


PyTorch 神经网络学习(官方教程中文版)(三、使用字符级RNN生成名字)
Pytorch的官方教程:https://pytorch123.com/
在做李宏毅老师的RNN的作业之前进行RNN相关的学习,相关名词与用到的函数:
UCS——通用字符集(Universal Character Set)
glob.glob(path)——所有路径下的符合条件的文件名的列表
os.path.splitext(“文件路径”)——分离文件名与扩展名
os.path.basename()——返回path最后的文件名
strip()——用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
split('\n')——按换行符进行分割
unicodedata.category()——把一个字符返回它在UNICODE里分类的类型
Mn——Nonspacing_mark
torch.cat——将两个张量(tensor)拼接在一起
数据下载https://download.pytorch.org/tutorial/data.zip
数据集为18个国家的姓氏,任务是根据训练得到的模型,在给定国家类别和首字母后,能得到一个与该国人名非常相似的一个人名。
导入的库函数,
from __future__ import unicode_literals, print_function, division from io import open import glob import os import unicodedata import string import torch import random import numpy as np import torch.nn as nn import time import matplotlib.pyplot as plt
一、数据预处理
定义所有的英文字符和" .,;'-"符号,
all_letters = string.ascii_letters + " .,;'-" n_letters = len(all_letters) + 1 # 停止位,当预测到的字母标签为n_letters-1时停止

数据导入,按照国家,人名的方式导入进字典category_lines,关于unicode和Ascii以及UTF-8可参考https://www.cnblogs.com/tsingke/p/10853936.html
def findFiles(path): return glob.glob(path) # glob.glob(path)所有路径下的符合条件的文件名的列表 def unicodeToAscii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' and c in all_letters ) # 读取文件并分成几行 def readLines(filename): lines = open(filename, encoding='utf-8').read().strip().split('\n') return [unicodeToAscii(line) for line in lines] # 构建category_lines字典,列表中的每行是一个国家类别 category_lines = {} all_categories = [] for filename in findFiles('/ML/data/names/*.txt'): category = os.path.splitext(os.path.basename(filename))[0] all_categories.append(category) lines = readLines(filename) category_lines[category] = lines n_categories = len(all_categories) if n_categories == 0: raise RuntimeError('Data not found. Make sure that you downloaded data ' 'from https://download.pytorch.org/tutorial/data.zip and extract it to ' 'the current directory.') print('# categories:', n_categories, all_categories) print(unicodeToAscii("O'Néàl"))
输出结果:

二、建立模型
教程使用的RNN模型如下所示,
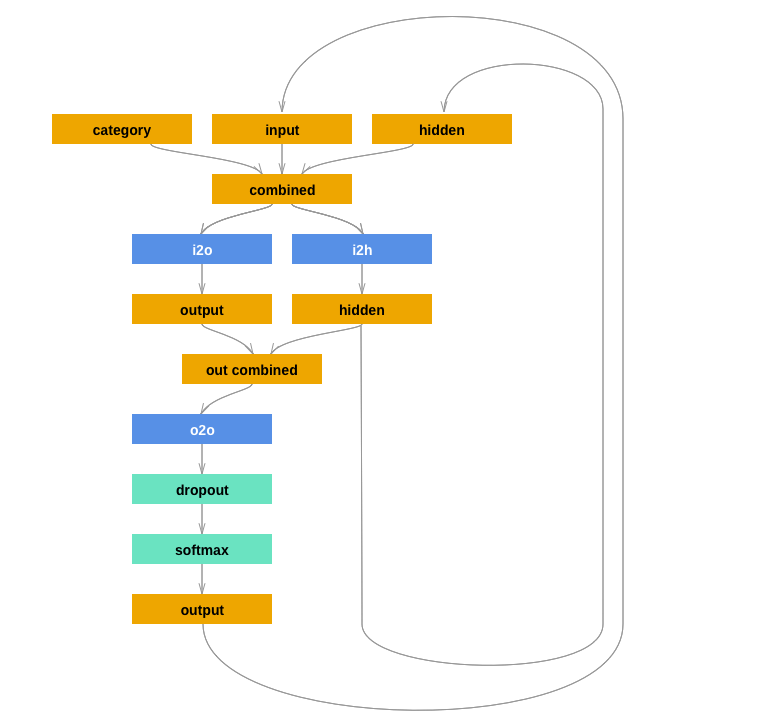
程序如下,
class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size) self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size) self.o2o = nn.Linear(hidden_size + output_size, output_size) self.dropout = nn.Dropout(0.1) self.softmax = nn.LogSoftmax(dim=1) # 对列做Softmax,最后得到的每行和为1;dim=0则每列和为1 def forward(self, category, input, hidden): input_combined = torch.cat((category, input, hidden), 1) hidden = self.i2h(input_combined) output = self.i2o(input_combined) output_combined = torch.cat((hidden, output), 1) output = self.o2o(output_combined) output = self.dropout(output) output = self.softmax(output) return output, hidden def initHidden(self): return torch.zeros(1, self.hidden_size)
参数初始化,国家类别、输入输出张量都需要初始化,这里的国家类别和输入张量采用one-hot张量,即有多少个国家(字符)类别,网络就用这么多数量的特征,在这些特征中,只有一个特征值是1,这个特征就是该国家(字符)在国家类别(字符)集合中的索引;而其余的特征值都是0。另外这里输入输出初始化函数采用相同的随机人名输入,输入张量取人名全长,而输出张量取第二到结束再加上一个休止符EOS(矩阵),同时保证了维度一致。
# Random item from a list def randomChoice(l): return l[random.randint(0, len(l) - 1)] # Get a random category and random line from that category def randomTrainingPair(): category = randomChoice(all_categories) line = randomChoice(category_lines[category]) return category, line def categoryTensor(category): li = all_categories.index(category) tensor = torch.zeros(1, n_categories) tensor[0][li] = 1 return tensor # One-hot matrix of first to last letters (not including EOS) for input def inputTensor(line): tensor = torch.zeros(len(line), 1, n_letters) for li in range(len(line)): letter = line[li] tensor[li][0][all_letters.find(letter)] = 1 return tensor # LongTensor of second letter to end (EOS) for target def targetTensor(line): letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))] letter_indexes.append(n_letters - 1) # EOS return torch.LongTensor(letter_indexes) def randomTrainingExample(): category, line = randomTrainingPair() category_tensor = categoryTensor(category) input_line_tensor = inputTensor(line) target_line_tensor = targetTensor(line) return category_tensor, input_line_tensor, target_line_tensor
三、训练模型
首先定义参数,包括RNN的参数向量大小,这里的损失采用的NLLLoss,NLLLoss的结果就是ln(Softmax())的输出与Label对应的那个值拿出来,再取相反数,再求均值。NLLLoss可参考https://blog.csdn.net/qq_22210253/article/details/85229988
rnn = RNN(n_letters, 128, n_letters) criterion = nn.NLLLoss() learning_rate = 0.0005 n_iters = 100000 print_every = 5000 plot_every = 500 all_losses = [] total_loss = 0 # Reset every plot_every iters start = time.time()
训练过程和以前一样,要说的是这里没有用pytorch自带的优化器,而是用下面循环来参数更新,但是运行时会出现报警(但程序还是可以运行)
for p in rnn.parameters(): p.data.add_(-learning_rate, p.grad.data)
用下面程序不会报警,p.data.add_(p.grad.data, alpha = -learning_rate),add()函数的用法如下所示,与传统参数更新一致。

