

爬虫实战进阶
概要
-
爬糗图百科汇总
-
爬取优美图库高清图片
-
爬取梨视频汽车视频数据
-
防盗链

详细
-
补充
拉链方法
# 将多个列表按索引分别组合成元组放入迭代器中 iter = zip(list1,list2,list3,list4) list(iter)
-
爬糗图百科汇总
# 正则 import requests import os import re # 1.图片在网页上,直接发送请求即可 qiushiRes = requests.get('https://www.qiushibaike.com/imgrank/') resText = qiushiRes.text # 2.通过正则匹配糗图 imgList = re.findall('<img src="(.*?)" alt="糗事.*"', resText) # 3.判断是否存在存放图片文件夹,不存在则创建 if not os.path.exists(r'糗图'): os.mkdir(r'糗图') # 4.循环获得的图片 for imgLink in imgList: # 5.组合图片链接 realLink = "https:"+imgLink # 6.向图片链接发送get请求,返回流文件 image = requests.get(realLink, stream=True) # 7.新建图片文件 with open(r'糗图\{}'.format(imgLink.split('/')[-1]), 'wb') as f: # 8.逐行写入 for line in image.iter_content(): f.write(line)
# bs4模块 import requests from bs4 import BeautifulSoup import os # 1.图片在网页上,直接发送请求即可 qiushiRes = requests.get('https://www.qiushibaike.com/imgrank/') resText = qiushiRes.text # 2.构造解析器对象 soup = BeautifulSoup(resText, 'lxml') # 3.