1:Redis的认识与使用
1.1:Redis是什么
Redis(Remote Dictionary Server)是一个开源的内存数据库,它提供了快速,可扩展和灵活的数据存储访问解决方案,Redis以键值对的形式存储数据,并支持多种数据结构,包括字符串,哈希,列表,集合,有序集合等,它的特点主要包括
1:快速高效:Redis完全存储在内存中,因此具有快速的读写性能,它使用高效的数据结构和算法,可以在毫秒级别内处理大量的请求。
2:数据持久化:Redis支持将数据持久化到磁盘,可以将内存中的数据定期写入磁盘,以防止数据丢失。
3:高可用性:Redis提供了主从复制,哨兵机制,可以实现数据的高可用和故障恢复。
4:数据结构丰富:Redis支持多种数据结构,如:字符串,哈希,列表,集合和有序集合,使得它非常适合于各种应用场景
1.2:Redis常用场景
1:缓存:Redis可以用作高速缓存存储,将常用的数据存储在内存中,以提高读取性能,它可以有效减轻数据库的负载,加快网站或者应用程序的响应速度。
2:会话存储:将用户会话数据存储在Redis中,以实现分布式可扩展的会话管理,这样可以实现无状态的应用服务器,提高应用程序的扩展性和性能。
3:计数器和排行榜:使用Redis的原子操作和有序集合,可以实现计数器和排行功能,例如,统计网站的访问次数或者实时更新热门文章排行等。
4:分布式锁:利用Redis的原子性和过期时间设置,可以实现分布式锁的功能,用于协调多个应用程序之间的资源访问。
总之Redis是一个强大的内存数据库,适用于各个场景,包括:缓存,会话存储,计数器和排行榜,消息队列等,它的快速性能,灵活的数据结构和丰富的功能使其成为许多应用程序中常用的数据存储解决方案
1.3:Redis第三方库
1:github.com/go-redis/redis:是一个功能丰富且易于使用的Redis客户端库,提供了各种操作Redis的方法,包括数据读写,事务,发布/订阅等
github:https://github.com/go-redis/redis
我们需要有一台Redis的服务器,这里我用Docker启动了一个Redis的服务
1:下载依赖(Go语言)
# 这里我们使用的是v6的版本,但是官方是v9的版本
go get -u "github.com/go-redis/redis"
1.4:Redis客户端使用
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
data := client.Ping()
fmt.Println(data)
}
PS D:\Codes\mmp> go run .\redis\base\main.go
ping: PONG
# 这里可以看到是返回了Pong,也就证明了我们成功连接了Redis了,这就是Redis的Client的初始化了,不过有些时候我们需要连接的不一定是一个节点而是一个集群,不过这里我们先不说集群,我们先来分析一下Client的一个初始化参数的详细解释
type Options struct {
// 网络类型: tcp 或 unix.
// 默认: tcp
Network string
// redis地址:格式是host:port
Addr string
// 新建一个redis连接的时候会调用这个函数
OnConnect func(*Conn) error
// Redis服务的密码,没有可以设置为空
Password string
// Redis的数据库,从序号0开始,默认是0,可以不设置
DB int
// Redis操作失败的最大尝试次数,默认不重试
MaxRetries int
// 最小重试间隔时间
// 默认是8ms,-1表示关闭
MinRetryBackoff time.Duration
// 最大重试间隔时间
// 默认为512ms,-1表示关闭
MaxRetryBackoff time.Duration
// Redis连接超时时间
// 默认是5s
DialTimeout time.Duration
// socket读取超时时间
// 默认为3s
ReadTimeout time.Duration
// socket写超时时间
// 默认和读一样
WriteTimeout time.Duration
// Redis连接池的最大连接数
// 默认连接池大小等于 cpu数量 * 10
PoolSize int
// Redis连接池最小空闲连接数
MinIdleConns int
// Redis连接最大的存活时间,默认不会关闭过时的连接
MaxConnAge time.Duration
// 当你从redis连接池获取一个连接之后,连接池最多等待这个拿出去的连接多长时间
// 默认是等待 ReadTimeout + 秒
PoolTimeout time.Duration
// Redis连接池多久会关闭一个空闲连接
// 默认是5分钟,-1则表示关闭这个配置
IdleTimeout time.Duration
// 多长时间监测一次空闲连接
// 默认是1分钟,-1表示关闭空闲连接监测
IdleCheckFrequency time.Duration
// 只读设置,如果设置为true,redis只能查询缓存不能更新
readOnly bool
}
1.5:Redis键值的基本用法
| 函数 |
功能 |
Set |
设置一个key的值 |
Get |
查询keyt的值 |
GetSet |
设置一个key的值,并返回这个值的旧值 |
SetNX |
如果key不存在,则设置这个key的值 |
MGet |
批量查询key的值 |
MSet |
批量设置key的值 |
Incr,IncrBy,IncrByFloat |
针对一个key的数值进行递增操作 |
Decr,DecrBy |
针对一个key的数值进行递减操作 |
Del |
删除key操作,可批量删除 |
Expire |
设置key的过期时间 |
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
// 设置一个键值
err := client.Set("name", "gitlayzer", 0).Err()
if err != nil {
fmt.Println("set error:", err)
} else {
fmt.Println("set success")
}
// 获取一个键值
val, err := client.Get("name").Result()
if err != nil {
fmt.Println("get error:", err)
} else {
fmt.Println("name:", val)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
set success
name: gitlayzer
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
oldVal, err := client.GetSet("name", "New Gitlayzer").Result()
if err != nil {
fmt.Println("getset error:", err)
} else {
fmt.Println("getset success", oldVal)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
getset success gitlayzer
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
oldVal, err := client.GetSet("name", "Gitlayzer").Result()
if err != nil {
fmt.Println("GetSet Error:", err)
} else {
fmt.Println("GetSet Success:", oldVal)
}
client.SetNX("name", "New Gitlayzer", 0)
newVal, err := client.Get("name").Result()
if err != nil {
fmt.Println("Get Error:", err)
} else {
fmt.Println("Get Success:", newVal)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
GetSet Error: redis: nil
Get Success: Gitlayzer
PS D:\Codes\mmp> go run .\redis\base\main.go
GetSet Success: Gitlayzer
Get Success: Gitlayzer
# 可以看到两次,第一次是没有值就设置上了,第二次再获取就有了,然后就没有走到设置新值的地方
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
// 批量设置键值对(不可批量设置过期时间,需要单独设置过期时间)
err := client.MSet("name", "Gitlayzer", "age", 18).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("MSet success")
}
// 批量获取键值对
vals, err := client.MGet("name", "age").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("MGet success")
fmt.Println(vals)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
MSet success
MGet success
[Gitlayzer 18]
# 这里批量获取出来的值的类型是一个[]interface类型
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.Set("num", 1, 0).Err()
if err != nil {
fmt.Println("set error:", err)
} else {
val, err := client.Incr("num").Result()
if err != nil {
fmt.Println("incr error:", err)
} else {
fmt.Println("num:", val)
}
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
num: 2
# 我们可以发现它是基于我们设置的一个值,然后进行了一次递增,前提是value必须为整数,但是这个有一个问题就是,如果我们不是想每次递增1怎么办呢?那么这就涉及到Incr的进阶版了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.Set("num", 1, 0).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("set num success")
}
val, err := client.IncrBy("num", 2).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("incrby num success, val:", val)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
set num success
incrby num success, val: 3
# 可以看到我们指定了上面的num为1,然后下面指定这个key每次递增2,然后结果就是3,是符合我们的要求的,那么这个时候我们如果想递增小数怎么办,这个时候又需要再进阶一次
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.Set("num", 1, 0).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("set num success")
}
val, err := client.IncrByFloat("num", 2.5).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("incrby num success, val:", val)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
set num success
incrbyfloat num success, val: 3.5
# 那么我们用这个IncrByFloat就可以递增小数了,那么有递增肯定有递减,那么我们下面来看看递减
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.Set("num", 5, 0).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("set num success")
}
val, err := client.Decr("num").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("decr num success %d\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
set num success
decr num success 4
# 我们可以看到原始赋值的value是5,然后我们使用了Decr之后,递减了1,然后得到的结果就是4了,也符合我们的需求,但是和递增一样,我们或许想递减的不是1那么DecrBy就是我们想要的操作了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.Set("num", 5, 0).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("set num success")
}
val, err := client.DecrBy("num", 2).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("decr num success %d\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
set num success
decr num success 3
# 和递增一样,我们只需要指定一次递减多少就可以了,但是需要注意的是,递减没有基于浮点数的递减哦,然后我们需要了解的就是删除指定的key了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.Set("num", 5, 0).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("set num success")
}
val, err := client.Get("num").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("num", val)
}
err = client.Del("num").Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("del num success")
}
val, err = client.Get("num").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("num", val)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
set num success
num 5
del num success
redis: nil
# 我们可以通过代码,看到先设置了一个key然后获取到了,然后删除这个key再去获取就没有了,成了nil,这就等于这个key已经被我们删除了,然后我们前面提到过批量设置的key是不能设置过期时间的,然后client还专门提供了一个设置过期时间的函数,下面我们来看看
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.MSet("name", "zhangsan", "age", 18).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("MSet success")
}
tf, err := client.Expire("name", 5*time.Minute).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("Expire success", tf)
}
ttl, err := client.TTL("name").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("TTL success", ttl)
}
ttl, err = client.TTL("age").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("TTL success", ttl)
}
}
PS D:\Codes\mmp> go run .\redis\base\main.go
MSet success
Expire success true
TTL success 5m0s
TTL success -1s
# 可以看到,这里我们设置了一个批量的key,然后并没有办法去设置它的过期时间,然后我们就使用Expire方法针对name的过期时间设置到了5分钟,然后还可以用TTL方法获取name的过期时间,然后还有获取到的age的时间是-1s,其实就是永不过期,那么到这里其实就是Redis的基础的字符串的操作了,下面我们要做的就是针对Redis的一些更进一步的cao'zuo
1.6:RedisHash用法
在Redis中,Hash(哈希)是一种数据类型,它类似于一个键值对的集合,在Hash中,每个键都与一个值相关联,这些键值都被存储在一个哈希表中,Redis的Hash提供了搞笑的存储和访问方式,适用于存储和操作具有结构化数据的场景
Redis Hash操作主要有2-3个元素组成:
1:key:redis key唯一标识
2:field:hash 数据的字段名
3:value:值,有些操作可以不需要值
# 函数解析
| 函数 |
功能 |
HSet |
根据key和field字段设置,field字段的值 |
HGet |
根据key和field字段,查询field字段的值 |
HGetAll |
根据key查询所有字段和值 |
HIncrBy |
根据key和field字段,累加数值 |
HKeys |
根据key返回所有字段名 |
HLen |
根据key,查询hash的字段数量 |
HMGet |
根据key和多个字段名,批量查询多个hash字段值 |
HMSet |
根据key和多个字段名和字段值,批量设置hash字段值 |
HSetNX |
如果field字段不存在,则设置hash字段值 |
HDel |
根据key和字段名,删除hash字段,支持批量删除hash字段 |
HExists |
检测hash字段是否存在 |
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.HSet("user", "name", "张三").Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("HSet success")
}
val, err := client.HGet("user", "name").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("HGet success, value is %s", val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HSet success
HGet success, value is 张三
# 可以看到这里我们通过HSet设置了一个Hash,然后我们通过HGet指定key和hash名称,然后获取到了value的值,同理,这里HSet也是不可以设置过期时间的,我们也需要单独去设置过期时间
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
client.HSet("user", "name", "张三")
client.HSet("user", "age", "18")
val, err := client.HGetAll("user").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("HGet success, Values is %s", val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HGet success, Values is map[age:18 name:张三]
# 这里就是我们针对一个key下面设置了多个hash字段,然后我们就可以使用HGetAll指定这个key然后列出下面的所有的field和values,获取的是一个map
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
client.HSet("user", "name", "张三")
client.HSet("user", "age", "18")
val, err := client.HIncrBy("user", "age", 2).Result()
if err != nil {
fmt.Println("HIncrBy err:", err)
} else {
fmt.Println("HIncrBy val:", val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HIncrBy val: 20
# 这个就类和IncrBy递增,可以指定递增的数量,当然这里也可以在HIncrBy的时候设置一个新值,而不是基于旧的key和field
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
client.HSet("user", "name", "张三")
client.HSet("user", "age", "18")
val, err := client.HIncrByFloat("user", "age", 2.5).Result()
if err != nil {
fmt.Println("HIncrByFloat err:", err)
} else {
fmt.Println("HIncrByFloat val:", val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HIncrByFloat val: 20.5
# 这个是和上面的递增一样,只不过这个支持的是Float的递增,当然这里也可以在HIncrBy的时候设置一个新值,而不是基于旧的key和field
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
client.HSet("user", "name", "张三")
client.HSet("user", "age", "18")
val, err := client.HKeys("user").Result()
if err != nil {
fmt.Println("HKeys err:", err)
} else {
fmt.Println("HKeys:", val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HKeys: [name age]
# 这个就是列出一个key下面所有的hash字段了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
client.HSet("user", "name", "张三")
client.HSet("user", "age", "18")
val, err := client.HLen("user").Result()
