


深入理解计算机系统 -- 程序的机器级表示
1. 程序优化等级
假设有源文件 p1.c 和 p2.c,使用 gcc -Og -o p p1.c p2.c 编译生成代码,-Og 会告诉编译器使用符合原始 C 代码整体结构的机器代码优化等级。(PS: -O0 所得到的汇编代码实用价值极小,几乎没有什么用处,建议使用 -Og 或者 -O1(有的较早的编译器可能不认识 -Og,这是 GCC 4.8 之后引入的内容),可读性会更高)。
1.1 机器级代码
对于机器级编程来说,计算机有两种抽象至关重要,第一种是用指令集结构来定义机器级程序的格式和行为,它定义了处理器的状态,指令的格式,以及每条指令对状态的影响,大多数指令集结构将程序的行为描述的好像每条指令都是按顺序执行的,实际情况要更加复杂一些,很多指令都是并发执行的。第二种抽象则是虚拟内存,所有机器级程序使用的内存地址均为虚拟内存,计算机提供了一个内存模型,看上去是一个很大的字节数组,具体的内容会在第九章讲到。
在整个编译过程中,编译器会完成大部分的工作,将把用 C 语言提供的相对比较抽象的执行模型表示的程序转换成处理器执行的非常基本的指令。汇编代码十分接近于机器代码,但可读性比二进制的机器代码显然是高很多的,理解汇编代码以及它与原始 C 代码的关系,是理解计算机如何执行程序的关键一步。
对于我们来说,可见的处理器状态主要有以下几种:
- 程序计数器,(通常称为“PC”,在 x86-64 中通常用 %rip 寄存器表示),主要存放下一条要执行的指令在内存中的地址。
- 整数寄存器,总共包含 16 个寄存器,分别存储 64 位的值。这些寄存器可以来存放地址(如指针)或者整型数据。有的寄存器用来记录某些重要的程序状态,而其他的寄存器用来保存临时数据,例如函数参数,局部变量以及函数返回值等。
- 条件码寄存器,保存着最近执行的算术运算或逻辑指令的状态信息。用来控制数据流中的条件变化,比如实现 if 和 while 等等语句。
- 向量寄存器,用来保存一个或多个整数或浮点数值。
C 语言提供了一种模型,可以在内存中分配和声明各种数据类型的对象,但是实际上机器代码只是简单的将内存视为一个巨大的,按字节寻址的数组。C 语言的各种数据类型,如数组,结构体,在机器代码中用连续的字节表示,对标量数据类型,汇编代码也不区分有符号和无符号整数,不区分各种类型的指针,甚至不区分指针与整数。
程序内存包括: 可执行的机器代码,操作系统需要的一些信息,用来管理过程调用和返回的运行时栈,以及用户分配的内存块(new, malloc)。程序内存用虚拟地址来寻址。在任意给定时刻,只有有限的一部分虚拟地址是认为合法的。例如,x86-64 的虚拟地址是由 64 位的字来表示的,在目前的实现中,这些地址的最高 16 位必须设置为 0 。所以一个地址实际上能够指定的是 2^48 或 64 TB 范围内的一个字节。较为典型的程序只会访问几兆字节或几千兆字节的数据。操作系统负责管理虚拟地址空间,将虚拟地址翻译成实际的处理器内存中的物理地址。
假如有源文件 main.c ,代码如下:
long mult2(long, long);
void multstore(long x, long y, long *dest)
{
long t = mult2(x, y);
*dest = t;
}
我们想查看它生成的汇编代码,可以使用 gcc -Og -S main.c ,即可产生一个 main.s 的汇编文件,此时可以直接用 vim 查看汇编代码,可以看到诸如以下的汇编代码:
.LFE34:
.size intlen, .-intlen
.globl multstore
.type multstore, @function
multstore:
.LFB35:
.cfi_startproc
pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
movq %rdx, %rbx
call mult2
movq %rax, (%rbx)
popq %rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
这里就是 multstore 的汇编代码,假如我们使用 gcc -Og -c main.c ,则会生成目标代码文件 main.o ,这个文件是二进制格式的,是一个字节序列,它是对一系列指令的编码。如果使用 vim 查看也只会是一堆乱码,我们可以使用一类被称为 反汇编器 的程序来查看这种文件的汇编代码。比如 objdump -d main.o ,此时会输出该文件的汇编代码。如下所示:
0000000000000054 <multstore>:
54: 53 push %rbx
55: 48 89 d3 mov %rdx,%rbx
58: e8 00 00 00 00 callq 5d <multstore+0x9>
5d: 48 89 03 mov %rax,(%rbx)
60: 5b pop %rbx
61: c3 retq
在使用 vim 查看 .o 文件时看到的乱码实际上就是上述代码中的十六进制数字对应的 ASCII 码,对于机器代码和它的反汇编表示的特性有几点值得注意:
- x86-64 的指令长度从 1 到 15 个字节不等。常用的指令以及操作数较少的指令所需的字节数少,而那些不太常用或操作数较多的指令所需字节数较多。
- 设计指令格式的方式是,从某个给定位置开始,可以将字节唯一的解码成机器指令。例如,只有指令 push %rbx 是以字节值 53 开头的(更多关于指令编码值相关的翻阅第四章)。
- 反汇编器只是根据机器代码文件中的字节序列来确定汇编代码。它不需要访问该程序的源代码或汇编代码。
假如我们需要对多个源文件进行链接生成一个可执行文件,那么这些文件中必须含有 main 函数,我们可以使用 gcc -Og main.c hello.c 来生成一个可执行文件 a.out ,此时 a.out 包含了两个文件的代码,还包含了启动和终止程序的代码,以及用来与操作系统交互的代码,我们反汇编 a.out 文件可以看到这些源文件的一些函数的汇编代码,此外,.o 文件和 .out 文件的显著区别之一就是,.o 文件的汇编代码是从地址 0 开始的, 而 .out 文件的地址是从某个地址开始的,具体参阅 第七章 链接。
2 数据格式
由于是从 16 位体系结构拓展成 32 位的,Intel 用 ‘字(word)’ 来表示 16 位数据类型,因此 32 位称为双字(double words),称 64 位为四字(quad words),指针存储为 8 字节的四字,64位机器预期如此。x86-64 中,数据类型 long 实现为 64 位,允许表示的值范围比较大。下图表示 C 语言数据在 x86-64 中的大小,大多数 GCC 生成的汇编代码都会有一个字符的后缀。