判断是否存在存放图片文件夹,不存在则创建 if not os.path.exists(r'糗图'): os.mkdir(r'糗图') # 34.查找图片 imgTagList = soup.find_all(name='img', attrs={'class': 'illustration'}) for img in imgTagList: # 4.拼接完整链接 realLink = 'https:' + img.get('src') # 5.向图片链接发送get请求,返回流文件 image = requests.get(realLink, stream=True) # 6.新建图片文件 with open(r'糗图\{}'.format(img.get('src').split('/')[-1]), 'wb') as f: # 8.逐行写入 for line in image.iter_content(): f.write(line)
-
爬取优美图库高清图片
https://www.umei.cc/katongdongman/dongmantupian/ 1.先在空白处右键点击查看网页源代码 2.发现页面上的小图链接在网页中,该网站的图片采用直接加载的方式 3.模拟朝该地址发送get请求获取动漫图片首页 4.分析返回结果发现主页面图片与动漫推荐下的图片在class不同的div页面布局标签下,可根据这个特点加以区分 5.利用bs4模块(或正则表达式)筛选图片标签,这里从区分度高的div标签往下找 6.查找div标签下的li列表标签 7.发现其下img标签中的是小图地址,不需要;观察发现点击a标签中的地址能打开图片详情页 8.循环li列表标签,获取这些a标签中链接与网站头拼接成完整链接 9.查看详情页源代码,存在大图链接,是直接加载的 10.分析页面发现class为ImageBody的div标签下的img标签为大图 11.循环向该标签的src链接发送请求,将返回结果保存至指定目录,这是单页图片
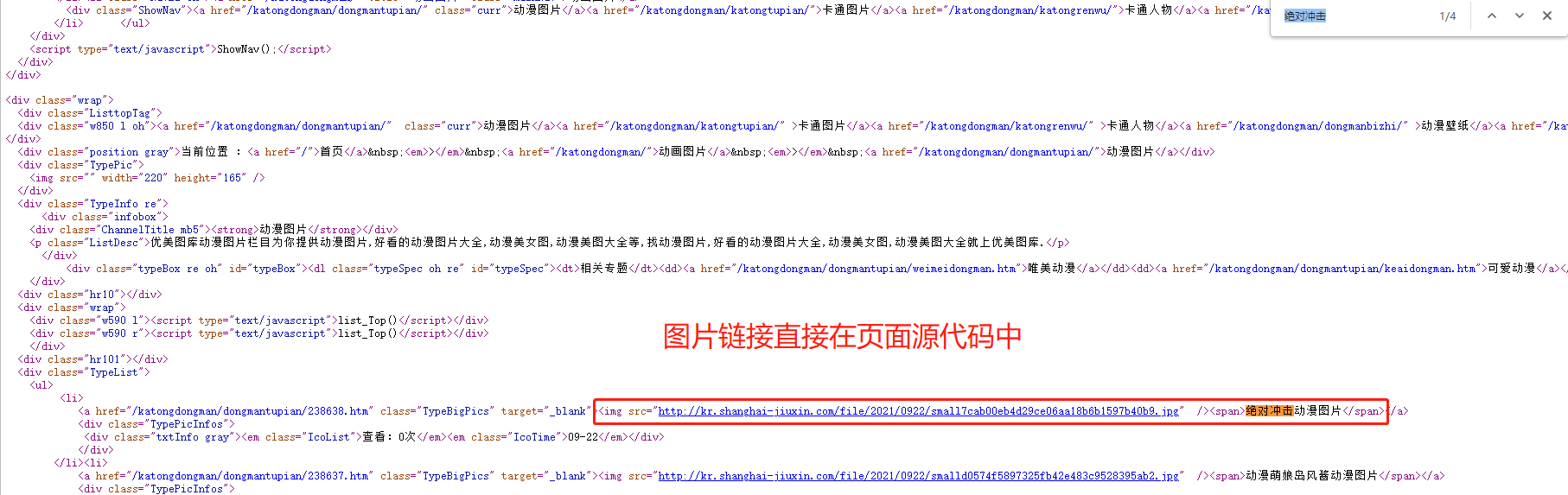

