
102302138 林楚涵 作业2
🌦️ 第二次爬虫作业实录|天气 + 股票 + 大学榜
作业①:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
① 核心代码与运行截图
点击查看代码
import sqlite3, urllib.request, bs4, re
db = sqlite3.connect('w.db')
db.execute('create table if not exists t(c,d,w,m)')
db.execute('delete from t')
head = {'User-Agent':'Mozilla/5.0'}
code = {'北京':'101010100','上海':'101020100','广州':'101280101','深圳':'101280601'}
for city in code:
url = f'http://www.weather.com.cn/weather/{code[city]}.shtml'
html = bs4.BeautifulSoup(urllib.request.urlopen(urllib.request.Request(url, headers=head)).read(), 'lxml')
for li in html.select('ul.t.clearfix li')[:7]:
d = li.h1.text.strip()
w = li.find('p','wea').text
tem = li.find('p','tem')
hi = tem.span.text if tem.span else '—'
lo = tem.i.text if tem.i else '—'
db.execute('insert into t values(?,?,?,?)', (city,d,w,f'{hi}/{lo}'))
db.commit()
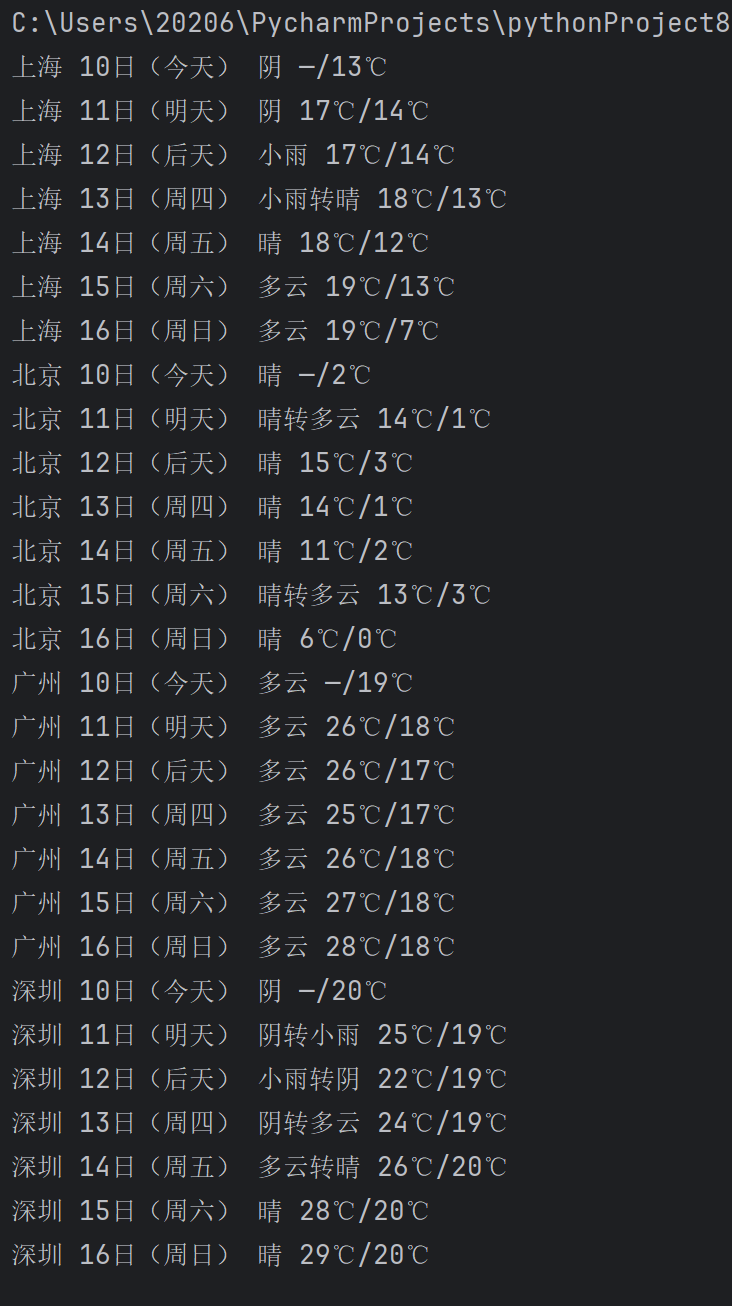
