Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要
随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心能力。为利用Hudi的upsert和增量拉取能力,用户需要重写整个数据集让其成为Hudi表。此RFC提供一个无需重写整张表的高效迁移机制。
2. 背景
为了更好的了解此RFC,读者需要了解一些Hudi基础知识
2.1 记录级别元数据

上图展示了Hudi中每条记录的组织结构,每条记录有5个Hudi元数据字段:
- _hoodie_commit_time : 最新记录提交时间
- _hoodie_commit_seqno : 在增量拉取中用于在单次摄取中创建多个窗口。
- _hoodie_record_key : Hudi记录主键,用来处理更新和删除
- _hoodie_partition_path : 分区路径
- _hoodie_file_name : 存储记录的文件名
2.2. 当前引导(Bootstrap)方案
Hudi提供了内置HDFSParquetImporter工具来完成一次性迁移整个数据集到Hudi中,当然也可以通过Spark Datasource API来进行一次简单的读取和写入。
一旦迁移完成,那么就可以按照普通方式写入Hudi数据集,具体可参考这里。更多详细讨论可参考这里,其中包括部分迁移方案。总而言之现在大致有两种迁移方案。
2.2.1 迁移新分区至Hudi
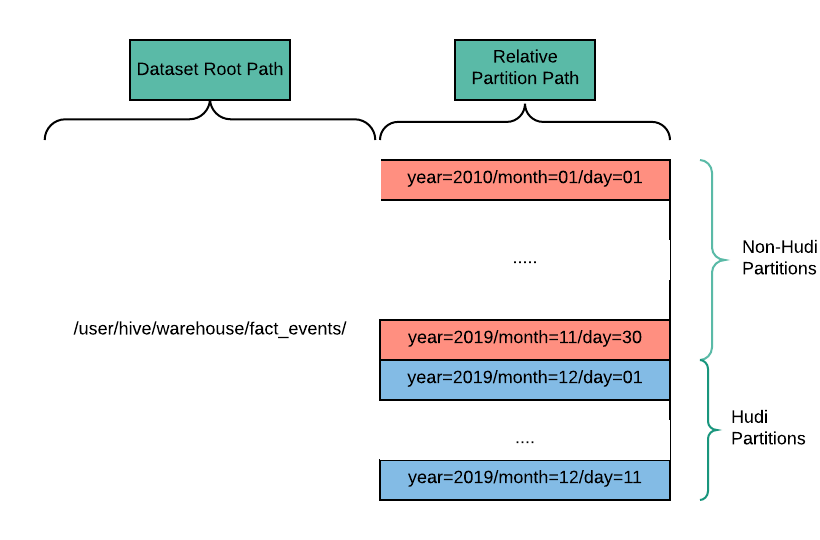
