
102302138 林楚涵 作业1
网络爬虫三次作业全记录
作业①:requests + BeautifulSoup 爬取大学排名
① 核心代码与运行截图
*
点击查看代码
import requests
from bs4 import BeautifulSoup
def get_university_ranking():
# 目标网址
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
}
# 获取页面
resp = requests.get(url, headers=headers)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text, 'html.parser')
# 定位表格
table = soup.find('table', class_='rk-table')
rows = table.find_all('tr')[1:] # 去掉表头
# 打印表头
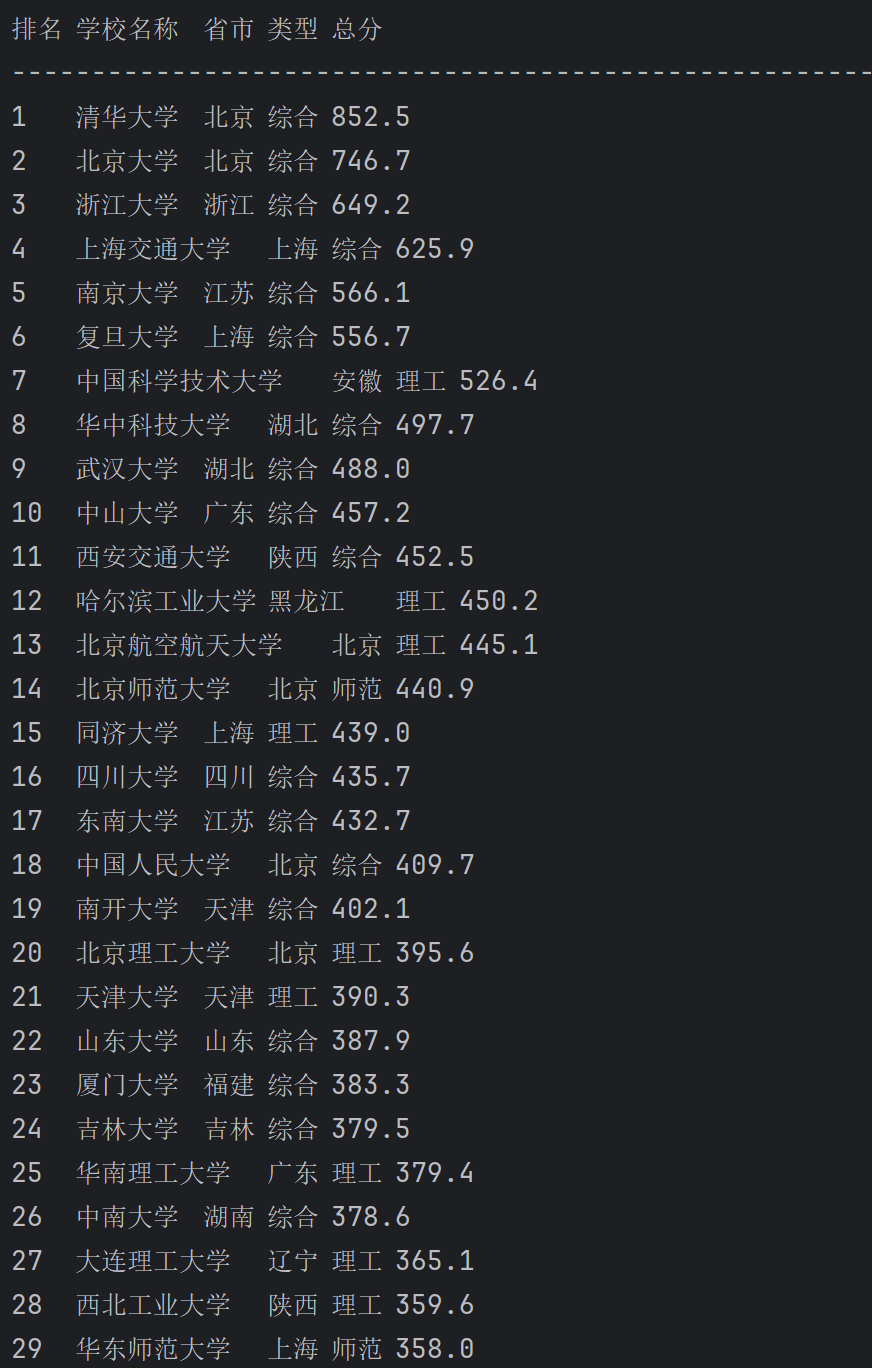
print('排名\t学校名称\t省市\t类型\t总分')
print('-' * 60)
# 遍历每行
for tr in rows:
td = tr.find_all('td')
if len(td) < 5:
continue
rank = td[0].text.strip()
# 只取中文校名,去掉英文
name = td[1].text.split('\n')[0].strip()
province = td[2].text.strip()
category = td[3].text.strip()
score = td[4].text.strip()
print(f'{rank}\t{name}\t{province}\t{category}\t{score}')
if __name__ == '__main__':
get_university_ranking()

② 作业心得
我先用 BeautifulSoup 把整段返回文本解析成树,随后用 find('table', class_='rk-table') 一次定位到“主干”,再用 find_all('tr')[1:] 剪掉表头这根侧枝,最后对每一行 tr 调用 find_all('td') ,就相当于顺着枝条摘到 5 片叶子(排名、校名、省市、类型、总分)。整个过程没有陷入繁杂的正则分组,也无需计算字符偏移,完全按照“树根—树枝—树叶”的层级关系一步步精确定位,既直观又不易出错。可见,BS 库“树操作”思维不仅帮助我在代码层面快速提取数据,更让网页结构从混乱的字符串变成了可视化的层次图,大幅降低了理解和维护成本,这正是作业①能够顺利跑通且后续易于扩展的根本原因。
作业②:正则解析当当网书包商品
① 核心代码与运行截图
*
点击查看代码
import re
import requests
from typing import List, Dict, Optional
class DangDangCrawler:
"""当当网商品信息采集器"""
BASE_URL = 'https://search.dangdang.com/'
DEFAULT_ENCODING = 'gbk'
def __init__(self):
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
