
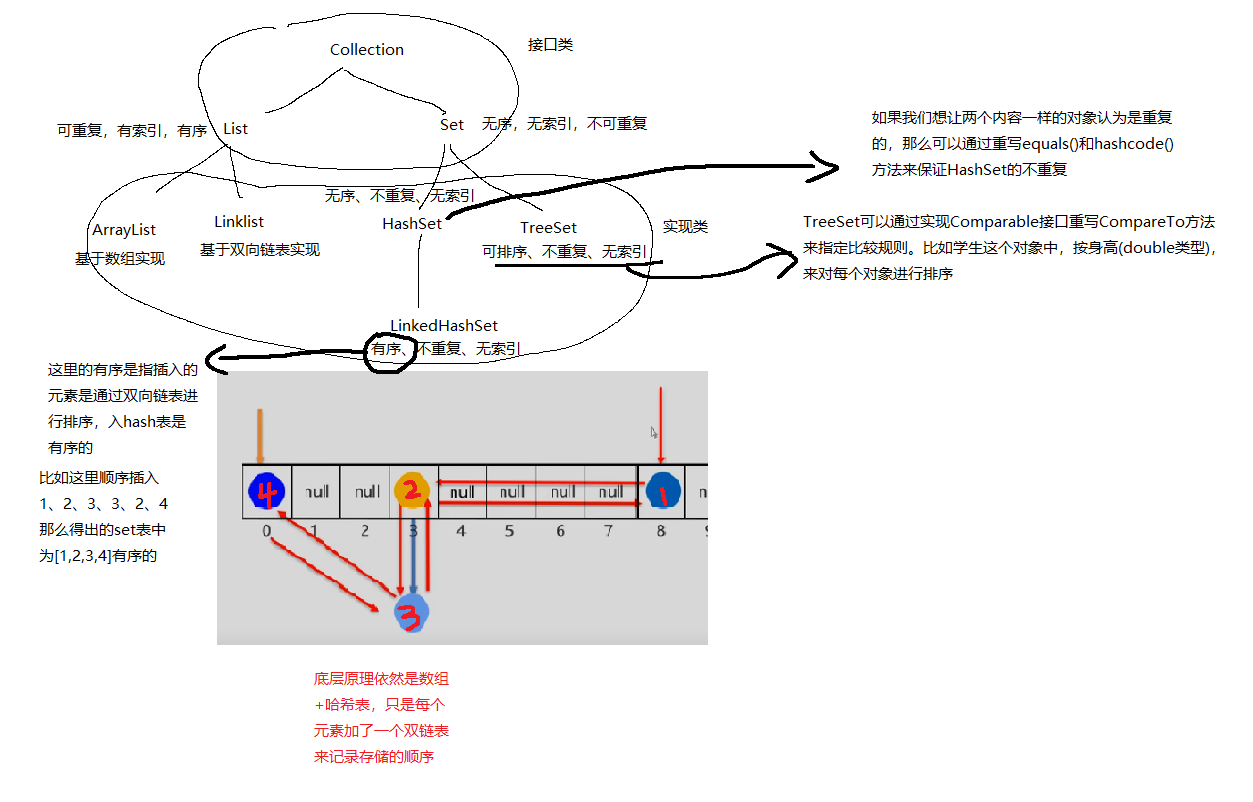
Java数据结构_Collection类
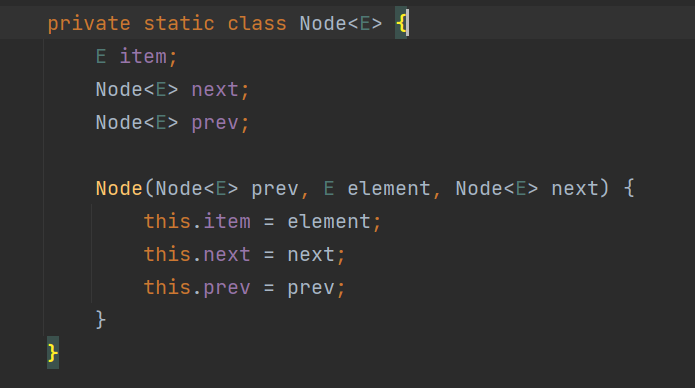
双链表结构
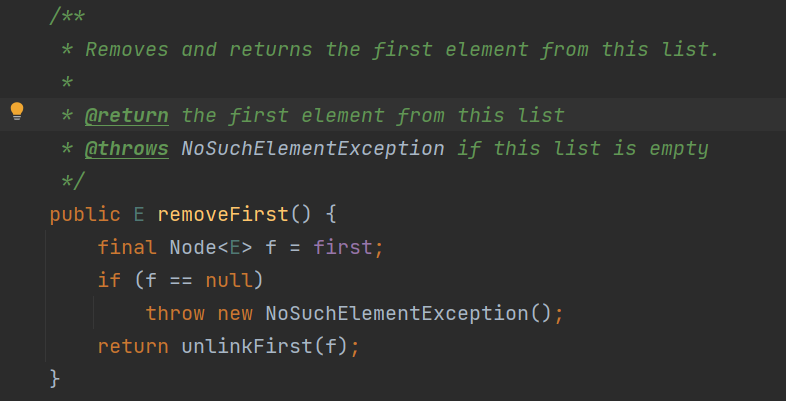
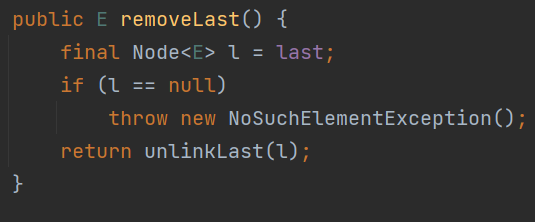
LinkedList 可以完成队列结构 栈结构 (双向链表)
栈 对头结点进行add和remove
pop的底层就是 push是对双向链表的头结点removeFirst
push是对双向链表的尾结点addFirst
队列就是对头进行删除(removeFirst)队尾进行入队(addLast)