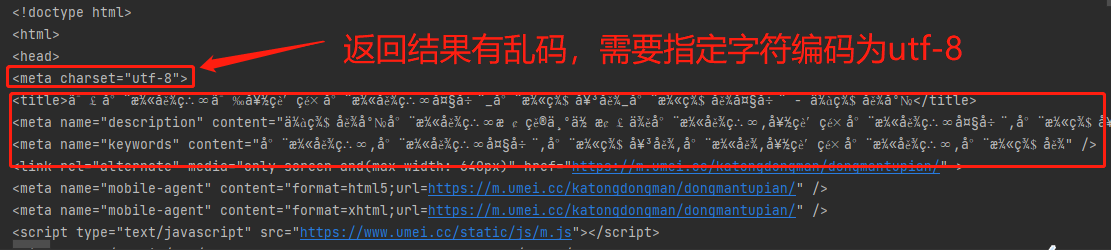
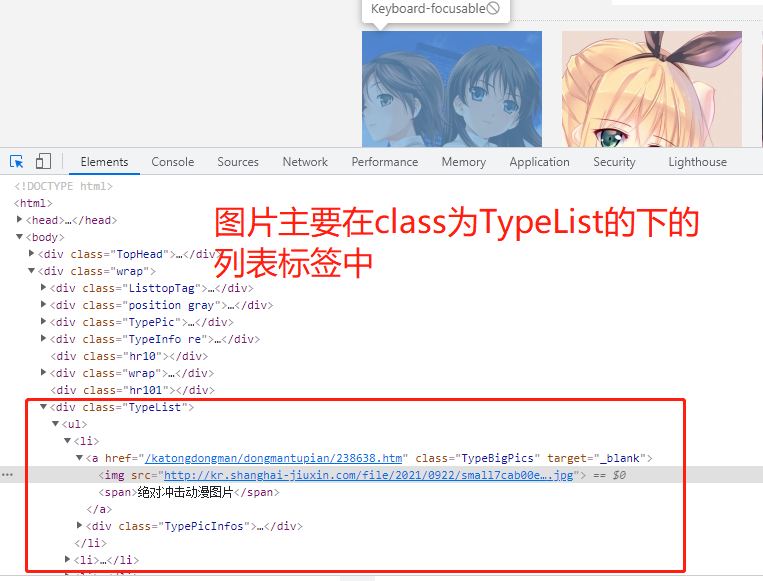
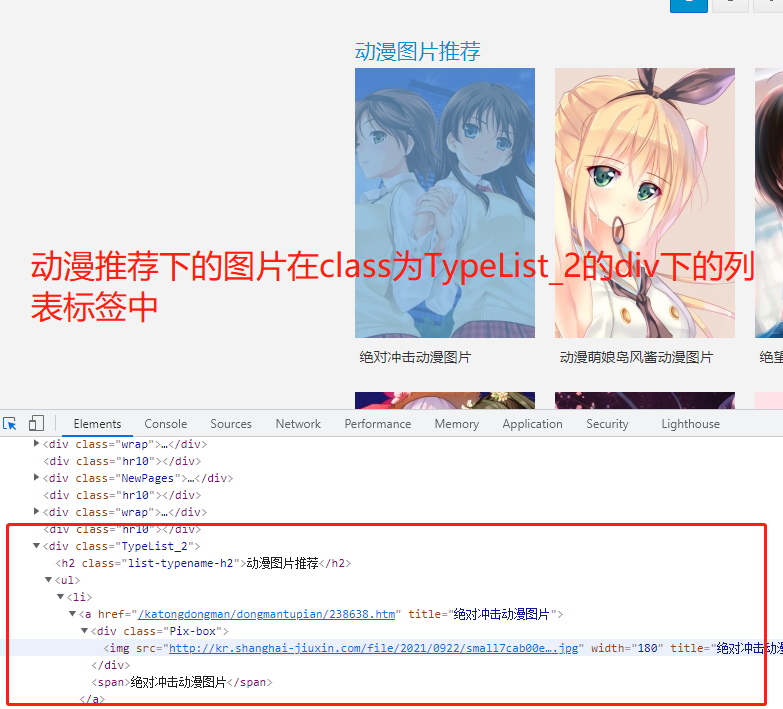
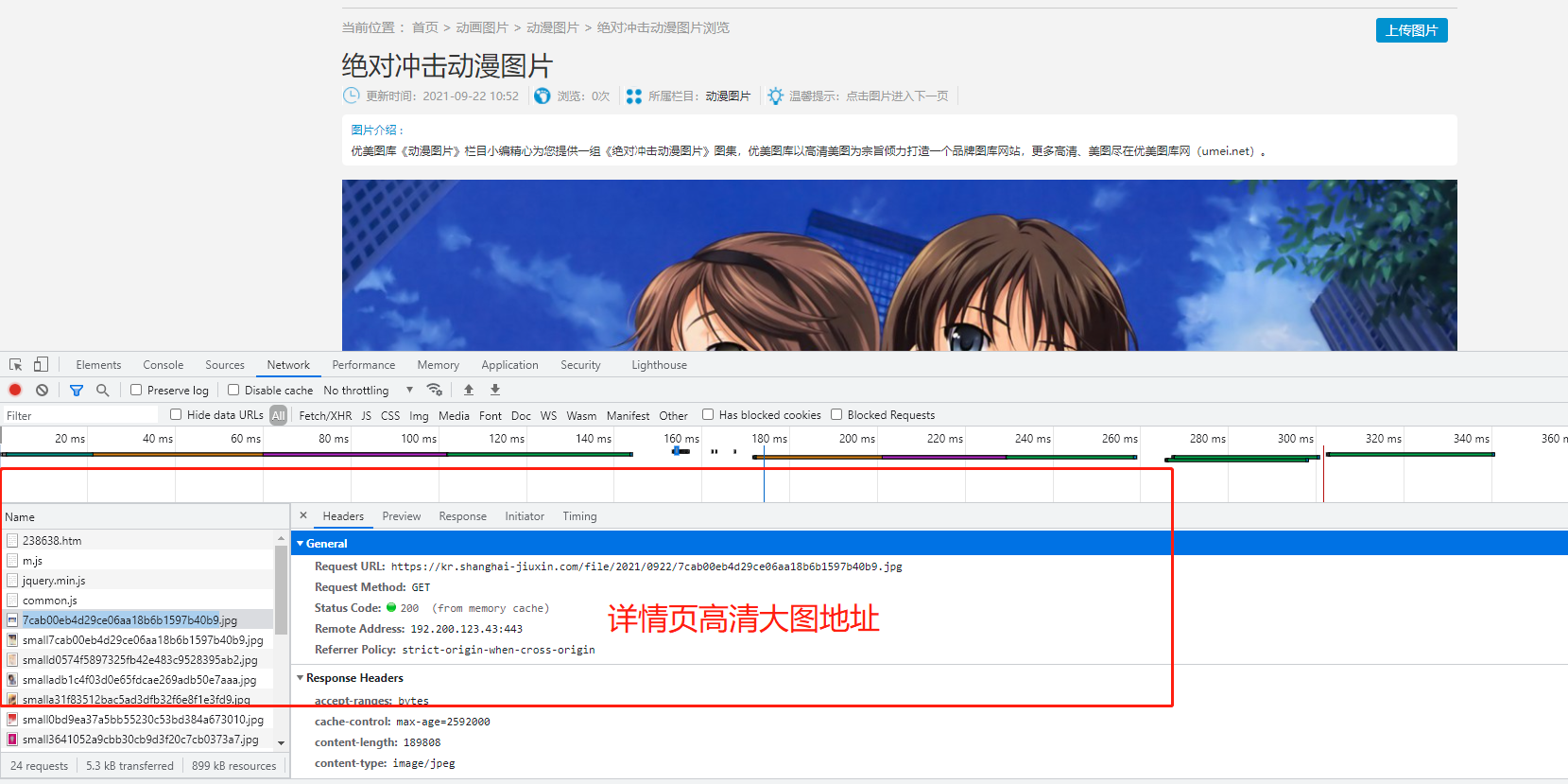


import requests from bs4 import BeautifulSoup import os import time # 1.判断存放图片的目录是否存在,不存在则自动创建 if not os.path.exists(r'动漫图片'): os.mkdir(r'动漫图片') # 2.图片首页地址 pageUrl = 'https://www.umei.cc/katongdongman/dongmantupian/' # 3.向该地址发送get请求 res = requests.get(pageUrl) # 4.指定合适的字符编码 res.encoding = 'UTF-8' # 5.构造html解析器 soup = BeautifulSoup(res.text, 'lxml') # 6.筛选图片所在的页面布局标签 divTag = soup.find(name='div', attrs={'class': 'TypeList'}) # 7.筛选页面布局下的列表标签 liList = divTag.find_all(name='li') # 8.获取每个a标签的href属性 imgDetailTag = [li.a.get('href') for li in liList] # 9.将每个href属性值补全成完整网址(图片详情页) imgDetailUrlList = ['https://www.umei.cc'+imgDetailUrl for imgDetailUrl in imgDetailTag] # 10.循环图片详情页 for imgDetail in imgDetailUrlList: # 11.向图片详情页发送请求 res1 = requests.get(imgDetail) # 12.