def _extract_product_data(self, html_content: str) -> List[Dict[str, str]]:
"""从HTML中提取商品数据"""
product_pattern = re.compile(
r'<li.*?ddt-pit="(?P<id>\d+)".*?'
r'<a title="(?P<name>[^"]+)".*?'
r'<span class="price_n">\s*¥\s*(?P<price>[\d.]+)\s*</span>',
re.DOTALL
)
return [
{
'id': match.group('id'),
'name': match.group('name'),
'price': match.group('price')
}
for match in product_pattern.finditer(html_content)
]
def _format_output(self, products: List[Dict[str, str]]) -> None:
"""格式化输出商品信息"""
header = f"{'编号':<5} {'价格':<10} {'商品名称'}"
separator = '-' * 70
print(header)
print(separator)
for product in products:
print(f"{product['id']:>5} ¥{product['price']:>8} {product['name'][:40]:40}")
def fetch_products(self, keyword: str = '书包') -> None:
"""获取并显示商品信息"""
try:
response = self.session.get(
self.BASE_URL,
params={'key': keyword, 'act': 'input'},
timeout=10
)
response.encoding = self.DEFAULT_ENCODING
products = self._extract_product_data(response.text)
self._format_output(products)
except requests.RequestException as e:
print(f"网络请求失败: {str(e)}")
except Exception as e:
print(f"处理过程中发生错误: {str(e)}")
if __name__ == "__main__":
crawler = DangDangCrawler()
crawler.fetch_products()


② 作业心得
整个流程被拆成初始化→请求→解析→输出四个独立方法,每个函数只干一件事,既方便调试,也便于以后更换解析器或增加多线程。尤其 _extract_product_data 把正则表达式写成命名分组,一条 finditer 就把 id、名称、价格一次性拎出来,比传统索引分组直观得多,也避免了硬写下标带来的“数括号”痛苦。通过定义私有方法 _format_output ,还把数据抓取与展示解耦,后续若想改成写 CSV 或入库,只需替换这一层即可,充分体现了“开闭原则”。编码方面,当当页面使用 GBK,若不手动指定 response.encoding = 'gbk' ,中文就会乱码,更让我意识到“爬取前先观察字符集”是条铁律。
