方文档:http://spark.apache.org/docs/3.1.2/spark-standalone.html
为每台机器安装Python3
由于是在分布式集群模式上运行Spark
那么,我们执行的程序,将会分配到集群的机器上去运行.
由于使用Python语言开发, 所以,集群中每一台服务器都需要有Python执行环境.
我们需要在每台机器上安装Python3环境
上传资料提供的: Anaconda3-2024.02-1-Linux-x86_64.sh到服务器
|
# 执行 sh Anaconda3-2024.02-1-Linux-x86_64.sh 在弹出选择安装位置的时候,可以设置安装路径,这里使用默认安装到/root/anaconda3 安装完成后,建立软链 ln -s /root/anaconda3/bin/python3 /usr/bin/python3 |
为每台机器,增加环境变量:
|
# SPARK_HOME export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin #Anaconda export ANACONDA_HOME=/root/anaconda3 export PATH=$PATH:$ANACONDA_HOME/bin |
修改配置并分发
Workers节点主机名
将【$SPARK_HOME/conf/slaves.template】名称命名为【slaves】,填写从节点名称。
|
##进入配置目录 cd /usr/local/spark/conf ##修改配置文件名称 mv workers.template workers vim workers ##内容如下: agent1 agent2 agent3 |
配置Master、Workers、HistoryServer
在配置文件$SPARK_HOME/conf/spark-env.sh添加如下内容:
|
## 进入配置目录 cd /usr/local/spark/conf ## 修改配置文件名称 mv spark-env.sh.template spark-env.sh ## 修改配置文件 vim spark-env.sh ## 增加如下内容: ## 设置JAVA安装目录 JAVA_HOME=/usr/local/jdk ## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop ## 指定spark老大Master的IP和提交任务的通信端口 export SPARK_MASTER_HOST=server1 export SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=3g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 ## 历史日志服务器 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://server1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true" |
注意:上述的hadoop3.3.0需要创建软连接
ln -s /usr/local/hadoop-3.3.0/ /usr/local/hadoop
创建EventLogs存储目录
启动HDFS服务,创建应用运行事件日志目录,命令如下:
|
hdfs dfs -mkdir -p /sparklog/ |
如果遇到Hadoop处理安全模式,可以按照下面方式退出Hadoop安全模式:hadoop dfsadmin -safemode leave 。
配置Spark应用保存EventLogs
将【$SPARK_HOME/conf/spark-defaults.conf.template】名称命名为【spark-defaults.conf】,填写如下内容:
|
## 进入配置目录 cd /usr/local/spark/conf ## 修改配置文件名称 mv spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf ## 添加内容如下: spark.eventLog.enabled true spark.eventLog.dir hdfs://server1:8020/sparklog/ spark.eventLog.compress true |
设置日志级别
将【$SPARK_HOME/conf/log4j.properties.template】名称命名为【log4j.properties】,修改级别为警告WARN。
|
## 进入目录 cd /usr/local/spark/conf ## 修改日志属性配置文件名称 mv log4j.properties.template log4j.properties ## 改变日志级别 vim log4j.properties |
修改内容如下:

分发到其他机器
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
|
cd /usr/local/ scp -r spark-3.1.2-bin-hadoop3.2 root@agent1:$PWD scp -r spark-3.1.2-bin-hadoop3.2 root@agent2:$PWD scp -r spark-3.1.2-bin-hadoop3.2 root@agent3:$PWD ##4个节点均创建软连接 ln -s /usr/local/spark-3.1.2-bin-hadoop3.2 /usr/local/spark |
启动服务进程
- 启动方式1:集群启动和停止
在主节点上启动spark集群
|
cd /usr/local/spark sbin/start-all.sh sbin/start-history-server.sh |
在主节点上停止spark集群
|
/usr/local/spark/sbin/stop-all.sh |
- 启动方式2:单独启动和停止
在 master 安装节点上启动和停止 master:
|
start-master.sh stop-master.sh |
在 Master 所在节点上启动和停止worker(work指的是slaves 配置文件中的主机名)
|
start-slaves.sh stop-slaves.sh |
- WEB UI页面

