

XGBoost
摘要
集成学习是机器学习算法中地位非常重要的一类算法, 其拥有理论基础扎实、易扩展、可解释性强等特点, 其核心思想是, 使用弱学习器(如线性模型、决策树等)进行加权求和, 从而产生性能较为强大的强学习器. 若按照指导弱学习器进行学习的理论基础进行分类的话, 集成学习的算法可分为两大类: 1. 基于偏差方差分解和bagging(bootstrap aggregating, 有放回抽样与集成)进行弱学习器学习的算法, 其典型代表是RF(Random Forest, 随机森林); 2. 基于梯度下降和boosting (提升)使弱学习器对前序产生的模型的不足之处进行改进, 以达到提升强学习器能力的效果, 其典型代表是AdaBoost(Adaptive Boosting, 自适应提升), GBDT(Gradient Boosting Decision Tree, 梯度提升决策树). 本文主要的阐述对象是第二类, 即基于梯度下降和boosting的算法, 具体分为如下章节:
- 阐述梯度提升算法的理论基础;
- 阐述GBDT的算法框架;
- 阐述XGBoost的具体实现;
- 阐述GBDT与LR(logistics regression, 逻辑斯底回归)在点击率预估任务中的具体应用;
- 总结.
关键词: 梯度提升, 决策树, 集成学习, 机器学习, 推荐系统
校对:
, ,知乎专栏: 「张同学讲机器学习」
梯度提升算法的理论基础
集成学习是机器学习算法中地位非常重要的一类算法, 其核心思想是, 使用弱学习器(如线性模型、决策树等)进行加权求和, 从而产生性能较为强大的强学习器. 具体的, 假设我们有数据集 , 集成学习希望使用如下的模型对数据集
进行拟合
其中, 系数 为各个弱学习器的权重,
为弱学习器. 由(1)来进行如下的拟合过程
即可得到强学习器 . 由(2)我们可知, 获得强学习器
的关键在于如何获得弱学习器
, 若按照指导弱学习器进行学习的理论基础进行分类, 我们可将其分为bagging和boosting, 具体地
- bagging. 使用bootstrap aggregating进行有放回抽样, 训练出若干个弱学习器进行集成, 其目的是通过有放回抽样构造出多个数据集并分别进行弱学习器训练再进行集成, 以期降低模型的期望泛化误差偏差方差分解中的方差部分, 从而增强模型的泛化能力
由(3)我们可知, 模型的期望泛化误差可表示成模型 关于同分布的多个数据集
的方差、模型
的偏差和数据集的噪声之和. 其中, 偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法的拟合能力;方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所带来的影响;噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度
. 一个很自然的想法是, 如果能使用多个同样大小的同分布数据集
分别进行模型的训练, 然后使用其平均的预测结果作为模型的最终预测结果, 那么我们就能有效地降低模型的方差, 从而降低模型的期望泛化误差. 基于这个思路衍生出了很多算法, 此处我们以随机森林为例.
由于在生产环境中, 数据的获得往往成本较为昂贵, 所以, 随机森林使用bagging在数据集 上构造多个数据集
, 以期达到相近的效果. 对于每个数据集
, 我们使用一棵C&RT
决策树进行拟合, 算法如下
由(5)我们可得最终的随机森林模型. 随机森林有许多的优点, 包括: 学习过程可高度并行, 学习效率较高; 继承了决策树强悍拟合数据能力的优点, 由规避了决策树容易过拟合的缺点.
2. boosting. 以分阶段的形式顺序迭代地学习每个弱学习器, 而每个弱学习器都是在对前序模型的不足之处进行改进, 从而得到更强的强学习器, 其理论基础是梯度下降. 具体地, 对于数据集 , 若此时我们已得到模型
, 其对数据集
的预测结果为
, 我们希望通过本次迭代学习到一个弱学习器
, 使其对模型
的预测结果进行修正, 从而得到更为精确的模型
, 即
更为接近数据集
中的标签值. 在不改变前序模型
的前提下, 一个很直观的想法是, 如果弱学习器
能对标签值
与预测值
之间的差值有一个很好的预测, 那么我们便可以得到更强的模型
. 在这种思路的指导下, 第
次迭代时, 我们使用数据集
对弱学习器
进行训练, 其中
, 为标签值
与预测值
之间的残差, 从弱学习器
开始, 其过程为
由(7)我们便可获得最终的强学习器 .