作业③:批量下载「影像福大」图片
① 核心代码与运行截图
*
点击查看代码
import urllib.request
import re
import os
import time
from urllib.parse import urljoin, urlparse
class FZUNewsImageSpider:
def __init__(self):
self.base_url = "https://news.fzu.edu.cn/yxfd.htm"
self.domain = "https://news.fzu.edu.cn/"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
self.all_images = []
self.all_news = []
def get_html_content(self, url):
"""获取网页内容"""
try:
req = urllib.request.Request(url=url, headers=self.headers)
response = urllib.request.urlopen(req)
html_content = response.read().decode('utf-8')
return html_content
except Exception as e:
print(f"获取网页内容失败 {url}: {e}")
return None
def parse_pagination(self, html_content):
"""解析分页链接"""
# 匹配分页链接,包括上一页、下一页和页码
pagination_pattern = r'<a href="([^"]*)"[^>]*>(\d+)</a>'
pagination_matches = re.findall(pagination_pattern, html_content)
page_urls = []
for url, page_num in pagination_matches:
if url and not url.startswith('javascript:'):
full_url = urljoin(self.domain, url)
page_urls.append((full_url, page_num))
# 去重并排序
unique_pages = list(dict.fromkeys(page_urls))
return unique_pages
def parse_image_links(self, html_content, page_url):
"""解析图片链接"""
# 改进的图片匹配模式,匹配各种图片格式
img_pattern = r'<img[^>]*src=["\']([^"\']*\.(?:jpg|jpeg|png|gif|webp|bmp))["\'][^>]*alt=["\']([^"\']*)["\'][^>]*>'
images = []
img_matches = re.findall(img_pattern, html_content, re.IGNORECASE)
for img_src, alt_text in img_matches:
# 构建完整的图片URL
full_img_url = urljoin(page_url, img_src)
title = alt_text.strip() if alt_text.strip() else "未命名图片"
images.append({
'url': full_img_url,
'title': title,
'page_url': page_url
})
return images
def parse_news_links(self, html_content, page_url):
"""解析新闻链接"""
# 改进的新闻链接匹配模式
news_pattern = r'<a[^>]*href=["\'](info/[^"\']*/\d+\.htm)["\'][^>]*title=["\']([^"\']*)["\'][^>]*>'
news_links = []
matches = re.findall(news_pattern, html_content)
for link, title in matches:
full_link = urljoin(self.domain, link)
news_links.append({
'title': title.strip(),
'url': full_link,
'page_url': page_url
})
return news_links
def crawl_page(self, url, page_num="1"):
"""爬取单个页面"""
print(f"\n正在爬取第 {page_num} 页: {url}")
html_content = self.get_html_content(url)
if not html_content:
return []
# 解析当前页面的图片和新闻
images = self.parse_image_links(html_content, url)
news_links = self.parse_news_links(html_content, url)
print(f"第 {page_num} 页找到 {len(images)} 张图片, {len(news_links)} 条新闻")
return images, news_links, html_content
def download_image(self, img_url, filename):
"""下载单张图片"""
try:
req = urllib.request.Request(url=img_url, headers=self.headers)
response = urllib.request.urlopen(req)
img_data = response.read()
with open(filename, 'wb') as f:
f.write(img_data)
print(f"下载成功: {filename}")
return True
except Exception as e:
print(f"下载失败 {filename}: {e}")
return False
def crawl_all_pages(self, download_images=True): # 修改为默认下载图片
"""爬取所有页面"""
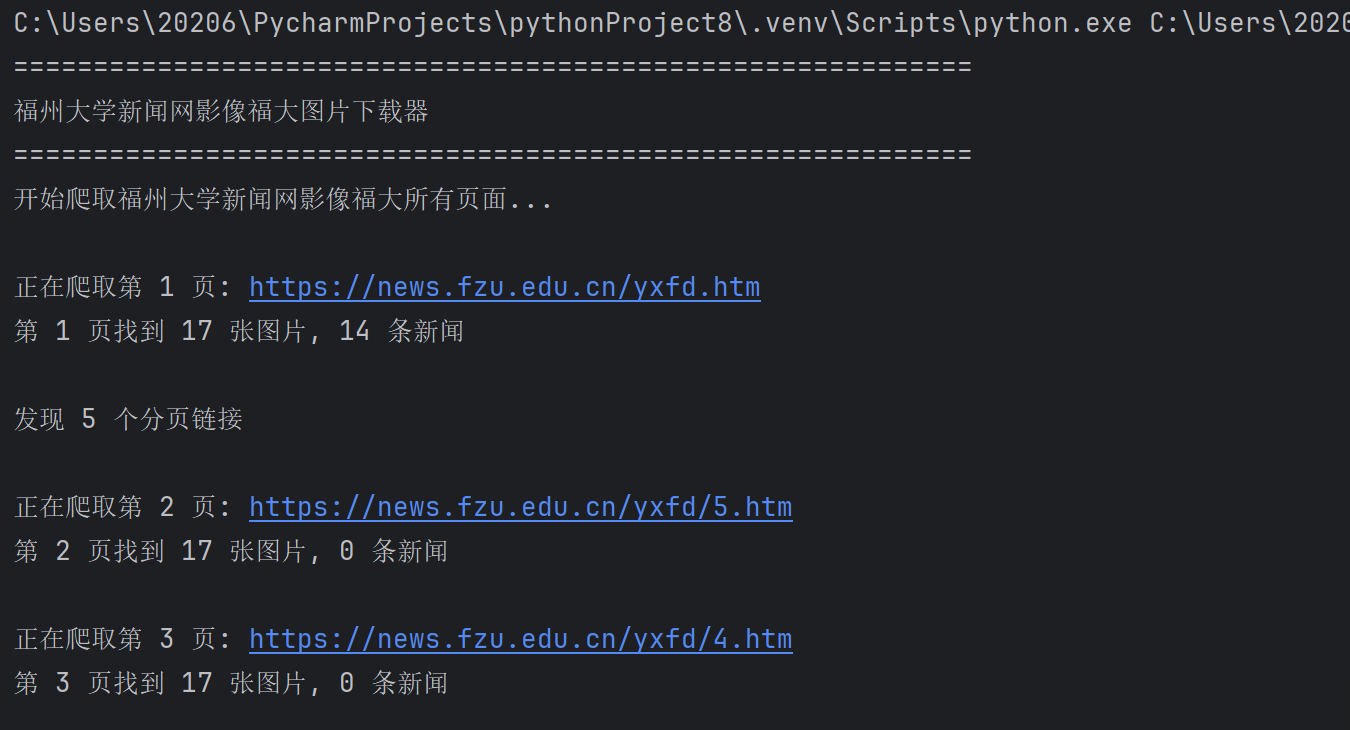
print("开始爬取福州大学新闻网影像福大所有页面...")