可以看出,配置了3个Worker进程实例,每个Worker实例为1核1GB内存,总共是2核 2GB 内存。目前显示的Worker资源都是空闲的,当向Spark集群提交应用之后,Spark就会分配相应的资源给程序使用,可以在该页面看到资源的使用情况。
- 历史服务器HistoryServer:
|
/usr/local/spark/sbin/start-history-server.sh |
WEB UI页面地址:http://server1:18080

测试
Wordcount测试
Pyspark shell脚本
|
/usr/local/spark/bin/pyspark --master spark://server1:7077 \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" |
截图如下:

- 运行程序
|
resultRDD2 = sc.textFile("hdfs://server1:8020/pydata/input/words.txt") \ .flatMap(lambda line: line.split(" ")) \ .map(lambda x: (x, 1)) \ .reduceByKey(lambda a, b: a + b) resultRDD2 .collect() |
查看文件
|
hadoop fs -text /wordcount/output2/part* |
截图如下:

- 注意
集群模式下程序是在集群上运行的,不要直接读取本地文件,应该读取hdfs上的
因为程序运行在集群上,具体在哪个节点上我们运行并不知道,其他节点可能并没有那个数据文件
- SparkContext web UI

- 查看Master主节点WEB UI界面:

提交运行圆周率
将上述运行在Local Mode的圆周率PI程序,运行在Standalone集群上,修改【--master】地址为Standalone集群地址:spark://server1:7077,具体命令如下:
|
SPARK_HOME=/usr/local/spark ${SPARK_HOME}/bin/spark-submit \ --master spark://server1:7077 \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 1 |
查看Master主节点WEB UI界面:

注意:
Python程序不像Java可以使用Maven打包,需要使用-py-files将项目达成zip包
在提交spark的时候,我们往往python工程是多个python文件,彼此之间有调用关系。
- 那如何提交python工程呢?
|
./bin/spark-submit –py-files XXXX.zip aaa.py |
- XXXX是你将你所有需要用到的python文件打包成一个zip文件
- aaa是你的python文件的main函数所在的py文件。
- 对于提交之后不同节点显示Python版本不一致
|
import os os.environ['PYTHONPATH']='python3' |
- 提交任务后遇到ascii码问题
其实我们是想要utf-8默认运行python的,但是就算你在文件里指定了#coding:utf-8仍然不行
|
import sys reload(sys) sys.setdefaultencoding('utf-8') |
环境搭建-Standalone HA
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。

高可用HA
如何解决这个单点故障的问题,Spark提供了两种方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
2.基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。

基于Zookeeper实现HA
如何解决这个单点故障的问题,Spark提供了HA方案:
即, 运行2个或多个Master进程.
其中一个是Active状态, 正常工作.
其余的为Standby状态, 待命中, 一旦Active Master出现问题, 立刻接上.
由于多个Master需要共享状态, 即大家要明确谁才是Active, 谁是Standby, 所以,这个方案需要引入Zookeeper
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来, 作为Active Master去工作。


官方文档:http://spark.apache.org/docs/3.1.2/spark-standalone.html#standby-masters-with-zookeeper

- 先停止Sprak集群
|
/usr/local/spark/sbin/stop-all.sh |
- 在server1上配置
|
vim /usr/local/spark/conf/spark-env.sh |
注释或删除MASTER_HOST内容:
|
# SPARK_MASTER_HOST=server1 |
增加如下配置
|
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=server1:2181,agent1:2181,agent2:2181 -Dspark.deploy.zookeeper.dir=/spark-ha" |
参数含义说明:
|
spark.deploy.recoveryMode:恢复模式 spark.deploy.zookeeper.url:ZooKeeper的Server地址 spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息。 |
- 将spark-env.sh分发集群
|
cd /usr/local/spark/conf scp -r spark-env.sh root@agent2:$PWD scp -r spark-env.sh root@agent2:$PWD scp -r spark-env.sh root@agent3:$PWD |
- 启动集群服务
启动ZOOKEEPER服务
|
zkServer.sh status zkServer.sh stop zkServer.sh start |
- server1上启动Spark集群执行
|
/export/server/spark/sbin/start-all.sh |
- 在agent1上再单独只起个master:
|
/export/server/spark/sbin/start-master.sh |
查看WebUI
默认情况下,先启动Master就为Active Master,如下截图所示:
|
|
|
|

