Apache Hudi表自动同步至阿里云数据湖分析DLA
1. 引入
Hudi 0.6.0版本之前只支持将Hudi表同步到Hive或者兼容Hive的MetaStore中,对于云上其他使用与Hive不同SQL语法MetaStore则无法支持,为解决这个问题,近期社区对原先的同步模块hudi-hive-sync进行了抽象改造,以支持将Hudi表同步到其他类型MetaStore中,如阿里云的数据湖分析DLA(https://www.aliyun.com/product/datalakeanalytics中。
2. 抽象
将Hudi表同步至Hive MetaStore的代码在hudi-hive-sync模块,为兼容更多类型MetaStore,现将其改造为如下模块
hudi-sync
|-hudi-sync-common
|-hudi-hive-sync
|-hudi-dla-sync
其中各模块说明如下
- hudi-sync-common表示元数据同步公共模块,用于存放一些用于同步的公共父类;
- hudi-hive-sync表示同步Hive模块;
- hudi-dla-sync表示同步阿里云DLA模块;
基于上述结构,用户可基于hudi-sync-common构建自定义的元数据同步逻辑。
3. 配置
下面以DLA为例,介绍如何通过Spark写入Hudi表后自动将Hudi表同步至DLA中,同步核心配置如下
df.write().format("hudi").
options(getQuickstartWriteConfigs()).
option(PRECOMBINE_FIELD_OPT_KEY(), "ts").
option(RECORDKEY_FIELD_OPT_KEY(), "name").
option(PARTITIONPATH_FIELD_OPT_KEY(), "location").
option("hoodie.embed.timeline.server", false).
option(TABLE_NAME, tableName).
option(TABLE_TYPE_OPT_KEY(), tableType).
option(META_SYNC_CLIENT_TOOL_CLASS(), "org.apache.hudi.dla.DLASyncTool").
option(META_SYNC_ENABLED_OPT_KEY(), "true").
option("hoodie.datasource.dla_sync.database", dbName).
option("hoodie.datasource.dla_sync.table", tableName).
option("hoodie.datasource.dla_sync.username", dlaUsername).
option("hoodie.datasource.dla_sync.password", dlaPassword).
option("hoodie.datasource.dla_sync.jdbcurl", dlaJdbcUrl).
option("hoodie.datasource.dla_sync.partition_fields", "location").
option("hoodie.datasource.dla_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
mode(saveMode).
save(basePath);
关键配置项说明如下:
META_SYNC_CLIENT_TOOL_CLASS()表示进行同步的类,指定为org.apache.hudi.dla.DLASyncTool表示通过DLASyncTool进行同步,与HiveSyncTool同步至Hive功能类似;hoodie.datasource.dla_sync.database表示同步至DLA中的数据库名;hoodie.datasource.dla_sync.table表示同步至DLA中的表名;hoodie.datasource.dla_sync.username表示连接DLA的用户名;hoodie.datasource.dla_sync.password表示连接DLA的密码;hoodie.datasource.dla_sync.jdbcurl表示连接DLA的JDBC连接;hoodie.datasource.dla_sync.partition_fields表示同步至DLA的分区字段;hoodie.datasource.dla_sync.partition_extractor_class表示同步至DLA的分区值解析器;
除了上述配置外,还需要在pom.xml依赖中新增hudi-dla-sync依赖(hudi.version为0.6.0-SNAPSHOT)
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-dla-sync</artifactId>
<version>${hudi.version}</version>
</dependency>
4. 同步
上述配置中,数据库名配置为hudi_dla_demo_db,表名配置为hudi_trips_dal_demo;其他用户名、密码、JDBC连接配置可参考如下链接: https://help.aliyun.com/document_detail/110829.html 。配置完后即可在Spark写入Hudi时自动将Hudi表同步至DLA,同步结果如下

查询表结果如下:

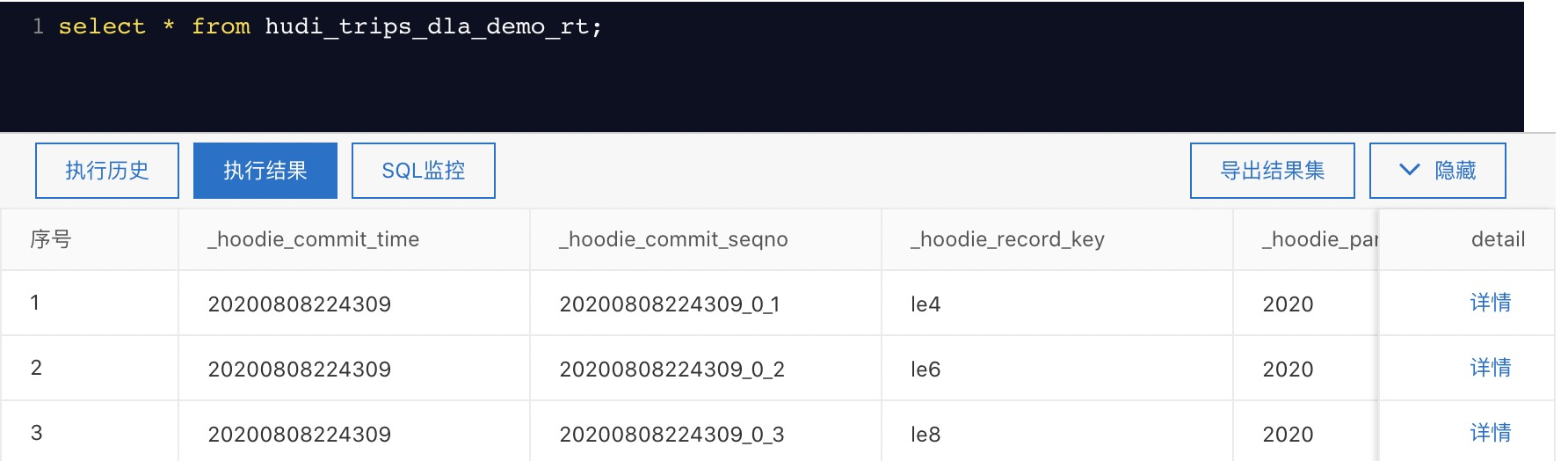
为方便用户直观感受到将Hudi表同步到DLA,可参考这里https://help.aliyun.com/document_detail/173653.html直接运行对应Jar包来快速构建基于Hudi和DLA的数据湖。
5. 总结
可以看到基于最新的Hudi版本,用户可自定义Hudi表同步MetaStore逻辑,同时只需要非常简单的配置即可完成自动同步,并且以同步至DLA为例,给出了关键配置,该功能将在近期发布的0.6.0版本中释出。
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:leesf 掌控之中,才会成功;掌控之外,注定失败。
出处:http://www.cnblogs.com/leesf456/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果觉得本文对您有帮助,您可以请我喝杯咖啡!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号