

爬虫实战
-
数据的加载方式
-
爬取天气数据
-
爬取百度翻译
-
-
详细
-
数据的加载方式
# 常见的加载方式 1.直接加载 朝服务器发送请求,返回全部页面数据并加载 2.间接加载(内部js代码多次请求) 朝服务器发送请求,先加载页面主要结构,再朝其他地址发送请求获取具体数据
-
爬取天气数据
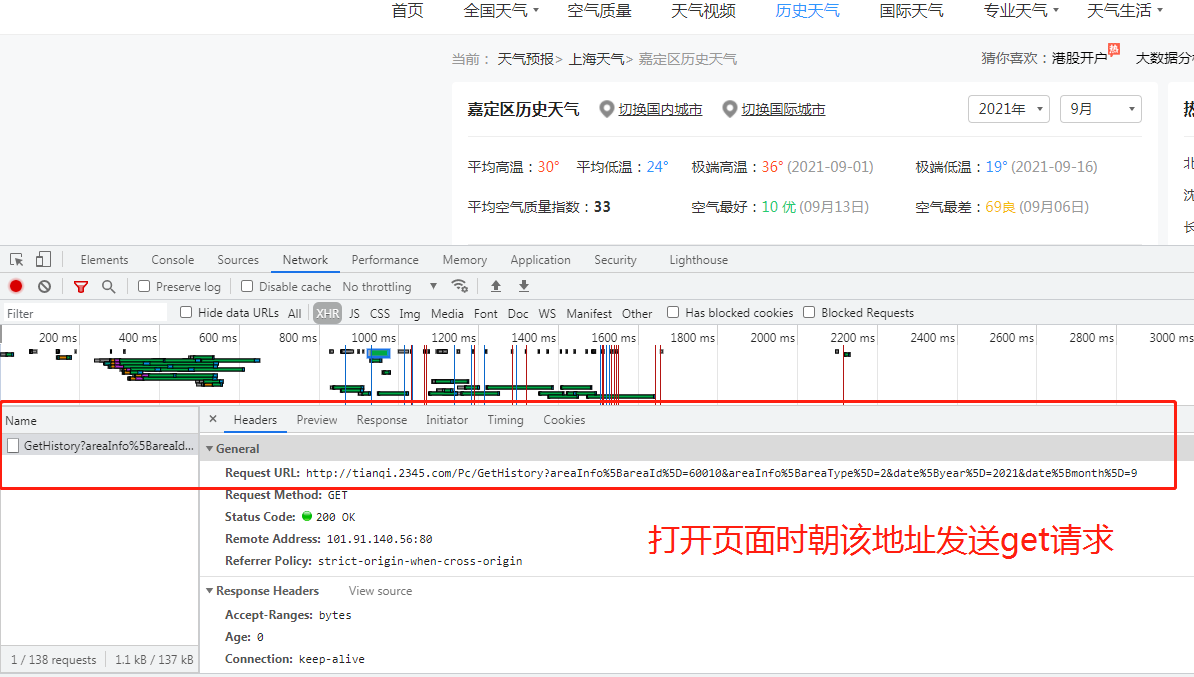
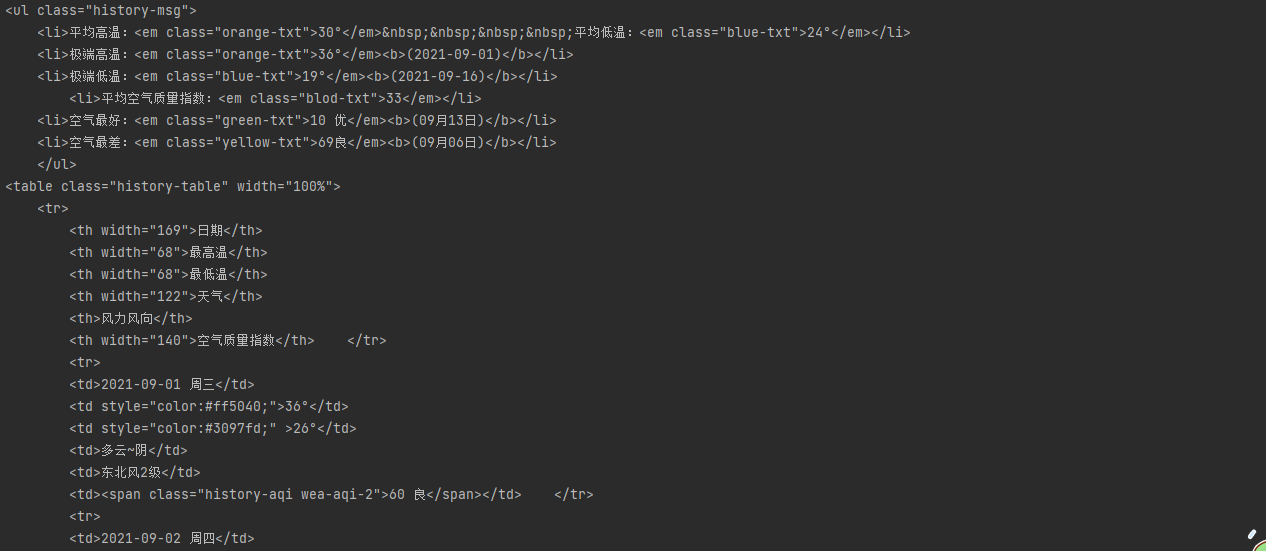
思路: 1.打开页面,先分析从数据加载的方式(空白处右键查看网页源代码) 2.源代码中并无天气数据,此页面为间接加载 3.查看打开该网页时会向哪些网址发送请求(空白处右键检查选network,get请求可直接将地址复制到浏览器地址栏访问) 4.分析请求得到的结果是否是天气数据 # 解析json字符串的网站:https://www.bejson.com/ 5.如果是就利用requests模块朝该地址发送get请求获取json数据 6.分析历史天气url的规律,可爬取其他月份的数据 import requests urlW = 'http://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=60010&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=9' res = requests.get(urlW) dictW = res.json().get('data') print(dictW)
![]()
-
爬取百度翻译
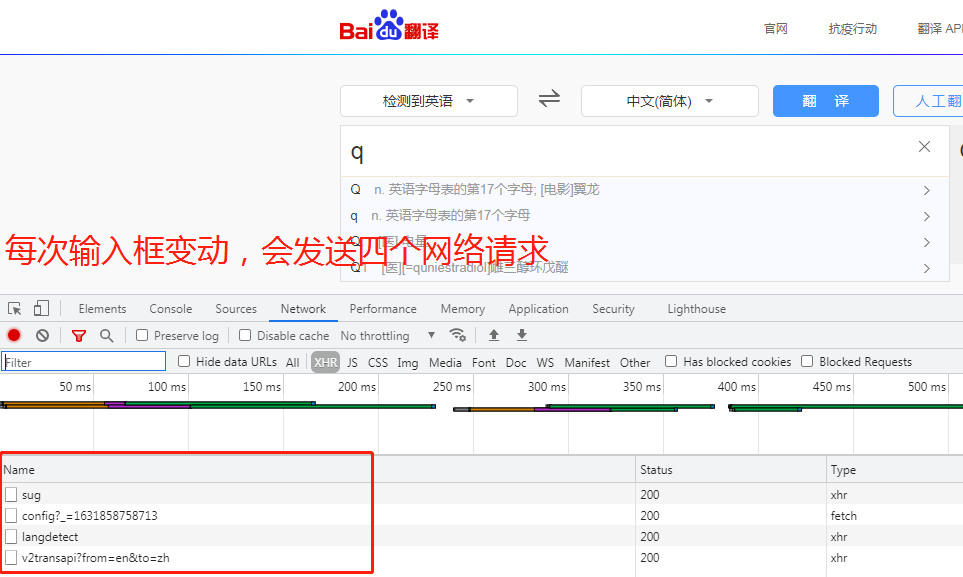
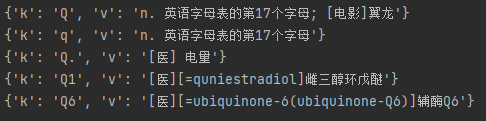