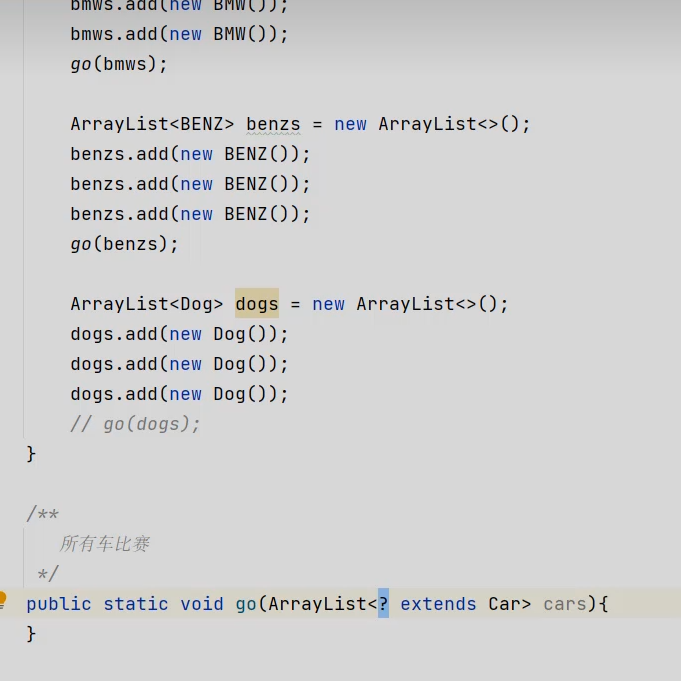
使用 ? extend 父类 这样除了父类类型的ArrayList可以传入 别的不能传入 比如狗这个ArrayList
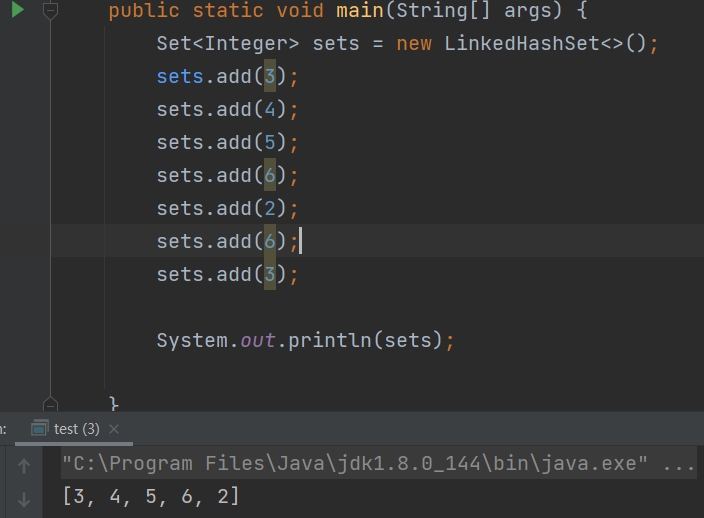
linkHashSet
TreeSet
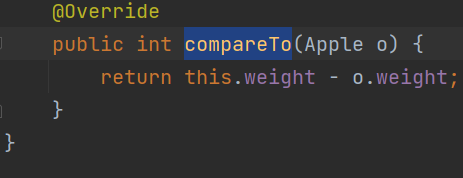
TreeSet类需要实现Comparable<E>的compareTo方法并且重写指定规则

重写compareTo方法,这里指定weight升序排列
如果有weight相等情况我们可以这样写