if err != nil {
fmt.Println("HLen error:", err)
} else {
fmt.Println("HLen:", val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HLen: 2
# HLen它可以列出一个key下面的field的数量,这里根据代码我们可以看出,我们设置了两个field,那么我们得到的结果就是2,符合我们的期望,那么下面就是批量操作了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
// 批量设置Hash
err := client.HMSet("user", map[string]interface{}{"name": "张三", "age": 18, "sex": "男"}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("HMSet成功")
}
// 批量获取Hash
val, err := client.HMGet("user", "name", "age").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("HMGet成功,val:%v\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HMSet成功
HMGet成功,val:[张三 18]
# 这和前面我们用到的批量基本是一样的,只不过这里多了一个field的值而已
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.HMSet("user", map[string]interface{}{"name": "张三", "age": 18, "sex": "男"}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("HMSet成功")
}
client.HSetNX("user", "name", "李四")
client.HSetNX("user", "school", "清华大学")
val, err := client.HMGet("user", "name", "age", "school").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("HMGet成功,val:%v\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HMSet成功
HMGet成功,val:[张三 18 清华大学]
# 那么这个MSetNX我想也不用多解释了,就是判断一个key下面的hash值是否存在,如果存在则不更改值,否则就写进去一个新值,可以清楚的看到school被设置进去了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.HMSet("user", map[string]interface{}{"name": "张三", "age": 18, "sex": "男", "school": "清华大学"}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("HMSet成功")
}
delErr := client.HDel("user", "name", "age", "sex").Err()
if delErr != nil {
fmt.Println(delErr)
} else {
fmt.Println("删除成功")
}
val, geterr := client.HGetAll("user").Result()
if geterr != nil {
fmt.Println(geterr)
} else {
fmt.Println(val)
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HMSet成功
删除成功
map[school:清华大学]
# 那么我们删除的时候也是可以根据自己的需求去删除一个key下的某一个或者多个hash值,这里我们就删除了user下的name,age,sex的三个值,最后得到的是一个school的值
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.HMSet("user", map[string]interface{}{"name": "张三", "age": 18, "sex": "男", "school": "清华大学"}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("HMSet成功")
}
val, err := client.HExists("user", "name").Result()
if err != nil {
fmt.Println(err)
} else if val {
fmt.Println("存在")
} else {
fmt.Println("不存在")
}
}
PS D:\Codes\mmp> go run .\redis\hash\main.go
HMSet成功
存在
# 那么这个就是最后一个操作了,就是判断一个key内是否存在某个field,它返回的是一个bool值,这里需要说一下,过期时间的设置方法和前面的一致
1.7:Redis列表
Redis列表是简单的字符串列表,列表是有序的,列表中的元素可以重复,可以添加一个元素到列表的头部(左边)或者尾部(右边)
# 函数解析
| 函数 |
功能 |
LPush |
从列表插入数据 |
LPushX |
跟LPush的区别是,仅当列表存在的时候才插入数据 |
RPop |
从列表的右边删除第一个数据,并返回删除的数据 |
RPush |
从表的右边插入数据 |
RPushX |
跟RPush的区别是,仅当列表存在的时候才插入数据 |
LPop |
从列表的左边删除第一个数据,并返回删除的数据 |
LLen |
返回列表的大小 |
LRange |
返回列表的一个范围内的数据,也可以返回全部数据 |
LRem |
删除列表中的数据 |
LIndex |
根据索引坐标,查询列表中的数据 |
LInsert |
在指定位置插入数据 |
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
// 从列表左边插入数据
err := client.LPush("list", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j").Err()
if err != nil {
fmt.Println(err)
}
val, err := client.LRange("list", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println(val)
}
}
PS D:\Codes\mmp> go run .\redis\list\main.go
[j i h g f e d c b a]
# 从这里可以看出我们设置了一个列表,并且获取到了它的数据,那么这个我们要知道的是因为是从左边插入数据,所以是按照a左边是b,b左边是c插入的,依次循环,然后我们还基于数据的下标去获取到了数据
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.LPush("list", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j").Err()
if err != nil {
fmt.Println(err)
}
val, err := client.RPop("list").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("RPop: %v\n", val)
}
data, err := client.LRange("list", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println(data)
}
}
PS D:\Codes\mmp> go run .\redis\list\main.go
RPop: a
[j i h g f e d c b a j i h g f e d c b]
# 这个结果可能会有一点抽象,但是我们看结果也能看出来,我们删除了一个a,但是由于是第二次执行,所以我们要找第二组数据中是否有a,我们发现没有,那么这个时候就实现了我们删除了右边的第一个数据的操作了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.LPush("list", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j").Err()
if err != nil {
fmt.Println(err)
}
val, err := client.LPop("list").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("RPop: %v\n", val)
}
data, err := client.LRange("list", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println(data)
}
}
PS D:\Codes\mmp> go run .\redis\list\main.go
RPop: j
[i h g f e d c b a j i h g f e d c b a j i h g f e d c b]
# 这个相信大家也能看出来了,我们基于上面的结果然后插入了一个新的值,但是发现左边并非是j,而是i,也就是说我们从左边删除了一个数据,那么这个LPop就是删除左边的一个数据
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.LPush("list", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j").Err()
if err != nil {
fmt.Println(err)
}
val, err := client.LLen("list").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println(val)
}
}
PS D:\Codes\mmp> go run .\redis\list\main.go
38
# 从这个结果我们不难看出,这是列出了我们列表的长度
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
// 获取现有列表的所有数据
oldColum, err := client.LRange("list", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("oldColum: %v\n", oldColum)
}
// 删除从左边开始第一位到右边数据中包含c的数据,并返回删除的个数
val, err := client.LRem("list", 0, "c").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("val: %v\n", val)
}
// 获取删除某些数据后的新列表
newColum, err := client.LRange("list", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("newColum: %v\n", newColum)
}
}
PS D:\Codes\mmp> go run .\redis\list\main.go
oldColum: [j i h g f e d c b a j i h g f e d c b a j i h g f e d c b a i h g f e d c b a j i h g f e d c b a j i h g f e d c b]
val: 5
newColum: [j i h g f e d c b j i h g f e d c b j i h g f e d c b i h g f e d c b j i h g f e d c b j i h g f e d c b]
PS D:\Codes\mmp> go run .\redis\list\main.go
oldColum: [j i h g f e d c b j i h g f e d c b j i h g f e d c b i h g f e d c b j i h g f e d c b j i h g f e d c b]
val: 6
newColum: [j i h g f e d c j i h g f e d c j i h g f e d c i h g f e d c j i h g f e d c j i h g f e d c]
PS D:\Codes\mmp> go run .\redis\list\main.go
oldColum: [j i h g f e d c j i h g f e d c j i h g f e d c i h g f e d c j i h g f e d c j i h g f e d c]
val: 6
newColum: [j i h g f e d j i h g f e d j i h g f e d i h g f e d j i h g f e d j i h g f e d]
# 这是我执行的结果,也就是说,我们只需要指定删除数据的开始与删除数据本身,就可以在列表内删除此数据了,并且返回的是删除了多少个这样的数据的值,0表示全部删除,1表示删除1个,超出现有指定数据的范围也是全部删除
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
oldColum, err := client.LRange("list", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("oldColum: %v\n", oldColum)
}
val, err := client.LRem("list", 0, "j").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("val: %v\n", val)
}
newColum, err := client.LRange("list", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("newColum: %v\n", newColum)
}
oneVal, err := client.LIndex("list", 0).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("oneVal: %v\n", oneVal)
}
twoVal, err := client.LIndex("list", -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("twoVal: %v\n", twoVal)
}
}
PS D:\Codes\mmp> go run .\redis\list\main.go
oldColum: [i h g f e d i h g f e d i h g f e d i h g f e d i h g f e d i h g f e d]
val: 0
newColum: [i h g f e d i h g f e d i h g f e d i h g f e d i h g f e d i h g f e d]
oneVal: i
twoVal: d
# 这个想必大家也都能看出结果吧,就是根据下标查找指定的数据,那么负数就是从右边查找数据了,这个就无可厚非了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
client.LInsert("list", "BEFORE", "g", "你好")
client.LInsert("list", "AFTER", "g", "上海")
newColum, err := client.LRange("list", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("newColum: %v\n", newColum)
}
}
PS D:\Codes\mmp> go run .\redis\list\main.go
newColum: [i h 你好 g 上海 f e d i h g f e d i h g f e d i h g f e d i h g f e d i h g f e d]
# 这个结果相信大家也都能看懂,也就是在某个数据的左边或者右边插入数据,before和after这个就不用多说了吧
1.8:Redis集合用法
Redis的set类型(集合)是string类型数值的无序集合,并且集合元素是唯一的。
# 函数解析
| 函数 |
功能 |
SAdd |
添加集合元素 |
SCard |
获取集合元素的个数 |
SIsMember |
判断元素是否在集合中 |
SMembers |
获取集合中所有的元素 |
SRem |
删除集合元素 |
SPop,SPopN |
随机返回集合中的元素,并且删除返回的元素 |
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.SAdd("users", "zhangsan", "lisi", "wangwu").Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("SAdd is success")
}
val, err := client.SMembers("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SMembers is success, val: %v\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\set\main.go
SAdd is success
SMembers is success, val: [wangwu lisi zhangsan]
# 从这里可以看出,我们在users集合里面添加了三个元素,然后并且去获取了三个元素,这个没什么我问题,如果我们放了重复的元素进去,那么它也不会再次写入到集合,而是必须唯一哦
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.SAdd("users", "zhangsan", "lisi", "wangwu").Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("SAdd is success")
}
val, err := client.SMembers("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SMembers is success, val: %v\n", val)
}
numbers, err := client.SCard("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SCard is success, numbers: %v\n", numbers)
}
}
PS D:\Codes\mmp> go run .\redis\set\
SAdd is success
SMembers is success, val: [wangwu lisi zhangsan]
SCard is success, numbers: 3
# 根据我们上面的解释,SCard就是获取我们集合内有多少个元素,和我们的期望也是一样的
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.SAdd("users", "zhangsan", "lisi", "wangwu").Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("SAdd is success")
}
val, err := client.SMembers("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SMembers is success, val: %v\n", val)
}
numbers, err := client.SCard("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SCard is success, numbers: %v\n", numbers)
}
data, err := client.SIsMember("users", "zhangsan").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SIsMember is success, data: %v\n", data)
}
}
PS D:\Codes\mmp> go run .\redis\set\
SAdd is success
SMembers is success, val: [wangwu lisi zhangsan]
SCard is success, numbers: 3
SIsMember is success, data: true
# 这也就不用多解释了,也就是从集合内查找一个元素,存在则返回true,不存在则返回false
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.SAdd("users", "zhangsan", "lisi", "wangwu").Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("SAdd is success")
}
// 删除某个元素
delErr := client.SRem("users", "zhangsan").Err()
if err != nil {
fmt.Println(delErr)
} else {
fmt.Println("SRem is success")
}
val, err := client.SMembers("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SMembers is success, val: %v\n", val)
}
numbers, err := client.SCard("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SCard is success, numbers: %v\n", numbers)
}
data, err := client.SIsMember("users", "zhangsan").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SIsMember is success, data: %v\n", data)
}
}
PS D:\Codes\mmp> go run .\redis\set\
SAdd is success
SRem is success
SMembers is success, val: [wangwu lisi]
SCard is success, numbers: 2
SIsMember is success, data: false
# 通过删除我们也验证了几个参数,就是删除了zhangsan之后同样的SIsMember没有找到这个元素了就返回了false,然后其他的也都有了响应的变化,这里SRem也是支持删除多个元素的
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.SAdd("users", "zhangsan", "lisi", "wangwu", "jialiu", "sunqi").Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("SAdd is success")