思路: 1.打开页面,先分析从数据加载的方式(空白处右键查看网页源代码) 2.源代码中并无输入单词的信息,此页面为间接加载 3.该网页对单词的翻译是随着输入框变动动态获取的 4.打开network,发现每次输入单词都会朝四个地址发送请求,其中sug频率固定 # 解析json字符串的网站:https://www.bejson.com/ 5.利用requests模块朝sug请求的地址发送post请求获取json数据 该请求用于显示输入框下拉菜单的数据 import requests urlEng = 'https://fanyi.baidu.com/sug' # 搜索框下拉数据 resE = requests.post(urlEng, headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36X-Requested-With: XMLHttpRequest'}, data={ 'kw': 'q' }) dataE = resE.json().get('data') for d in dataE: print(d)

http://scxk.nmpa.gov.cn:81/xk/ 思路: 1.打开页面,先分析从数据加载的方式(空白处右键查看网页源代码) 2.源代码中并无药企信息,此页面为间接加载 3.查看打开该网页时会向哪些网址发送请求 4.发现打开页面时会向一个地址发送post请求,查看其请求体 5.利用requests模块朝sug请求的地址发送post请求获取json数据 6.继续验证详情页的数据加载方式 # 1.引入requests模块用于发送网络请求 import requests # 2.指定查找药企概要信息的url urlXkzsList = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList' # 3.指定查找详情的url urlXkzsDetail = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById' # 4.