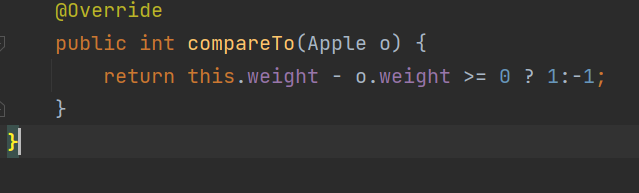
排除了相等还是分了大小的情况
也可以使用集合自带的比较器对象指定规则:
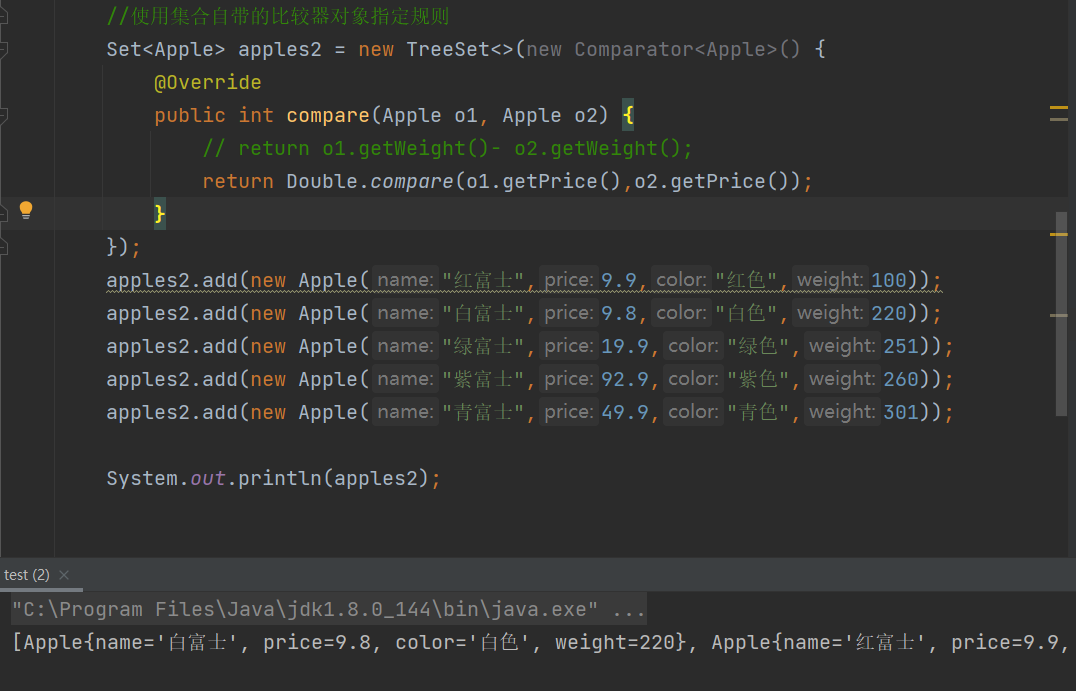
注意:如果规则中是按照double等带小数点类型的话 比较最好调用double.compare(double d1,double d2)方法比较,如果直接相减的话可能两个相差不大的值比如 4.5 - 4.3 = 0.2,结果取整数,得到了两个对象都是相等的,其实4.5比4.3是要大的,可以看double.compare方法中是写的比较完美的,考虑到了很多情况,这就是为什么要看Java源码的原因,写的很严谨!值得学习!