for r in db.execute('select * from t order by c,d'):
print(*r)
db.close()
*
② 作业心得
这段代码的核心思路是“构造请求→解析页面→提取数据→入库→展示”。首先建立 SQLite 数据库并清空历史数据;随后用伪装的 User-Agent 头,按“城市-编码”字典循环拼接中国天气网 7 日预报 URL,通过 urllib 拉取 HTML 后交给 BeautifulSoup 解析;针对返回的 7 个
③ Gitee文件夹链接
作业②:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
① 核心代码与运行截图
**
点击查看代码
import requests, json, time, csv, os
def get_stock_data(page):
url = "http://69.push2.eastmoney.com/api/qt/clist/get"
params = {
"pn": page, "pz": 20, "po": 1, "np": 1,
"ut": "bd1d9ddb00efe4882cddb8fe999b62f7c",
"fltt": 2, "invt": 2, "fid": "f3",
"fs": "m:0+f:8,m:1+f:8",
"fields": "f12,f14,f2,f3,f4,f5,f6,f7",
"_": int(time.time() * 1000)
}
headers = {
"User-Agent": "Mozilla/5.0",
"Referer": "http://quote.eastmoney.com/"
}
resp = requests.get(url, params=params, headers=headers)
data = json.loads(resp.text)
return data["data"]["diff"] if data.get("data") else []