}
val, err := client.SPop("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SPop is success, val is %s\n", val)
}
vals, err := client.SMembers("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SMembers is success, vals is %v\n", vals)
}
}
PS D:\Codes\mmp> go run .\redis\set\
SAdd is success
SPop is success, val is jialiu
SMembers is success, vals is [wangwu zhangsan lisi sunqi]
PS D:\Codes\mmp> go run .\redis\set\main.go
SAdd is success
SPop is success, val is lisi
SMembers is success, vals is [wangwu zhangsan sunqi jialiu]
# 这个就比较暴力了,随机取出一个元素并删除它,那么它和SPopN的区别就是默认只能删除一个,但是SPopN它可以指定你删除几个元素
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.SAdd("users", "zhangsan", "lisi", "wangwu", "jialiu", "sunqi").Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("SAdd is success")
}
val, err := client.SPopN("users", 2).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SPop is success, val is %s\n", val)
}
vals, err := client.SMembers("users").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("SMembers is success, vals is %v\n", vals)
}
}
PS D:\Codes\mmp> go run .\redis\set\main.go
SAdd is success
SPop is success, val is [wangwu zhangsan]
SMembers is success, vals is [sunqi lisi jialiu]
PS D:\Codes\mmp> go run .\redis\set\main.go
SAdd is success
SPop is success, val is [sunqi jialiu]
SMembers is success, vals is [wangwu zhangsan lisi]
# 这里可以看到,我们删除的是2个,然后从集合内取出的有三个值
1.9:Redis有序集合用法
它和集合是一样的也是string类型元素的集合,且不允许有重复的元素,不同的是每个元素都会关联一个double类型的分数,这个分数主要用于集合元素排序,分数越高排序优先级就越低
# 函数解析
| 函数 |
功能 |
ZAdd |
添加一个或者多个元素,如果元素已存在,在则更新分数 |
ZCard |
返回集合元素的个数 |
ZCount |
统计某个分数范围内的元素个数 |
ZIncrBy |
增加某个元素的分数 |
ZRange,ZRevRange |
返回集合中某个索引范围的元素,根据分数从小到大排序 |
ZRangeByScore,ZRevRangeByScore |
根据分数范围返回集合元素,元素根据分数从小到大排序,支持分页 |
ZRem |
删除集合元素 |
ZRemRangeByRank |
根据索引范围删除元素 |
ZRemRangeByScore |
根据分数范围删除元素 |
ZScore |
查询元素对应的分数 |
ZRank,ZRevRank |
查询元素的排名 |
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{Score: 3, Member: "one"}, redis.Z{Score: 2, Member: "two"}, redis.Z{Score: 1, Member: "three"}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
val, err := client.ZRange("zset", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("zset的值为:%v\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset的值为:[three two one]
# 可以从代码看到,它的添加方法和其他的不一样,因为它可以添加多个member,但是多个member又是Z类型,所以我们会再嵌套一层,所以它的添加就是我们看到的这样了,分数越高,优先级越低
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{Score: 3, Member: "one"}, redis.Z{Score: 2, Member: "two"}, redis.Z{Score: 1, Member: "three"}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
val, err := client.ZRank("zset", "one").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("排名为:%v\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
排名为:2
# 根据上面的解释,我们这里就是获取一个元素的排名,它这个排名就是根据它的分数来进行排序,分数越高,排序越低
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{Score: 3, Member: "one"}, redis.Z{Score: 2, Member: "two"}, redis.Z{Score: 1, Member: "three"}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
val, err := client.ZCard("zset").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("zset集合元素的个数为:%d\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset集合元素的个数为:3
# 返回集合元素的个数,这个和前面的无序集合是一样的
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{
Score: 3,
Member: "one",
}, redis.Z{
Score: 2,
Member: "two",
}, redis.Z{
Score: 1,
Member: "three",
}, redis.Z{
Score: 2,
Member: "four",
}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
val, err := client.ZCount("zset", "2", "3").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset中score在2-3之间的元素个数为:", val)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset中score在2-3之间的元素个数为: 3
# 统计2-3分数之间的元素个数有多少个,这边从代码可以看出是3个,结果也符合我们的预期
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{
Score: 3,
Member: "one",
}, redis.Z{
Score: 2,
Member: "two",
}, redis.Z{
Score: 1,
Member: "three",
}, redis.Z{
Score: 2,
Member: "four",
}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
// 增加元素three的score值
val, err := client.ZIncr("zset", redis.Z{
Score: 1,
Member: "three",
}).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset中元素three的score值为:", val)
}
data, err := client.ZCount("zset", "2", "3").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset中score在2-3之间的元素个数为:", data)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset中元素three的score值为: 2
zset中score在2-3之间的元素个数为: 4
# 这个就是为指定的元素加分,我们可以看到,我们把three的1分加到了2分,当然,这里可以自己指定分数
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{
Score: 3,
Member: "one",
}, redis.Z{
Score: 2,
Member: "two",
}, redis.Z{
Score: 1,
Member: "three",
}, redis.Z{
Score: 2,
Member: "four",
}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
val, err := client.ZIncrBy("zset", 2, "three").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset中元素three的score值为:", val)
}
data, err := client.ZCount("zset", "2", "5").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset中score在2-3之间的元素个数为:", data)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset中元素three的score值为: 3
zset中score在2-3之间的元素个数为: 4
# ZIncrBy和ZIncr的区别就在于一个可以直接指定分数和元素,另一个需要指定这个Z类型才可以,不过两个都可以自定义分数的多少
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{
Score: 3,
Member: "one",
}, redis.Z{
Score: 2,
Member: "two",
}, redis.Z{
Score: 1,
Member: "three",
}, redis.Z{
Score: 2,
Member: "four",
}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
// 根据范围进行排序
op := redis.ZRangeBy{
Min: "1", // 最小分数
Max: "5", // 最大分数
Offset: 0, // 偏移量
Count: 3, // 每次返回的数量
}
val, err := client.ZRangeByScore("zset", op).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("zset排序结果:%v\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset排序结果:[three four two]
# 这里需要说明的是Count如果是-1,则说明返回所有
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{
Score: 3,
Member: "one",
}, redis.Z{
Score: 2,
Member: "two",
}, redis.Z{
Score: 1,
Member: "three",
}, redis.Z{
Score: 2,
Member: "four",
}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
val, err := client.ZRem("zset", "one", "two").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("zset删除成功,删除了%d个元素\n", val)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset删除成功,删除了2个元素
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{
Score: 3,
Member: "one",
}, redis.Z{
Score: 2,
Member: "two",
}, redis.Z{
Score: 1,
Member: "three",
}, redis.Z{
Score: 2,
Member: "four",
}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
val, err := client.ZRemRangeByScore("zset", "1", "2").Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset删除", val, "个元素")
}
vals, err := client.ZRange("zset", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset元素", vals)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset删除 3 个元素
zset元素 [one]
# 这个就是根据分数来删除数据,这里可以看到只有one是3分其他的全部符合删除条件,然后结果就是只剩one了
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
err := client.ZAdd("zset", redis.Z{
Score: 3,
Member: "one",
}, redis.Z{
Score: 2,
Member: "two",
}, redis.Z{
Score: 1,
Member: "three",
}, redis.Z{
Score: 2,
Member: "four",
}).Err()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("zset添加成功")
}
oldVal, err := client.ZRange("zset", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("zset原始值:%v\n", oldVal)
}
val, err := client.ZRemRangeByRank("zset", 1, 2).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("zset删除值:%v\n", val)
}
newVal, err := client.ZRange("zset", 0, -1).Result()
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("zset新值:%v\n", newVal)
}
}
PS D:\Codes\mmp> go run .\redis\sortedset\main.go
zset添加成功
zset原始值:[three four two one]
zset删除值:2
zset新值:[three one]
# 可以从这里看出,这是删除某个范围内的数据,我们这里是删除了下标为1到2的数据,然后保留的结果也是符合我们的需求的
1.10:Redis事务
Redis事务其实就是一组Redis的操作,并且带有两个重要的保证:
1:事务是一个单独的隔离操作,事务中的所有操作都会序列化,按顺序地执行,事务再执行过程中,不会被其他客户端发送来的指令请求所打断
2:事务是一个原子操作,事务中的操作要么全部执行,要么全部不执行
go-redis客户端常用的针对事务的函数:
1:TxPipeline:以Pipeline的方式操作事务
2:Watch:redis乐观锁支持
# 这里需要说明的是,Redis的事务和MySQL那些事务有些差别,Redis的事务只能确保需要执行的多个操作能够单线程,一起执行,但是执行多个操作中出现错误时,不会回滚,需要业务开发人员考虑如何处理失败的场景
package main
import (
"fmt"
"github.com/go-redis/redis"
"time"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379", // Redis地址
Password: "123456", // Redis链接密码
DB: 0, // Redis库,逻辑分区数,默认为0
WriteTimeout: 600 * time.Millisecond, // 写超时时间,这里是600毫秒
ReadTimeout: 300 * time.Millisecond, // 读超时时间,这里是300毫秒
DialTimeout: 3 * time.Minute, // 连接超时时间
PoolSize: 100, // 连接池大小
MinIdleConns: 3, // 最小空闲连接数
IdleTimeout: 1 * time.Minute, // 空闲连接超时时间
})
// 以Pipeline的方式操作事务
pipeline := client.TxPipeline()
pipeline.Get("pipeline_one")
pipeline.Set("pipeline_two", "one", 0)
_, err := pipeline.Exec()
if err != nil {
fmt.Println("Pipeline Exec failed, err:", err)
}
val, err := client.Get("pipeline_two").Result()
if err != nil {
fmt.Println("Get pipeline_two failed, err:", err)
} else {
fmt.Println("Get pipeline_two success, val:", val)
}
}
PS D:\Codes\mmp> go run .\redis\work\main.go
Pipeline Exec failed, err: redis: nil
Get pipeline_two success, val: one
# 从这里我们可以清楚的看出,事务内虽然有报错,但是我们后面去查pipeline_two的时候还是查到了数据,也就意味着,即使有报错也不影响事务的运行
1.11:Redis断点续查案例
断点续查是指在查询大量数据时,可以设置一个断点,记录已经获取的数据位置,以便下次继续查询,以下是一种基于断点续查的一般方法
1:定义断点键(Checkpoint Key) :可以在Redis中设置一个键,用于存储断点位置,这个键可以是一个唯一标识,用来跟踪断点的位置
2:设置初始断点位置:在执行查询或处理操作之前,将初始断点位置存储在Redis中的断点键中,初始断点位置通常为0或某个合适的起始位置
3:分页查询或处理:按照分页的方式执行查询或处理操作,每次处理一个固定大小的数据块
4:更新断点位置:在处理完每个数据块后,将当前断点位置存储回Redis的断点键中,以便下次继续从断点位置开始
5:循环处理:重复执行分页查询处理的过程,直到处理完所有数据或达到终止条件
package main
import (
"context"
"fmt"
"github.com/go-redis/redis"
"time"
)
func RedisClient() (*redis.Client, error) {
return redis.NewClient(&redis.Options{
Addr: "10.0.0.13:6379",
Password: "123456",
DB: 0,
WriteTimeout: 600 * time.Millisecond,
ReadTimeout: 300 * time.Millisecond,
DialTimeout: 3 * time.Minute,
PoolSize: 100,
MinIdleConns: 3,
IdleTimeout: 1 * time.Minute,
}), nil
}
func main() {
client, err := RedisClient()
if err != nil {
fmt.Println(err)
}
// 生成List数据
client.LPush("list", "a", "b", "c", "d", "e", "f", "g")
// 定义分页以及断点的key
ctx := context.Background()
checkpointKey := "checkpoint"
pageSize := 3
stopProcessing := false
client.Set(checkpointKey, 1, 0)
// 获取上一次断点的位置
page, err := client.Get(checkpointKey).Int()
if err != nil {
return
}
// for循环获取发起分页请求
for !stopProcessing {
// 查询数据,从断点位置开始
data, err := QueryDataFromRedis(ctx, client, int64(page), int64(pageSize))
if err != nil {
fmt.Printf("QueryDataFromRedis err: %v\n", err)
return
}
// 处理数据
fmt.Println(data)
// 更新断点位置
page++
err = client.Set(checkpointKey, page, 0).Err()
if err != nil {
fmt.Printf("client.Set err: %v\n", err)
return
}
// 检查谁否达到终止条件
if len(data) < pageSize {
stopProcessing = true
}
}
fmt.Println("查询数据成功")
}
// QueryDataFromRedis 从Redis中查询分页数据
func QueryDataFromRedis(ctx context.Context, client *redis.Client, page, pageSize int64) ([]string, error) {
start := (page - 1) * pageSize
end := page*pageSize - 1
val, err := client.LRange("list", start, end).Result()
if err != nil {
return nil, err
}