# 首先爬取第一页
images, news, html_content = self.crawl_page(self.base_url, "1")
self.all_images.extend(images)
self.all_news.extend(news)
# 解析分页链接
page_links = self.parse_pagination(html_content)
print(f"\n发现 {len(page_links)} 个分页链接")
# 爬取其他页面
for page_url, page_num in page_links:
# 避免重复爬取第一页
if page_num != "1":
time.sleep(1) # 添加延迟,避免请求过快
images, news, _ = self.crawl_page(page_url, page_num)
self.all_images.extend(images)
self.all_news.extend(news)
# 去重
self.all_images = list({img['url']: img for img in self.all_images}.values())
self.all_news = list({news['url']: news for news in self.all_news}.values())
self.display_results()
# 下载图片
if download_images and self.all_images:
self.download_all_images()
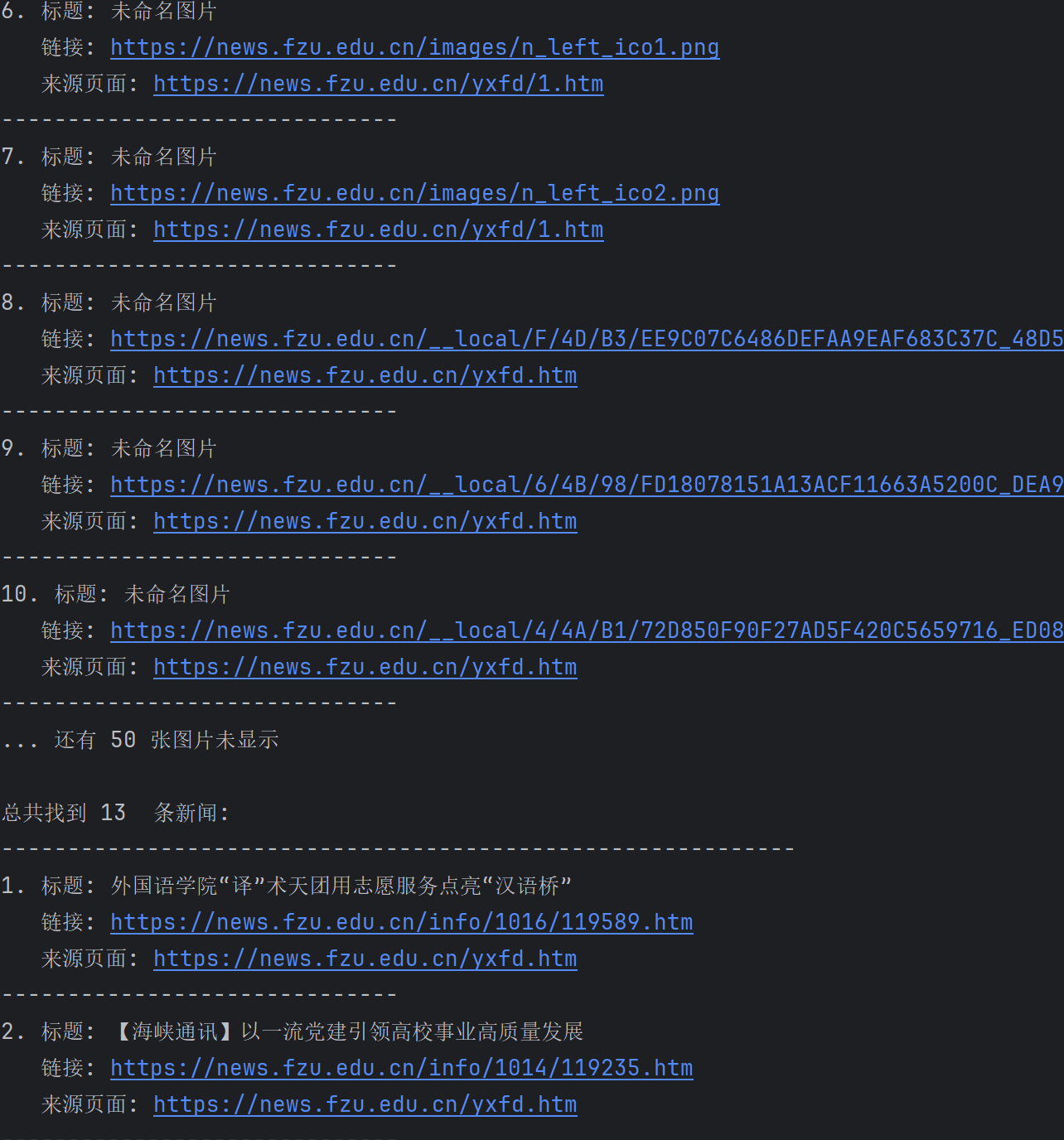
def display_results(self):
"""显示爬取结果"""
