HashSet集合存储数据的结构(哈希表)-Set集合存储元素不重复的原理
HashSet集合存储数据的结构(哈希表)
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超迂阈值(8 )时,将链表转换为红黑树,这样大大减少了查找时间。

简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
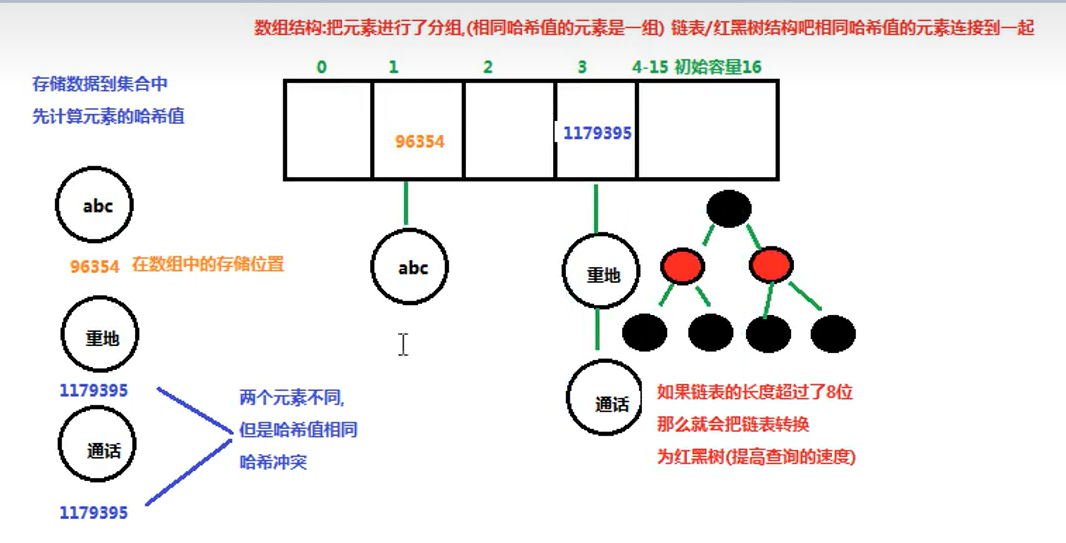
Set集合存储元素不重复的原理
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一
创建自定义Student类
package A_Lian_one.demo13; import java.util.HashSet; /* set集合不允许存储重复元素的原理 */ public class Demo02HashSetSaveString { public static void main(String[] args) { //创建HashSet集合对象 HashSet<String> set = new HashSet<>(); String s1 = new String("abc"); String s2 = new String("abc"); set.add(s1); set.add(s2); set.add("种地"); set.add("同孤傲"); set.add("阿桑的歌"); System.out.println(set); } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号