如果将server1的Master进程Kill掉,agent1的Master在1Min-2Min左右会接替server1的Master作用。 也就是在执行过程中,使用jps查看Active Master进程ID,将其kill,观察Master是否自动切换与应用运行完成结束。(需要等待1-2min)
测试运行
Wordcount测试
●测试主备切换
1.在server1上使用jps查看master进程id
2.使用kill -9 id号强制结束该进程
3.稍等片刻后刷新agent1的web界面发现agent1为Alive
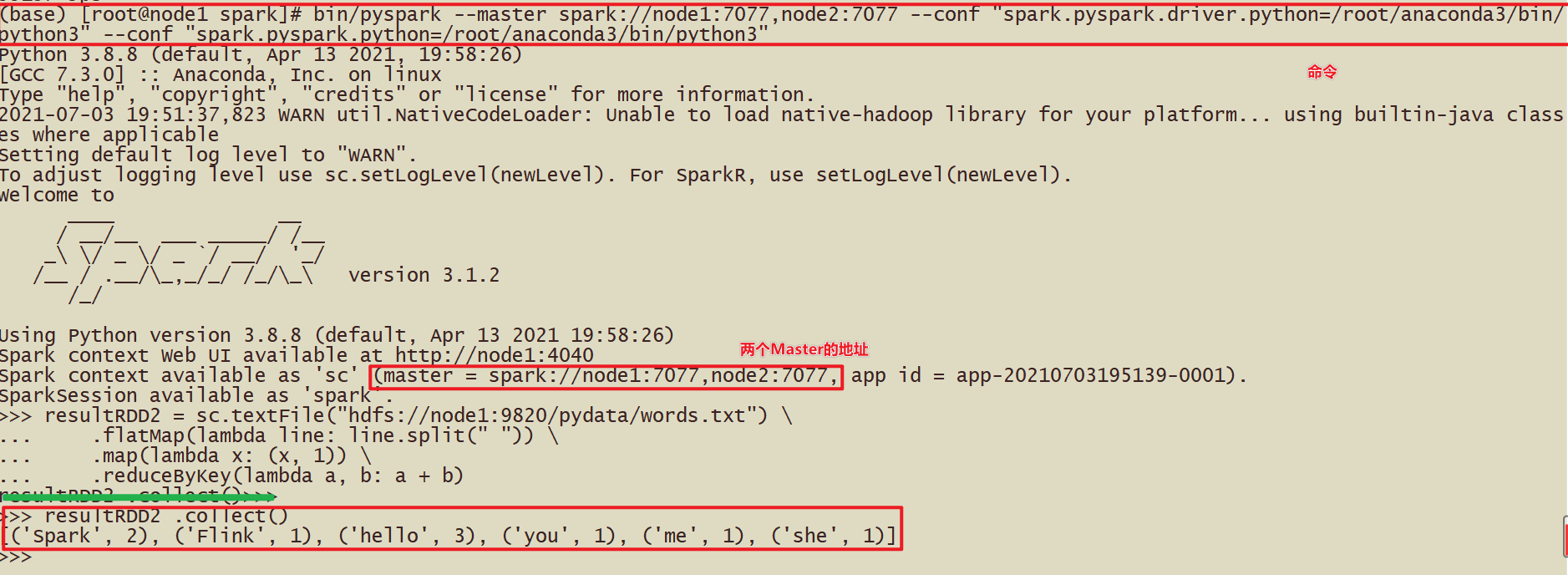
如启动spark-shell,需要指定多个master地址
/usr/local/spark/bin/spark-shell --master spark://server1:7077,agent1:7077
|
bin/pyspark --master spark://server1:7077,agent1:7077 \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" |
如下代码:
|
resultRDD2 = sc.textFile("hdfs://server1:8020/pydata/input/words.txt") \ .flatMap(lambda line: line.split(" ")) \ .map(lambda x: (x, 1)) \ .reduceByKey(lambda a, b: a + b) resultRDD2 .collect() |
截图如下:
停止集群
|
/export/server/spark/sbin/stop-all.sh |
提交测试运行圆周率
Standalone HA集群运行应用时,指定ClusterManager参数属性为
|
--master spark://host1:port1,host2:port2 |
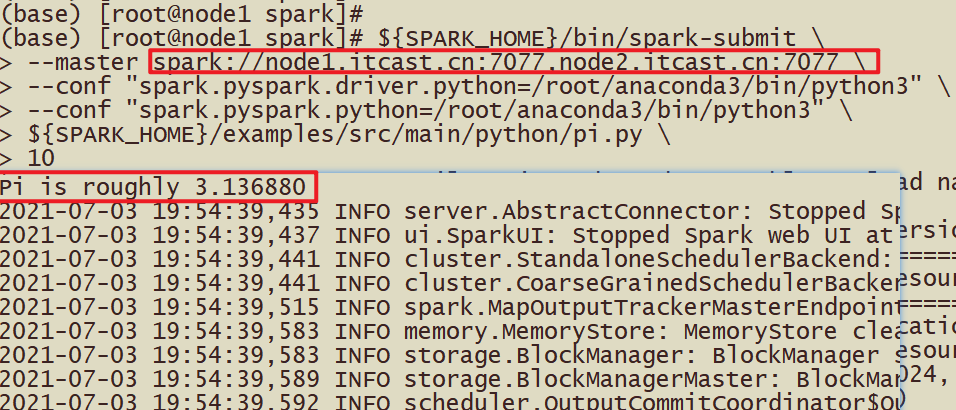
提交圆周率PI运行集群,命令如下:
|
${SPARK_HOME}/bin/spark-submit \ --master spark://server1:7077,agent1:7077 \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10 |
结果截图如下:
环境搭建-Spark on YARN
将Spark Application提交运行到YARN集群上,至关重要,企业中大多数都是运行在YANR上,文档:http://spark.apache.org/docs/3.1.2/running-on-yarn.html#launching-spark-on-yarn。
spark on yarn 模式官方文档说明:
http://spark.apache.org/docs/latest/running-on-yarn.html
http://spark.apache.org/docs/latest/running-on-yarn.html#configuration
同时注意,如果我们的spark程序是运行在yarn上面的话,那么我们就不需要spark 的集群了,我们只需要找任意一台机器配置我们的spark的客户端提交任务到yarn集群上面去即可。
Yarn是一个成熟稳定且强大的资源管理和任务调度的大数据框架,在企业中市场占有率很高,意味着有很多公司都在用Yarn,将公司的资源交给Yarn做统一的管理!并支持对任务做多种模式的调度,如FIFO/Capacity/Fair等多种调度模式!
所以很多计算框架,都主动支持将计算任务放在Yarn上运行,如Spark/Flink
企业中也都是将Spark Application提交运行在YANR上。
SparkOnYarn本质
- Spark On Yarn的本质?
将Spark任务的pyspark文件,经过Py4J转换,提交到Yarn的JVM中去运行
- Spark On Yarn需要啥?
1.需要Yarn集群:已经安装了
2.需要提交工具:spark-submit命令--在spark/bin目录
3.需要被提交的PySpark代码:Spark任务的文件,如spark/examples/src/main/python/pi.py中有示例程序,或我们后续自己开发的Spark任务)
4.需要其他依赖jar:Yarn的JVM运行PySpark的代码经过Py4J转化为字节码,需要Spark的jar包支持!Spark安装目录中有jar包,在spark/jars/中
修改配置
当Spark Application运行到YARN上时,在提交应用时指定master为yarn即可,同时需要告知YARN集群配置信息(比如ResourceManager地址信息),此外需要监控Spark Application,配置历史服务器相关属性。
修改spark-env.sh
基础操作
|
cd /usr/local/spark/conf vim /export/server/spark/conf/spark-env.sh |
添加内容
|
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop YARN_CONF_DIR=/usr/local//hadoop/etc/hadoop |
同步
|
cd /usr/local/spark/conf scp -r spark-env.sh root@agent1:$PWD scp -r spark-env.sh root@agent2:$PWD scp -r spark-env.sh root@agent3:$PWD |
整合历史服务器MRHistoryServer并关闭资源检查
- 整合Yarn历史服务器并关闭资源检查
在【$HADOOP_HOME/etc/hadoop/yarn-site.xml】配置文件中,指定MRHistoryServer地址信息,添加如下内容,
在server1上修改
|
cd /usr/local/hadoop/etc/hadoop vim /export/server/hadoop/etc/hadoop/yarn-site.xml |