def print_and_save_stocks(stocks, start_idx, csv_path, is_first):
if is_first:
print("序号 代码 名称 最新价 涨跌幅 涨跌额 成交量(万手) 成交额(亿) 振幅")
for i, stock in enumerate(stocks, start_idx):
code = stock.get("f12", "")
name = stock.get("f14", "")
price = round(stock.get("f2", 0.0), 2)
chg_pct = round(stock.get("f3", 0.0), 2)
chg_amt = round(stock.get("f4", 0.0), 2)
vol = round(stock.get("f5", 0) / 10000, 2)
amt = round(stock.get("f6", 0.0) / 1e8, 2)
amp = round(stock.get("f7", 0.0), 2)
print(f"{i:2d} {code:6s} {name:<8s} {price:6.2f} {chg_pct:6.2f}% {chg_amt:7.2f} {vol:12.2f} {amt:10.2f} {amp:6.2f}%")
os.makedirs(os.path.dirname(csv_path), exist_ok=True)
headers = ["序号", "代码", "名称", "最新价", "涨跌幅(%)", "涨跌额", "成交量(万手)", "成交额(亿)", "振幅(%)"]
with open(csv_path, "a", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=headers)
if is_first:
writer.writeheader()
for i, s in enumerate(stocks, start_idx):