print("\n" + "=" * 60)
print("爬取完成!汇总结果:")
print("=" * 60)
print(f"\n总共找到 {len(self.all_images)} 张图片:")
print("-" * 60)
for i, img in enumerate(self.all_images[:10], 1): # 只显示前10个
print(f"{i}. 标题: {img['title']}")
print(f" 链接: {img['url']}")
print(f" 来源页面: {img['page_url']}")
print("-" * 30)
if len(self.all_images) > 10:
print(f"... 还有 {len(self.all_images) - 10} 张图片未显示")
print(f"\n总共找到 {len(self.all_news)} 条新闻:")
print("-" * 60)
for i, news in enumerate(self.all_news[:10], 1): # 只显示前10个
print(f"{i}. 标题: {news['title']}")
print(f" 链接: {news['url']}")
print(f" 来源页面: {news['page_url']}")
print("-" * 30)
if len(self.all_news) > 10:
print(f"... 还有 {len(self.all_news) - 10} 条新闻未显示")
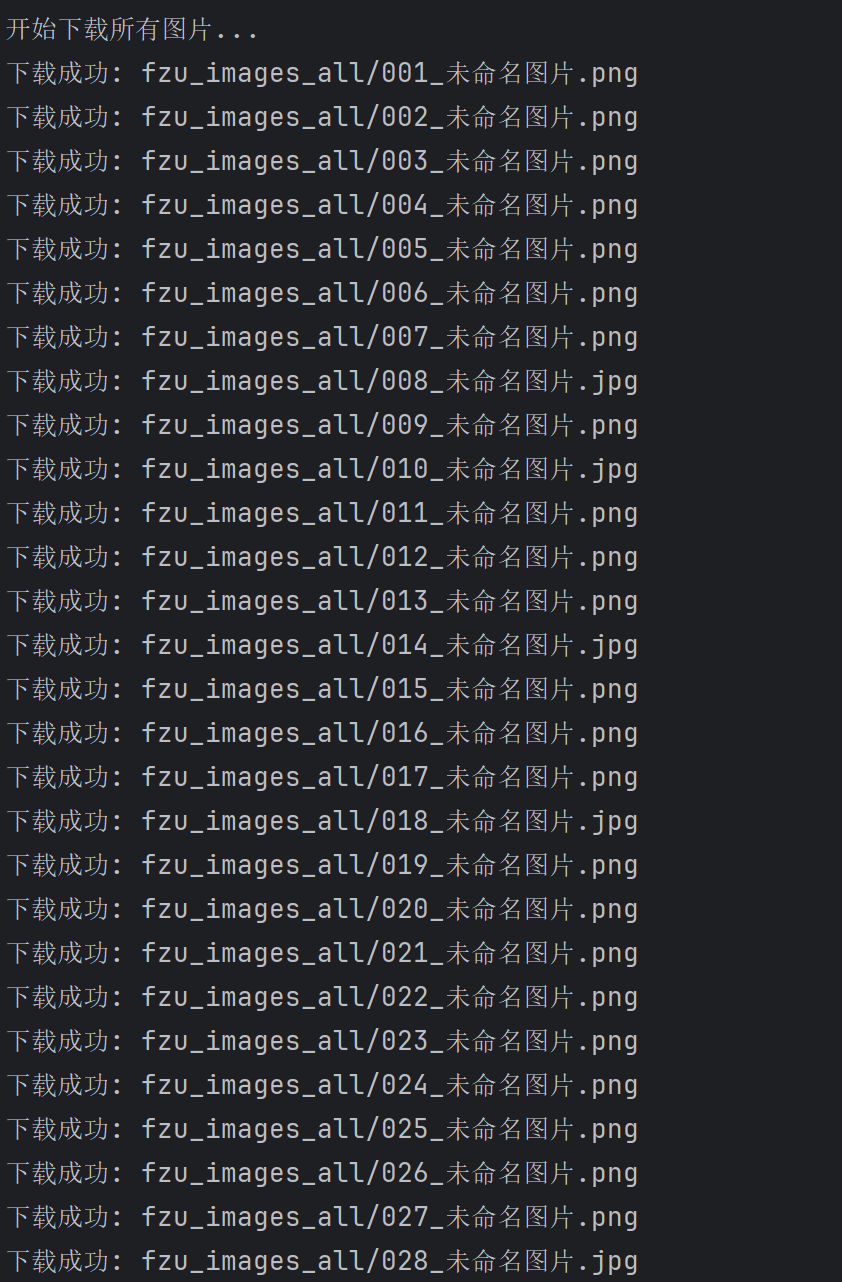
def download_all_images(self):
"""下载所有图片"""
print("\n开始下载所有图片...")