return val, nil
}
PS D:\Codes\mmp\redis\demo> go run .\main.go
[g f e]
[d c b]
[a]
查询数据成功
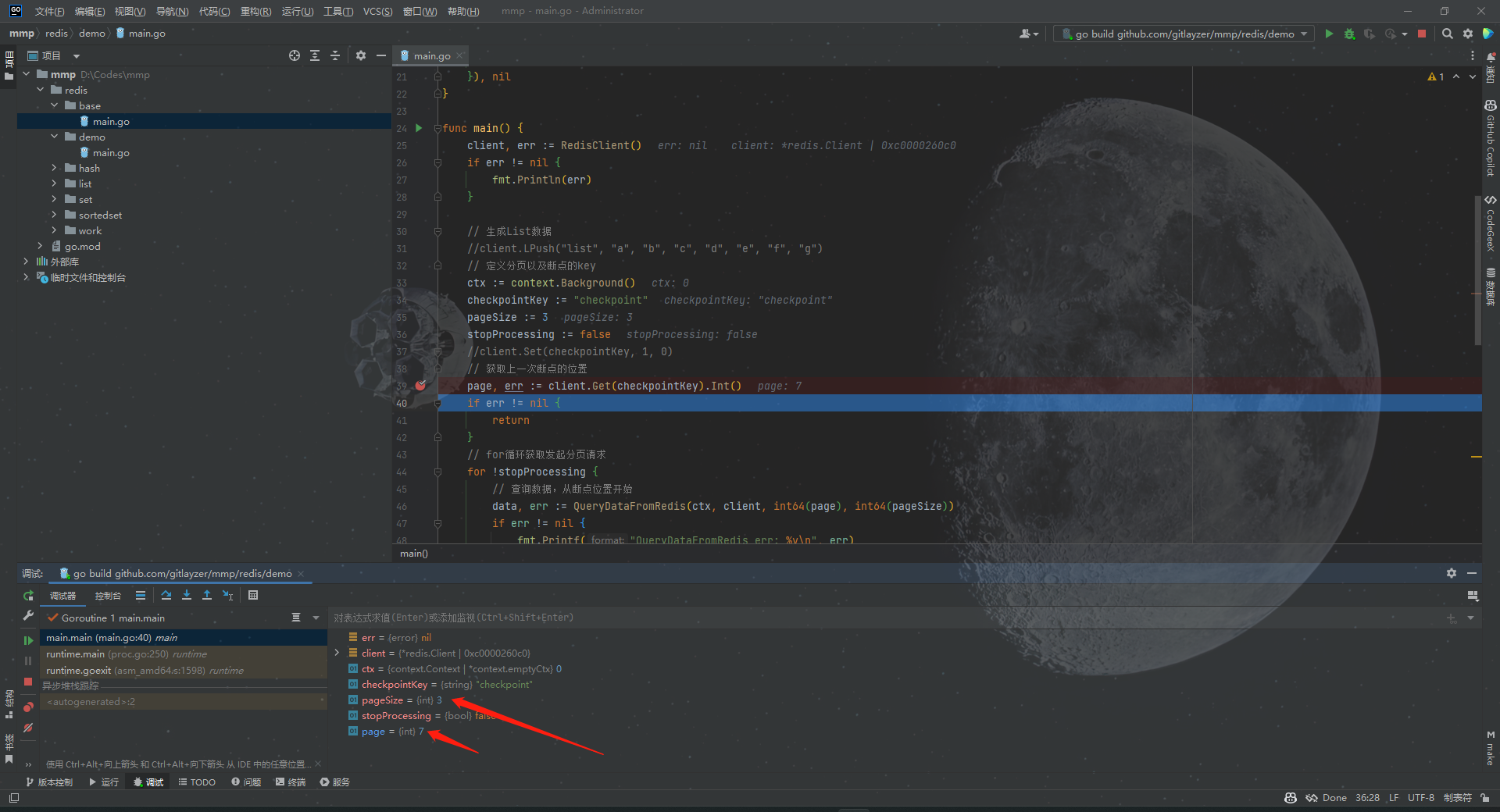
从DeBug的情况来看,我们的确是做到了断点续查,只不过这里我前面Debug了三次,所以这里就累加成了7,否则应该是4的,那么这里就是我们从哪儿断开的,就会从哪儿开始查,这就是一个断点续查的案例
2:ElasticSearch的认识与使用
2.1:ElasticSearch介绍
ElasticSearch是一个开源的分布式搜索和分析引擎,构建在Apache Lucene基础之上,它提供了强大的全文搜索,结构化查询,分析能力和实时数据分析能力,被广泛应用于各种领域,包括企业搜索,日志分析,产品搜索,监控数据分析等
以下是ElasticSearch的一些主要特点和功能:
1:分布式和高可用性:ElasticSearch是一个分布式的搜索引擎,它可以在多个节点上存储和处理数据,具备高可用性和容错性,数据可以分片和复制到多个节点,从而实现数据的水平扩展和故障恢复
2:实时搜索和分析:ElasticSearch提供了实时搜索和分析功能,可以在大规模数据集上快速进行搜索,聚合和分析,它支持全文搜索,近实时的数据索引和搜索,以及复杂的查询和聚合操作
3:多样化的查询和聚合:ElasticSearch提供了丰富的查询语言和灵活的聚合功能,使用户可以进行复杂的数据检索和分许,您可以使用诸如匹配查询,范围查询,过滤器,聚合等查询和分析操作来探索数据集
4:多种数据类型支持:ElasticSearch支持多种数据类型,包括文本,数值,日期,地理位置等,它具有强大的全文搜索功能,可以处理各种语言和文本分析需求
5:高性能和可扩展性:ElasticSearch基于Apache Lucene引擎,具有高性能的搜索和索引功能,它可以水平扩展,通过增加节点来处理大规模数据和高并发请求
6:集成和生态系统:ElasticSearch提供了丰富的API和工具,方便与其他系统进行集成,它与Logstash,Kibana,Beats等工具集成,形成了ELK Stack(现称为 Elastic Stack),用于日志分析和实时数据处理
7:安全性和权限控制:ElasticSearch提供了访问控制,身份验证和权限管理等安全功能,以保护数据的机密性和完整性
2.2:ElasticSearch常用场景
1:搜索引擎:ElasticSearch提供了高效的全文搜索和实时搜索功能,使其成为构建搜索引擎和相关应用的理想选择,它可以轻松的处理大规模的文本数据,并提供强大的搜索,过滤,排序和高亮显示等功能
2:日志和事件分析:ElasticSearch被广泛用于实时日志和事件数据分析,它可以接收,索引和存储大量的日志数据,并提供快速的搜索和聚合能力,使我们能够以实时方式分析日志数据并提取有用的见解
3:监控和指标分析:ElasticSearch可以用作实时监控和指标数据的存储和分析引擎,它可以接收和处理大量的指标数据,并提供灵活的聚合和可视化功能,以帮助监控系统性能,应用程序指标和基础设施指标
4:商业智能和数据分析:ElasticSearch与Kibana结合使用,可以构建强大的商业智能和数据分析平台,它可以处理和分析结构化和非结构化数据,提供高级的数据聚合,过滤和可视化功能,使用户能发现数据中的模式和洞察,并进行深入的数据分析
5:实时推荐系统:ElasticSearch的实时性能和搜索功能使其成为实时推荐系统的理想选择,它可以接收实时事件数据,并通过实时搜索和聚合来生成个性化的推荐结果,提供更好的用户体验和个性化推荐服务
6:地理空间分析:ElasticSearch具有强大的地理空间搜索和分析功能,可以处理和分析地理位置相关的数据,它支持地理坐标索引,距离计算,地理范围查询等功能,使其适用于地理空间数据分析和地理信息系统(GIS)应用
2.3:ElasticSearch第三方库
1:github.com/olivere/elastic/v7:是一个用于ElasticSearch进行交互的Go客户端库,它提供了方便的API,使我们能够索引,检索,更新和删除ElasticSearch中的文档,以及执行聚合和搜索操作
2:Github链接:http://github.com/olivere/elastic
# 同样的,我们一样用Docker启动一个ElasticSearch
# 下载Go的依赖包
PS D:\Codes\mmp\redis\demo> go get -u "github.com/olivere/elastic/v7"
2.4:ElasticSearch的使用
package main
import (
"fmt"
"github.com/olivere/elastic/v7"
)
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 使用客户端获取es的版本号
esVersion, err := client.ElasticsearchVersion("http://10.0.0.13:9200")
if err != nil {
fmt.Printf("get es version error: %v\n", err)
} else {
fmt.Printf("es version: %v\n", esVersion)
}
}
PS D:\Codes\mmp\elasticsearch\index> go run .\main.go
es version: 7.17.11
# 根据上面的代码,我们拿到了ES的版本,证明客户端是没有什么问题的
2.5:ElasticSearch初始化参数详解
1:elastic.SetURL:用来设置ES的服务地址,如果是本地,就是127.0.0.1:9200,支持设置多个地址,用逗号分开即可
2:elastic.SetBasicAuth:这个是基于http basic auth验证机制的账号密码认证
3:elastic.SetGzip:启动Gzip压缩
4:elasitc.SetHealthcheckInterval:用来设置监控检查时间间隔
5:elasitc.SetMaxRetries:设置请求失败最大重试次数,v7版本以后已被弃用
6:elasitc.SetSniff:允许指定弹性是否应该定期检查集群(默认为true)
7:elastic.SetErrirLog:设置错误日志输出
8:elasitc.SetInforLog:设置info日志输出
2.6:ElasticSearch索引的CRUD
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
var (
indexName = "index"
mapping = `{
"mappings": {
"dynamic": "strict",
"properties": {
"id": {
"type": "long"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text"
},
"phone": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"ancestral": {
"type": "text"
},
"identity": {
"type": "text"
},
"update_time": {
"type": "long"
},
"create_time": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}`
)
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 创建索引
val, err := client.CreateIndex(indexName).BodyString(mapping).Do(context.Background())
if err != nil {
fmt.Printf("create index error: %v\n", err)
} else {
fmt.Printf("create index success: %v\n", val)
}
}
PS D:\Codes\mmp\elasticsearch\index> go run .\main.go
create index success: &{true true index}
# 可以看到这边我们将一个索引的mapping创建出来了,并且返回了索引名称和创建的状态,我们可以通过API查询我们的索引,可以直接请求http://url:9200/<index_name>
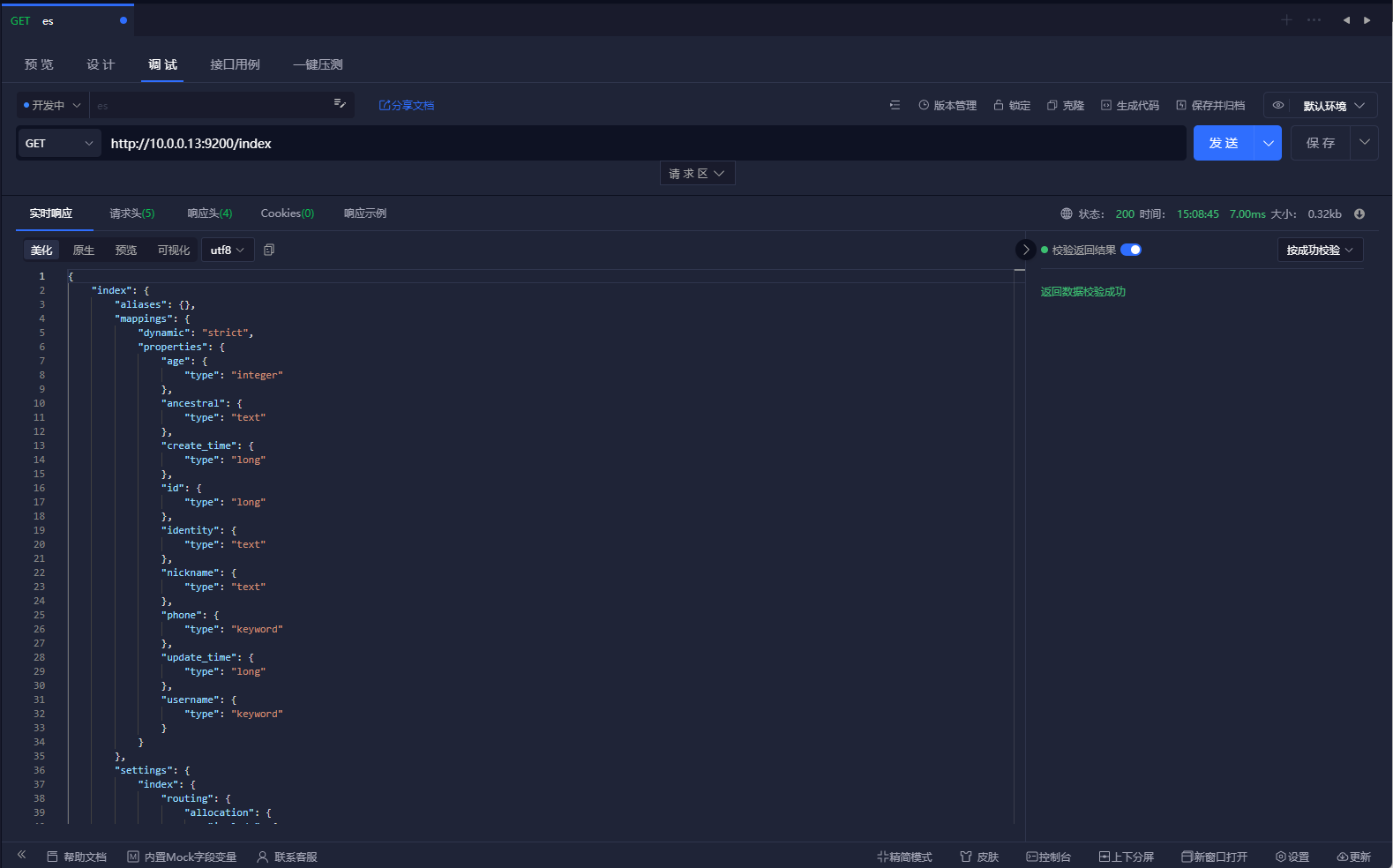
# 类似于查询表结构
[root@localhost ~]# curl 127.0.0.1:9200/index
{"index":{"aliases":{},"mappings":{"dynamic":"strict","properties":{"age":{"type":"integer"},"ancestral":{"type":"text"},"create_time":{"type":"long"},"id":{"type":"long"},"identity":{"type":"text"},"nickname":{"type":"text"},"phone":{"type":"keyword"},"update_time":{"type":"long"},"username":{"type":"keyword"}}},"settings":{"index":{"routing":{"allocation":{"include":{"_tier_preference":"data_content"}}},"number_of_shards":"1","provided_name":"index","creation_date":"1689750262291","number_of_replicas":"0","uuid":"0IzCbqwlThaw6JaocOfcXA","version":{"created":"7171199"}}}}}
# 另一种查询方法(通过search查询具体的数据)
[root@localhost ~]# curl 127.0.0.1:9200/index/_search
{"took":3,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":0,"relation":"eq"},"max_score":null,"hits":[]}}
# 查询不存在的索引
[root@localhost ~]# curl 127.0.0.1:9200/index2
{"error":{"root_cause":[{"type":"index_not_found_exception","reason":"no such index [index2]","resource.type":"index_or_alias","resource.id":"index2","index_uuid":"_na_","index":"index2"}],"type":"index_not_found_exception","reason":"no such index [index2]","resource.type":"index_or_alias","resource.id":"index2","index_uuid":"_na_","index":"index2"},"status":404}
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
var (
indexName = "index"
mapping = `{
"mappings": {
"dynamic": "strict",
"properties": {
"id": {
"type": "long"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text"
},
"phone": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"ancestral": {
"type": "text"
},
"identity": {
"type": "text"
},
"update_time": {
"type": "long"
},
"create_time": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}`
)
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 删除索引
val, err := client.DeleteIndex(indexName).Do(context.Background())
if err != nil {
fmt.Printf("delete index error: %v\n", err)
} else {
fmt.Printf("delete index success: %v\n", val)
}
}
PS D:\Codes\mmp\elasticsearch\index> go run .\main.go
delete index success: &{true}
# 可以看到删除索引成功,并且返回了删除的状态
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
var (
sourceName = "source_index"
targetName = "target_index"
mapping = `{
"mappings": {
"dynamic": "strict",
"properties": {
"id": {
"type": "long"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text"
},
"phone": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"ancestral": {
"type": "text"
},
"identity": {
"type": "text"
},
"update_time": {
"type": "long"
},
"create_time": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}`
)
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 创建索引
//val, err := client.CreateIndex(sourceName).BodyString(mapping).Do(context.Background())
//if err != nil {
// fmt.Printf("create index error: %v\n", err)
//} else {
// fmt.Printf("create index success: %v\n", val)
//}
// 删除索引
//val, err := client.DeleteIndex(indexName).Do(context.Background())
//if err != nil {
// fmt.Printf("delete index error: %v\n", err)
//} else {
// fmt.Printf("delete index success: %v\n", val)
//}
// 迁移索引
_, err = client.Reindex().SourceIndex(sourceName).DestinationIndex(targetName).Do(context.Background())
if err != nil {
fmt.Printf("reindex error: %v\n", err)
} else {
fmt.Printf("reindex success: %v\n", targetName)
}
}
PS D:\Codes\mmp\elasticsearch\index> go run .\main.go
reindex success: target_index
# 这里我先创建了索引,然后将source_index迁移到了target_index索引内,这个时候我们可以去查以下target_index,这边迁移数据其实就是基于新的老的index迁移到新的index的时候可以增加字段,这个我们可以自己去尝试一下,它也就对应了我们这里的改的操作
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
var (
sourceName = "source_index"
targetName = "target_index"
mapping = `{
"mappings": {
"dynamic": "strict",
"properties": {
"id": {
"type": "long"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text"
},
"phone": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"ancestral": {
"type": "text"
},
"identity": {
"type": "text"
},
"update_time": {
"type": "long"
},
"create_time": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}`
)
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 查询索引
val, err := client.Search().Index(sourceName).Query(elastic.NewMatchAllQuery()).Do(context.Background())
if err != nil {
fmt.Printf("search index error: %v\n", err)
} else {
fmt.Printf("search index success: %v\n", val)
}
}
PS D:\Codes\mmp\elasticsearch\index> go run .\main.go
search index success: &{map[Content-Type:[application/json; charset=UTF-8] X-Elastic-Product:[Elasticsearch]] 0 false 0 <nil> 0xc0000ee570 map[] map[] false <nil> <nil> 0xc00005c780 0 }
# 从这里可以看出,查询到了索引,它是一个map,然后查询到这个索引之后我们就可以去查询索引下的文件了
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
var (
sourceName = "source_index"
targetName = "target_index"
mapping = `{
"mappings": {
"dynamic": "strict",
"properties": {
"id": {
"type": "long"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text"
},
"phone": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"ancestral": {
"type": "text"
},
"identity": {
"type": "text"
},
"update_time": {
"type": "long"
},
"create_time": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}`
)
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 查询索引
val, err := client.Search().Index(sourceName).Query(elastic.NewMatchAllQuery()).Do(context.Background())
if err != nil {
fmt.Printf("search index error: %v\n", err)
} else {
fmt.Printf("search index success: %v\n", val)
}
// 查询索引下的文件
if val.Hits.TotalHits.Value > 0 {
for _, hit := range val.Hits.Hits {
fmt.Printf("id: %v\n", hit.Id)
fmt.Printf("index: %v\n", hit.Index)
fmt.Printf("source: %v\n", hit.Source)
}
} else {
fmt.Printf("no data\n")
}
}
PS D:\Codes\mmp\elasticsearch\index> go run .\main.go
search index success: &{map[Content-Type:[application/json; charset=UTF-8] X-Elastic-Product:[Elasticsearch]] 0 false 0 <nil> 0xc00008d080 map[] map[] false <nil> <nil> 0xc0000a64c0 0 }
no data
# 因为现在没有向索引内写文件,所以它没有数据,等下我们操作一下它之后返回查询就有了
2.7:ElasticSearch文档的CRUD
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称,前提是索引存在
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 创建文档
doc := Document{
ID: 1,
Username: "gitlayzer",
Nickname: "gitlayzer",
Phone: "12345678901",
Age: 18,
Ancestral: "中国",
Identity: "程序员",
}
val, err := client.Index().Index(indexName).BodyJson(doc).OpType("create").BodyJson(doc).Do(context.Background())
if err != nil {
fmt.Printf("create doc error: %v\n", err)
} else {
fmt.Printf("create doc success: %v\n", val.Id)
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
create doc success: wFysbokBnumd1Y5RhIWW
# 可以看到,这边我们拿到了一个文档的ID,那么我们去查一下这个文档
[root@localhost ~]# curl 127.0.0.1:9200/index/_search
{"took":624,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"index","_type":"_doc","_id":"wFysbokBnumd1Y5RhIWW","_score":1.0,"_source":{"id":1,"username":"gitlayzer","nickname":"gitlayzer","phone":"12345678901","age":18,"ancestral":"中国","identity":"程序员"}}]}}
# 可以看到我们的文档了,这就是创建文档的一个操作,那么前面我们还有一个查询文档的方法,我们来试试
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 查询索引
