
8 在IPython Notebook 运行Python Spark 程序
8.1安装Anaconda
下载:wget https://mirrors.pku.edu.cn/anaconda/archive/Anaconda3-2021.05-Linux-x86_64.sh
安装:bash Anaconda3-2021.05-Linux-x86_64.sh -b
编辑~/.bashrc:sudo gedit ~/.bashrc

source ~/.bashrc
查看python版本

在data1,data2按同样的方法安装Anaconda
8.2在IPython Notebook使用Spark
创建工作目录:
mkdir -p ~/pythonwork/ipynotebook
cd ~/pythonwork/ipynotebook
输入:PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" pyspark,进入IPython Notebook界面
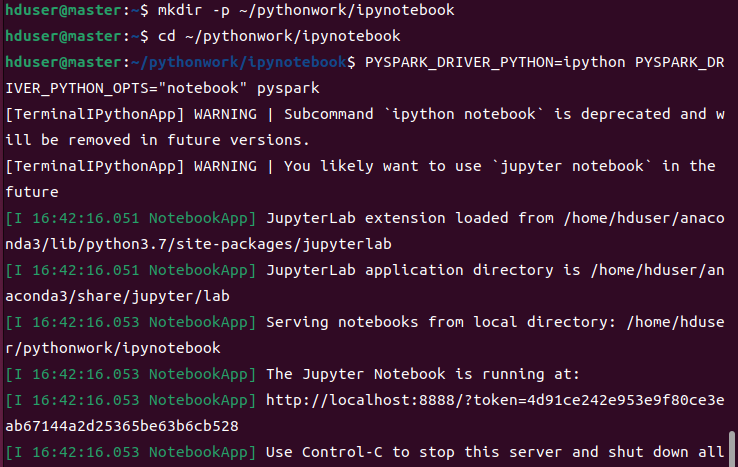
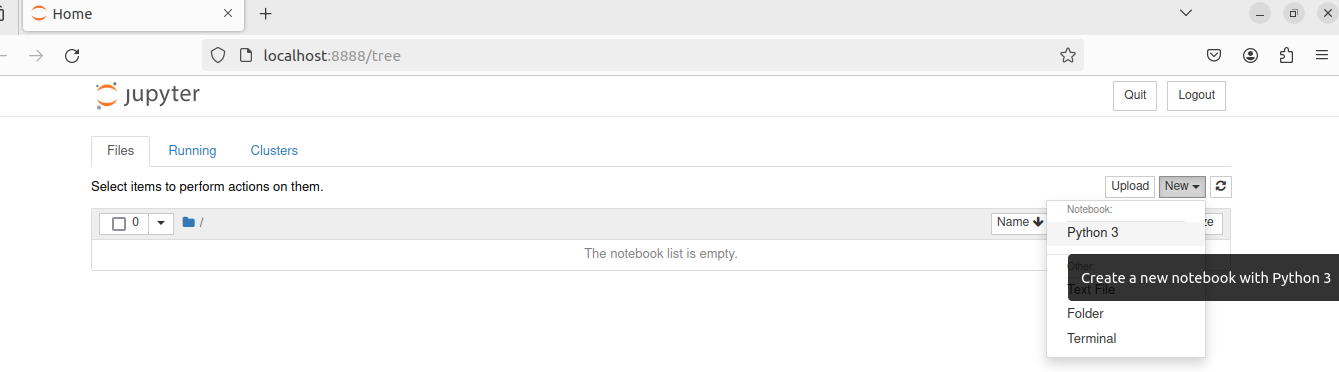
新建一个ipython notebook,命名为test。
测试(记得开hadoop集群):
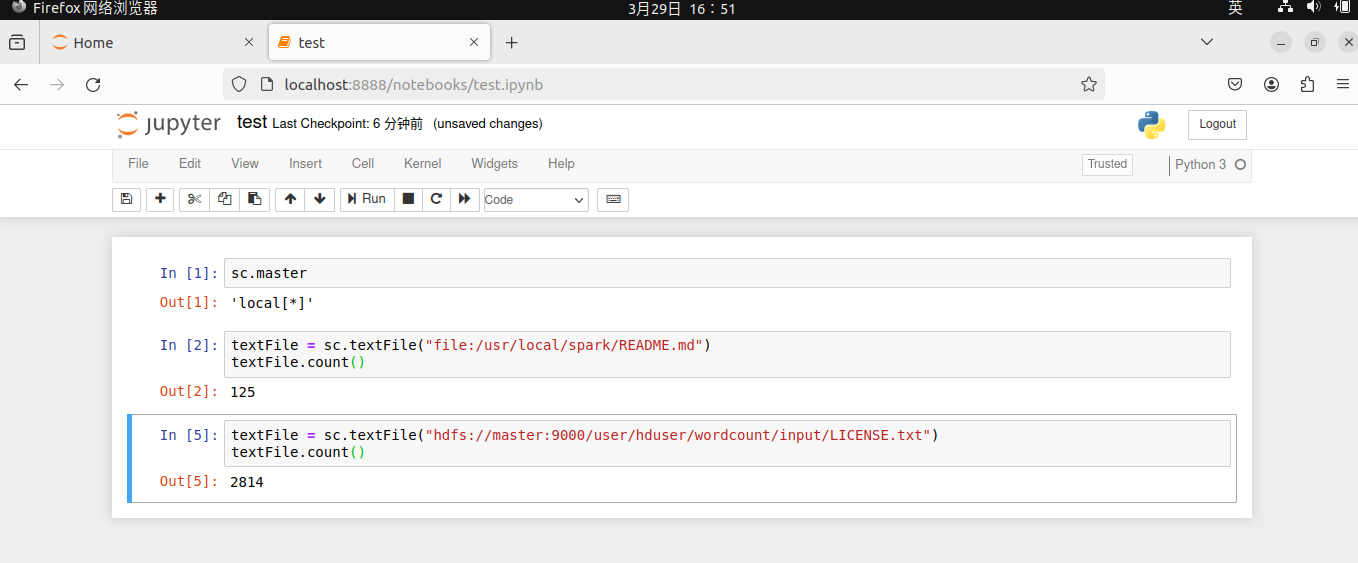
8.3使用IPython Notebook 在Hadoop YARN - client模式运行