writer.writerow({
"序号": i, "代码": s.get("f12"), "名称": s.get("f14"),
"最新价": round(s.get("f2", 0), 2),
"涨跌幅(%)": round(s.get("f3", 0), 2),
"涨跌额": round(s.get("f4", 0), 2),
"成交量(万手)": round(s.get("f5", 0) / 10000, 2),
"成交额(亿)": round(s.get("f6", 0) / 1e8, 2),
"振幅(%)": round(s.get("f7", 0), 2)
})
def main():
csv_path = "股票/创新股数据/创新股股票数据.csv"
for page in range(1, 3):
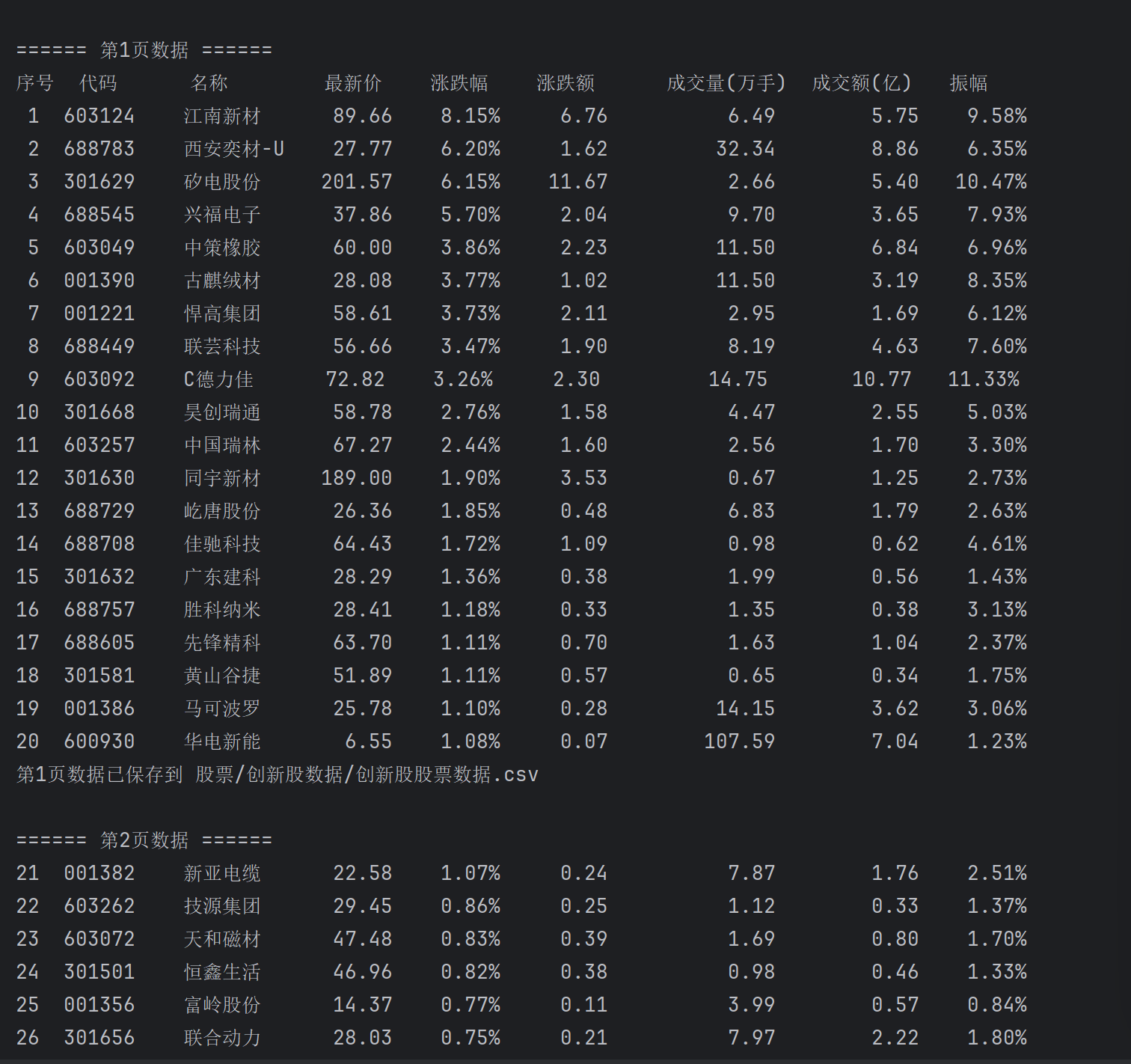
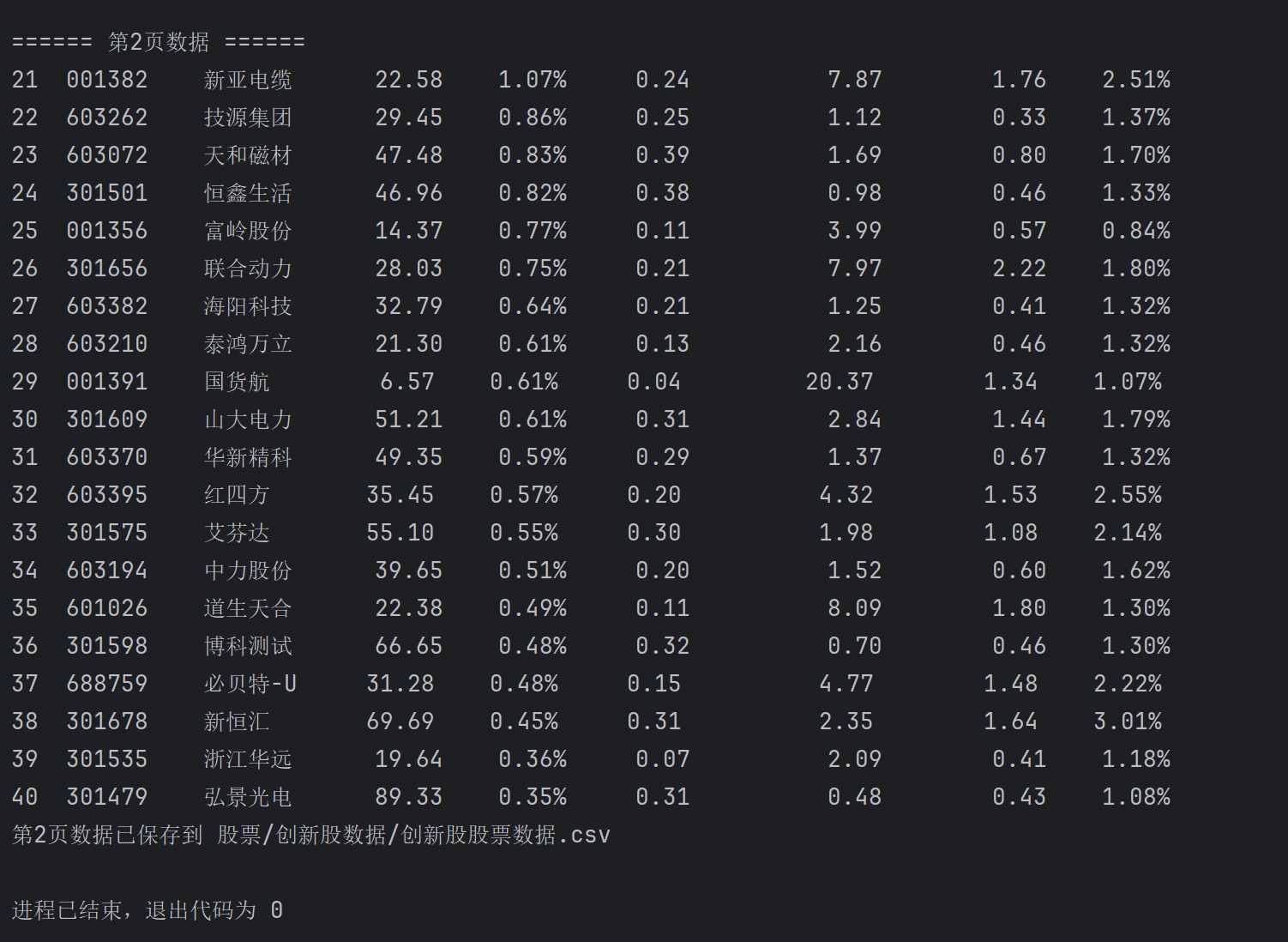
print(f"\n====== 第{page}页数据 ======")
stocks = get_stock_data(page)
if stocks:
print_and_save_stocks(stocks, (page - 1) * 20 + 1, csv_path, page == 1)
print(f"第{page}页数据已保存到 {csv_path}")
else:
print("未获取到数据")
time.sleep(1)
if __name__ == "__main__":
main()
② 作业心得
整段代码以东方财富网公开 JSONP 接口为切入口,先拼接带分页、字段过滤和时间戳的动态 URL,再用 Session 伪装浏览器请求并解析返回 JSON,批量提取股票代码、名称、最新价等八项关键指标,实时控制台对齐打印的同时追加写入 CSV,通过分页循环与延迟机制完成 40 条创新股数据的完整落盘,全程用函数分工实现“请求-解析-输出-存储”流水线,既避免重复建表又保证中断续写,将抓包、参数构造、异常兜底和落盘细节封装成可复用的轻量级框架。