val, err := client.Search().Index(indexName).Query(elastic.NewMatchAllQuery()).Do(context.Background())
if err != nil {
fmt.Printf("search index error: %v\n", err)
} else {
fmt.Println("search index success")
}
// 查询索引下的文档
if val.Hits.TotalHits.Value > 0 {
for _, hit := range val.Hits.Hits {
fmt.Printf("id: %v\n", hit.Id)
fmt.Printf("index: %v\n", hit.Index)
}
} else {
fmt.Printf("no data\n")
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
search index success
id: wFysbokBnumd1Y5RhIWW
index: index
# 可以看到这里面我们列出了文档的ID和索引的名称
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
var (
indexName = "index"
backup_indexName = "index_backup"
mapping = `{
"mappings": {
"dynamic": "strict",
"properties": {
"id": {
"type": "long"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text"
},
"phone": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"ancestral": {
"type": "text"
},
"identity": {
"type": "text"
},
"update_time": {
"type": "long"
},
"create_time": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}`
)
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 创建索引
val, err := client.CreateIndex(backup_indexName).BodyString(mapping).Do(context.Background())
if err != nil {
fmt.Printf("create index error: %v\n", err)
} else {
fmt.Printf("create index success: %v\n", val)
}
// 迁移index到backup_index
resp, err := client.Reindex().SourceIndex(indexName).DestinationIndex(backup_indexName).Do(context.Background())
if err != nil {
fmt.Printf("reindex error: %v\n", err)
} else {
fmt.Printf("reindex success: %v\n", resp)
}
}
PS D:\Codes\mmp\elasticsearch\document> go run ..\index\main.go
create index success: &{true true index_backup}
reindex success: &{map[Content-Type:[application/json; charset=UTF-8] X-Elastic-Product:[Elasticsearch]] 24 <nil> false 1 0 1 0 1 0 0 {0 0} 0 -1 0 []}
# 迁移文档,这边是把index内的文档迁移到index_backup的索引中了,然后我们来查看一下
[root@localhost ~]# curl 127.0.0.1:9200/index/_search
{"took":1,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"index","_type":"_doc","_id":"wFysbokBnumd1Y5RhIWW","_score":1.0,"_source":{"id":1,"username":"gitlayzer","nickname":"gitlayzer","phone":"12345678901","age":18,"ancestral":"中国","identity":"程序员"}}]}}
[root@localhost ~]# curl 127.0.0.1:9200/index_backup/_search
{"took":1,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"index_backup","_type":"_doc","_id":"wFysbokBnumd1Y5RhIWW","_score":1.0,"_source":{"id":1,"username":"gitlayzer","nickname":"gitlayzer","phone":"12345678901","age":18,"ancestral":"中国","identity":"程序员"}}]}}
# 可以看到,俩数据长得那是一模一样,这就代表着文档迁移成功了,但是我们要知道的是,迁移前要迁移的目标是索引是必须存在的,否则是不会迁移成功的,我们在创建新的索引的时候就可以添加新的字段然后将老的索引数据迁移到这个索引内,但是我们可以看出来,我们这里是创建一个文档,下面我们要看的是如何创建多个文档
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 创建文档
dosc := []*Document{
{
ID: 2,
Username: "zhangsan",
Nickname: "zhangsan",
Phone: "18888888888",
Age: 30,
Ancestral: "中国",
Identity: "主管",
},
{
ID: 3,
Username: "lisi",
Nickname: "lisi",
Phone: "19999999999",
Age: 36,
Ancestral: "中国",
Identity: "经理",
},
}
// 批量创建文档
bulk := client.Bulk().Index(indexName)
for _, doc := range dosc {
bulk.Add(elastic.NewBulkIndexRequest().Doc(doc))
}
bulkResp, err := bulk.Do(context.Background())
if err != nil {
fmt.Printf("bulk create error: %v\n", err)
} else {
fmt.Printf("bulk create success: %v\n", bulkResp)
}
val, err := client.Search().Index(indexName).Query(elastic.NewMatchAllQuery()).Do(context.Background())
if err != nil {
fmt.Printf("search index error: %v\n", err)
} else {
fmt.Println("search index success")
}
// 查询索引下的文件
if val.Hits.TotalHits.Value > 0 {
for _, hit := range val.Hits.Hits {
fmt.Printf("id: %v\n", hit.Id)
fmt.Printf("index: %v\n", hit.Index)
}
} else {
fmt.Printf("no data\n")
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
bulk create success: &{5 false [map[index:0xc0000d4000] map[index:0xc0000d4080]]}
search index success
id: wFysbokBnumd1Y5RhIWW
index: index
# 这边貌似并没有查询到更多的资源,但是文档的确是创建出来了
[root@localhost ~]# curl 127.0.0.1:9200/index/_search
{"took":3,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":3,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"index","_type":"_doc","_id":"wFysbokBnumd1Y5RhIWW","_score":1.0,"_source":{"id":1,"username":"gitlayzer","nickname":"gitlayzer","phone":"12345678901","age":18,"ancestral":"中国","identity":"程序员"}},{"_index":"index","_type":"_doc","_id":"wVxscYkBnumd1Y5RToV7","_score":1.0,"_source":{"id":2,"username":"zhangsan","nickname":"zhangsan","phone":"18888888888","age":30,"ancestral":"中国","identity":"主管"}},{"_index":"index","_type":"_doc","_id":"wlxscYkBnumd1Y5RToV7","_score":1.0,"_source":{"id":3,"username":"lisi","nickname":"lisi","phone":"19999999999","age":36,"ancestral":"中国","identity":"经理"}}]}}
# 可以看到数据都已经创建了,其实我们这里是比较推荐批量创建的,文档创建完了,那么我们下面就考虑的是针对文档的操作了
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 根据文档id查询(此id并非是我们定义的那个id,而是自动生成ID)
result, err := client.Get().Index(indexName).Id("wFysbokBnumd1Y5RhIWW").Do(context.Background())
if err != nil {
fmt.Printf("get index error: %v\n", err)
} else {
fmt.Printf("get index success: %v\n", string(result.Source))
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
get index success: {"id":1,"username":"gitlayzer","nickname":"gitlayzer","phone":"12345678901","age":18,"ancestral":"中国","identity":"程序员"}
# 可以看到,查询到了这个ID的数据,这是我们第一次写进去的数据,不过我们这里还是单个ID查询,我偶们一般也会使用批量ID查询来替代这个单个ID查询的方法
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 批量ID查询文档
ids := []string{"wVxscYkBnumd1Y5RToV7", "wlxscYkBnumd1Y5RToV7"}
// 批量查询
mget := client.MultiGet()
for _, id := range ids {
mget.Add(elastic.NewMultiGetItem().Index(indexName).Id(id))
}
mgetResp, err := mget.Do(context.Background())
if err != nil {
fmt.Printf("mget error: %v\n", err)
} else {
for _, doc := range mgetResp.Docs {
if doc.Found {
fmt.Printf("doc: %v\n", string(doc.Source))
} else {
fmt.Printf("doc not found\n")
}
}
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
doc: {"id":2,"username":"zhangsan","nickname":"zhangsan","phone":"18888888888","age":30,"ancestral":"中国","identity":"主管"}
doc: {"id":3,"username":"lisi","nickname":"lisi","phone":"19999999999","age":36,"ancestral":"中国","identity":"经理"}
# 那么这个就是我们批量查询出来的结果,其实也就就是循环的多个id去查询的,我们利用单个查询去循环多个ID其实效果基本一样的
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 定义精确查询规则
terms := elastic.NewTermsQuery("username", "zhangsan", "lisi")
// 将规则传入查询
result, err := client.Search().Index(indexName).Query(terms).From(0).Size(10).Do(context.Background())
if err != nil {
fmt.Printf("search error: %v\n", err)
} else {
for _, hit := range result.Hits.Hits {
fmt.Printf("hit: %v\n", string(hit.Source))
}
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
hit: {"id":2,"username":"zhangsan","nickname":"zhangsan","phone":"18888888888","age":30,"ancestral":"中国","identity":"主管"}
hit: {"id":3,"username":"lisi","nickname":"lisi","phone":"19999999999","age":36,"ancestral":"中国","identity":"经理"}
# 这里就是我们精确查询出来的结果了
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 使用年龄区间查询
rangeQuery := elastic.NewRangeQuery("age").Gte(20).Lte(40)
val, err := client.Search().Index(indexName).Query(rangeQuery).Do(context.Background())
if err != nil {
fmt.Printf("search error: %v\n", err)
} else {
for _, hit := range val.Hits.Hits {
fmt.Printf("id: %s, source: %s\n", hit.Id, hit.Source)
}
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
id: wVxscYkBnumd1Y5RToV7, source: {"id":2,"username":"zhangsan","nickname":"zhangsan","phone":"18888888888","age":30,"ancestral":"中国","identity":"主管"}
id: wlxscYkBnumd1Y5RToV7, source: {"id":3,"username":"lisi","nickname":"lisi","phone":"19999999999","age":36,"ancestral":"中国","identity":"经理"}
# 可以看到这边过滤出来的就是大于等于20,小于等于40区间的年龄的数据,这边符合的只有两条,我们也列出来了
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 组合查询,使用名字和年龄一起查询
boolQuery := elastic.NewBoolQuery()
termQuery := elastic.NewTermsQuery("username", "zhangsan", "lisi")
rangeQuery := elastic.NewRangeQuery("age").Gte(18).Lte(30)
boolQuery.Must(termQuery, rangeQuery)
val, err := client.Search(indexName).Query(boolQuery).From(0).Size(10).Do(context.Background())
if err != nil {
fmt.Printf("query error: %v\n", err)
} else {
for _, doc := range val.Hits.Hits {
fmt.Printf("doc: %v\n", string(doc.Source))
}
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
doc: {"id":2,"username":"zhangsan","nickname":"zhangsan","phone":"18888888888","age":30,"ancestral":"中国","identity":"主管"}
# 可以看到这边符合条件的只有一个,因为lisi的age是不符合条件的,所以是查询不到的,查询讲的差不多了,我们下面来看看删除
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 列出删除前的数据(这里我基本上是列出了全部)
rangeQuery := elastic.NewRangeQuery("age").Gte(1).Lte(50)
oldData, err := client.Search().Index(indexName).Query(rangeQuery).Do(context.Background())
if err != nil {
fmt.Printf("search error: %v\n", err)
} else {
for _, hit := range oldData.Hits.Hits {
fmt.Printf("id: %s, source: %s\n", hit.Id, hit.Source)
}
}
// 删除ID为wFysbokBnumd1Y5RhIWW的数据,这里的ID指的是ES自动生成的ID
val, err := client.Delete().Id("wFysbokBnumd1Y5RhIWW").Refresh("true").Index(indexName).Do(context.Background())
if err != nil {
fmt.Printf("delete error: %v\n", err)
} else {
fmt.Printf("delete success: %v\n", val)
}
// 查看删除后的所有数据
newData, err := client.Search().Index(indexName).Query(rangeQuery).Do(context.Background())
if err != nil {
fmt.Printf("search error: %v\n", err)
} else {
for _, hit := range newData.Hits.Hits {
fmt.Printf("id: %s, source: %s\n", hit.Id, hit.Source)
}
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
id: wFysbokBnumd1Y5RhIWW, source: {"id":1,"username":"gitlayzer","nickname":"gitlayzer","phone":"12345678901","age":18,"ancestral":"中国","identity":"程序员"}
id: wVxscYkBnumd1Y5RToV7, source: {"id":2,"username":"zhangsan","nickname":"zhangsan","phone":"18888888888","age":30,"ancestral":"中国","identity":"主管"}
id: wlxscYkBnumd1Y5RToV7, source: {"id":3,"username":"lisi","nickname":"lisi","phone":"19999999999","age":36,"ancestral":"中国","identity":"经理"}
delete success: &{index _doc wFysbokBnumd1Y5RhIWW 2 deleted 0xc0001b0140 3 1 0 true}
id: wVxscYkBnumd1Y5RToV7, source: {"id":2,"username":"zhangsan","nickname":"zhangsan","phone":"18888888888","age":30,"ancestral":"中国","identity":"主管"}
id: wlxscYkBnumd1Y5RToV7, source: {"id":3,"username":"lisi","nickname":"lisi","phone":"19999999999","age":36,"ancestral":"中国","identity":"经理"}
# 可以看到这里我们根据ID删除了指定的一条数据,当然它也是支持批量删除的,不过它的逻辑和批量创建是一样的,我们直接把批量创建拿过来然后改一下就可以成为批量删除了
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
doc := Document{
ID: 2,
Username: "zhangsan",
Nickname: "zhangsan",
Phone: "18888888888",
Age: 32,
Ancestral: "中国",
Identity: "项目经理",
}
// 更新文档
val, err := client.Update().Index(indexName).Id("wVxscYkBnumd1Y5RToV7").Doc(doc).Refresh("true").Do(context.Background())
if err != nil {
fmt.Printf("update doc error: %v\n", err)
} else {
fmt.Printf("update doc success: %v\n", val)
}
// 查看文档
result, err := client.Get().Index(indexName).Id("wVxscYkBnumd1Y5RToV7").Do(context.Background())
if err != nil {
