PyTorch 神经网络学习(官方教程中文版)(二、利用Pytorch搭建图像分类器)
pytorch的官方教程https://pytorch123.com/
训练一个图像分类器的步骤如下所示:

需要加入的库函数:
import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch.nn as nn import torch.nn.functional as F import torch.optim as optim
训练集和测试集通过torchvision加载,
# 先将数据转为Tensor,然后进行归一标准化,原图片为三通道,共三组数,前为mean,后为std transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # train的True or False 决定载入的是训练集还是测试集,download的True or False决定是否下载CIFAR10 trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) # Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中根据batch_size得到数据片段,shuffle用来判断每次数据分段时是否需要打乱数据 # 原示例中为双线程加载数据,但我的电脑不行,一直报错,这里设置为了0,也就是单线程。 trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=0) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=0) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
展示需要训练的部分图片,
def imshow(img): img = img / 2 + 0.5 # unnormalize npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() print(trainloader) # 数据打乱所以得到的随机的 dataiter = iter(trainloader) images, labels = dataiter.next() # show images imshow(torchvision.utils.make_grid(images)) # print labels print(' '.join('%5s' % classes[labels[j]] for j in range(4)))


定义一个卷积神经网络 在这之前先 从神经网络章节 复制神经网络,并修改它为3通道的图片(在此之前它被定义为1通道),16*5*5代替了self.num_flat_features(x),效果是一样的,都是第二次池化后得到的x尺寸。
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net()
定义一个损失函数和优化器 让我们使用分类交叉熵Cross-Entropy 作损失函数,动量SGD做优化器。逻辑回归的损失函数用的便是交叉熵,交叉熵可以简单理解为两个概率分布的近似程度,公式如下,
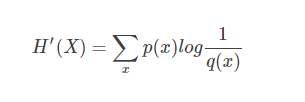
动量SGD优化器是考虑了模型参数更新过程中参数的“惯性‘作用,防止参数停留在损失函数的’鞍部”,局部最小值等微分为0但不是全局最小值的地方。
v = momentum * v - learning_rate * dx
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
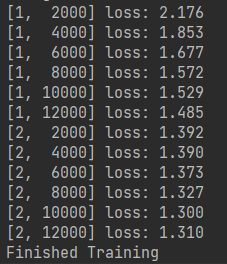
接下来计算随时函数,共两次迭代,但当训练完每2000张都将输出平均的损失函数,
for epoch in range(2): # loop over the dataset multiple times running_loss = 0.0 for i, data in enumerate(trainloader, 0): # get the inputs inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: # print every 2000 mini-batches print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000)) running_loss = 0.0 print('Finished Training')
结果如下,
像训练集时一样,取出四幅图进行观察,由于Dataloader时设置不打乱数据,每次所取的图片都是前面四张,并不会变,现在看一下模型的预测结果,
dataier = iter(testloader) images1, labels1 = dataier.next() # show images imshow(torchvision.utils.make_grid(images1)) # print labels print(' '.join('%5s' % classes[labels1[j]] for j in range(4))) outputs = net(images1) x, predicted = torch.max(outputs, 1) print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]for j in range(4)))


训练好的模型在测试集上的效果很一般,正确率在55%,随机预测的正确率为10%左右,很稳定的数字,随即预测就是丢弃掉迭代那个循环,一般都在9%到10%徘徊
correct = 0 total = 0 with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %d %%' % ( 100 * correct / total))

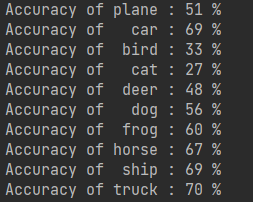
最后是在测试集上测试模型,
class_correct = list(0. for i in range(10)) class_total = list(0. for i in range(10)) with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs, 1) c = (predicted == labels).squeeze() for i in range(4): label = labels[i] class_correct[label] += c[i].item() class_total[label] += 1 for i in range(10): print('Accuracy of %5s : %2d %%' % ( classes[i], 100 * class_correct[i] / class_total[i]))
输出:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号