对图片详情页构造html解析器 soupD = BeautifulSoup(res1.text, 'lxml') # 13.获取img标签 imgBigTag = soupD.select('div.ImageBody img') # 14.select返回结果需要循环,获取图片链接 for imgBig in imgBigTag: # 15.设置时间延迟 time.sleep(1) print(imgBig.get('src')) # 16.向大图链接发送请求 img = requests.get(imgBig.get('src'), stream=True) # 17.拼接文件路径 filePath = os.path.join(r'动漫图片', imgBig.get('src').split('/')[-1]) # 18.保存图片 with open(filePath, 'wb') as f: for line in img.iter_content(): f.write(line)
-
爬取梨视频汽车视频数据
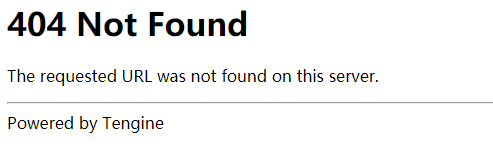
https://www.pearvideo.com/category_31 1.先在空白处右键点击查看网页源代码 2.发现页面上的视频信息在网页中,该网站的视频链接、名称等是直接加载的 3.模拟向梨视频汽车板块网址发送get请求 4.分析返回结果发现视频链接是一个个li标签下的a标签的href值 5.由于同类li只用于存放视频,从这些li标签定位a标签即可 6.补全a标签中的链接,点击,是视频详情页,查询该网页源代码 7.视频详情页中视频不是直接加载的,无需向该网页发送请求 8.通过network找到二次加载的地址,并向其发送get请求,返回错误信息,说明该网站有防爬措施 9.在请求头中添加referer字段说明请求来源 10.向该视频链接发送请求并反序列化 11.拿到的视频链接无法访问 12.分析可知中间有一段被系统时间替换 请求返回的链接: https://video.pearvideo.com/mp4/short/20210922/1632319206999-15771638-hd.mp4 13.