Apache Hudi分区可以和其他非Hudi分区共存,这种情况下会在Apache Hudi查询引擎侧做处理以便处理这种混合分区,这可以让用户使用Hudi来管理新的分区,同时保持老的分区不变。在上述示例中,历史分区从Jan 1 2020到Nov 30 2019为非Hudi格式,从Dec 01 2019开始的新分区为Hudi格式。由于历史分区不被Hudi管理,因此这些分区也无法使用Hudi提供的能力,但这在append-only类型数据集场景下非常完美。
2.2.2 将数据集重写至Hudi
如果用户需要使用Apache Hudi来管理数据集的所有分区,那么需要重新整个数据集至Hudi,因为Hudi为每条记录维护元数据信息和索引信息,所以此过程是必须的。要么一次性重新整个数据集,要么将数据集切分为多个分区,然后加载。更详细的讨论可参考这里。
2.3 重写数据集至Hudi
即便是一次性操作,但对于大规模数据迁移而言也是非常有挑战的。大规模事实表通常有大量的列,嵌套列也是比较常见情况,重写整个数据集会导致非常高的IO和占用太多计算资源。
提供一个高效迁移历史存量表机制对用户使用Apache Hudi非常关键,此RFC就提供了这样一种机制。
3. 方案
下图展示了每条记录的组织结构,为了方便理解,我们使用行格式进行展示,虽然实际使用的列存,另外假设下图中使用了BloomIndex。
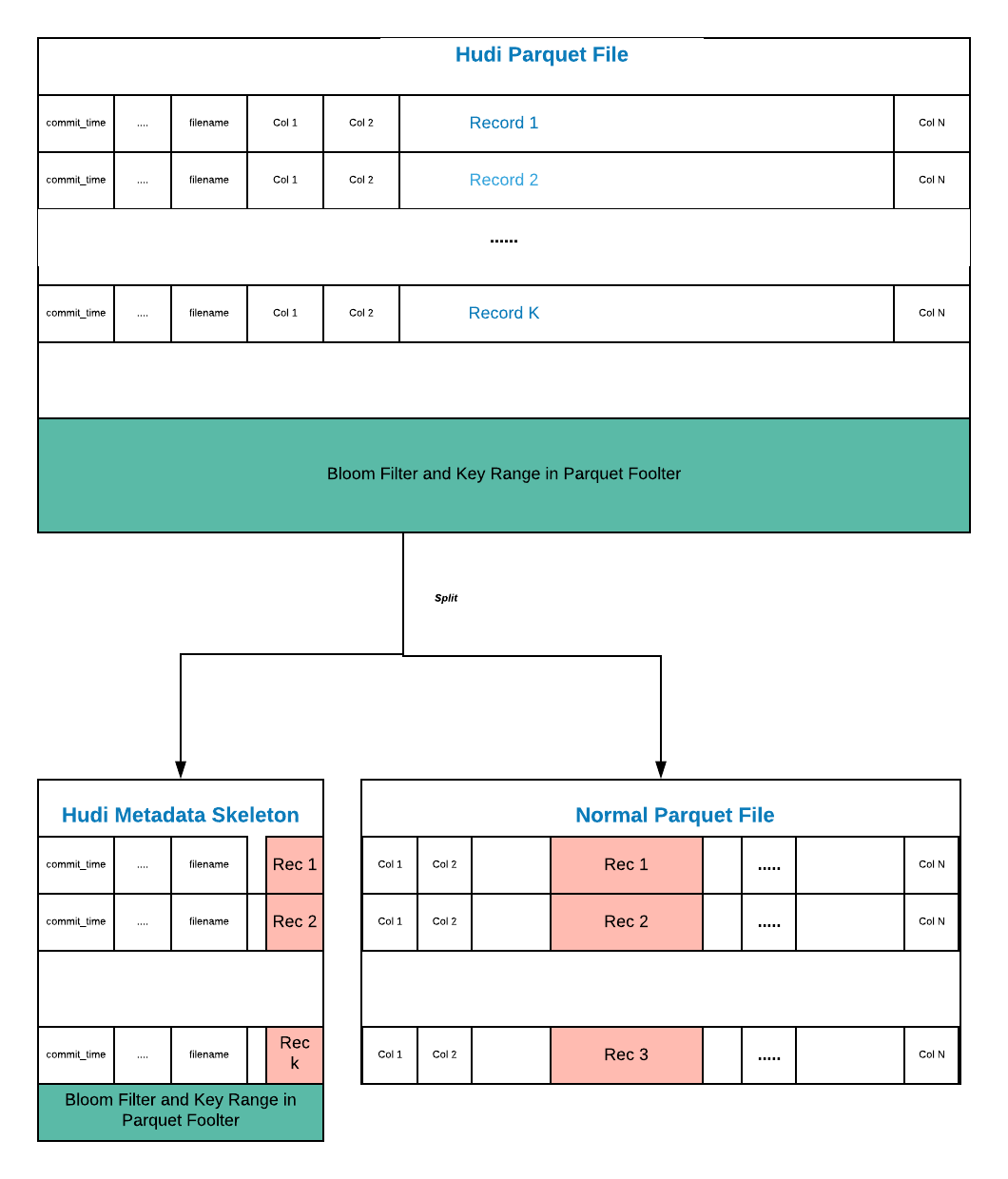
正如上图所示,Apache Hudi文件主要包含了三部分。
-
对于每条记录,Hudi维护了5个元数据字段,索引从0 ~ 4。
-
对于每条记录,原始数据列代表了记录(原始数据)。
-
另外文件Footer存放索引信息。
原始数据表通常包含很多列,而(1)和(3)让Hudi的parquet文件变得比较特别。
为了方便讨论,我们将(1)和(3)称为Hudi骨架,Hudi骨架包含了额外的元数据信息以支持Hudi原语。
