
102302138 林楚涵 作业三
作业三
作业①:要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
① 核心代码与运行截图
*
点击查看代码
import requests
import os
import threading
from urllib.parse import urljoin, urlparse
from bs4 import BeautifulSoup
# 配置项
TARGET_URL = "http://www.weather.com.cn" # 目标网站
SAVE_DIR = "images" # 图片存储目录
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# 创建存储文件夹
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR)
# 解析页面获取所有图片URL
def get_all_img_urls(url):
"""
爬取指定页面的所有图片URL
:param url: 目标页面URL
:return: 图片URL列表
"""
img_urls = []
try:
response = requests.get(url, headers=HEADERS, timeout=10)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
# 提取所有img标签的src属性
img_tags = soup.find_all("img")
for img in img_tags:
img_src = img.get("src")
if img_src:
# 拼接绝对URL
full_url = urljoin(url, img_src)
img_urls.append(full_url)
print(f"解析到图片URL: {full_url}") # 控制台输出URL
except Exception as e:
print(f"解析页面失败: {e}")
return img_urls
# 单线程下载图片
def download_img_single_thread(img_urls):
"""单线程下载图片"""
for idx, img_url in enumerate(img_urls):
try:
# 下载图片
img_response = requests.get(img_url, headers=HEADERS, timeout=10)
# 生成文件名(避免重复)
file_name = f"{idx}_{urlparse(img_url).path.split('/')[-1]}"
if not file_name.endswith((".jpg", ".png", ".jpeg", ".gif")):
file_name += ".jpg" # 补全后缀
save_path = os.path.join(SAVE_DIR, file_name)
# 保存图片
with open(save_path, "wb") as f:
f.write(img_response.content)
print(f"单线程已下载: {img_url} → {save_path}")
except Exception as e:
print(f"单线程下载失败 {img_url}: {e}")
# 多线程下载单张图片(线程任务)
def download_img_thread(img_url, idx):
"""单个线程的图片下载任务"""
try:
img_response = requests.get(img_url, headers=HEADERS, timeout=10)
file_name = f"thread_{idx}_{urlparse(img_url).path.split('/')[-1]}"
if not file_name.endswith((".jpg", ".png", ".jpeg", ".gif")):
file_name += ".jpg"
save_path = os.path.join(SAVE_DIR, file_name)
with open(save_path, "wb") as f:
f.write(img_response.content)
print(f"多线程已下载: {img_url} → {save_path}")
except Exception as e:
print(f"多线程下载失败 {img_url}: {e}")
# 多线程下载图片
def download_img_multi_thread(img_urls):
"""多线程下载图片"""
threads = []
for idx, img_url in enumerate(img_urls):
# 创建线程
t = threading.Thread(target=download_img_thread, args=(img_url, idx))
threads.append(t)
t.start() # 启动线程
# 等待所有线程结束
for t in threads:
t.join()
# 主函数
if __name__ == "__main__":
print("===== 开始解析图片URL =====")
img_urls = get_all_img_urls(TARGET_URL)
if not img_urls:
print("未解析到任何图片URL")
else:
print(f"\n===== 单线程下载开始(共{len(img_urls)}张) =====")
download_img_single_thread(img_urls)
print(f"\n===== 多线程下载开始(共{len(img_urls)}张) =====")
download_img_multi_thread(img_urls)
print("\n===== 下载完成 =====")

② 作业心得
本次实验对比了单线程和多线程爬取图片的差异:单线程逻辑简单、易于调试,但下载大量图片时效率极低;多线程通过并发执行任务,大幅缩短了下载时间,但需要注意线程安全(本次场景无文件写入冲突,未加锁)。同时,爬取过程中需处理 URL 拼接、请求超时、文件后缀异常等问题,让我理解了网络爬虫中 “健壮性” 的重要性。另外,遵守网站 robots 协议、控制请求频率,是爬虫开发的基本准则。
作业②:Scrapy 爬取股票信息并存储 MySQL
① 核心代码与运行截图
*
点击查看代码
import scrapy
import json
from scrapy.selector import Selector
from eastmoney_stock.items import EastmoneyStockItem
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['eastmoney.com']
start_urls = [
'https://83.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=50&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426280e&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'
]
def parse(self, response):
json_raw = response.text
html_wrapper = f"<body>{json_raw}</body>"
html_selector = Selector(text=html_wrapper, type='html')
json_str_by_xpath = html_selector.xpath('//body/text()').extract_first()
if json_str_by_xpath:
self.logger.info(f"XPath提取JSON前100字符 → {json_str_by_xpath[:100]}...")