def train(category_tensor, input_line_tensor, target_line_tensor): target_line_tensor.unsqueeze_(-1) hidden = rnn.initHidden() rnn.zero_grad() loss = 0 for i in range(input_line_tensor.size(0)): output, hidden = rnn(category_tensor, input_line_tensor[i], hidden) l = criterion(output, target_line_tensor[i]) loss += l loss.backward() for p in rnn.parameters(): p.data.add_(p.grad.data, alpha = -learning_rate) # 模型参数更新 return output, loss.item() / input_line_tensor.size(0)
计时小程序,以后编程可参考,
def timeSince(since): now = time.time() s = now - since m = np.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s)
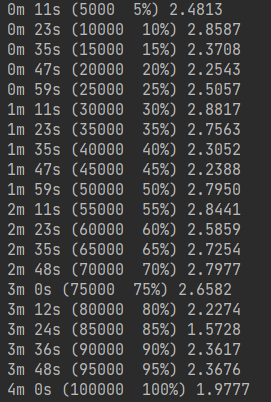
训练输出结果,代码和结果,
for iter in range(1, n_iters + 1): output, loss = train(*randomTrainingExample()) total_loss += loss if iter % print_every == 0: print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, loss)) if iter % plot_every == 0: all_losses.append(total_loss / plot_every) total_loss = 0
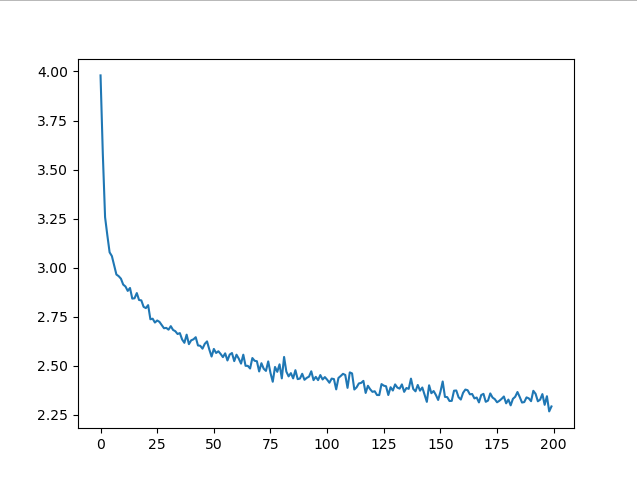
plt.figure()
plt.plot(all_losses)
plt.show()
四、预测人名
用计算好的模型,输入首字母后得到人名,模型在这里我觉得有一个问题就是每次迭代取的都是根据首字母预测的人名的第二个字母,来输出或判断终止与否,丢失了整个输出人名的信息。
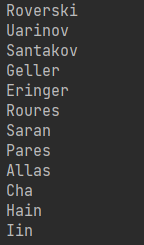
max_length = 20 # 人名的最大长度 def sample(category, start_letter='A'): with torch.no_grad(): # no need to track history in sampling category_tensor = categoryTensor(category) input = inputTensor(start_letter) hidden = rnn.initHidden() output_name = start_letter for i in range(max_length): output, hidden = rnn(category_tensor, input[0], hidden) topv, topi = output.topk(1) # topk(1)得到的是两组数据,分别为每行中的最大数据已经其对应的索引 topi = topi[0][0] if topi == n_letters - 1: break else: letter = all_letters[topi] output_name += letter input = inputTensor(letter) return output_name # Get multiple samples from one category and multiple starting letters def samples(category, start_letters='ABC'): for start_letter in start_letters: print(sample(category, start_letter)) samples('Russian', 'RUS') samples('German', 'GER') samples('Spanish', 'SPA') samples('Chinese', 'CHI')
输出结果为,


 浙公网安备 33010602011771号
浙公网安备 33010602011771号