那么, 为什么说上述的学习过程是以梯度下降为理论基础的呢? 我们不妨换一个角度来看(6). 当模型 已经确定下来时, 其预测值
便为常数, 此时模型
的损失函数为
(8)可以被看做自变量为 的函数. 而我们希望损失函数能够越小越好, 则自变量
的取值往其负梯度方向进行移动便可以达到此效果
. 由(8)我们可得其梯度为
若此处我们采用MSE(mean squared error, 均方误差)作为其损失函数, 则(9)可进一步表示为
由(10)我们发现, 损失函数 关于自变量
的负梯度其实就是残差
. 所以, 我们使用数据集
对弱学习器
进行拟合, 实际上是在用弱学习器
对负梯度进行拟合, 因此
由(11)可以看出, 弱学习器相加的过程, 其实就是损失函数进行梯度下降的过程, 所以, boosting的理论基础就是梯度下降.
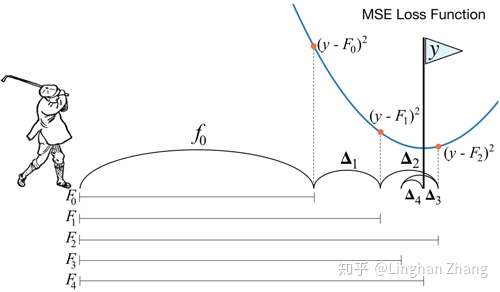
若从一阶泰勒展开的角度来看待(6)(8), 我们试图对自变量 在其邻域中进行一个小的位移
, 从而使损失函数减小
由(12)可知, 损失函数值确实会逐步地进行下降, 当然, 如果能使用二阶导数的信息来帮助 进行取值, 损失函数值将能更快地下降, 这便是XGBoost所采取的思路, 请参考本文后续章节.
综上所述, boosting使用梯度来指导弱学习器 进行学习, 与bagging试图减少模型的方差不同, 是完全不同的理论基础. boosting模型的训练过程只能是依次进行弱学习器的学习, 相较bagging较为低效, 而实际使用中, boosting往往能获得比bagging更好的模型性能.
GBDT的算法框架
上一小节中, 我们阐述了boosting的理论基础, 了解了其训练过程是梯度下降的本质. 那么, 我们应该使用什么样的模型来训练弱学习器 呢? GBDT就是非常典型的一类代表, 其使用决策树作为训练弱学习器
的模型. 具体地, 其算法流程如下
算法(13)提供了一个GBDT的框架, 其可以拥有多种不同变体且细节相异的实现方式.
XGBoost的具体实现
通过前面章节的阐述我们知道, 在每一轮迭代中, 梯度提升算法使用前序模型的预测值 与标签值
之间的残差
对弱学习器
进行训练, 从而得到更强的强学习器
, 其本质是使用损失函数
关于自变量
的一阶导数信息进行梯度下降. 一个很自然的思路是, 如果我们能够使用损失函数
关于自变量
的二阶导数信息来指导弱学习器
的训练, 必将有助于提高训练的收敛速度, 从而得到性能更为强劲的模型. 而这就是XGBoost所采取的思路. 具体地, 我们从二阶泰勒展开来看待(6)(8), 有
对于 , 由牛顿法
我们令
则有
由于(14)是损失函数 的二阶近似, 所以我们令
得到(16), 即可保证损失函数
在其二阶近似上取得极小值. 换句话说, 使用数据集
对弱学习器
进行训练, 即可利用二阶导数的信息得到更好的弱学习器
. 然而, 这还不完全是XGBoost所采取的策略, XGBoost还在二阶泰勒展开的基础上加入了对弱学习器
的惩罚项, 防止过拟合的发生. 具体地, 我们在(14)的基础上, 加上对弱学习器
的惩罚项, 并去掉对模型训练不造成影响的常数项
(17)中加入了 作为对弱学习器
的惩罚项. 当使用
树作为弱学习器
时, 我们可以将
表示为
, 其中,
表示将
维的特征映射到树叶的索引, 为树结构的表示;
表示树叶的个数. 假设我们已经得到了树
, 则对于
, 我们必然可以将其映射到某个叶子
上, 即
, 从而有
. 我们令
为落在叶子
上的样本的集合, 则
中的样本全都会被预测为
, 则(17)可进一步改写为
(18)经由叶子重新进行组织, 使得落在同一个叶子的 能够合并在一起. (18)由
个一元二次函数组成, 在树的结构
已经确定的情况下, 为了使损失函数
在其二阶近似中取得最小值, 我们可得叶子的最优取值为
值得注意的是, (16)与(19)是相同的形式, 一脉相承的牛顿法. 此时, 损失函数 在其二阶近似中取得最小值
(20)给出了在树的结构已经确定为 的情况下, 损失函数
在其二阶近似所能取得的最小值, 接下来, 我们只需要确定一个足够优秀的树结构
, 使得损失函数
的取值足够小就可以了. 为什么是足够优秀的树结构
, 而不是最优秀的树结构
呢? 因为我们是无法枚举所有可能的树结构的, 所以, XGBoost采用一种贪心的策略来构建一棵树. 我们需要一种类似于信息增益或者基尼系数的评判标准, 来对一个树的结构进行评优, 确定某一个节点是否值得我们去分裂以及怎么去分裂. 由(19)(20)我们知道, 树结构
决定了样本
落在每个叶子
上面的情况, 从而决定了
使损失函数取值最小的最优取值
, 进而决定了损失函数
. 一个很自然的思路是, 我们就使用树结构
变化前后的损失函数
的变化值
的大小, 来衡量一个结构变化的优劣. 具体地, 设一个树节点分裂前有样本集合
, 其进行分裂后得到两个叶子, 分别有样本集合
, 则
, 则
(21)给出了树节点分裂前后损失函数 减少的数值
, 通过比较该值, 我们便可以评判出最优的分裂方案了. 有了(21), XGBoost就能从一个单叶子节点开始, 以贪心的策略不断地尝试节点分裂的方案, 进而不断地分裂生长, 最终长成一棵完整的树.