添加内容
|
<configuration> <!-- 配置yarn主节点的位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>server1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 设置yarn集群的内存分配方案 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <!-- 开启日志聚合功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置聚合日志在hdfs上的保存时间 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://server1:19888/jobhistory/logs</value> </property> <!-- 关闭yarn内存检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration> |
由于使用虚拟机运行服务,默认情况下YARN检查机器内存,当内存不足时,提交的应用无法运行,可以设置不检查资源
同步
|
cd /usr/local/hadoop/etc/Hadoop scp -r yarn-site.xml root@agent1:$PWD scp -r yarn-site.xml root@agent2:$PWD scp -r yarn-site.xml root@agent3:$PWD |
历史服务HistoryServer地址
在【$SPARK_HOME/conf/spark-defaults.conf】文件增加SparkHistoryServer地址信息:
- 配置spark历史服务器
|
## 进入配置目录 cd /usr/local/spark/conf ## 修改配置文件名称 mv spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf |
## 添加内容:
|
spark.eventLog.enabled true spark.eventLog.dir hdfs://server1:8020/sparklog/ spark.eventLog.compress true spark.yarn.historyServer.address server1:18080 |
- 设置日志级别
|
## 进入目录 cd /export/server/spark/conf ## 修改日志属性配置文件名称 mv log4j.properties.template log4j.properties ## 改变日志级别 vim log4j.properties |
修改内容如下:
同步
|
cd /usr/local/spark/conf scp -r spark-defaults.conf root@agent1:$PWD scp -r spark-defaults.conf root@agent2:$PWD scp -r spark-defaults.conf root@agent3:$PWD scp -r log4j.properties root@agent1:$PWD scp -r log4j.properties root@agent2:$PWD scp -r log4j.properties root@agent3:$PWD |
配置依赖Spark Jar包
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。
|
## hdfs上创建存储spark相关jar包目录 hadoop fs -mkdir -p /spark/jars/ ## 上传$SPARK_HOME/jars所有jar包 hadoop fs -put /usr/local/spark/jars/* /spark/jars/ |
在spark-defaults.conf中增加Spark相关jar包位置信息:
|
在server1上操作 vim /usr/local/spark/conf/spark-defaults.conf 添加内容 spark.yarn.jars hdfs://server1:8020/spark/jars/* |
同步
|
cd /usr/local/spark/conf scp -r spark-defaults.conf root@agent1:$PWD scp -r spark-defaults.conf root@agent2:$PWD scp -r spark-defaults.conf root@agent3:$PWD |
启动服务
Spark Application运行在YARN上时,上述配置完成
启动服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
|
## 启动HDFS和YARN服务,在node1执行命令 start-dfs.sh start-yarn.sh 或 /usr/local/hadoop/sbin/start-all.sh 注意:在onyarn模式下不需要启动start-all.sh(jps查看一下看到worker和master) ## 启动MRHistoryServer服务,在node1执行命令 /usr/local/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver ## 启动Spark HistoryServer服务,,在node1执行命令 /usr/local/spark/sbin/start-history-server.sh |
- Spark HistoryServer服务WEB UI页面地址:
提交应用测试
先将圆周率PI程序提交运行在YARN上,命令如下:
|
SPARK_HOME=/usr/local/spark ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10 |
运行完成在YARN 监控页面截图如下:

设置资源信息,提交运行WordCount程序至YARN上,命令如下:
|
SPARK_HOME=/usr/local/spark ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ --num-executors 2 \ --queue default \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10 |
当WordCount应用运行YARN上完成以后,从8080 WEB 页面点击应用历史服务连接,查看应用运行状态信息。

SparkSQL整合Hive步骤
第一步:将hive-site.xml拷贝到spark安装路径conf目录
server1执行以下命令来拷贝hive-site.xml到所有的spark安装服务器上面去
|
cd /usr/local/hive/conf cp hive-site.xml /usr/local/spark/conf/ scp hive-site.xml root@agent1:/usr/local/spark/conf/ scp hive-site.xml root@agent2:/usr/local/spark/conf/ scp hive-site.xml root@agent3:/usr/local/spark/conf/ |
第二步:将mysql的连接驱动包拷贝到spark的jars目录下
server1执行以下命令将连接驱动包拷贝到spark的jars目录下,三台机器都要进行拷贝
|
cd /usr/local/hive/lib cp mysql-connector-java-5.1.32.jar /usr/local/spark/jars/ scp mysql-connector-java-5.1.32.jar root@agent1:/usr/local/spark/jars/ scp mysql-connector-java-5.1.32.jar root@agent2:/usr/local/spark/jars/ scp mysql-connector-java-5.1.32.jar root@agent3:/usr/local/spark/jars/rs/ |
第三步:Hive开启MetaStore服务
(1)修改 hive/conf/hive-site.xml新增如下配置
|
远程模式部署metastore 服务地址 <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://server1:9083</value> </property> </configuration> |
2: 后台启动 Hive MetaStore服务
前台启动:
|
bin/hive --service metastore & |
后台启动:
|
nohup /usr/local/hive/bin/hive --service metastore 2>&1 >> /var/log.log & |
完整的hive-site.xml文件
|
<configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value> jdbc:mysql://server1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>server1</value> </property> <!-- 远程模式部署metastore 服务地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://server1:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!-- 关闭元数据存储版本的验证 --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> </configuration> |
第四步:测试Sparksql整合Hive是否成功
- [方式1]Spark-sql方式测试
先启动hadoop集群,在启动spark集群,确保启动成功之后server1执行命令,指明master地址、每一个executor的内存大小、一共所需要的核数、mysql数据库连接驱动:
|
cd /usr/local/spark bin/spark-sql --master local[2] --executor-memory 512m --total-executor-cores 1 或 bin/spark-sql --master spark://server1:7077 --executor-memory 512m --total-executor-cores 1 |
执行成功后的界面:进入到spark-sql 客户端命令行界面
查看当前有哪些数据库, 并创建数据库
|
show databases; create database sparkhive; |
看到数据的结果,说明sparksql整合hive成功!


