

爬虫实战进阶2
概要
-
爬取链接二手房数据并写入文件
-
爬取汽车之家新闻数据并写入文件

详情
-
爬取链接二手房数据并写入文件
1.先查看网页的数据加载方式,发现该网页是直接加载的
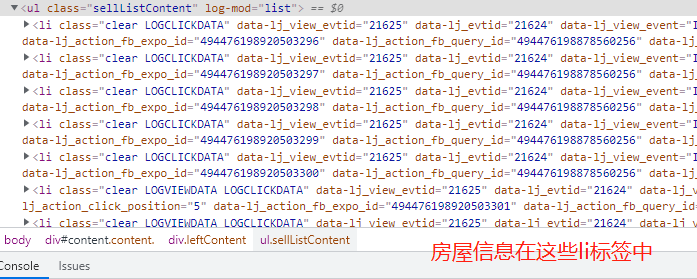
2.向该地址发送get请求,直接从返回的html页面筛选数据即可
3.分析页面组成,筛选数据
4.按照特定格式处理并保存至excel表格文件
5.查找规律,爬取多页多地区二手房数据并保存至表格文件
eg:https://sh.lianjia.com/ershoufang/pudong/pg2
其中,sh表示省
pudong表示地区
pg后的数字表示页数
import time import requests from bs4 import BeautifulSoup from openpyxl import Workbook # 1.创建Excel表格文件 wbHouse = Workbook() # 2.创建工作表 ws1 = wbHouse.create_sheet('某地区二手房', 0) ws1.append(['房屋名称', '详情链接', '小区名称', '区域名称', '详细信息', '关注人数', '发布时间', '总价(万元)', '单价(元/平)']) def handleInfo(info): """ 分割详细信息 户型,大小,朝向,装修程度,楼层,年代,楼型 """ details = info.split('|').strip() if not len(details) == 7: details[0] = info return details def getTwoHandHouse(city, area, n): """ 获取特定地区房屋信息 房屋名称,详情链接,小区名称,区域名称,详细信息(可拆分),关注人数,发布时间,总价,单价 """ # 1.指定网站url twoHandUrl = 'https://{}.lianjia.com/ershoufang/{}/pg{}/'.format(city, area, n) # 2.定义请求头 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" } # 3.发送请求 resBS = requests.get(twoHandUrl, headers=headers) # 4.利用解析库筛选数据 soup = BeautifulSoup(resBS.text, 'lxml') # 5.找到显示房屋信息的列表 houseList = soup.select('ul.sellListContent>li') # 6.循环当页所有房屋 for house in houseList: # 1.获取存放名称、链接的a标签 aTag = house.select('div.title>a')[0] if not aTag: continue # 获取房屋名称 houseName = aTag.text # 获取详情链接 link = aTag.get('href') # 2.获取存放小区、地区的div标签 divPosiTag = house.select('div.positionInfo')[0] posi = divPosiTag.text.split('-') # 根据是否有不可分割的位置信息,做不同处理 if len(posi) == 2: estateName = posi[0] estateArea = posi[1] elif len(posi) == 1: estateName, estateArea = posi[0] else: estateName, estateArea = '' # 3.获取存放详细信息的div标签 divInfoTag = house.select('div.houseInfo')[0] # 获取详细信息 info = divInfoTag.text # 分割详细信息 # detail =handleInfo(info) # 4.获取关注度与发布时间的div标签 divFollowTag = house.select('div.followInfo')[0] focusTime = divFollowTag.text # 获取关注人数 peopleNum = focusTime.split('/')[0].strip() # 获取发布时间(多少天以前) publishTime = focusTime.split('/')[1].strip() # 5.获取总价标签 divTotalTag = house.select('div.totalPrice')[0] # 获取总价 totalPrice = divTotalTag.span.text # 6.获取单价标签 divUnitTag = house.select('div.unitPrice')[0] # 获取单价 unitPrice = divUnitTag.text.strip('元/平') ''' 主动延迟 ''' time.sleep(1) # 7.将数据添加至Excel表格文件 ws1.append([houseName, link, estateName, estateArea, info, peopleNum, publishTime, totalPrice, unitPrice]) num = int(input('请输入需要的二手房页数: ').strip()) # 按页获取二手房 for n in range(num): getTwoHandHouse('sh', 'baoshan', n) # 保存文件 wbHouse.save('二手房.xlsx')
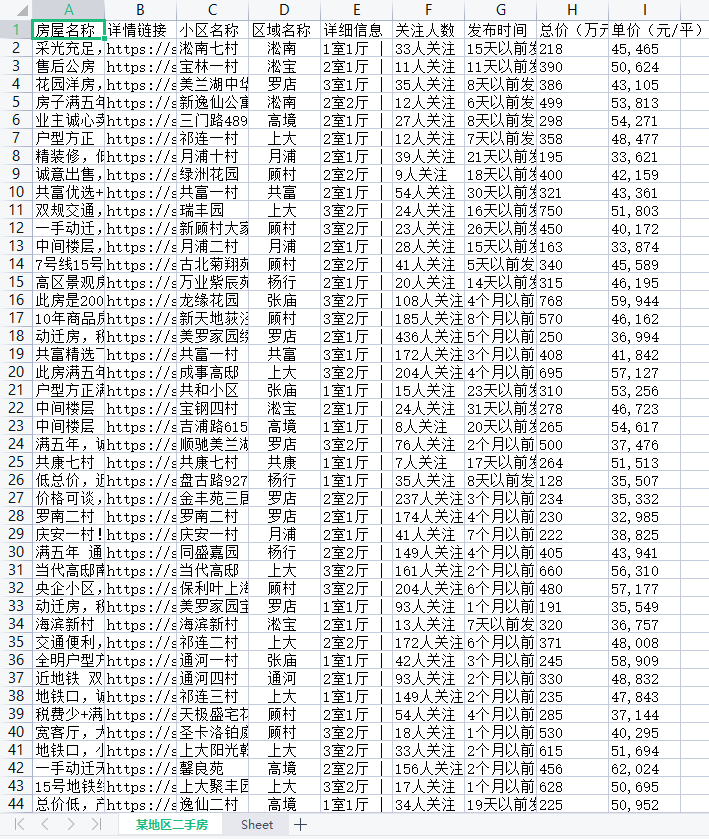
-
爬取汽车之家新闻数据并写入文件
1.先查看网页的数据加载方式,页面数据主要直接加载
但有一部分是动态展示的,由js代码完成,用来限制展示条数
2.首次请求数据的时候已经获取到了所有的数据,所以直接从html页面筛选数据即可