如何进行一个树节点的分裂, 看起来已经成为一个至关重要的步骤了. XGBoost提供了两种分裂的方式, 具体地
- Exact Greedy Algorithm. 对于每一维特征, 该算法针对此特征对样本集进行排序, 然后遍历每个样本在该特征上的取值并进行分裂, 计算出
以确定最佳分裂特征和分裂点.
Exact Greedy Algorithm进行了一次完全的扫描, 从而得到最佳的分裂方案. 其优点是, 能确保找到最佳的分裂方案, 然而缺点也非常明显, 当特征的维数 和样本个数
非常大时, 算法的执行会非常消耗时间和资源. 为此, XGBoost提出了另一种近似的算法以寻找分裂特征和分裂点.
2. Approximate Algorithm. 当训练集的样本量为千万甚至上亿级别时, 对于任一特征 , 这意味着寻找特征
的分裂点需要执行同样数量级的尝试操作. 如果我们能通过减少特征
所需要尝试分裂点的个数, 那自然能减少大量的计算量, 这便是Approximate Algorithm所采取的思路, Approximate Algorithm试图从特征
中较为均匀地采样分裂点. 具体地, 对于特征
, 我们有数据集
, 其中,
为样本
的第
个特征值,
为样本
所对应的二阶导数值. 我们定义如下的排序函数
(23)表示特征值 的样本占全体样本的比重, 其定义与概率密度函数的定义非常地相似. 为什么样本
所占的比重要用其所对应的二阶导数
来表示呢? 我们将(17)进行一下调整, 就可以看出端倪. (17)调整为
正如我们在(16)中由牛顿法得出, 以
为目标进行学习, 而此时二阶导数
正是样本
所产生损失的权重, 其描述了样本
在损失函数
中的重要性, 所以我们才使用二阶导数
在(23)中描述特征值
的样本占全体样本的比重. 有了(23), 我们就可以比较均匀地对特征
的分裂点进行采样了. 我们定义分裂点集为
,
使用 进行调节, 可获得大致
个分裂点, 这使得我们需要尝试的分裂点数大大地减少了. 由(25)我们可得
在(26)中, 我们便只需围绕分裂点集 来进行
的计算了, 完成计算后, 便只需沿着(22)的方法进行操作即可.
GBDT + LR 进行点击率预估
CTR(Click-Through Rate Prediction, 点击率预估)在推荐系统、计算广告中是一个重要的环节, CTR的性能将直接影响用户体验和广告营收. 使用LR进行CTR预估, 在工业级的推荐系统中是很常见的技术方案. LR是一种广义线性模型, 其使用 函数将模型的预测值映射成一个概率值, 并使用
作为CTR预估的分数值来进行判断. LR的优点在于其足够简单, 非常容易进行扩展, 可轻松处理上亿级别的数据; 其缺点则在于其太简单, 没有足够强的学习能力, 需要在特征工程阶段由人工预先分析有效特征、进行特征组合等操作. 熟悉推荐系统的同学都知道, 特征组合对于CTR模型的训练非常重要, LR作为一种线性模型, 在特征组合问题上有着天然缺陷, 其并没有考虑特征之间的相互关系. 如何使有效特征的学习和特征组合的学习自动化, 减少对特征工程的依赖, 是学界的一个重要课题.