一个想法是解耦Hudi骨架和实际数据(2),Hudi骨架可以存储在Hudi文件中,而实际数据存储在外部非Hudi文件中(即保持之前的parquet文件不动)。
只要Hudi能够理解新的文件格式,那么引导一个存量表就只需要生成Hudi骨架文件即可。对生产环境中表进行了粗略测试,该表包含3500个分区,25W个文件,超过600亿条数据。新的引导过程使用500个executor,每个executor为1核和4G内存,总耗时1个小时。老的引导过程使用超过4倍的executor(2000个),总耗时差不多24小时。
4. 新引导过程
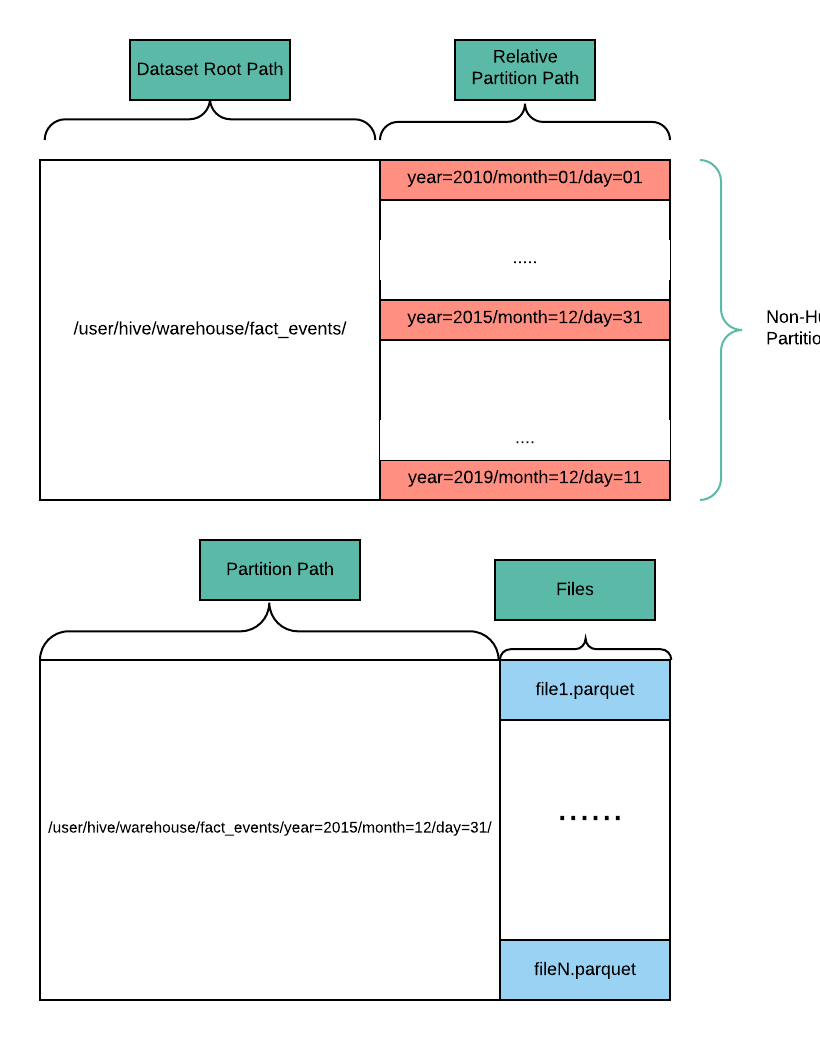
新的引导过程包含如下步骤。首先假设parquet数据集(名为fact_events)需要迁移至Hudi数据集,数据集根路径为/user/hive/warehouse/fact_events,并且是基于日期的分区,在每个分区内有很多parquet文件,如下图所示。
假设用户使用新的引导机制引导至新的Hudi数据集名为fact_events_hudi,路径为/user/hive/warehouse/fact_events_hudi。
-
用户在原始数据集上停止所有写操作。
-
用户使用DeltaStreamer或者独立工具开始启动引导,用户需要提供如下引导参数
- 原始(非Hudi)数据集位置。
- 生成Hudi键的列。
- 迁移的并发度。
- 新的Hudi数据集位置。
-
引导时Hudi会扫描原始表位置(
/user/hive/warehouse/fact_events)的分区和文件,进行如下操作 : -
- 在新数据集位置创建Hudi分区,在上述示例中,将会在