注意:日志太多,我们可以修改spark的日志输出级别(conf/log4j.properties)
注意:
在spark2.0版本后由于出现了sparkSession,在初始化sqlContext的时候,会设置默认的spark.sql.warehouse.dir=spark-warehouse,
此时将hive与sparksql整合完成之后,在通过spark-sql脚本启动的时候,还是会在那里启动spark-sql脚本,就会在当前目录下创建一个spark.sql.warehouse.dir为spark-warehouse的目录,存放由spark-sql创建数据库和创建表的数据信息,与之前hive的数据息不是放在同一个路径下(可以互相访问)。但是此时spark-sql中表的数据在本地,不利于操作,也不安全。
所有在启动的时候需要加上这样一个参数:
--conf spark.sql.warehouse.dir=hdfs://server1:8020/user/hive/warehouse
保证spark-sql启动时不在产生新的存放数据的目录,sparksql与hive最终使用的是hive同一存放数据的目录。如果使用的是spark2.0之前的版本,由于没有sparkSession,不会出现spark.sql.warehouse.dir配置项,不会出现上述问题。
Spark2之后最后的执行脚本,server1执行以下命令重新进去spark-sql
|
cd /export/server/spark bin/spark-sql \ --master spark://node1:7077 \ --executor-memory 512m --total-executor-cores 1 \ --conf spark.sql.warehouse.dir=hdfs://server1:8020/user/hive/warehouse |
- [方式2]PySpark-Shell方式启动:
|
bin/spark-shell --master local[3] spark.sql("show databases").show |
如下图:

- [方式3]PySpark-Shell方式启动:
|
bin/pyspark --master local[2] spark.sql("show databases").show() |



 浙公网安备 33010602011771号
浙公网安备 33010602011771号