将请求体信息放入post请求并向概要url发送 res = requests.post(urlXkzsList, data={ 'on': 'true', 'page': 1, # 页码 'pageSize': 15, # 每页数据行数 'productName': '', 'conditionType': 1, 'applyname': '', 'applysn': '' }) # 5.获取上述的响应,为单页药企概要信息 dataList = res.json().get('list') # 6.循环获取每家药企的信息 for d in dataList: # 7.向每家药企发送携带企业ID的post请求 resD = requests.post(urlXkzsDetail, data={'id': d.get('ID')}) # 8.将请求结果(单家药企信息)反序列化成字典 resDict = resD.json() # 9.输出该企业信息 print(resDict)
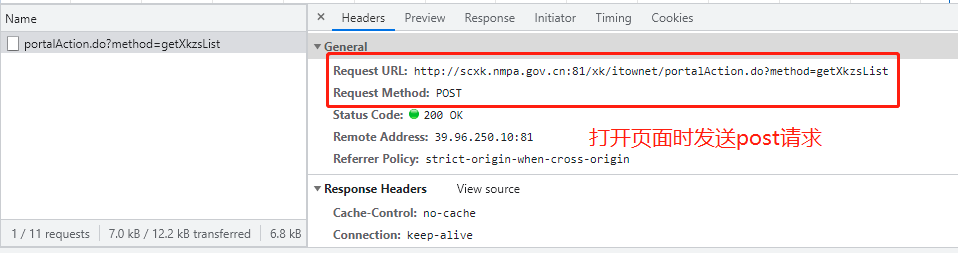
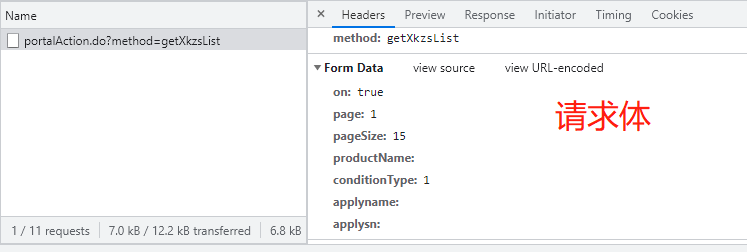

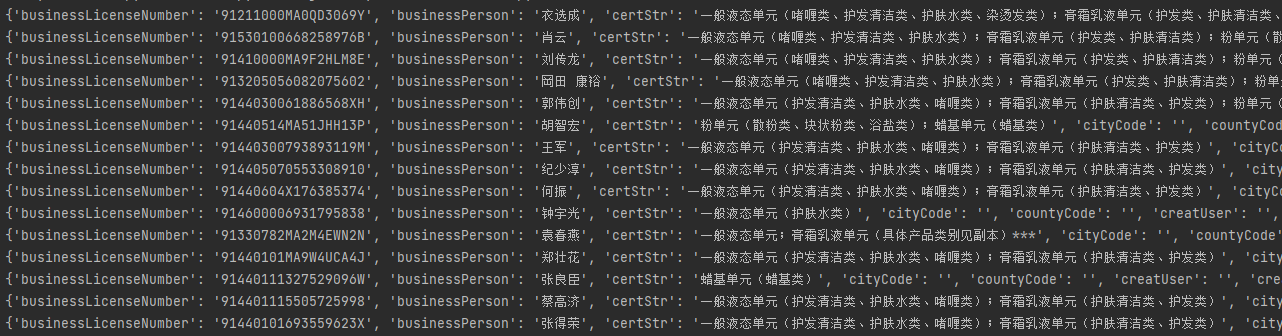
思路: 1.先点击页码在network查看请求url的变化 (1)如果数据变化且url不变 那么数据肯定是动态加载的 (2)如果数据变化且url变 那么数据可能是直接加载或动态加载 2.针对上述案例,数据是动态加载,所以需要研究每一次点击页码内部请求 3.研究请求体参数得知数据页由page表示 4.在外层加一个for循环 5.将数据逐次存入文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号