/user/hive/warehouse/fact_events_hudi路径创建日期分区。 - 生成唯一的文件ID并以此为每个原始parquet文件生成Hudi骨架文件,同时会使用一个特殊的commit,称为
BOOTSTRAP_COMMIT。下面我们假设BOOTSTRAP_COMMIT对应的timestamp为000000000,例如一个原始parquet文件为/user/hive/warehouse/fact_events/year=2015/month=12/day=31/file1.parquet,假设新生成的文件ID为h1,所以相应的骨架文件为/user/hive/warehouse/fact_events_hudi/year=2015/month=12/day=31/h1_1-0-1_000000000.parquet.。 - 生成一个特殊的bootstrap索引,该索引将生成的骨架文件映射到对应的原始parquet文件。
- 在新数据集位置创建Hudi分区,在上述示例中,将会在
-
- 使用Hudi timeline状态变更进行原子性提交,也支持回滚操作。
-
如果开启了Hive同步,那么会创建一张Hudi类型的Hive外表,并指向
/user/hive/warehouse/fact_events_hudi路径。 -
随后的写操作将作用在Hudi数据集上。
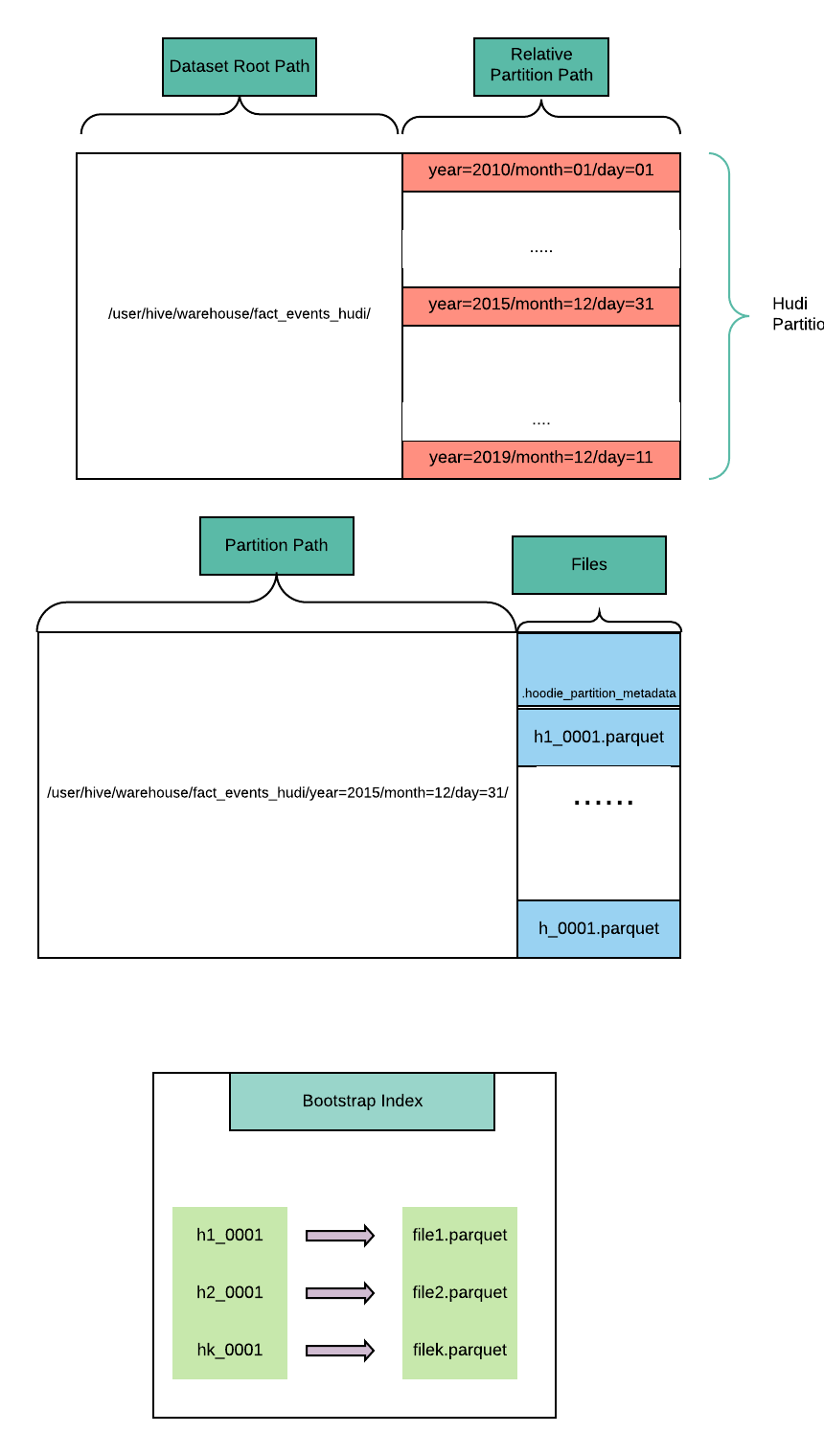
4.1 引导(Bootstrap)索引
索引用于映射Hudi骨架文件和原始包含数据的parquet文件。该信息会作为Hudi file-system view并用于生成FileSlice,Bootstrap索引和CompactionPlan类似,但与CompactionPlan不同的是引导索引可能更大,因此需要一种高效读写的文件格式。