3.由于存在一些页面干扰项,最好在筛选标签时判断结果存在与否
![]()
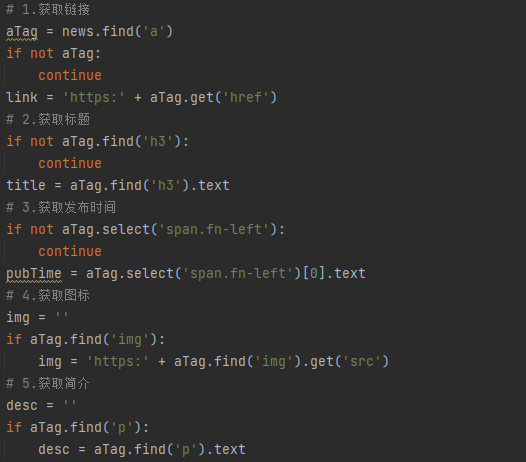
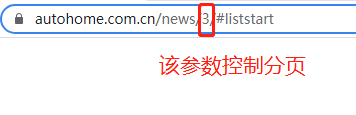
4.单页的写好了,查看切换页面会造成链接的变化,如下可知,该网页是靠链接的变化实现切换页面的
![]()
![]()

5.按照特定格式处理并保存至Excel表格文件
![]()

import time import requests from bs4 import BeautifulSoup from openpyxl import Workbook # 1.创建Excel表格文件 wbCar = Workbook() # 2.创建工作表 ws1 = wbCar.create_sheet('汽车之家新闻', 0) ws1.append(['标题', '详情链接', '图标', '发布时间', '简介']) def getCarNews(n): """ 获取汽车之家新闻相关信息 标题、链接、图标、发布时间、简介 """ # 1.指定汽车之家新闻网的链接 carNewsUrl = 'https://www.autohome.com.cn/news/{}/#liststart'.format(n) # 2.定义请求头 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" } # 2.向汽车之家发送请求 carRes = requests.get(carNewsUrl, headers=headers) # 3.避免乱码,按照响应设置字符编码 carRes.encoding = 'GBK' # 4.构造html文件解析器 carSoup = BeautifulSoup(carRes.text, 'lxml') # 5.先查找存放新闻信息的li标签 newsList = carSoup.select("ul.article>li") for news in newsList: # 1.获取链接 aTag = news.find('a') if not aTag: continue link = 'https:' + aTag.get('href') # 2.获取标题 if not aTag.find('h3'): continue title = aTag.find('h3').text # 3.获取发布时间 if not aTag.select('span.fn-left'): continue pubTime = aTag.select('span.fn-left')[0].text # 4.获取图标 img = '' if aTag.find('img'): img = 'https:' + aTag.find('img').get('src') # 5.获取简介 desc = '' if aTag.find('p'): desc = aTag.find('p').text print(link, '\n', title, '\n', img, '\n', pubTime, '\n', desc, '\n', '******************') # 6.将数据添加到Excel表格文件 ws1.append([title, link, img, pubTime, desc]) # 主动延迟 time.sleep(1) # 输入想要获取的新闻数目 pageNum = int(input('请输入想要获取的汽车新闻的数量(页): ').strip()) # 按页获取新闻 for n in range(pageNum): # 调用爬取汽车之家新闻信息的函数 getCarNews(n) # 保存文件 wbCar.save('车闻.xlsx')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号