引发思考?为什么重写equals方法要重写hashcode方法?
比如:我们new了两个对象
People s1 = new Students("张三",16,"男",89.5);
People s2 = new Students("张三",16,"男",89.5);
两个对象的hash值肯定不一样,但是内容是完全一致的,这时候用hashset存储可能认为是相同的,这时候set的不可重复性无法保证
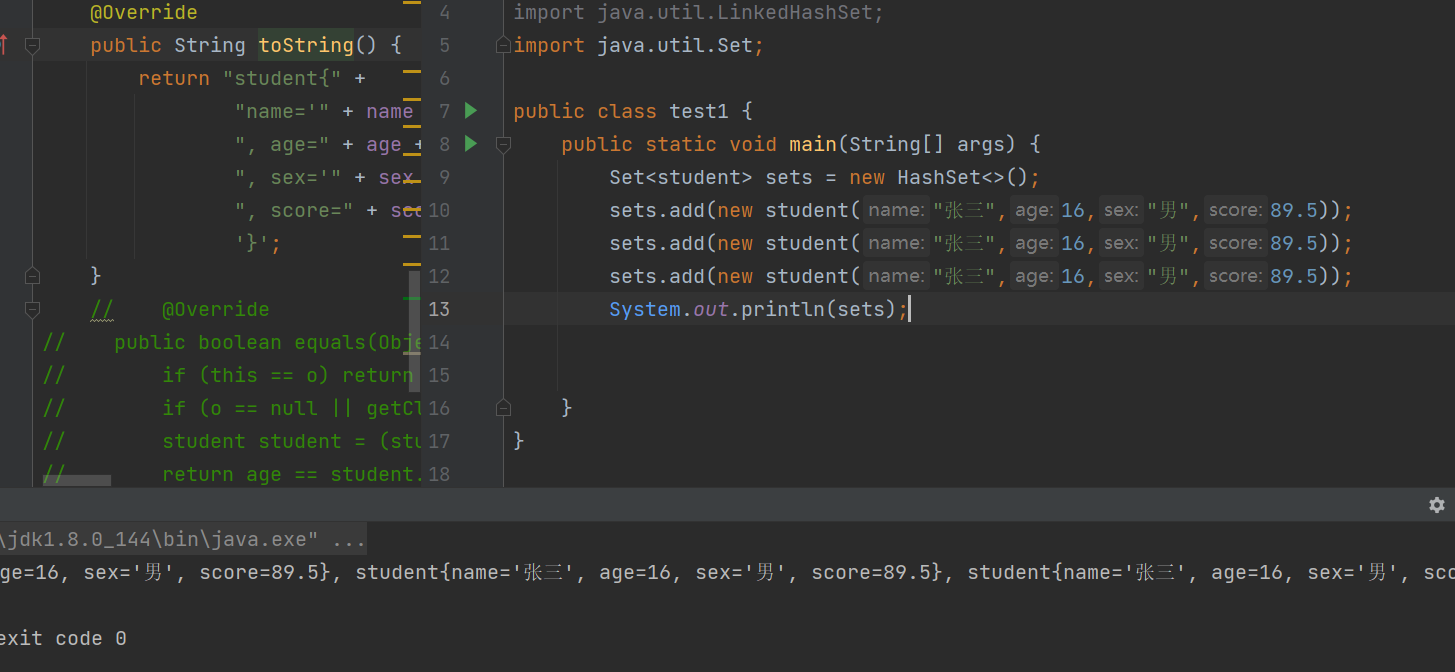