Hudi的file-system view是物理文件名到FileGroup和FileSlice的抽象,可以支持到分区级别的API,因此Bootstrap索引一定需要提供快速查找单个分区索引信息的能力。
一个合适的存储结构为Hadoop Map文件,包含两种类型文件:
- 引导日志:顺序文件,每一个条目包含单个分区内索引信息,对于分区下引导索引的变更只需要在日志文件中顺序添加新的条目即可。
- 索引引导日志:包含Hudi分区、文件名和offset的顺序文件,offset表示引导索引日志条目对应Hudi分区的位置。
基于上述结构,迁移过程中使用Spark并发度可以控制迁移时的日志文件数量,并相应提升生成引导索引的速度。Hudi的Reader和Writer都需要加载分区的引导索引,索引引导日志中每个分区对应一个条目,并可被读取至内存或RocksDB中。
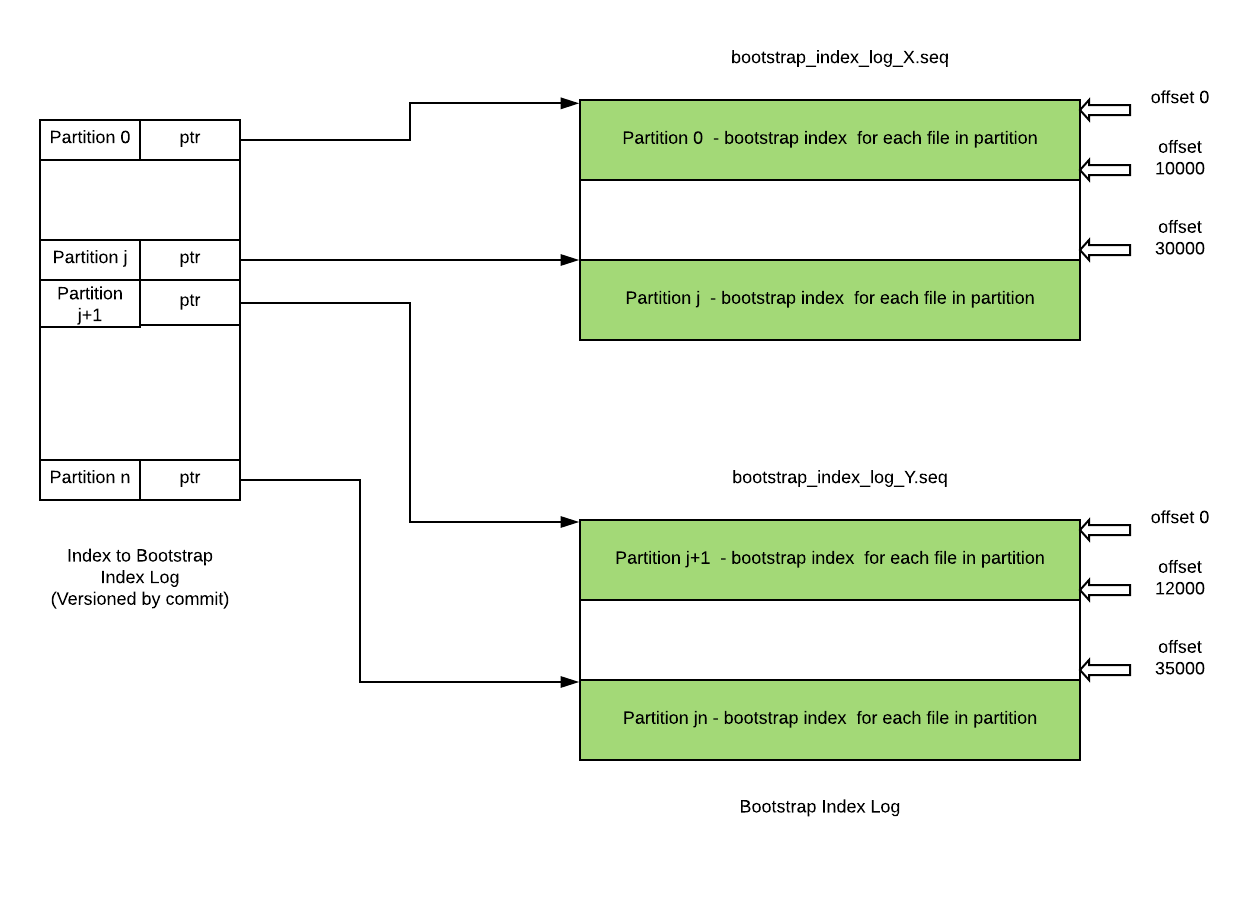
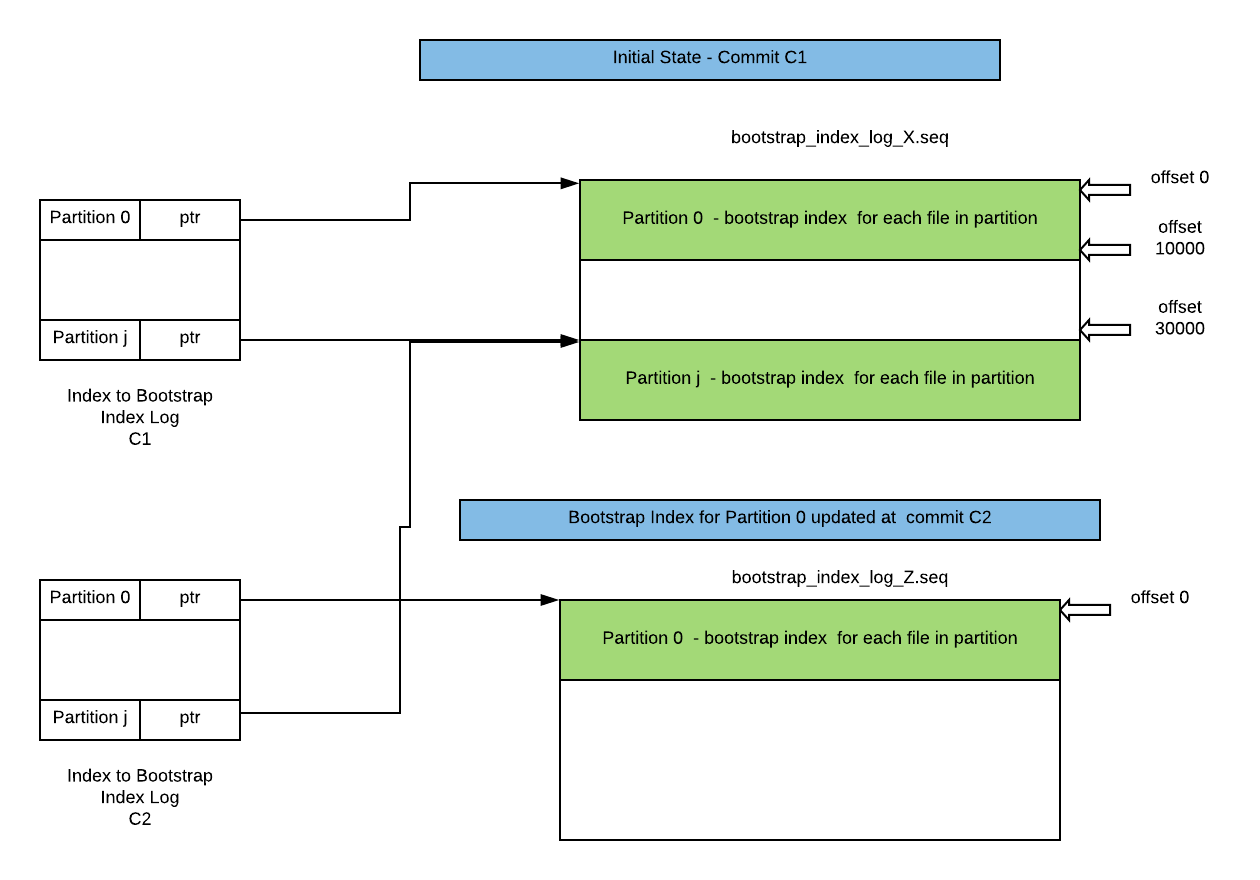
Hudi Cleaner会移除旧的不再需要的FileSlice,由于Hudi骨架是FileSlice的一部分,因此也适用于Clean。无论何时FileSlice被清理,即便清理对正确性不是必须的,引导索引都需要进行相应的更新,这会保证状态的一致性并减少引导索引的大小。为支持ACID,Hudi Timeline也支持类似的MVCC机制,以便保证引导索引的最新状态,同时隔离更新和并发读取。
4.2 Upsert支持及读取场景
本节将介绍Hudi为支持这种新的文件存储和在引导的分区上支持Hudi原语的抽象。