fmt.Printf("get index error: %v\n", err)
} else {
fmt.Printf("get index success: %v\n", string(result.Source))
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
update doc success: &{index _doc wVxscYkBnumd1Y5RToV7 2 updated 0xc0000c2240 4 1 0 true <nil>}
get index success: {"id":2,"username":"zhangsan","nickname":"zhangsan","phone":"18888888888","age":32,"ancestral":"中国","identity":"项目经理"}
# 可以看到,这和我们前面的数据有一些变化了,比如age和identity都如我我们所想的的变化更改了,其次就是我们还有一个根据条件做修改的操作
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// 声明索引名称
var (
indexName = "index"
)
// Document 声明文档结构体
type Document struct {
ID int64 `json:"id"`
Username string `json:"username"`
Nickname string `json:"nickname"`
Phone string `json:"phone"`
Age int `json:"age"`
Ancestral string `json:"ancestral"`
Identity string `json:"identity"`
}
func main() {
// 初始化客户端
client, err := elastic.NewClient(elastic.SetURL("http://10.0.0.13:9200"), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 修改username叫zhangsan,并且年龄在30-40之间的age为33
query := elastic.NewBoolQuery()
query.Filter(elastic.NewTermQuery("username", "zhangsan"))
query.Filter(elastic.NewRangeQuery("age").Gte(30).Lte(40))
script := elastic.NewScriptInline("ctx._source.age = params.age").Param("age", 33)
val, err := client.UpdateByQuery(indexName).Query(query).Script(script).Refresh("true").Do(context.Background())
if err != nil {
fmt.Printf("update by query error: %v\n", err)
} else {
fmt.Printf("update by query result: %v\n", val)
}
// 再次循环查询数据
rangeQuery := elastic.NewRangeQuery("age").Gte(1).Lte(50)
oldData, err := client.Search().Index(indexName).Query(rangeQuery).Do(context.Background())
if err != nil {
fmt.Printf("search error: %v\n", err)
} else {
for _, hit := range oldData.Hits.Hits {
fmt.Printf("id: %s, source: %s\n", hit.Id, hit.Source)
}
}
}
PS D:\Codes\mmp\elasticsearch\document> go run .\main.go
update by query result: &{map[] 65 <nil> false 1 1 0 0 1 0 0 {0 0} 0 -1 0 []}
id: wlxscYkBnumd1Y5RToV7, source: {"id":3,"username":"lisi","nickname":"lisi","phone":"19999999999","age":36,"ancestral":"中国","identity":"经理"}
id: wVxscYkBnumd1Y5RToV7, source: {"ancestral":"中国","phone":"18888888888","identity":"项目经理","nickname":"zhangsan","id":2,"age":33,"username":"zhangsan"}
# 可以看到,这里的张三的数据就已经修改完成了,看到age是33的zhangsan,也就是符合我们的需求的结果了
2.8:ElasticSearch案例日志分析
package main
import (
"bufio"
"context"
"fmt"
"github.com/olivere/elastic/v7"
"os"
"strconv"
"strings"
"time"
)
const (
indexName = "nginx_logs"
dateFormat = "02/Jan/2006:15:04:05"
)
var (
ElasticsearchURL = "http://10.0.0.13:9200"
File = "access.log"
)
// 写入日志到ES
type AccessLog struct {
Timestamp time.Time `json:"timestamp"`
IP string `json:"ip"`
Method string `json:"method"`
Url string `json:"url"`
StatusCode int `json:"status_code"`
ResponseTime int `json:"response_time"`
UserAgent string `json:"user_agent"`
}
func main() {
// 创建es客户端
client, err := elastic.NewClient(elastic.SetURL(ElasticsearchURL), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
// 读取access.log文件
file, err := os.Open(File)
if err != nil {
fmt.Printf("open file error: %v\n", err.Error())
}
defer file.Close()
// 逐行读取日志
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := scanner.Text()
// ParseAccessLog 解析日志
accesslog := ParseAccessLog(line)
if accesslog != nil {
// IndexAccessLog 写入日志
IndexAccessLog(client, accesslog)
}
}
if err := scanner.Err(); err != nil {
fmt.Printf("read file error: %v\n", err.Error())
}
}
// IndexAccessLog 写入日志
func IndexAccessLog(client *elastic.Client, access *AccessLog) {
_, err := client.Index().Index(indexName).BodyJson(access).Refresh("true").Do(context.Background())
if err != nil {
fmt.Printf("index access log error: %v\n", err.Error())
} else {
fmt.Printf("index access log success\n")
}
}
// ParseAccessLog 解析日志
func ParseAccessLog(line string) *AccessLog {
parts := strings.Split(line, " ")
if len(parts) < 7 {
return nil
}
timestamp, err := time.Parse(dateFormat, parts[3][1:])
if err != nil {
fmt.Printf("parse timestamp error: %v\n", err.Error())
return nil
}
return &AccessLog{
Timestamp: timestamp,
IP: parts[0],
Method: parts[5][1:],
Url: parts[6],
StatusCode: ParseStrToInt(parts[8]),
ResponseTime: ParseStrToInt(parts[9]),
UserAgent: strings.Join(parts[11:], " "),
}
}
// ParseStrToInt 字符串转int
func ParseStrToInt(str string) int {
String, _ := strconv.Atoi(str)
return String
}
PS D:\Codes\mmp\elasticsearch\log_demo> go run .\main.go
index access log success
# 这里我们没有做任何的回显,我们直接去访问ES去看看
[root@localhost ~]# curl 127.0.0.1:9200/nginx_logs
{"nginx_logs":{"aliases":{},"mappings":{"properties":{"ip":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"method":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"response_time":{"type":"long"},"status_code":{"type":"long"},"timestamp":{"type":"date"},"url":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"user_agent":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}}}},"settings":{"index":{"routing":{"allocation":{"include":{"_tier_preference":"data_content"}}},"number_of_shards":"1","provided_name":"nginx_logs","creation_date":"1689998589561","number_of_replicas":"1","uuid":"R-A50RB8QpCoMctZGSHm1Q","version":{"created":"7171199"}}}}}
# 可以看到这里已经显示了这个索引了,然后我们就可以根据这个索引去查询数据了
[root@localhost ~]# curl 127.0.0.1:9200/nginx_logs/_search -H 'Content-Type: application/json' -d '{ "size": 30 }'
{"took":1,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":20,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"nginx_logs","_type":"_doc","_id":"41zDe4kBnumd1Y5R_4Ul","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:06Z","ip":"172.16.0.20","method":"GET","url":"/contact.html","status_code":200,"response_time":9876,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"5VzDe4kBnumd1Y5R_4U-","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:08Z","ip":"10.0.0.3","method":"GET","url":"/products.html","status_code":200,"response_time":2048,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"51zDe4kBnumd1Y5R_4VW","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:10Z","ip":"192.168.1.3","method":"GET","url":"/blog.html","status_code":200,"response_time":3456,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"5FzDe4kBnumd1Y5R_4Uz","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:07Z","ip":"192.168.1.2","method":"GET","url":"/scripts/main.js","status_code":200,"response_time":5678,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"4FzDe4kBnumd1Y5R_oX_","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:03Z","ip":"172.16.0.10","method":"GET","url":"/images/logo.jpg","status_code":304,"response_time":0,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"6FzDe4kBnumd1Y5R_4Vi","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:12Z","ip":"192.168.0.101","method":"GET","url":"/index.html","status_code":200,"response_time":5432,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"31zDe4kBnumd1Y5R_oXx","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:02Z","ip":"10.0.0.1","method":"POST","url":"/login.php","status_code":302,"response_time":0,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"5lzDe4kBnumd1Y5R_4VL","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:09Z","ip":"172.16.0.30","method":"GET","url":"/favicon.ico","status_code":404,"response_time":0,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"4lzDe4kBnumd1Y5R_4UW","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:05Z","ip":"10.0.0.2","method":"GET","url":"/styles/main.css","status_code":200,"response_time":1234,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"3lzDe4kBnumd1Y5R_oWx","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:01Z","ip":"192.168.1.1","method":"GET","url":"/index.html","status_code":200,"response_time":5432,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"4VzDe4kBnumd1Y5R_4UL","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:04Z","ip":"192.168.0.100","method":"GET","url":"/about.html","status_code":200,"response_time":4321,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"7VzDe4kBnumd1Y5R_4Wy","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:17Z","ip":"172.16.0.50","method":"GET","url":"/contact.html","status_code":200,"response_time":9876,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"7lzDe4kBnumd1Y5R_4XB","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:18Z","ip":"192.168.0.102","method":"GET","url":"/scripts/main.js","status_code":200,"response_time":5678,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"61zDe4kBnumd1Y5R_4WU","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:15Z","ip":"192.168.1.4","method":"GET","url":"/about.html","status_code":200,"response_time":4321,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"71zDe4kBnumd1Y5R_4XO","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:19Z","ip":"10.0.0.7","method":"GET","url":"/products.html","status_code":200,"response_time":2048,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"8VzDe4kBnumd1Y5R_4Xl","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:21Z","ip":"192.168.1.5","method":"GET","url":"/blog.html","status_code":200,"response_time":3456,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"6lzDe4kBnumd1Y5R_4V8","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:14Z","ip":"172.16.0.40","method":"GET","url":"/images/logo.jpg","status_code":304,"response_time":0,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"6VzDe4kBnumd1Y5R_4Vv","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:13Z","ip":"10.0.0.5","method":"POST","url":"/login.php","status_code":302,"response_time":0,"user_agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"8FzDe4kBnumd1Y5R_4XY","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:20Z","ip":"172.16.0.60","method":"GET","url":"/favicon.ico","status_code":404,"response_time":0,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}},{"_index":"nginx_logs","_type":"_doc","_id":"7FzDe4kBnumd1Y5R_4Wj","_score":1.0,"_source":{"timestamp":"2023-07-21T09:30:16Z","ip":"10.0.0.6","method":"GET","url":"/styles/main.css","status_code":200,"response_time":1234,"user_agent":"\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""}}]}}
# 这里默认是10条,但是其实我们的数据不止10条,我们可以传递json参数size来指定每页多少条数据,然后还可以指定from指定从第几条数据开始返回,然后还有query指定条件,大概参数是
GET /your_index/_search
{
"size": 10, // 指定每页返回10个文档
"from": 20, // 从结果集的第20个文档开始返回
"query": {
// 查询条件
}
}
# 可以看到,数据也都在索引内了,而且自动匹配了字段,然后我们就可以去分析了,分析我们这些日志中请求为200的有多少个
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
const (
indexName = "nginx_logs"
)
var (
ElasticsearchURL = "http://10.0.0.13:9200"
)
func Client() *elastic.Client {
client, err := elastic.NewClient(elastic.SetURL(ElasticsearchURL), elastic.SetSniff(false))
if err != nil {
fmt.Printf("connect es error: %v\n", err)
}
return client
}
// 分析访问日志状态码为200的IP地址数量
func main() {