# 创建下载目录
download_dir = 'fzu_images_all'
if not os.path.exists(download_dir):
os.makedirs(download_dir)
success_count = 0
for i, img in enumerate(self.all_images, 1):
# 清理文件名中的非法字符
safe_title = re.sub(r'[\\/*?:"<> |]', '', img['title'])
# 根据URL确定文件扩展名
parsed_url = urlparse(img['url'])
file_ext = os.path.splitext(parsed_url.path)[1]
if not file_ext:
file_ext = '.jpg' # 默认扩展名
filename = f"{download_dir}/{i:03d}_{safe_title}{file_ext}"
# 如果文件名太长,截断
if len(filename) > 200:
filename = f"{download_dir}/{i:03d}_image{file_ext}"
if self.download_image(img['url'], filename):
success_count += 1
time.sleep(0.5) # 添加延迟,避免请求过快
print(f"\n图片下载完成!成功下载 {success_count}/{len(self.all_images)} 张图片")
# 生成下载报告
report_file = f"{download_dir}/download_report.txt"
with open(report_file, 'w', encoding='utf-8') as f:
f.write(" 福州大学新闻网影像福大图片下载报告\n")
f.write("=" * 50 + "\n\n")
f.write(f" 总图片数: {len(self.all_images)}\n")
f.write(f" 成功下载: {success_count}\n")
f.write(f" 失败数量: {len(self.all_images) - success_count}\n\n")
f.write(" 下载详情:\n")
for i, img in enumerate(self.all_images, 1):
status = "成功" if i <= success_count else "失败"
f.write(f"{i:03d}. {img['title']} - {status}\n")
def save_to_file(self):
"""将结果保存到文件"""
with open('fzu_news_crawl_results.txt', 'w', encoding='utf-8') as f:
f.write(" 福州大学新闻网影像福大爬取结果\n")
f.write("=" * 50 + "\n\n")
f.write(" 图片列表:\n")
f.write("-" * 30 + "\n")
for i, img in enumerate(self.all_images, 1):
f.write(f"{i}. {img['title']}\n")
f.write(f" 链接: {img['url']}\n")
f.write(f" 来源: {img['page_url']}\n\n")
f.write("\n 新闻列表:\n")
f.write("-" * 30 + "\n")
for i, news in enumerate(self.all_news, 1):
f.write(f"{i}. {news['title']}\n")
f.write(f" 链接: {news['url']}\n")
f.write(f" 来源: {news['page_url']}\n\n")
print("结果已保存到 fzu_news_crawl_results.txt")
def main():
# 创建爬虫实例
spider = FZUNewsImageSpider()
print("=" * 60)
print("福州大学新闻网影像福大图片下载器")
print("=" * 60)
# 爬取所有页面并下载图片
spider.crawl_all_pages(download_images=True)
# 保存结果到文件
spider.save_to_file()
print("\n程序执行完毕!")
print(f"图片保存在: fzu_images_all/ 目录")
print(f"爬取结果保存在: fzu_news_crawl_results.txt")
if __name__ == "__main__":
main()




② 作业心得
先把任务拆成“拿页面 → 抠图片/新闻 → 去重 → 落盘”四个独立环节,每一步都封装成方法,给未来加功能(视频、PDF、断点续传)留好口子。正则写起来其实挺爽,一句命名分组就能同时抠出 src、alt,但很快发现新闻标题里嵌双引号就能让模式翻车,于是把 [^"] 改成非贪婪 .? 再套 re.DOTALL ,算是给正则上了“保险丝”。真正花时间的是“如何不让同一图片反复下载”——用 URL 当 key 去重最干脆,但又要保留标题、来源页信息,于是折中搞了个“字典套字典”的临时映射,算是用空间换时间。下载目录、文件名合法性、过长截断、失败计数、下载报告,这些“边角料”功能占了一半代码量,却直接决定脚本能不能一次性跑完不用人工擦屁股。*

 浙公网安备 33010602011771号
浙公网安备 33010602011771号