has_diff = html_selector.xpath('contains(//body/text(), "diff")').extract_first()
self.logger.info(f"包含'diff'字段 → {has_diff}")
else:
self.logger.warning("XPath提取失败")
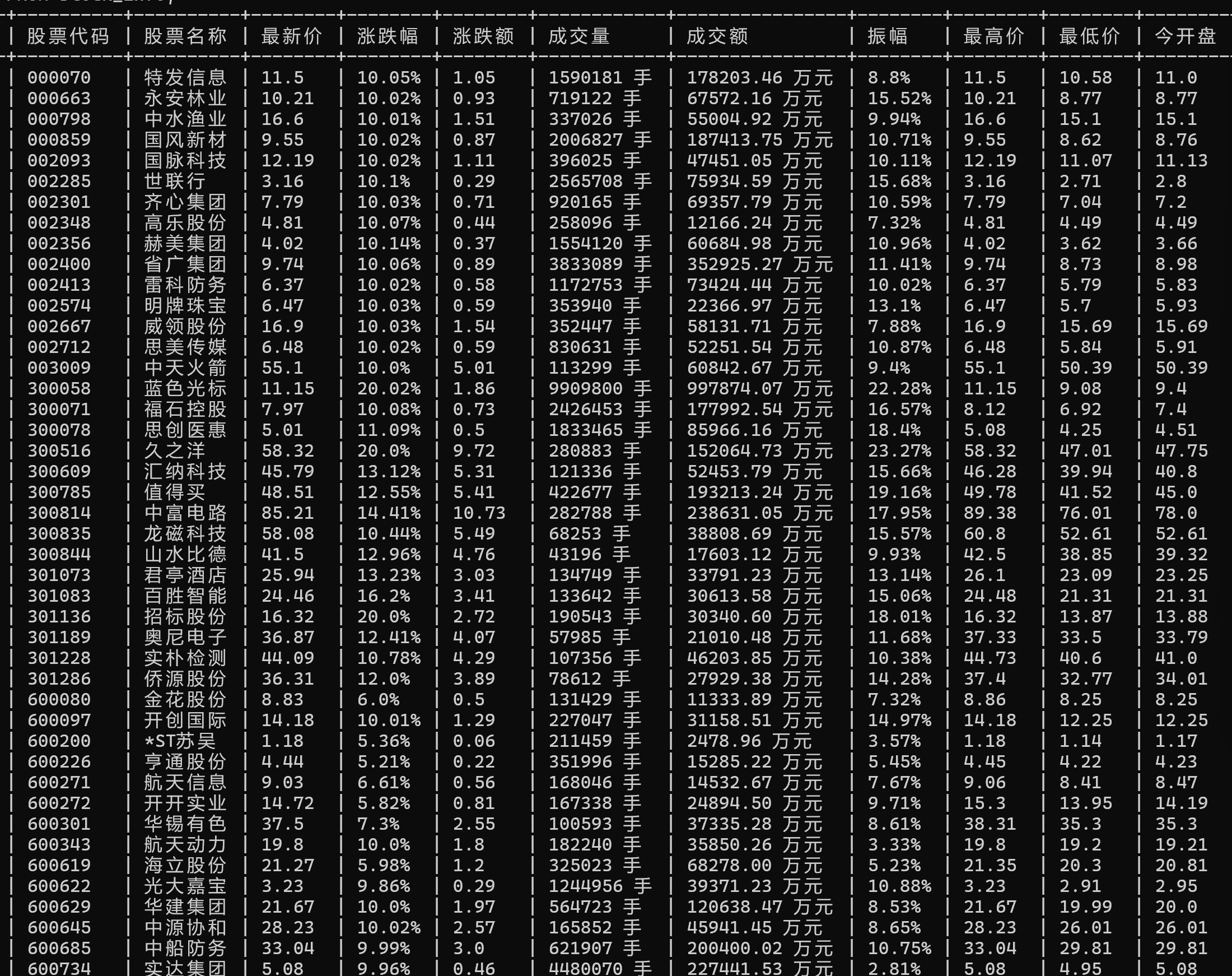
stock_data = json.loads(json_raw)
stock_list = stock_data.get('data', {}).get('diff', [])
self.logger.info(f"解析API → 共{len(stock_list)}条数据")
for idx, stock in enumerate(stock_list, 1):
item = EastmoneyStockItem()
item['serial_id'] = str(idx)
item['stock_code'] = stock.get('f12', '')
item['stock_name'] = stock.get('f14', '')
item['latest_price'] = str(stock.get('f2', ''))
item['price_change_rate'] = f"{stock.get('f3', '')}%"
item['price_change_amount'] = str(stock.get('f4', ''))
item['volume'] = f"{stock.get('f5', '')} 手" if stock.get('f5') else ''
item['turnover'] = f"{stock.get('f6', '')/10000:.2f} 万元" if stock.get('f6') else ''
item['amplitude'] = f"{stock.get('f7', '')}%" if stock.get('f7') else ''
item['highest_price'] = str(stock.get('f15', ''))