aggs := elastic.NewTermsAggregation().Field("status_code").Size(10000)
val, err := Client().Search().Index(indexName).Aggregation("status_code", aggs).Do(context.Background())
if err != nil {
fmt.Printf("search error: %v\n", err)
return
}
// 获取聚合结果
codes, found := val.Aggregations.Terms("status_code")
if !found {
fmt.Printf("status_code not found\n")
return
} else {
// 遍历聚合结果,并取出status_code为200的桶的个数
for _, code := range codes.Buckets {
if code.Key.(float64) == 200 {
fmt.Printf("status_code: %v, count: %v\n", code.Key, code.DocCount)
}
}
}
}
PS D:\Codes\mmp\elasticsearch\analysis> go run .\main.go
status_code: 200, count: 14
# 从结果我们不难看出,这里200的status_code的数量为14个,我们仔细数数也可以数出来了,这就是一个简单的数据分析的demo了
3:Kafka的认识与使用
3.1:Kafka介绍
Kafka是一个分布式流处理平台,最初由Linkedln公司开发,现在由Apache软件基金会维护,它被设计用于高吞吐量,低延迟的数据传输,并具有可扩展性和容错性
Kafka的核心概念是消息传递系统,它通过将数据以消息的方式进行发布和订阅来实现数据流的处理,以下是Kafka的一些关键特点和概念:
1:消息的发布和订阅:Kafka使用发布-订阅模型,消息发送者将消息发送到一个或者多个主题(Topics),而消息订阅者可以从这些主题中获取消息
2:分布式架构:Kafka是一个分布式系统,可以在多个节点上部署,实现数据的分区和复制,以实现高可用性和可扩展性
3:消息持久化:Kafka使用日志(log)的方式持久化消息,每个主题的消息以追加的方式写入分区中,并且消息会在一段时间后根据配置进行保留
4:分区和复制:Kafka将每个主题分成一个或者多个分区(Partitions),每个分区可以在多个节点上进行复制,以实现负载均衡和容错性
5:高吞吐量:Kafka具有非常高的吞吐量和低延迟,能够处理大量的消息流,并保持较低的延迟
6:实时数据处理:Kafka可以与流处理框架(Flink,Spark)集成,支持实时的数据处理和流式分析
3.2:Kafka应用场景
1:数据流集成和数据通道:Kafka可以作为数据流的中间件,用于连接不同的数据系统和应用程序,它可以集成多个数据源和数据目的地,实现可靠的数据传输和流水线处理
2:日志收集和集中式日志管理:Kafka可以用作日志收集系统,收集和存储分布式在多个应用程序和服务器上的日志数据,它提供高吞吐量和持久化存储,支持实时的日志数据处理和分析
3:事件驱动架构:Kafka的发布-订阅模型使其成为构建事件驱动架构的理想选择,应用程序可以将事件发布到Kafka主题,然后其他应用程序可以订阅并处理这些事件,实现松耦合,可扩展和实时的事件驱动架构
4:流式处理和实时分析:Kafka可以与流式处理框架(Flink,Spark)集成,支持实时的流式数据和复杂的实时分析,通过将数据流导入Kafka主题,应用程序可以实时处理和分析数据,实现实时的洞察和决策
5:异步消息队列:Kafka可以用作高吞吐量的异步消息队列,实现应用程序之间的解耦和异步通信,应用程序可以将消息发送到Kafka主题,并异步处理这些消息,提高系统的可伸缩性和弹性
6:数据备份和容错性:Kafka支持数据的分区和复制,可以在多个节点上复制和存储数据,以实现数据的冗余备份和容错性
3.3:Kafka第三方库
github:https://github.com/Shopify/sarama ----> https://github.com/IBM/sarama
# 它是一个Go语言编写的Apache Kafka的客户端库,用于与kafka进行集群交互,它提供了丰富的功能和易于使用的API,使得开发人员能够方便的使用Go语言来生产和消费Kafka消息
# 下载依赖客户端
go get -u "github.com/Shopify/sarama" ----> go get -u "github.com/IBM/sarama"
3.4:Kafka客户端使用
package main
import (
"fmt"
"github.com/IBM/sarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
} else {
fmt.Println("Client started", client)
}
defer client.Close()
// 创建一个生产者
producer, err := sarama.NewSyncProducerFromClient(client)
if err != nil {
fmt.Printf("Failed to start producer: %s", err)
} else {
fmt.Println("Producer started", producer)
}
defer producer.Close()
// 创建一个消费者
consumer, err := sarama.NewConsumerFromClient(client)
if err != nil {
fmt.Printf("Failed to start consumer: %s", err)
} else {
fmt.Println("Consumer started", consumer)
}
defer consumer.Close()
}
PS D:\Codes\mmp\kafka\base> go run .\main.go
Client started &{1690103977248 0xc00000d400 0xc000020300 0xc000020360 [0xc0000bf180] [] 0 map[0:0xc0000bf500] map[] map[] map[] map[] map[] {{0 0} 0 0 {{} 0} {{} 0}}}
# 从这里可以看出,Kafka是已经连接成功了,那么下面我们主要就是针对生产和消费端进行的一些操作了
3.5:Kafka参数解析
| 参数 |
作用 |
Version |
指定使用的Kafka协议版本 |
ClientID |
指定客户端ID,用于在kafka服务器端进行日志记录和跟踪 |
Net |
指定用于与kafka服务通信的网络类型 |
Metadata.Refresh |
控制是否从kafka集群获取和更新元数据信息 |
Producer.Return.Successes |
在成功发送消息后返回成功的消息元数据 |
Producer.RequiredAcks |
指定生产者需要等待的确认数 |
Consumer.Group.Rebalance.Strategy |
指定消费者组的再平衡策略 |
Consumer.Offsets.Initial |
指定消费者从哪儿个偏移量开始消费 |
Consumer.MaxWaitTime |
设置消费者在等待消息时的最大等待时间 |
Consumer.Fetch.Default |
指定消费者默认一次从kafka获取的消息字节数 |
Admin.Timeout |
设置管理员操作的超时时间 |
3.6:KafkaTopic增删查
package main
import (
"fmt"
"github.com/IBM/sarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
}
defer client.Close()
// 创建一个集群管理器
admin, err := sarama.NewClusterAdminFromClient(client)
if err != nil {
fmt.Printf("Failed to start cluster admin: %s", err)
}
defer admin.Close()
// 设置Topic的分区与副本数
topicDetail := &sarama.TopicDetail{
NumPartitions: 2,
ReplicationFactor: 1,
}
// 创建Topic
if err := admin.CreateTopic("topic_one", topicDetail, false); err != nil {
fmt.Printf("Failed to create topic: %s", err)
} else {
fmt.Println("Topic created")
}
// 查看所有的Topic
topics, err := admin.ListTopics()
if err != nil {
fmt.Printf("Failed to list topics: %s", err)
} else {
fmt.Println("Topics listed", topics)
}
}
PS D:\Codes\mmp\kafka\topic> go run .\main.go
Topic created
Topics listed map[topic_one:{2 1 map[0:[0] 1:[0]] map[cleanup.policy:0xc0001ca190 compression.type:0xc0001ca050 delete.retention.ms:0xc0001ca5d0 file.delete.delay.ms:0xc0001ca390 flush.messages:0xc0001ca2d0 flush.ms:0xc0001ca1d0 fol
lower.replication.throttled.replicas:0xc0001ca210 index.interval.bytes:0xc0001ca510 leader.replication.throttled.replicas:0xc0001ca090 max.compaction.lag.ms:0xc0001ca350 max.message.bytes:0xc0001ca3d0 message.downconversion.enable:0
xc0001ca0d0 message.format.version:0xc0001ca310 message.timestamp.difference.max.ms:0xc0001ca650 message.timestamp.type:0xc0001ca450 min.cleanable.dirty.ratio:0xc0001ca4d0 min.compaction.lag.ms:0xc0001ca410 min.insync.replicas:0xc00
01ca110 preallocate:0xc0001ca490 retention.bytes:0xc0001ca590 retention.ms:0xc0001ca290 segment.bytes:0xc0001ca250 segment.index.bytes:0xc0001ca690 segment.jitter.ms:0xc0001ca150 segment.ms:0xc0001ca610 unclean.leader.election.enable:0xc0001ca550]}]
# 从上面可以看到,Topic是创建成功的,而且最后也拿到了Topic了,然后我们就是考虑如何删除Topic了,因为Topic本身就没有什么可操作的东西
package main
import (
"fmt"
"github.com/IBM/sarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
}
defer client.Close()
// 创建一个集群管理器
admin, err := sarama.NewClusterAdminFromClient(client)
if err != nil {
fmt.Printf("Failed to start cluster admin: %s", err)
}
defer admin.Close()
// 删除一个Topic
if err := admin.DeleteTopic("topic_one"); err != nil {
fmt.Printf("Failed to delete topic: %s", err)
} else {
fmt.Println("Topic deleted")
}
// 查看所有的Topic
topics, err := admin.ListTopics()
if err != nil {
fmt.Printf("Failed to list topics: %s", err)
} else {
fmt.Println("Topics listed", topics)
}
}
PS D:\Codes\mmp\kafka\topic> go run .\main.go
Topic deleted
Topics listed map[]
# 可以看到这里已经把Topic给删除了(默认Kafka是不允许删除Topic的),然后我们就是查询一个Topic的详细信息了
package main
import (
"fmt"
"github.com/IBM/sarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
}
defer client.Close()
// 创建一个集群管理器
admin, err := sarama.NewClusterAdminFromClient(client)
if err != nil {
fmt.Printf("Failed to start cluster admin: %s", err)
}
defer admin.Close()
// 查看一个Topic的详细信息
desc, err := admin.DescribeTopics([]string{"topic_one"})
if err != nil {
fmt.Printf("Failed to describe topic: %s", err)
}
fmt.Println(desc[0].Version)
}
PS D:\Codes\mmp\kafka\topic> go run .\main.go
5
# 可以看到,这里拿到了Topic的版本,然后我们就可以在深入一下,就是查找指定主题和分区了(最早和最新)
package main
import (
"fmt"
"github.com/IBM/sarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
}
defer client.Close()
// 创建一个集群管理器
admin, err := sarama.NewClusterAdminFromClient(client)
if err != nil {
fmt.Printf("Failed to start cluster admin: %s", err)
}
defer admin.Close()
// 查找指定主题和分区(最早和最新)的偏移量
earliestOffset, _ := client.GetOffset("topic_one", 0, sarama.OffsetOldest)
latestOffset, _ := client.GetOffset("topic_one", 0, sarama.OffsetNewest)
fmt.Println(earliestOffset, latestOffset)
}
PS D:\Codes\mmp\kafka\topic> go run .\main.go
0 0
# 因为我们没有消息的创建和消费,所以都是0这个是正常的
package main
import (
"fmt"
"github.com/IBM/sarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
}
defer client.Close()
// 查看指定主题分区的消费位移
consumer, err := sarama.NewConsumerFromClient(client)
if err != nil {
fmt.Printf("Failed to start consumer: %s", err)
}
defer consumer.Close()
// 获取分区的消费者
partitionConsumer, _ := consumer.ConsumePartition("topic_one", 0, sarama.OffsetNewest)
defer partitionConsumer.Close()
partitionOffset := partitionConsumer.HighWaterMarkOffset() // 获取分区的最新偏移量
fmt.Println(partitionOffset)
}
PS D:\Codes\mmp\kafka\topic> go run .\main.go
0
# 还是那句话,我们还没开始创建消息和消费消息,所以等于0,那么我们下面就来看看如何生产和消费消息
3.7:KafkaProcuder
package main
import (
"fmt"
"github.com/IBM/sarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
config.Producer.Return.Errors = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
}
defer client.Close()
// 同步生出消息
syncProducer, err := sarama.NewSyncProducerFromClient(client)
if err != nil {
panic(err)
}
defer syncProducer.Close()
// 指定消息的主题和内容
topic := "topic_one"
message := "Hello Kafka"
// 创建消息对象
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.StringEncoder(message),
}
// 发送消息
partition, offset, err := syncProducer.SendMessage(msg)
if err != nil {
fmt.Printf("Failed to produce message: %s", err)
}
fmt.Println("Partition = ", partition, " offset = ", offset)
}
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 0 offset = 0
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 0 offset = 1
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 0 offset = 2
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 0 offset = 3
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 1 offset = 0
# 理论来说,现在0分区的消息为4个,因为我们没有消费它,所以会是4个,1分区的消息为1个,这个partition的数量是我们创建Topic的时候指定的NumPartitions的数量,发送消息是随机的,至于查询消息的方式我们在上面的代码也给到了,也就是获取分区消费者的时候最下面的代码,上面是一个同步的生产消息,那么我们下面来看看异步的情况
package main
import (
"fmt"
"github.com/IBM/sarama"
"time"
)
func main() {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
config.Producer.Return.Errors = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
}
defer client.Close()
// 同步生出消息
syncProducer, err := sarama.NewSyncProducerFromClient(client)
if err != nil {
panic(err)
}
defer syncProducer.Close()
// 指定消息的主题和内容
topic := "topic_one"
message := "Hello Kafka"
// 创建消息对象
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.StringEncoder(message),
}
// 发送消息
partition, offset, err := syncProducer.SendMessage(msg)
if err != nil {
fmt.Printf("Failed to produce message: %s", err)
}
fmt.Println("Partition = ", partition, " offset = ", offset)
// 异步生产消息
asyncProducer, err := sarama.NewAsyncProducerFromClient(client)
if err != nil {
panic(err)
}
defer asyncProducer.Close()
msg.Key = sarama.StringEncoder("async-key")
// 设置消息的发送时间
msg.Timestamp = time.Now()
// 设置消息的头部
msg.Headers = []sarama.RecordHeader{
{
Key: []byte("header-key"),
Value: []byte("header-value"),
},
}
// 异步发送消息
asyncProducer.Input() <- msg
// 监听发送结果
select {
case success := <-asyncProducer.Successes():
fmt.Println("offset: ", success.Offset, "timestamp: ", success.Timestamp.String(), "partitions: ", success.Partition)
case err := <-asyncProducer.Errors():
fmt.Println("err: ", err.Error())
case <-time.After(time.Second * 5):
fmt.Println("timeout 5s")
}
}
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 0 offset = 4 # 同步生产消息的结果
offset: 1 timestamp: 2023-07-24 16:35:50.8897526 +0800 CST m=+0.008035301 partitions: 1 # 异步生产消息的结果
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 1 offset = 2
offset: 3 timestamp: 2023-07-24 16:41:21.367569 +0800 CST m=+0.008221701 partitions: 1
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 1 offset = 4
offset: 5 timestamp: 2023-07-24 16:41:38.0670606 +0800 CST m=+0.008419101 partitions: 1
