


Kafka入门之broker-消息设计

消息设计
1.消息格式
Kafka的实现方式本质上是使用java NIO的ByteBuffer来保存消息,同时依赖文件系统提供的页缓存机制,而非依靠java的堆缓存。
2.版本变迁
0.11.0.0版本是kafka的一个里程碑式的大版本。特别是对于消息格式进行了改进和升级。kafka的消息版本变迁:
1.V0:指0.10.0.0之前的版本,是kafka最早的消息版本,格式如下:
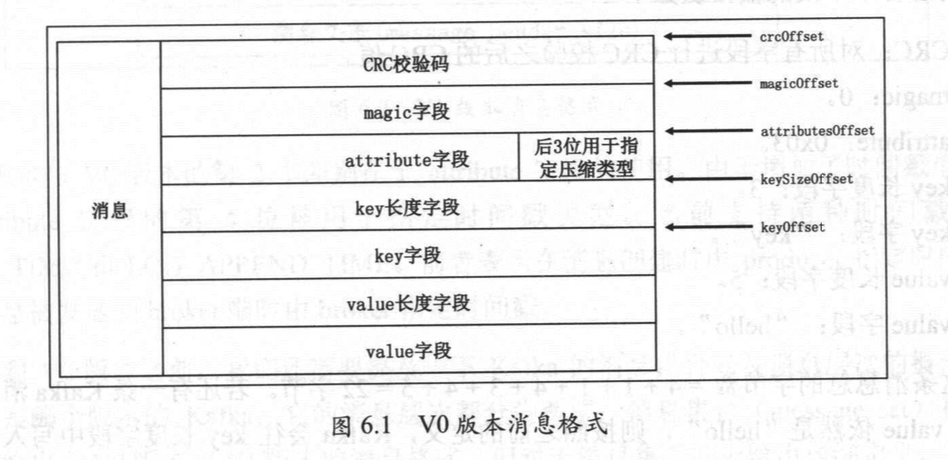
crc校验码:4字节,用于确保消息在传输过程中不会被恶意篡改。
magic:单字节的版本号,V0版本magic=0,V1版本magic=1,V2版本magic=2.
attribute:单字节属性字段,目前只使用低3位表示消息的压缩类型
key长度字段:4字节,若未指定key,则给该字段赋值为-1.
key值:
value长度字段:4字节,未指定value,则为-1。
value值:
2.V1:Kafka0.10.0.0中改进了V0版本的消息格式,推出了V1版本的格式,主要变化就是在消息中加入了时间戳字段。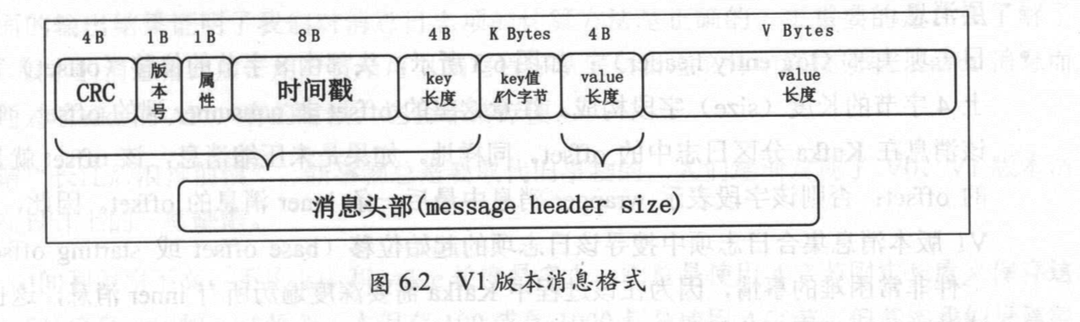
新增消息时间戳,并且attribute的第四位表示时间戳类型。
3.V2:
消息集合:一个消息集合包含若干日志项,而每个日志项都装了实际的消息和一组元数据信息。Kafka日志文件就是由一系列消息集合日志项构成的。Kafka不会在消息层面上直接操作,它总是在消息集合上进行写入操作。
V2版本之前的消息集合:

浅层消息+日志头部,头部由8字节位移(offset)字段加上4字节的长度(size)字段构成,这里的offset指的是该消息在Kafka分区日志中offset。如果未压缩该offset就是消息的offset,否则该字段表示wrapper消息中最后一条inner消息的offset。因此从v0,v1版本消息集合日志项中搜寻该日志项的起始位移是一件非常困难的事情,因为在该过程中Kafka需要深度便利所有inner消息,这也就意味着broker端需要执行解压缩的操作,可见代价之高。
V2版本消息格式: v2版本借鉴了Google ProtoBuffer中的zig-zag编码方式,使得绝对值较小的整数占用比较少的字节
v2版本借鉴了Google ProtoBuffer中的zig-zag编码方式,使得绝对值较小的整数占用比较少的字节
增加消息总长度字段:kafka操作消息时可直接获取总字节数,直接创建出等大小的ByteBuffer,然后分别填装其他字段,简化了消息处理过程,总字节数的引入还实现了消息遍历时的快速跳跃和过滤,省去了很多空间拷贝的开销。
保存时间戳增量:不再使用8字节保存时间戳信息,而是用可变长度保存与batch起始时间戳的差值
保存位移增量:保存消息位移与外层batch起始位置的差值,而不再固定保存8字节的位移值。
增加消息头部:对用户可见,v2版本中每条消息都必须有一个头部数组,每个头部信息都是一个key-value主要为了满足用户的一些定制化需求,比如,做集群间的消息路由或承载消息的一些特定元数据信息。
去除消息级CRC校验:对整个消息batch进行crc校验。
废弃attribute字段:v0,v1版本格式都有一个attribute字段,v2版本的消息正式废弃了这个字段,原先保存在attribute字段中的压缩类型,时间戳等信息都统一保存在外层的batch格式字段中,但v2版本依然保留了单字节的attribute字段留作以后扩展使用。
batch格式:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号