一个FileSlice代表一个Hudi文件的所有快照,其包含一个基础文件和一个或多个delta增量文件。我们将引导索引信息封装在FlieSlice级别,所以一个FileSlice可以提供外部原始数据位置信息。
在Hudi中我们实现了file-system view的抽象,即将物理文件映射为FileSlice。此抽象也会让FileSlice包含抽象,引导索引项(骨架文件到外部文件映射),以便上层引擎可以以一致的方式处理外部原始数据文件。
基于这个模型,如果我们对fact_events_hudi表的分区更新了1 - K条记录,将会有如下步骤。
- 假设upsert操作对应的时间为
C1,C1大于BOOTSTRAP_COMMIT(000000000)。 - 假设使用BloomIndex,将会直接在Hudi骨架文件查找索引,假设Hudi骨架文件
h1有所有的记录。 - 在下面的描述中,
常规Hudi文件表示一个Hudi Parquet文件,并包含记录级别的元数据字段信息,同时包含索引,即包含前面所述的(1),(2),(3)。对于Copy-On-Write类型表,在引导写入阶段中生成了最新的FileSlice,对应的文件ID为h1,会读取位于/user/hive/warehouse/fact_events路径的外部原始文件,Hudi MergeHandle将会并行读取外部文件和Hudi元数据文件,然后合并记录成为一个新的常规Hudi文件,并生成对应文件ID为h1的新版本。
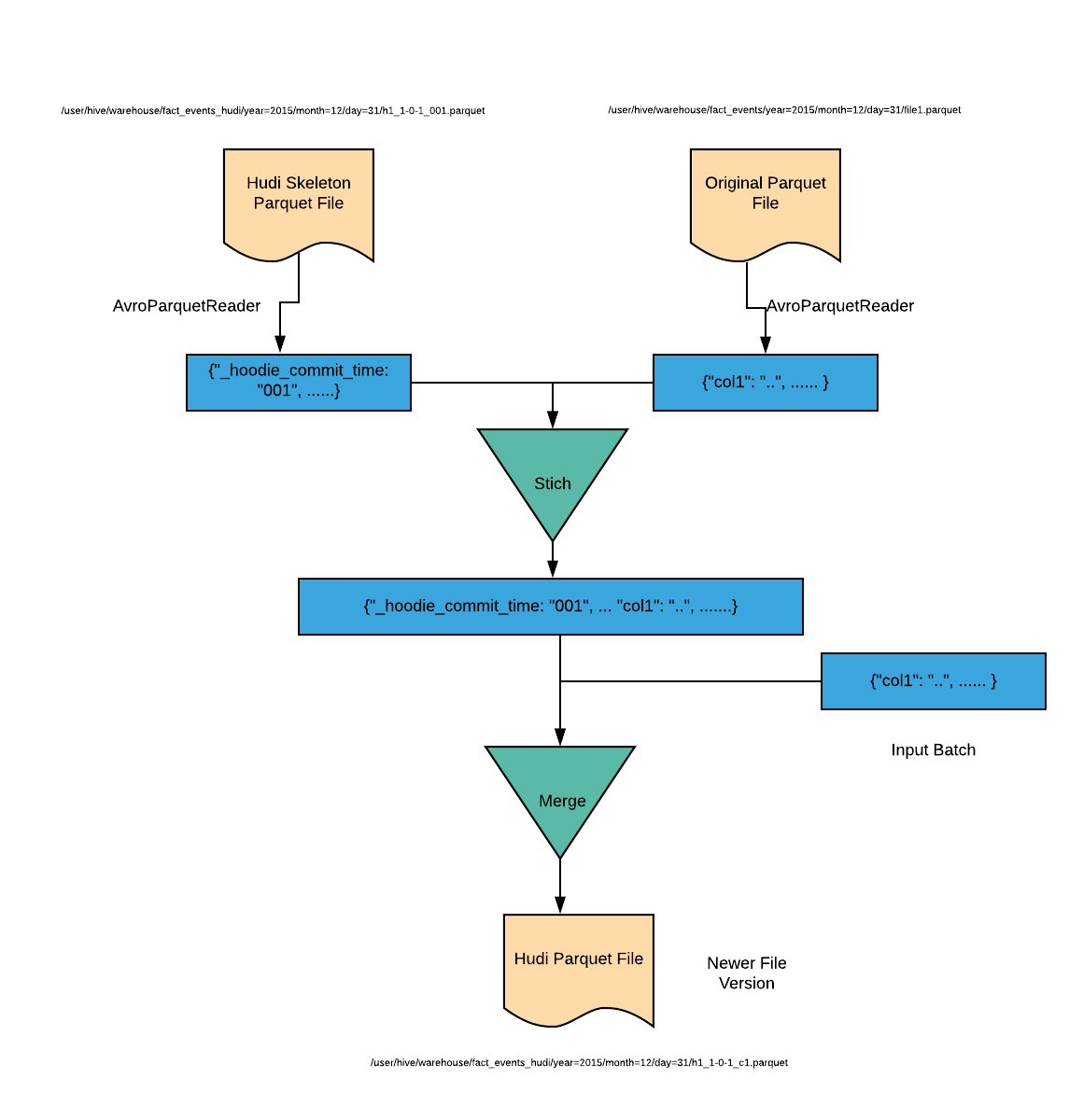
- 对于Merge-On-Read类型表,摄入仅仅写入增量日志文件,然后进行Compaction,类似Copy-On-Write模式下生成一个新的
常规Hudi文件。
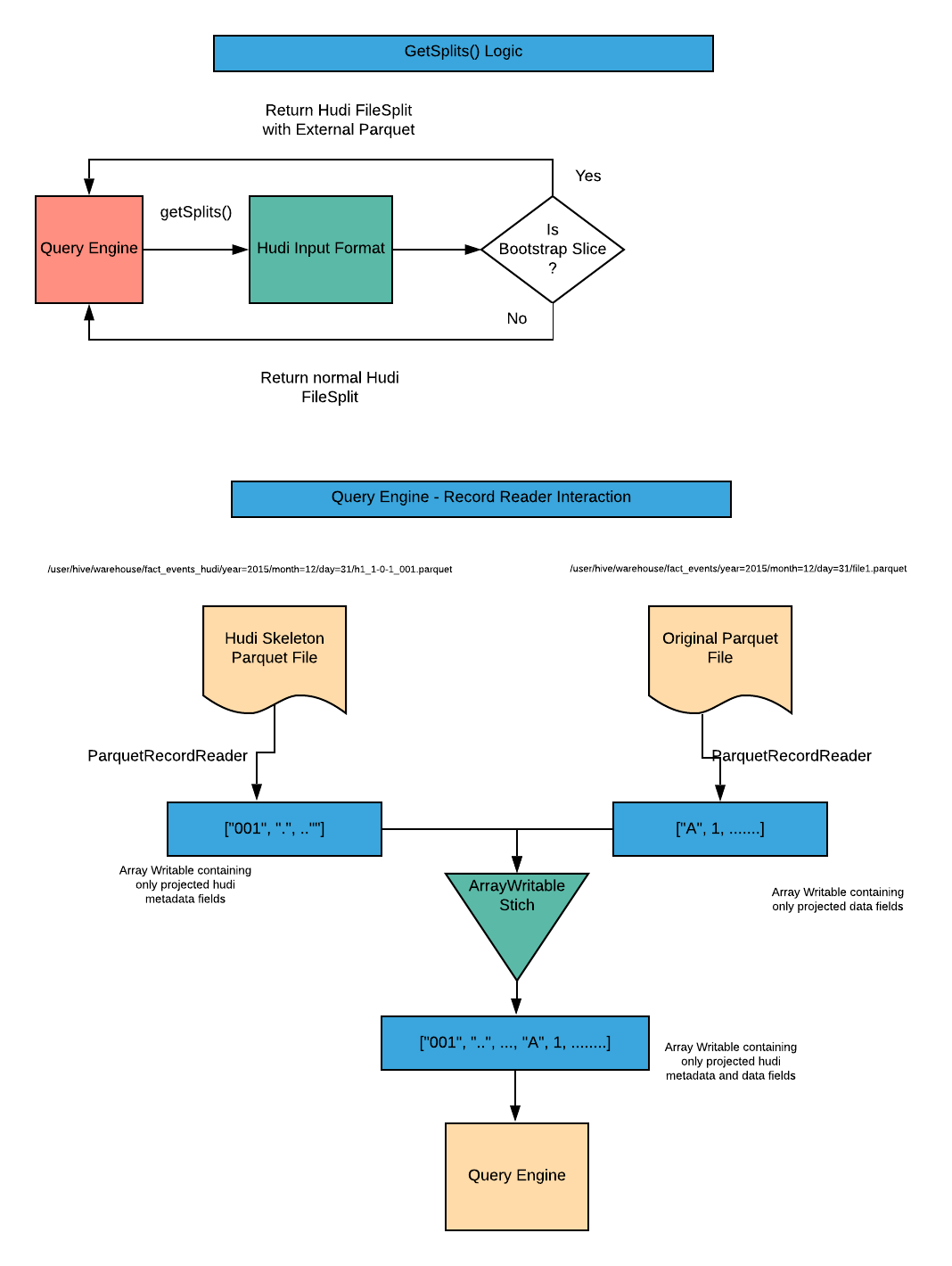