# 这样应该很明了了,这里的客户端貌似设置分区的参数并不生效,也不知道是不是我使用有问题,总之这里的使用就是这样的,这就是生产消息的方法,然后我们就可以去写消费消息的操作了
3.8:KafkaConsumer
package main
import (
"context"
"fmt"
"github.com/IBM/sarama"
"os"
"os/signal"
)
func main() {
// 新的初始化方式
config := sarama.NewConfig()
// 设置统一的消费offset
config.Consumer.Offsets.Initial = sarama.OffsetOldest
// 创建消费组的客户端
consumerGroup, err := sarama.NewConsumerGroup([]string{"10.0.0.13:9092"}, "topic_group", config)
if err != nil {
panic(err)
}
defer consumerGroup.Close()
// 指定topic
topics := []string{"topic_one"}
// 创建一个消费组处理器
handler := ConsumerGroupHandler{}
// 启动消费者
go func() {
for {
if err := consumerGroup.Consume(context.Background(), topics, handler); err != nil {
fmt.Println("ConsumerGroupHandler error", err)
}
}
}()
signChan := make(chan os.Signal, 1)
signal.Notify(signChan, os.Interrupt)
// 监听到os.Interrupt信号后,从阻塞中退出
<-signChan
}
// ConsumerGroupHandler 自定义消费组处理器
type ConsumerGroupHandler struct{}
// Setup 消费组处理器启动时执行
func (h ConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {
fmt.Println("Consumer Group Setup")
return nil
}
// Cleanup 消费组处理器退出时执行
func (h ConsumerGroupHandler) Cleanup(session sarama.ConsumerGroupSession) error {
fmt.Println("Consumer Group Cleanup")
return nil
}
// ConsumeClaim 消费组处理器消费消息
func (h ConsumerGroupHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
fmt.Println("Consumer Group ConsumeClaim")
for msg := range claim.Messages() {
fmt.Println("Received messages", msg.Topic, msg.Partition, msg.Offset, string(msg.Key), string(msg.Value))
session.MarkMessage(msg, "")
}
return nil
}
PS D:\Codes\mmp\kafka\consuner> go run .\main.go
Received messages topic_one 0 0 Hello Kafka
Received messages topic_one 0 1 Hello Kafka
Received messages topic_one 0 2 Hello Kafka
Received messages topic_one 0 3 Hello Kafka
Received messages topic_one 0 4 Hello Kafka
Received messages topic_one 0 5 Hello Kafka
Received messages topic_one 0 6 Hello Kafka
Received messages topic_one 0 7 Hello Kafka
Received messages topic_one 0 8 Hello Kafka
Received messages topic_one 0 9 Hello Kafka
Received messages topic_one 0 10 Hello Kafka
Received messages topic_one 0 11 Hello Kafka
Received messages topic_one 0 12 Hello Kafka
Received messages topic_one 0 13 Hello Kafka
Received messages topic_one 0 14 Hello Kafka
Received messages topic_one 0 15 Hello Kafka
# 可以看到0分区消费了16个,因为后面我执行了很多,所以有16,然后我们换成1分区试一下
PS D:\Codes\mmp\kafka\consuner> go run .\main.go
Received messages topic_one 1 0 Hello Kafka
Received messages topic_one 1 1 async-key Hello Kafka
Received messages topic_one 1 2 Hello Kafka
Received messages topic_one 1 3 async-key Hello Kafka
Received messages topic_one 1 4 Hello Kafka
Received messages topic_one 1 5 async-key Hello Kafka
Received messages topic_one 1 6 Hello Kafka
Received messages topic_one 1 7 async-key Hello Kafka
Received messages topic_one 1 8 async-key Hello Kafka
Received messages topic_one 1 9 Hello Kafka
Received messages topic_one 1 10 async-key Hello Kafka
Received messages topic_one 1 11 Hello Kafka
Received messages topic_one 1 12 async-key Hello Kafka
Received messages topic_one 1 13 async-key Hello Kafka
Received messages topic_one 1 14 Hello Kafka
Received messages topic_one 1 15 async-key Hello Kafka
Received messages topic_one 1 16 async-key Hello Kafka
Received messages topic_one 1 17 async-key Hello Kafka
Received messages topic_one 1 18 async-key Hello Kafka
Received messages topic_one 1 19 async-key Hello Kafka
Received messages topic_one 1 20 Hello Kafka
Received messages topic_one 1 21 async-key Hello Kafka
Received messages topic_one 1 22 async-key Hello Kafka
Received messages topic_one 1 23 async-key Hello Kafka
Received messages topic_one 1 24 Hello Kafka
Received messages topic_one 1 25 async-key Hello Kafka
Received messages topic_one 1 26 async-key Hello Kafka
Received messages topic_one 1 27 Hello Kafka
Received messages topic_one 1 28 async-key Hello Kafka
Received messages topic_one 1 29 Hello Kafka
Received messages topic_one 1 30 async-key Hello Kafka
Received messages topic_one 1 31 Hello Kafka
Received messages topic_one 1 32 async-key Hello Kafka
Received messages topic_one 1 33 async-key Hello Kafka
Received messages topic_one 1 34 async-key Hello Kafka
Received messages topic_one 1 35 Hello Kafka
Received messages topic_one 1 36 async-key Hello Kafka
Received messages topic_one 1 37 Hello Kafka
Received messages topic_one 1 38 async-key Hello Kafka
# 可以看到,这里面消费的更多,这就是我们的消费的一个逻辑了,此时此刻我们可以看到的是程序还在阻塞在前台,这个时候我们的Producer,那么Consumer就还可以接着消费它,不过这里是单分区的消费逻辑,下面我们看看多分区的消费逻辑是什么样子的
package main
import (
"fmt"
"github.com/IBM/sarama"
"sync"
)
func main() {
config := sarama.NewConfig()
config.Consumer.Return.Errors = true
client, err := sarama.NewClient([]string{"10.0.0.13:9092"}, config)
if err != nil {
fmt.Printf("Failed to start client: %s", err)
}
defer client.Close()
// 创建消费者操作客户端
consumer, err := sarama.NewConsumerFromClient(client)
if err != nil {
panic(err)
}
defer consumer.Close()
// 订阅主题
topic := "topic_one"
partitions := []int32{0, 1}
offset := int64(0)
// 使用waitGroup等待消费者处理完成
wg := &sync.WaitGroup{}
wg.Add(len(partitions))
// 创建分区消费者
for _, partition := range partitions {
go func(p int32) {
defer wg.Done()
partitionConsumer, _ := consumer.ConsumePartition(topic, p, offset)
defer partitionConsumer.Close()
// 消费信息
for msg := range partitionConsumer.Messages() {
fmt.Println("Received messages", msg.Topic, msg.Partition, msg.Offset, string(msg.Key), string(msg.Value))
}
}(partition)
}
// 等待消费者处理完成
wg.Wait()
}
PS D:\Codes\mmp\kafka\consuner\multi_partition> go run .\main.go
Received messages topic_one 0 0 Hello Kafka
Received messages topic_one 0 1 Hello Kafka
Received messages topic_one 0 2 Hello Kafka
Received messages topic_one 0 3 Hello Kafka
Received messages topic_one 0 4 Hello Kafka
Received messages topic_one 0 5 Hello Kafka
Received messages topic_one 0 6 Hello Kafka
Received messages topic_one 0 7 Hello Kafka
Received messages topic_one 0 8 Hello Kafka
Received messages topic_one 0 9 Hello Kafka
Received messages topic_one 0 10 Hello Kafka
Received messages topic_one 0 11 Hello Kafka
Received messages topic_one 0 12 Hello Kafka
Received messages topic_one 0 13 Hello Kafka
Received messages topic_one 0 14 Hello Kafka
Received messages topic_one 0 15 Hello Kafka
Received messages topic_one 0 16 Hello Kafka
Received messages topic_one 0 17 Hello Kafka
Received messages topic_one 1 0 Hello Kafka
Received messages topic_one 1 1 async-key Hello Kafka
Received messages topic_one 1 2 Hello Kafka
Received messages topic_one 1 3 async-key Hello Kafka
Received messages topic_one 1 4 Hello Kafka
Received messages topic_one 1 5 async-key Hello Kafka
Received messages topic_one 1 6 Hello Kafka
Received messages topic_one 1 7 async-key Hello Kafka
Received messages topic_one 1 8 async-key Hello Kafka
Received messages topic_one 1 9 Hello Kafka
Received messages topic_one 1 10 async-key Hello Kafka
Received messages topic_one 1 11 Hello Kafka
Received messages topic_one 1 12 async-key Hello Kafka
Received messages topic_one 1 13 async-key Hello Kafka
Received messages topic_one 1 14 Hello Kafka
Received messages topic_one 1 15 async-key Hello Kafka
Received messages topic_one 1 16 async-key Hello Kafka
Received messages topic_one 1 17 async-key Hello Kafka
Received messages topic_one 1 18 async-key Hello Kafka
Received messages topic_one 1 19 async-key Hello Kafka
Received messages topic_one 1 20 Hello Kafka
Received messages topic_one 1 21 async-key Hello Kafka
Received messages topic_one 1 22 async-key Hello Kafka
Received messages topic_one 1 23 async-key Hello Kafka
Received messages topic_one 1 24 Hello Kafka
Received messages topic_one 1 25 async-key Hello Kafka
Received messages topic_one 1 26 async-key Hello Kafka
Received messages topic_one 1 27 Hello Kafka
Received messages topic_one 1 28 async-key Hello Kafka
Received messages topic_one 1 29 Hello Kafka
Received messages topic_one 1 30 async-key Hello Kafka
Received messages topic_one 1 31 Hello Kafka
Received messages topic_one 1 32 async-key Hello Kafka
Received messages topic_one 1 33 async-key Hello Kafka
Received messages topic_one 1 34 async-key Hello Kafka
Received messages topic_one 1 35 Hello Kafka
Received messages topic_one 1 36 async-key Hello Kafka
Received messages topic_one 1 37 Hello Kafka
Received messages topic_one 1 38 async-key Hello Kafka
Received messages topic_one 1 39 Hello Kafka
Received messages topic_one 1 40 Hello Kafka
Received messages topic_one 1 41 Hello Kafka
Received messages topic_one 1 42 Hello Kafka
Received messages topic_one 1 43 Hello Kafka
# 可以看到,这里面利用了sync的包来处理这个逻辑,其实可以理解为就是循环填入了partitions的数量,然后进行了消费,就是这样,写个循环其实应该也能实现,那么最后还有一个kafka的消费组的概念,它也是我们比较常用的一个消费消息的方法
package main
import (
"context"
"fmt"
"github.com/IBM/sarama"
"os"
)
func main() {
// 新的初始化方式
config := sarama.NewConfig()
// 设置统一的消费offset
config.Consumer.Offsets.Initial = sarama.OffsetOldest
// 创建消费组的客户端
consumerGroup, err := sarama.NewConsumerGroup([]string{"10.0.0.13:9092"}, "topic_group", config)
if err != nil {
panic(err)
}
defer consumerGroup.Close()
// 指定topic
topics := []string{"topic_one"}
// 创建一个消费组处理器
handler := ConsumerGroupHandler{}
// 启动消费者
go func() {
for {
if err := consumerGroup.Consume(context.Background(), topics, handler); err != nil {
fmt.Println("ConsumerGroupHandler error", err)
}
}
}()
signChan := make(chan os.Signal, 1)
// 监听到os.Interrupt信号后,从阻塞中退出
<-signChan
}
// ConsumerGroupHandler 自定义消费组处理器
type ConsumerGroupHandler struct{}
// Setup 消费组处理器启动时执行
func (h ConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {
fmt.Println("Consumer Group Setup")
return nil
}
// Cleanup 消费组处理器退出时执行
func (h ConsumerGroupHandler) Cleanup(session sarama.ConsumerGroupSession) error {
fmt.Println("Consumer Group Cleanup")
return nil
}
// ConsumeClaim 消费组处理器消费消息
func (h ConsumerGroupHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
fmt.Println("Consumer Group ConsumeClaim")
for msg := range claim.Messages() {
fmt.Println("Received messages", msg.Topic, msg.Partition, msg.Offset, string(msg.Key), string(msg.Value))
session.MarkMessage(msg, "")
}
return nil
}
这里我们主要说明的就是如下两个配置的区别,一个是从最新的开始消费,一个是从上次消费结束的地方开始消费
config.Consumer.Offsets.Initial = sarama.OffsetOldest # 从最老的offset也就是0开始
config.Consumer.Offsets.Initial = sarama.OffsetNewest # 从最新的offset也就是最后一次消费的offset开始
# 创建消息
PS D:\Codes\mmp\kafka\producer> go run .\main.go
Partition = 0 offset = 28
offset: 72 timestamp: 2023-07-25 03:03:17.4479532 +0800 CST m=+0.007061501 partitions: 1
# 消费消息
PS D:\Codes\mmp\kafka\consuner\consumer_group> go run .\main.go
Consumer Group Setup
Consumer Group ConsumeClaim
Consumer Group ConsumeClaim
Received messages topic_one 0 28 Hello Kafka
Received messages topic_one 1 72 async-key Hello Kafka
# 这里可以看到,也就没什么问题了,一边传递消息一边消费消息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号