item['lowest_price'] = str(stock.get('f16', ''))
item['opening_price'] = str(stock.get('f17', ''))
item['previous_close'] = str(stock.get('f18', ''))
self.logger.info(f"解析 → {item['stock_code']} {item['stock_name']}")
yield item
self.logger.info("数据解析完成,已提交存储")
② 作业心得
通过作业二的Scrapy爬虫开发,我切实掌握了网页表格XPath解析的核心逻辑,从定位表格行、精准提取列数据到过滤无效信息,每一步都让我对数据爬取的流程有了更具体的认知。将解析后的股票数据通过Item与Pipeline序列化存入MySQL,不仅实现了“爬取-存储”的完整闭环,更让我体会到技术选型的重要性——相比API接口,网页表格解析虽需应对结构变化,但XPath的灵活运用让数据提取更直观。过程中遇到的空值处理、异常捕获问题,也教会我用更严谨的逻辑保障程序稳定,真正感受到理论知识转化为实用工具的成就感。
作业③:Scrapy 爬取外汇数据并存储 MySQL
① 核心代码与运行截图
*
点击查看代码
# -*- coding: utf-8 -*-
import scrapy
from forex_project.items import ForexProjectItem
class ForexSpider(scrapy.Spider):
name = 'forex_spider'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 定位数据行(排除表头)
data_rows = response.xpath('//div[@class="BOC_main"]//tr[td]')
self.logger.info(f"匹配数据行数:{len(data_rows)}")
for row in data_rows:
item = ForexProjectItem()
