
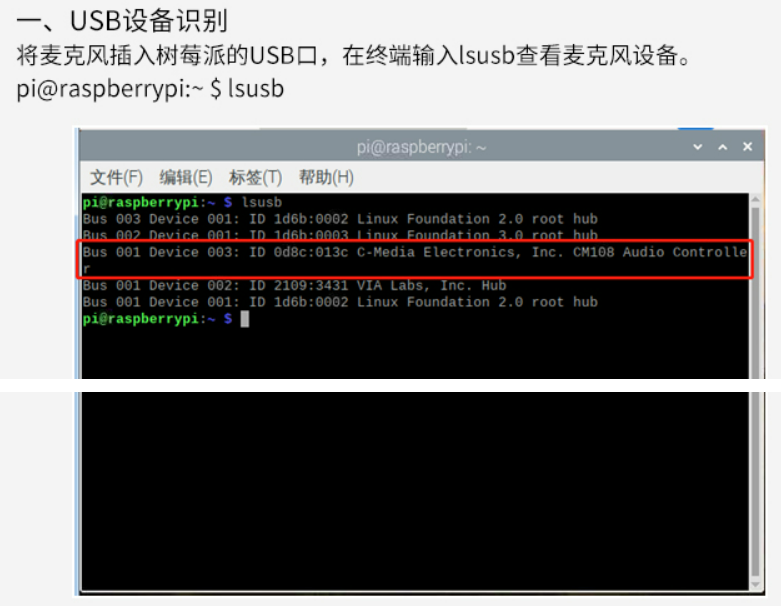
搭建一个声音采集和输出的硬件平台。硬件设备包括一个usb麦克风和一个3.5mm音频输出,麦克风最好采用免驱和树莓派兼容的usb设备。音频输出直接采用树莓派的3.5mm音频输出,树莓派的3.5mm接口采用的是美国标准的输出,如何测试没有输出你需要看一下你的耳机或者音箱接口是不是一致的,不一致的可以在某宝上购买转接头。我们采用pyaudio录音,下面配置一下树莓派。
树莓派下安装pyaudio与使用
pyaudio是python的模块,在树莓派下安装pyaudio 首先需安装portaudio.dev
1、安装portaudio.dev : sudo apt-get install portaudio.dev
2、安装python-pyaudio: sudo apt-get install python-pyaudio
3、安装sox快速检测麦克风配置是否正确: sudo apt-get install sox
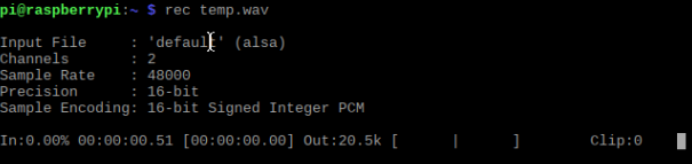
4、(可跳过)测试麦克风配置是否正确,树莓派终端输入以下命令: rec temp.wav
注意如果显示提示没有找到某个头文件失败了,可能是由于raspberry 8.0 图形界面设置默认声卡有BUG 就只能手动去改~/.asoundrc文件。在/home/pi目录下创建一个名为.asoundrc文件 然后把下面的复制进去。


pcm.!default { type asym playback.pcm { type plug slave.pcm "hw:0,0" } capture.pcm { type plug slave.pcm "hw:1,0" } } ctl.!default { type hw card 1 }
4、测试pyaudio 代码如下:录音5s并保存为audio.wav播放。
# 测试pyaudio 使用pyaudio录音,录音完毕播放录音内容 # 需要安装pyaudio 安装过程在教程中讲解 # pyaudio API函数库参考: http://people.csail.mit.edu/hubert/pyaudio/docs/#pyaudio.Stream.write import wave from pyaudio import PyAudio,paInt16 # 设置采样参数 NUM_SAMPLES = 2000 TIME = 2 chunk = 1024 # read wav file from filename def read_wave_file(filename): fp = wave.open(filename,'rb') nf = fp.getnframes() #获取采样点数量 print('sampwidth:',fp.getsampwidth()) print('framerate:',fp.getframerate()) print('channels:',fp.getnchannels()) f_len = nf*2 audio_data = fp.readframes(nf) # save wav file to filename def save_wave_file(filename,data): wf = wave.open(filename,'wb') wf.setnchannels(1) # set channels 1 or 2 wf.setsampwidth(2) # set sampwidth 1 or 2 wf.setframerate(16000) # set framerate 8K or 16K wf.writeframes(b"".join(data)) # write data wf.close() #recode audio to audio.wav def record(): pa = PyAudio() # 实例化 pyaudio # 打开输入流并设置音频采样参数 1 channel 16K framerate stream = pa.open(format = paInt16, channels=1, rate=16000, input=True, frames_per_buffer=NUM_SAMPLES) audioBuffer = [] # 录音缓存数组 count = 0 # 录制40s语音 while count<TIME*20: string_audio_data = stream.read(NUM_SAMPLES) #一次性录音采样字节的大小 audioBuffer.append(string_audio_data) count +=1 print('.'), #加逗号不换行输出 # 保存录制的语音文件到audio.wav中并关闭流 save_wave_file('audio.wav',audioBuffer) stream.close() # 播放后缀为wav的音频文件 def play(): # 打开audio.wav wf = wave.open(r"audio.wav",'rb') # 实例化pyaudio p = PyAudio() # 打开流 stream = p.open( format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), rate=wf.getframerate(), output=True) # 播放音频 while True: data = wf.readframes(chunk) if data == "":break stream.write(data) # 释放IO stream.stop_stream() stream.close() p.terminate() # main函数 录制5s音频并播放 if __name__ == '__main__': print('record ready...') record() print('record over!') play()
注意如果启动程序报错误IO错误应该是没有启动pulseaudio
确保pulseaudio服务器依旧在工作
安装pulseaudio,如下命令:
sudo apt-get install pulseaudio
然后运行pulseaudio
pulseaudio --start
注意如果有其他异常可以看下以下两个链接
使用不同的usb摄像头会出现采样率报错的问题,解决方案参考以下博客:
https://blog.csdn.net/u013860985/article/details/79326379
https://blog.csdn.net/u013372900/article/details/80296125
添加一个新的~/.asoundrc 到pi目录下:sudo nano ~/.asoundrc
输入以下内容:
pcm.!default{ type hw card 1 } ctl.!default{ type hw card 1 } 或者: pcm.!default{ type asym playback.pcm { type plug slave.pcm "hw:0,0" } capture.pcm { type plug slave.pcm "hw:1,0" } } ctl.!default{ type hw card 1 }
树莓派音频输出设置:
1、选择树莓派 audio output 为AUTO或者3.5mm
在终端输入sudo raspi-config 设置:选择1.system options,然后选择audio,选择headphone即可。
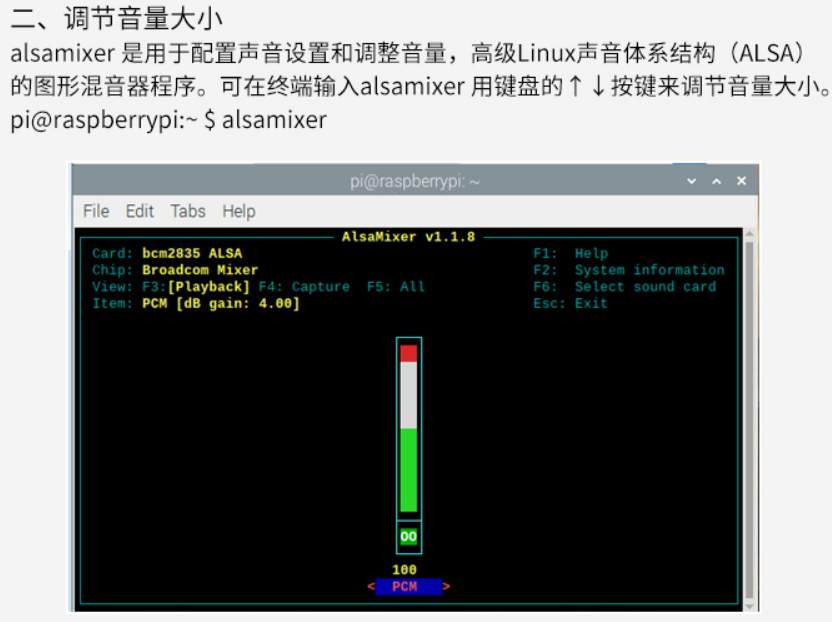
2、如何调整输出音量,终端输入 alsamixer 命令然后上下键调整
3、语音合成的音频为MP3文件,pyaudio只能播放wav文件,所以需要安装MP3播放插件 mplayer。
安装 sudo apt-get install mplayer
测试 mplayer xx.mp3 (需先进入xx.mp3的文件夹下)
Python 程序播放 MP3: os.system('mplayer %s'%'xx.mp3')
注意: 要到播放的的mp3路径下启动播放这个文件


 浙公网安备 33010602011771号
浙公网安备 33010602011771号