为集成查询引擎,Hudi自定义实现了InputFormat,这些InputFormat将会识别特殊的索引提交并会合并Hudi的元数据字段和外部Parquet表中的实际数据字段,提供常规Hudi文件。注意只会从Parquet文件中读取投影字段。下图展示了查询引擎是如何工作的。
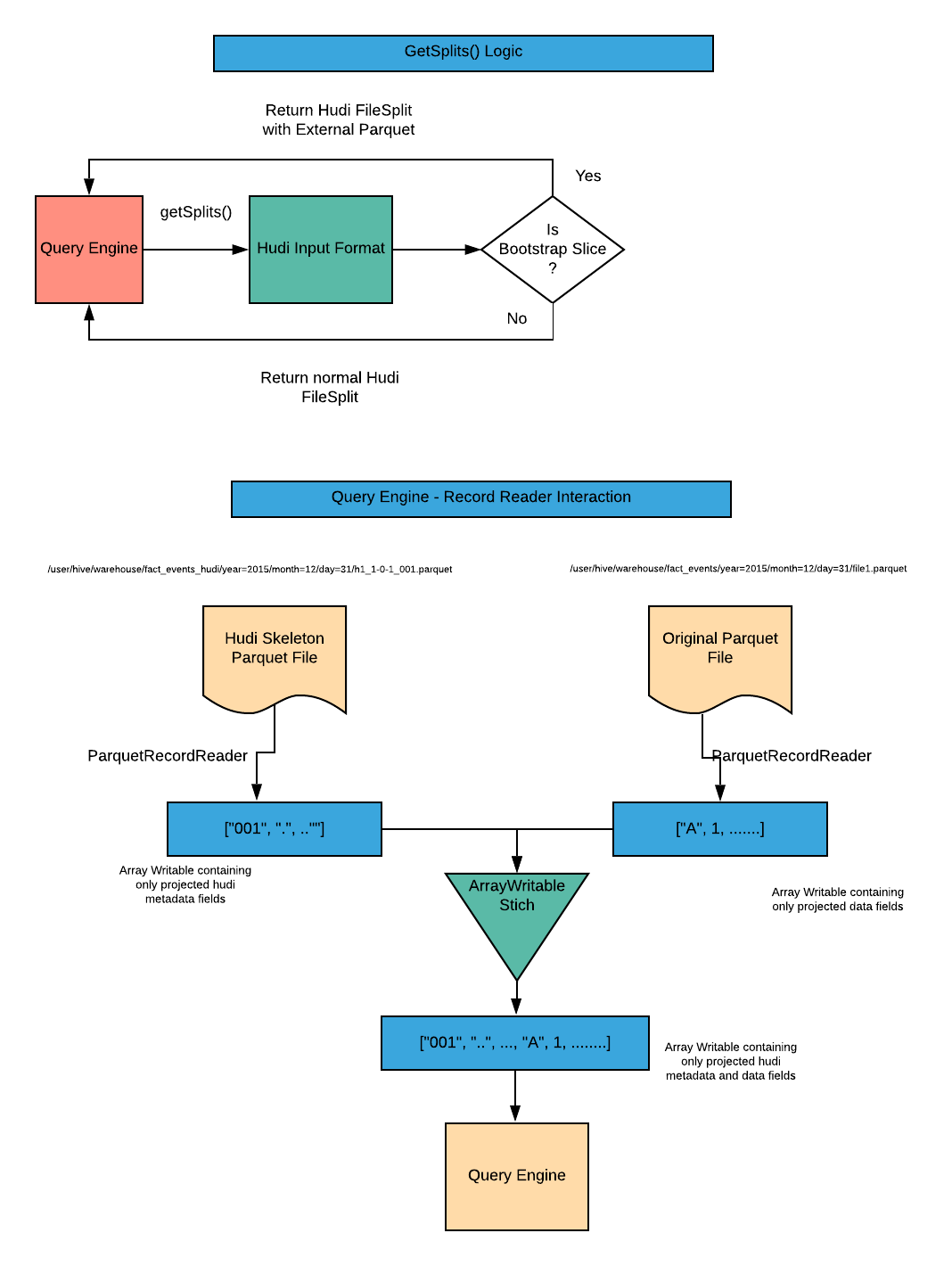
4.3 要求
对于任何Hudi数据集,都需要提供RecordKey的唯一键约束,因此,查询列时需要考虑到原始数据的唯一性,否则不能保证对与重复key对应的记录进行正确的upsert。
5. Data Source支持
此部分说明如何集成Hudi引导表和Spark DataSource,Copy-On-Write表可以按照如下步骤使用Hudi数据源读取。
val df = spark.read.format("hudi").load("s3://<bucket>/table1/")
val df = spark.read.format("hudi").load("s3://<bucket>/table1/partition1/")
注意:这里也可以传递路径模式以保持兼容性,但必须自定义对模式的处理。
5.1 COW快照查询
这里的想法是实现一个新的Spark Relationship和Spark RDD用来扫描和读取引导表。自定义Relation将实现PruneFilteredScan允许支持过滤器下推和列剪裁。对于RDD,每个分区将是数据文件+可选的骨架文件组合,这些组合将被发送到一个任务,以执行合并并返回结果。
下面的代码框架将提供实现的高层次概要,API签名可能会随着我们实现而改变。
package org.apache.hudi.skeleton
2.