Facebook 提出了一种使用GBDT解决LR模型特征发现和特征组合问题的方案. 由前述章节GBDT原理的阐述我们可以发现, 使用GBDT的决策路径作为LR模型的特征输入本身就是一种天然的特征发现与特征组合的过程. 使用GBDT进行特征发现和特征组合的核心思想是: 样本
经过GBDT每棵树的路径都作为LR的一维特征, 以期达到路径上所有特征进行组合的效果. 使用已有的特征训练GBDT模型, 然后利用GBDT模型来构造新的特征向量. 新特征向量由
组成, 其每个特征对应GBDT模型树的一个叶子节点, 当样本落在某个叶子节点上时, 该位特征取值为1, 否则取值为0. 新特征向量的长度等于GBDT模型里所有树包含的叶子结点数之和.
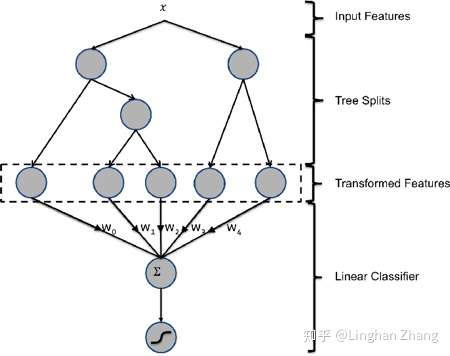
如上图所示, 图中的GBDT模型由两棵树组成, 共5个叶子节点, 故 经由GBDT模型处理后将生成5维的新特征向量. 假设其分别落在第一棵树的2号叶子节点和第二棵树的1号叶子节点, 则生成的新特征向量为
, 而后再使用LR模型进行后续操作. 论文
中树的数量达到500棵, 每棵树的叶子节点数不超过12.
使用GBDT代替人工的特征发现和特征组合在工业级的推荐系统中已经得到广泛的应用, 其表现出了卓越的性能. 另外, 除了与LR进行糅合, 还有一些工作尝试了GBDT+FM等, 总的来说都不逊色于人工的特征.
总结
本文从集成学习的理论基础出发, 阐述了bagging与boosting的数学原理. 并着重阐述了GBDT与XGBoost的算法流程和具体实现, 最后给出了GBDT+LR进行CTR预估的具体示例. 集成学习是非常活跃的机器学习研究领域, 学术界的产出也与工业界的使用联系得相当紧密.
引用
[1] Wikipedia contributors. (2019, March 22). Gradient boosting. InWikipedia, The Free Encyclopedia. Retrieved 13:00, April 10, 2019, fromhttps://en.wikipedia.org/w/index.php?title=Gradient_boosting&oldid=888968392
[2] Zhang, J. (2016). GBDT算法原理深入解析. [online] Zybuluo.com. Available at: https://www.zybuluo.com/yxd/note/611571 [Accessed 19 Mar. 2019].
[3] Chen, T., & Guestrin, C. (2016, March 9). XGBoost: A Scalable Tree Boosting System. http://arXiv.org. http://doi.org/10.1145/2939672.2939785
[4] TccccD. (2018).GBDT与XGBOOST的联系和区别 - TcD的博客 - CSDN博客. [online] Available at: https://blog.csdn.net/u011094454/article/details/78948989 [Accessed 10 Apr. 2019].
[5] Li, C. (2019).A gentle introduction of gradient boosting. [online] Chengli.io. Available at: http://www.chengli.io/tutorials/gradient_boosting.pdf [Accessed 20 Mar. 2019].
[6] Zhou, Z. (2016).机器学习. 1st ed. 北京: 清华大学出版社, pp.45-46.
[7] Zhang, L. (2019).为什么负梯度是函数值减小的最快方向. [online] Zhuanlan.zhihu.com. Available at: https://zhuanlan.zhihu.com/p/57601606 [Accessed 18 Apr. 2019].
[8] Wikipedia contributors. (2019, April 11). Decision tree learning. InWikipedia, The Free Encyclopedia. Retrieved 14:31, April 18, 2019, fromhttps://en.wikipedia.org/w/index.php?title=Decision_tree_learning&oldid=891961623
[9] Wang, X. (2018).从XGB到LGB:美团外卖树模型的迭代之路. [online] Itcodemonkey.com. Available at: https://www.itcodemonkey.com/article/9065.html [Accessed 20 Apr. 2019].
[10] Wikipedia contributors. (2019, April 18). Newton's method. InWikipedia, The Free Encyclopedia. Retrieved 03:42, April 21, 2019, fromhttps://en.wikipedia.org/w/index.php?title=Newton%27s_method&oldid=892955071
[11] He, X. and Pan, J. (2014).Practical Lessons from Predicting Clicks on Ads at Facebook. [online] Facebook Research. Available at: https://research.fb.com/publications/practical-lessons-from-predicting-clicks-on-ads-at-facebook/ [Accessed 22 Apr. 2019].

 浙公网安备 33010602011771号
浙公网安备 33010602011771号