利用视频编号将其替换回来从而获取真实连接: https://video.pearvideo.com/mp4/adshort/20210922/cont-1742228-15771122_adpkg-ad_hd.mp4 14.向该链接发送请求并将返回的视频保存至本地
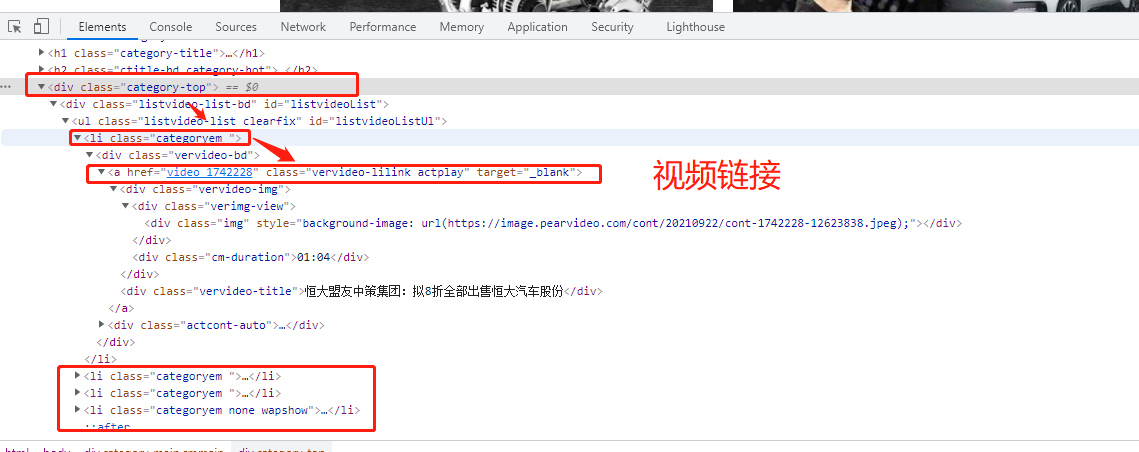
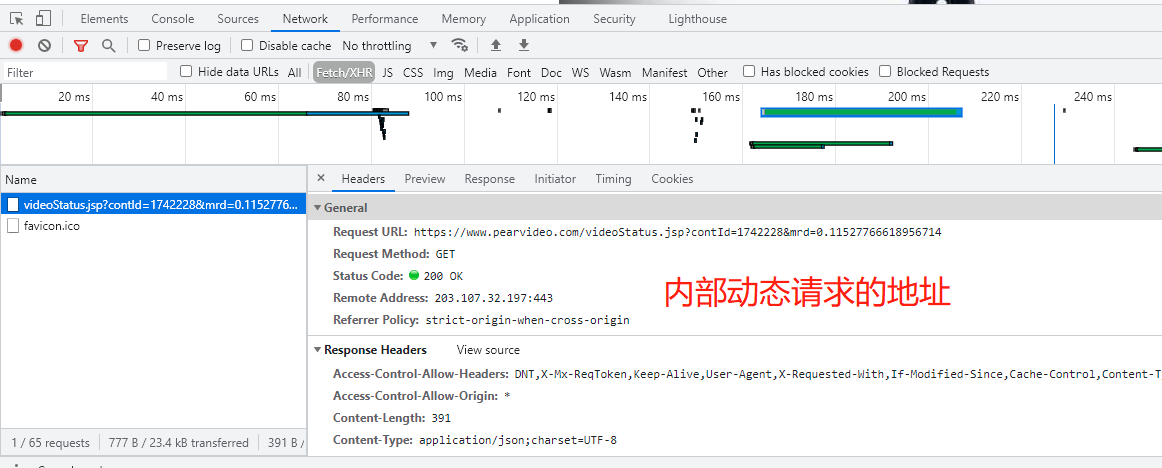
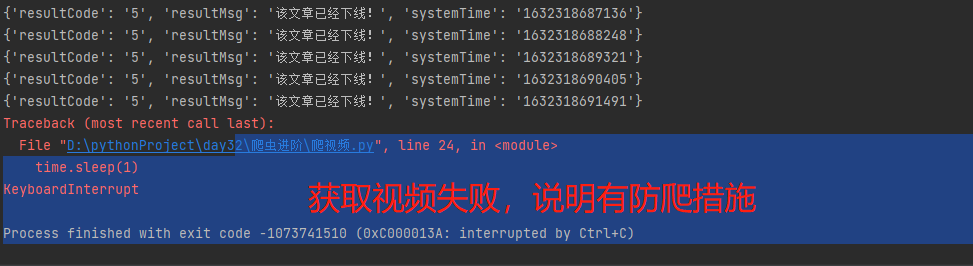
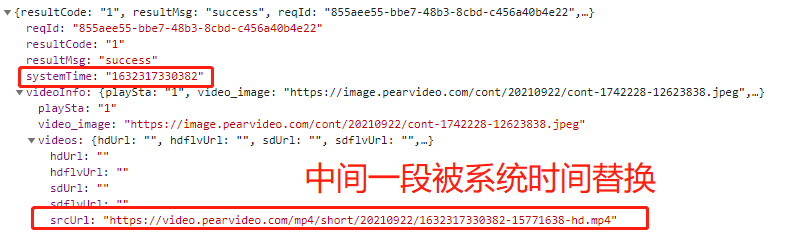
import requests from bs4 import BeautifulSoup import os import time # 1.判断存放视频的目录是否存在,不存在则自动创建 if not os.path.exists(r'梨视频_Car'): os.mkdir(r'梨视频_Car') # 2.指定梨视频汽车板块主界面url mainUrl = 'https://www.pearvideo.com/category_31' # 3.模拟向梨视频汽车板块发送get请求 mainRes = requests.get(mainUrl) # 4.构造html解析器 mainSoup = BeautifulSoup(mainRes.text, 'lxml') # 5.循环li标签 liList = mainSoup.find_all(name='li', attrs={'class': 'categoryem'}) # 6.获取a标签的href值,同时也是视频编号 videoDetailList = [li.a.get('href') for li in liList] # 7.设置基础网站 baseUrl = 'https://www.pearvideo.com/' # 8.虽然无需向详情页发送请求,视频链接的请求参数需要a标签的href值作为视频编号 for videoCode in videoDetailList: # 9.