启动Hadoop集群:start-all.sh
关闭hadoop安全模式: bin/hadoop dfsadmin -safemode leave
输入:PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop MASTER=yarn-client pyspark
重新运行test文件
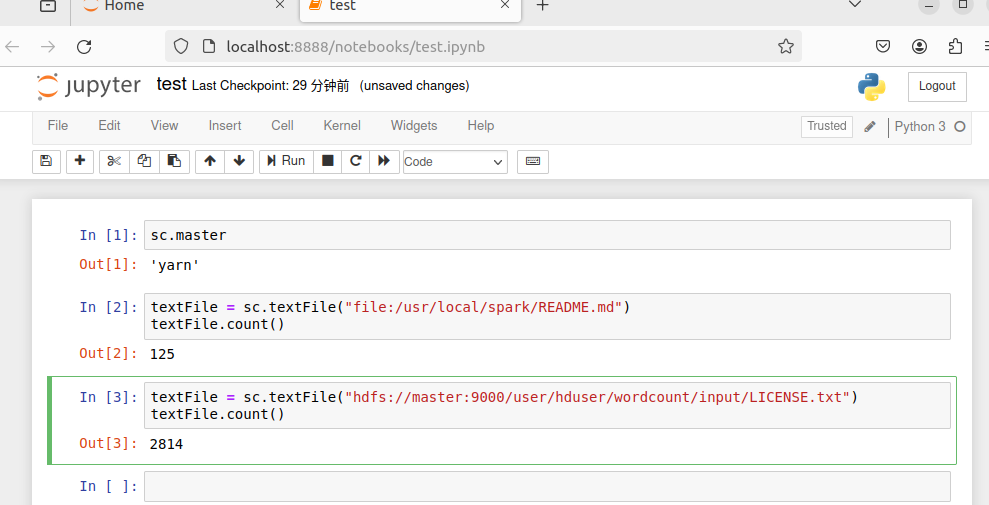
8.4.使用IPython Notebook在Spark Stand Alone模式运行
启动spark: /usr/local/spark/sbin/start-all.sh
输入命令:PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" MASTER=spark://master:8081 pyspark --num-executors 1 --total-executor-cores 2 --executor-memory 512m
运行test:
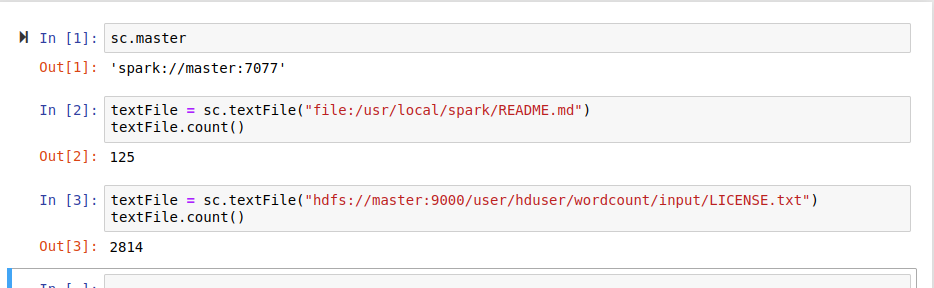
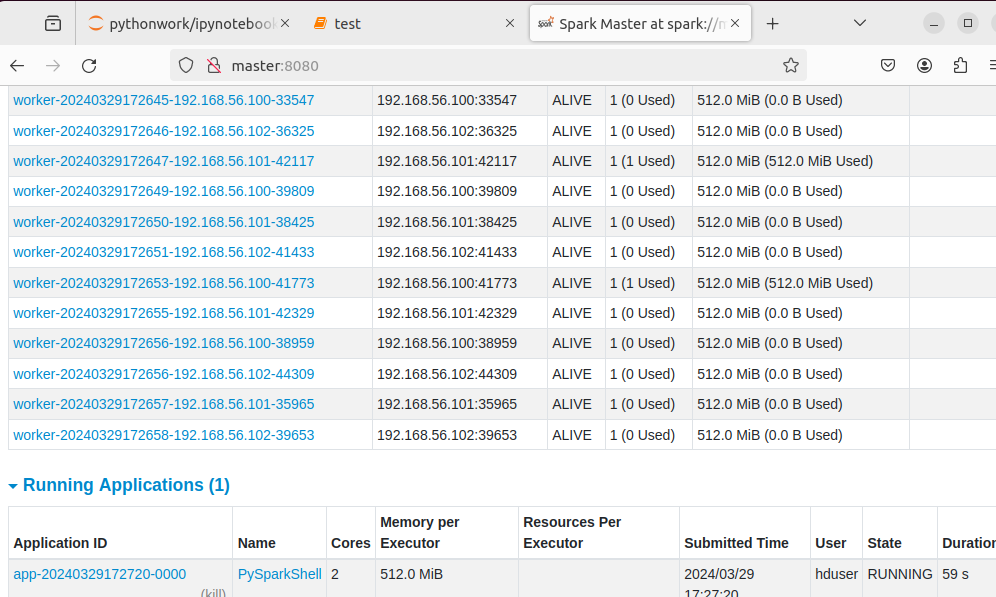
进入master:8080 可以看到正在运行的PysparkShell

 浙公网安备 33010602011771号
浙公网安备 33010602011771号