③ Gitee文件夹链接
https://gitee.com/forest-stream-whisper/2025_crawl_project/blob/master/%E4%BD%9C%E4%B8%9A2/%E4%BD%9C%E4%B8%9A2/2.csv
作业③:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
① 核心代码与运行截图
*
点击查看代码
import re
import requests
import sqlite3
from datetime import datetime
# 基础配置
db_name = "2021_univ_rank.db"
target_url = "https://www.shanghairanking.cn/_nuxt/static/1762223212/rankings/bcur/2021/payload.js"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# 省市、学校类型编码映射
province_code = {
'k': '江苏', 'n': '山东', 'o': '河南', 'p': '河北', 'q': '北京', 'r': '辽宁',
's': '陕西', 't': '四川', 'u': '广东', 'v': '湖北', 'w': '湖南', 'x': '浙江',
'y': '安徽', 'z': '江西', 'A': '黑龙江', 'B': '吉林', 'D': '上海', 'F': '福建',
'E': '山西', 'H': '云南', 'G': '广西', 'I': '贵州', 'J': '甘肃', 'K': '内蒙古',
'L': '重庆', 'N': '天津', 'O': '新疆', 'az': '宁夏', 'aA': '青海', 'aB': '西藏'
}
category_code = {
'f': '综合', 'e': '理工', 'h': '师范', 'm': '农业', 'S': '林业'
}
# 正则表达式:提取学校名称、类型、省市、分数
rank_pattern = re.compile(
r'univNameCn:"(?P<name>[^"]+)",.*?'
r'univCategory:(?P<cat>[^,]+),.*?'
r'province:(?P<prov>[^,]+),.*?'
r'score:(?P<score>[^,]+),',
re.S
)
def clean_str(s):
return s.strip().strip('"')
def init_database():
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# 创建表结构
cursor.execute('''
CREATE TABLE IF NOT EXISTS univ_rank_2021 (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ranking INTEGER NOT NULL,
school TEXT NOT NULL,
province TEXT NOT NULL,
category TEXT NOT NULL,
total_score FLOAT NOT NULL,
crawl_time TEXT NOT NULL
)
''')
conn.commit()
conn.close()
print("数据库初始化完成")
def save_data(school_list):
crawl_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# 批量插入数据(按排名顺序)
for i, (school, prov, cat, score) in enumerate(school_list, 1):
cursor.execute('''
INSERT INTO univ_rank_2021