主动设置时间延迟 time.sleep(1) # 10.向视频详情页动态加载的地址发送get请求 videoId = videoCode.split('_')[-1] videoRes = requests.get('https://www.pearvideo.com/videoStatus.jsp', params={'contId': videoId}, headers={'referer': baseUrl + videoCode} ) # 11.将返回结果反序列化 dataJson = videoRes.json() # 12.获取视频链接,但是无法访问 srcUrl = dataJson.get('videoInfo').get('videos').get('srcUrl') # 13.需要获取真实链接 realUrl = srcUrl.replace(dataJson.get('systemTime'), 'cont-{}'.format(videoId)) # 14.向真实视频链接发送请求 realVideoRes = requests.get(realUrl, stream=True) # 15.拼接文件路径 filePath = os.path.join(r'梨视频_Car', realUrl.split('/')[-1] ) # 16.将视频写入指定路径的文件 with open(filePath, 'wb') as f: # 17.逐行写入 for line in realVideoRes.iter_content(): f.write(line) print('{}下载成功'.format(videoId))
-
防盗链
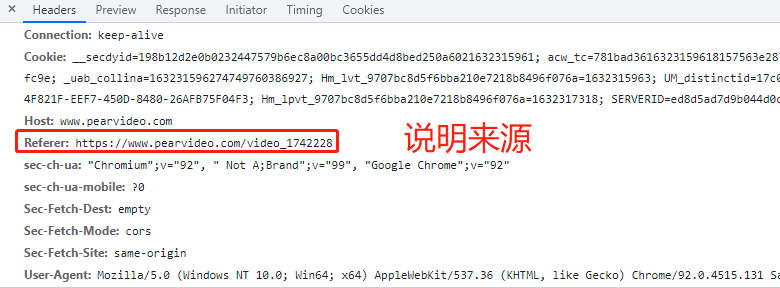
防爬措施:校验当前请求从何而来
1.本网站 - > 允许访问
2.其他网址 - > 拒绝
在请求头中有一个专门用于记录来源的键值对 referer:本网站地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号