# 提取字段(空值处理)
item['currency'] = row.xpath('./td[1]/text()').extract_first() or '' # 货币名称
item['tbp'] = row.xpath('./td[2]/text()').extract_first() or '' # 现汇买入价
item['cbp'] = row.xpath('./td[3]/text()').extract_first() or '' # 现钞买入价
item['tsp'] = row.xpath('./td[4]/text()').extract_first() or '' # 现汇卖出价
item['csp'] = row.xpath('./td[5]/text()').extract_first() or '' # 现钞卖出价
item['time'] = row.xpath('./td[8]/text()').extract_first() or '' # 发布时间
# 清理字段空格
for key in item.keys():
item[key] = item[key].strip() if item[key] else ''
# 过滤无效行并提交
if item['currency']:
self.logger.debug(f"提取数据:{item['currency']} | {item['time']} | TBP:{item['tbp']}")
yield item
else:
self.logger.debug("跳过空行")
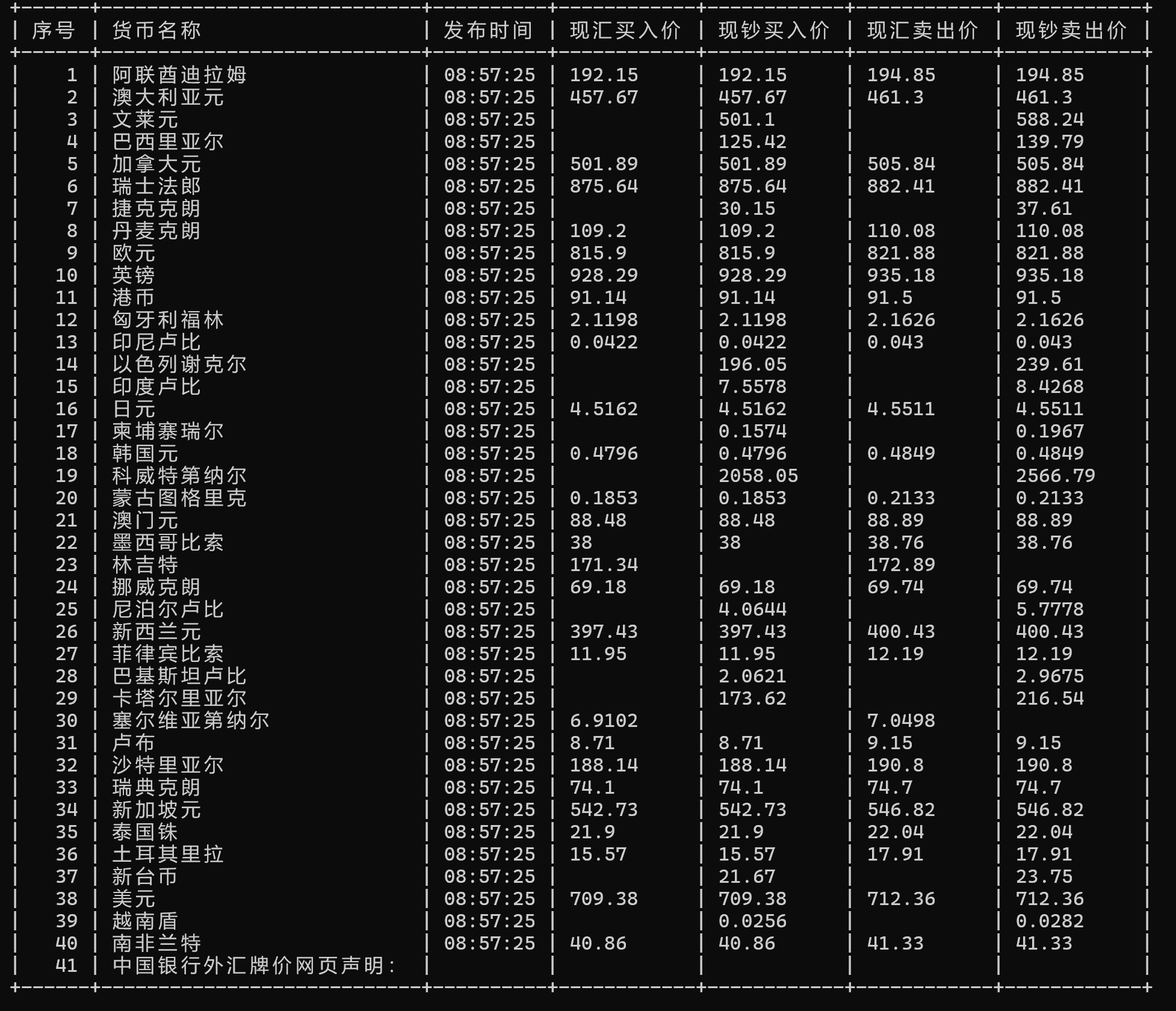
② 作业心得
本次作业最宝贵的收获,是学会了 “拆解问题” 的调试思路。面对 “无数据提取” 的问题,我不再盲目修改代码,而是先通过日志确认页面请求成功(response_status_count/200:1),再用scrapy shell验证 XPath 匹配结果(len(response.xpath('//div[@class="BOC_main"]//tr[td]'))返回 42 条数据),最后验证字段提取逻辑,逐步缩小问题范围。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号