(ranking, school, province, category, total_score, crawl_time)
VALUES (?, ?, ?, ?, ?, ?)
''', (i, school, prov, cat, score, crawl_time))
conn.commit()
conn.close()
def get_univ_ranking():
resp = requests.get(target_url, headers=headers)
resp.encoding = resp.apparent_encoding # 自动适配编码
content = resp.text
rank_list = []
# 正则匹配提取每条学校数据
for match in rank_pattern.finditer(content):
# 提取原始字段并清理
school_name = clean_str(match.group('name'))
cat_raw = clean_str(match.group('cat'))
prov_raw = clean_str(match.group('prov'))
score_raw = clean_str(match.group('score'))
# 映射编码到实际省市和类型
province = province_code.get(prov_raw, '其他')
category = category_code.get(cat_raw, '其他')
# 分数转换为浮点数(跳过无效分数)
try:
score = float(score_raw)
except:
continue
# 过滤空学校名称,添加到列表
if school_name:
rank_list.append((school_name, province, category, score))
# 按总分降序排序
rank_list.sort(key=lambda x: x[3], reverse=True)
return rank_list
def main():
init_database()
univ_data = get_univ_ranking()
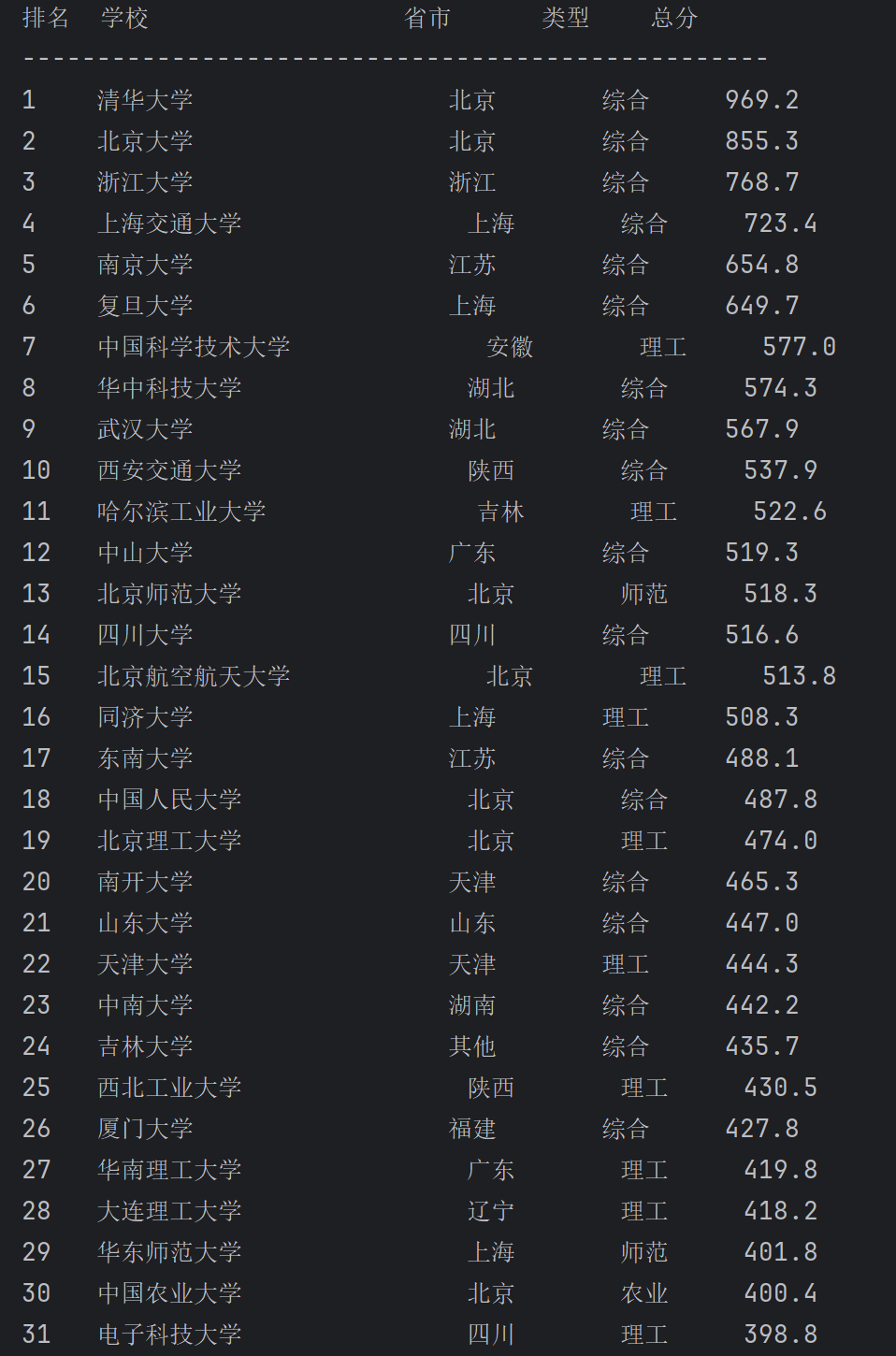
# 打印爬取结果(格式化输出)
print("\n排名 学校 省市 类型 总分")
print("-" * 50)
for i, (school, prov, cat, score) in enumerate(univ_data, 1):
print(f"{i:<4} {school:<20} {prov:<8} {cat:<6} {score:.1f}")
# 保存数据到数据库
save_data(univ_data)
print(f"\n爬取完成!共{len(univ_data)}所大学数据已保存到{db_name}")
if __name__ == "__main__":
main()
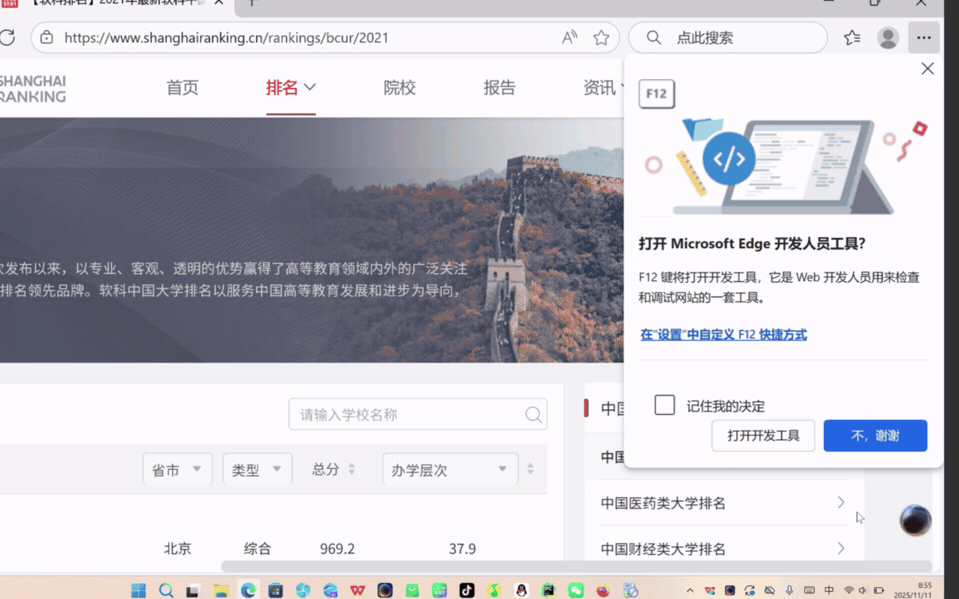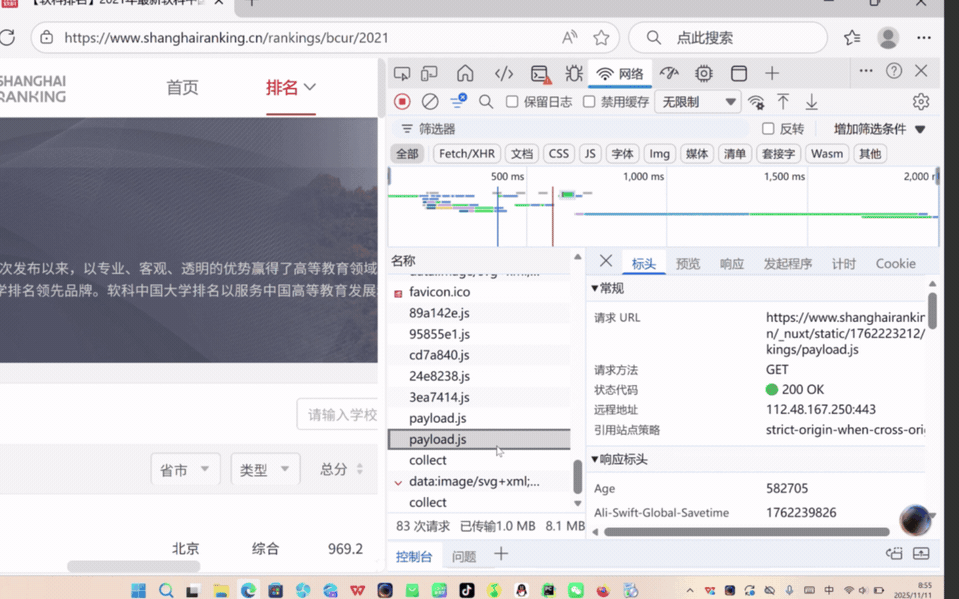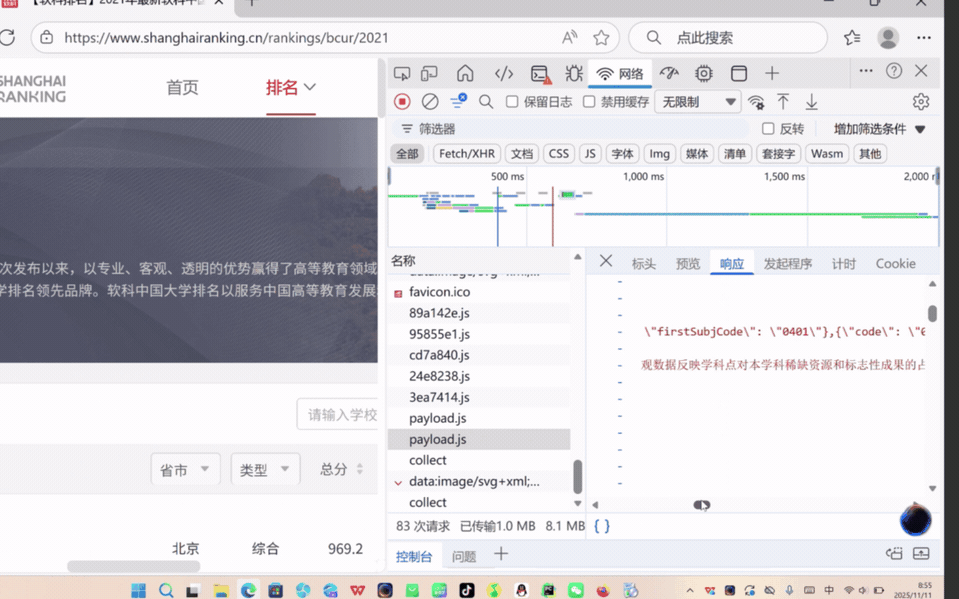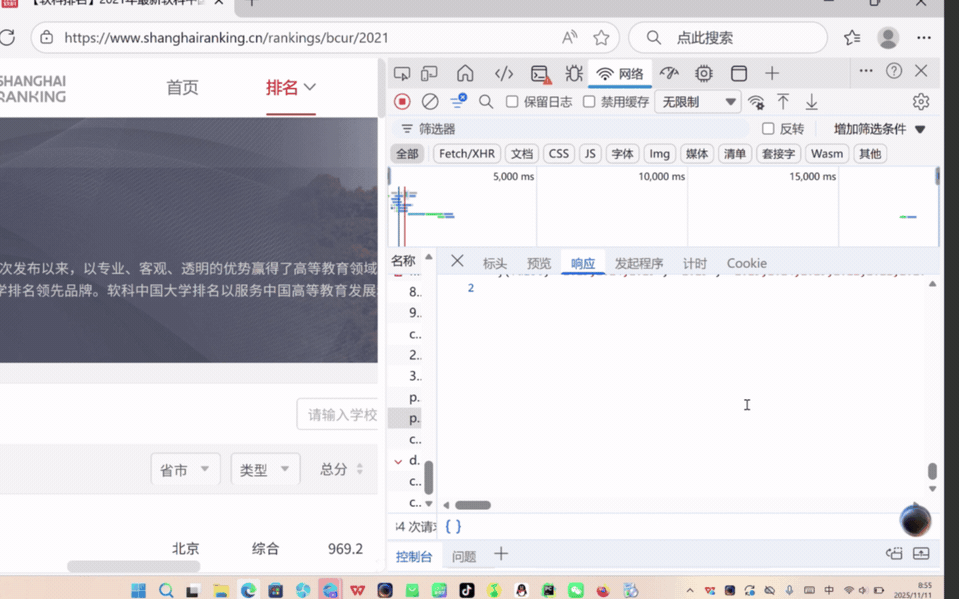
② 作业心得
这段代码首先通过 requests 库向目标 API 发起请求,获取包含排名信息的 JavaScript 数据文件;接着利用正则表达式从响应内容中提取学校名称、省市编码、类型编码及总分等关键信息,再通过预设的编码映射表将省市和类型编码转换为中文名称,并对分数进行格式转换和过滤;之后按总分降序对提取的学校数据排序,得到排名结果;最后初始化 SQLite 数据库,创建用于存储排名数据的表,将处理后的学校信息(含排名、名称、省市、类型、总分及爬取时间)批量插入数据库,并打印展示爬取结果。整体流程实现了从网络数据获取到本地结构化存储的闭环

 浙公网安备 33010602011771号
浙公网安备 33010602011771号