3. import org.apache.spark.rdd.RDD
4. import org.apache.spark.sql.{Row, SQLContext}
5. import org.apache.spark.sql.sources.{BaseRelation, Filter, PrunedFilteredScan}
6. import org.apache.spark.sql.types.StructType
7.
8. case class HudiBootstrapTableState(files: List[HudiBootstrapSplit])
9.
10. case class HudiBootstrapSplit(dataFile: String,
11. skeletonFile: String)
12.
13. class HudiBootstrapRelation(val sqlContext: SQLContext,
14. val basePath: String,
15. val optParams: Map[String, String],
16. val userSchema: StructType)
17. extends BaseRelation with PrunedFilteredScan {
18.
19. override def schema: StructType = ???
20.
21. override def buildScan(requiredColumns: Array[String],
22. filters: Array[Filter]): RDD[Row] = {
23. // Perform the following steps here:
24. // 1. Perform file system listing to form HudiBootstrapTableState which would
25. // maintain a mapping of Hudi skeleton files to External data files
26. //
27. // 2. Form the HudiBootstrapRDD and return it
28.
29. val tableState = HudiBootstrapTableState(List())
30. new HudiBootstrapRDD(tableState, sqlContext.sparkSession).map(_.asInstanceOf[Row])
31. }
32. }
1. package org.apache.hudi.skeleton
2.
3. import org.apache.spark.{Partition, TaskContext}
4. import org.apache.spark.rdd.RDD
5. import org.apache.spark.sql.SparkSession
6. import org.apache.spark.sql.catalyst.InternalRow
7.
8. class HudiBootstrapRDD(table: HudiBootstrapTableState,
9. spark: SparkSession)
10. extends RDD[InternalRow](spark.sparkContext, Nil) {
11.
12. override def compute(split: Partition, context: TaskContext): Iterator[InternalRow] = {
13. // This is the code that gets executed at each spark task. We will perform
14. // the following tasks here:
15. // - From the HudiBootstrapPartition, obtain the data and skeleton file paths
16. // - If the skeleton file exists (bootstrapped partition), perform the merge
17. // and return a merged iterator
18. // - If the skeleton file does not exist (non-bootstrapped partition), read
19. // only the data file and return an iterator
20. // - For reading parquet files, build reader using ParquetFileFormat which
21. // returns an Iterator[InternalRow].
22. // - Merge the readers for skeleton and data files and return a single
23. // Iterator[InternalRow]
24. // - Investigate and implement passing of filters and required schema down
25. // for pruning and filtering optimizations that ParquetFileFormat provides.
26. }
27.
28. override protected def getPartitions: Array[Partition] = {
29. // Form the partitions i.e. HudiBootstrapPartition from HudiBootstrapTableState.
30. // Each spark task would handle one partition. Here we can do one of the
31. // following mappings:
32. // - Map one HudiBootstrapSplit to one partition, so that each task would
33. // perform merging of just one split i.e. data file and skeleton
34. // - Map multiple HudiBootstrapSplit to one partition, so that each task
35. // would perform merging of multiple splits i.e. multiple data/skeleton files
36.
37. table.files.zipWithIndex.map(file =>
38. HudiBootstrapPartition(file._1, file._2)).toArray
39. }
40. }
41.
42. case class HudiBootstrapPartition(split: HudiBootstrapSplit,
43. index: Int) extends Partition
优势
- 不需要对Spark代码做任何修改。
- 提供一种控制文件列表逻辑的方法,以列出骨架文件,然后将它们映射到相应的外部数据文件。
- 提供对每个分区内容和计算逻辑的控制。
- 相同的设计也可应用于Merge-On-Read表。
缺点
- 不支持文件切片,这可能会影响读取性能。每个任务只处理一个骨架+数据文件的合并。但目前还没有一种方法来切分骨架+数据文件,以便能够以完全相同的行偏移量切分它们,然后在以后合并它们。即使使用InputFormat列合并逻辑,我们也必须禁用文件切片,并且每个切片都将映射到一个文件。因此,从某种意义上说,我们会遵循类似的方法。
5.2 COW增量查询
对于增量查询,我们必须使用类似的逻辑来重新设计当前在Hudi代码中实现的IncrementalRelation。我们可能使用相同快照查询的RDD实现。
6. 总结
此功能对数据库备份场景非常有用,无需重写整张原始Parquet表,利用更少的资源就可以完成原始Parquet表到Hudi表的转化,此功能将在0.6.0版本(下个版本)释出,敬请期待。
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:leesf 掌控之中,才会成功;掌控之外,注定失败。
出处:http://www.cnblogs.com/leesf456/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果觉得本文对您有帮助,您可以请我喝杯咖啡!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号