只有重写了equals方法和hashcode方法才能保证,约定我们认为内容一样,及时他们的hash值不一样,也是一样的对象。
这两个方法底层都是调用底层对象的地址,所以两个必须一起重写,不然重写了一个,另一个还是按照地址对比,对象还是不一样,所以两个方法必须同时修改重写,才能一致。
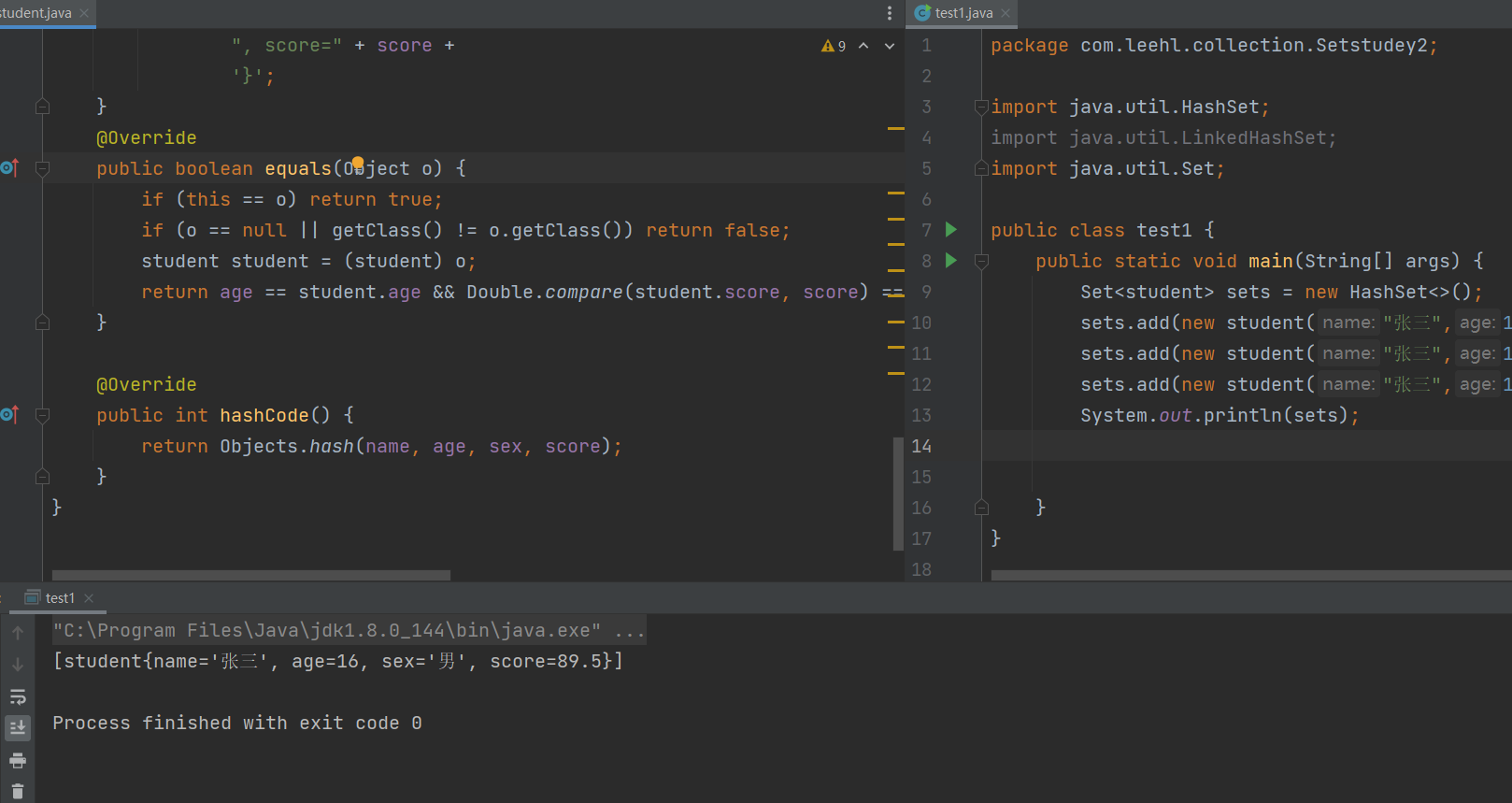
重写的hash方法只对传入对象的具体值进行hash计算,没有对对象的堆内存中进行hash。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号