一个 x86-64 的中央处理单元(CPU)包含一组 16 个存储 64 位值的通用目的寄存器。这些寄存器用来存储整数数据和指针,下图显示了这 16 个寄存器,每个寄存器都有特殊的用途,如 %rsp 表示运行时栈顶的地址。
2.1 操作数指示符
大多数指令有一个或多个操作数,指示出执行一个操作中要使用的源数据值,以及防止结果的目的位置。主要有以下三类操作数立即数,寄存器以及内存。
- 立即数:立即数的格式主要为 '$' 后面加一个用标准 C 表示法表示的整数,比如 $-577 和 $0x1F。
- 寄存器:主要表示某个寄存器的内容,用 ra (如下图第 3 行) 来表示任意寄存器 a ,用引用 R[ra] 来表示寄存器 a 里面存储的值,可以将 R 看成寄存器数组,ra 看成索引标志某个寄存器。
- 内存引用:内存引用会根据计算出来的地址(通常称为有效地址)访问某个内存地址。因为将内存看成一个很大的字节数组,我们使用 Mb[Addr] 来表示存储在内存中地址 Addr 开始的 b 个字节的引用, 为了简便,通常省略 b , 即 M[Addr]

3 指令
3.1 数据传送指令
最频繁使用的指令是 数据传送 指令,它将数据从一个位置复制到另一个位置,数据传送指令有很多种,或者源和目的地址不同,或者执行的转换不同,或者具有的一些副作用不同。下图列出了最简单形式的 mov 指令,可以看到有四条 mov 指令,后缀均不相同,表明每一条指令的操作数大小都不同。

源操作数指定的值是一个立即数,存储在寄存器中或者内存中,目的操作数指定一个位置,寄存器或者内存地址,x86-64 加了一条限制,传送指令的两个操作数不能都是内存地址,将一个值从源地址传送到目的地址需要两条指令,将源地址的值加载到寄存器中,再将寄存器的值写入到目标地址中。下图展示了源操作数和目的操作数的 5 种可能组合。

此外还有 movz 指令以及 movs 指令,具体的描述如下所示,此外,可以观察到,图 3-6 中有 movslq 指令,但是图 3-5 中没有 movzlq 指令,这是因为 movzlq 指令所实现的效果可以利用 movl 指令来实现。 这一技术主要利用的属性是,生成 4 字节值并以寄存器作为目的的指令会把高 4 字节置为 0 。

举一个数据传送的例子,有如下代码:
long exchange(long *xp, long y)
{
long x = *xp;
*xp = y;
return x;
}
其汇编代码如下:
exchange:
movq (%rdi), %rax
movq %rsi, (%rdi)
ret
首先,根据各个寄存器的作用描述图可知,xp 存储在 %rdi, y 存储在 %rsi , 第一条 mov 指令将 %rdi 寄存器中的地址解引用赋值给 %rax 寄存器,对应着代码 *xp 赋值给 x ,且 x 为返回值,%rax 寄存器的作用就是作为返回值。故 %rax 寄存器存放的为 x 的值。关于这段汇编代码可知,C 语言中所谓的指针实质上就是地址,间接引用指针j就是将该指针放在一个寄存器中,然后在内存引用中使用这个寄存器。其次,像 x 这样的局部变量通常是保存在寄存器中,而不是内存中,访问寄存器比访问内存要快的多。
3.2 压栈和出栈
栈在处理过程调用中起着至关重要的作用,栈存储着局部变量,函数参数以及函数返回地址等等,它可以添加和删除值,但是需要遵循先进后出的原则,通过 push 压数据入栈,pop 将数据弹出栈,它具有一个属性,弹出的值永远是最近刚入栈且仍然在栈顶的值,在 x86-64 中,程序的栈被存放在内存中某个区域,栈是向下生长的,也就意味着栈的地址会随着入栈操作而变小。故而栈顶地址是所有栈中元素中地址最小的,%rsp 指针保存着栈顶地址。下图是 push 和 pop 指令的效果和描述。

push 和 pop 都只有一个操作数,要压入的数据源和要弹出的数据目的,将一个四字值压入栈中,首先要将 %rsp 减 8 ,然后将新值写到新的栈顶地址,因此 pushq %rbp 等价于 sub $8 , %rsp ; movq %rbp, (%rsp) 。两者的区别主要在于,机器代码中 pushq 指令编码为一个字节,而上面两条指令需要8 个字节。popq 指令与 pushq 指令类似,popq %rax 等价于 add $8, %rsp ; movq (%rsp), %rax 。此外,也可以利用 push 和 pop 来完成交换值的操作: push %rax ; mov %rbx , %rax ; pop %rbx 。
3.3 算术和逻辑操作

此处需要注意 leaq 和 movq 的区别在于,leaq 不解引用,即 movq M[addr] , %rax 会将 *addr 赋给 rax 寄存器,而 leaq M[addr] , %rax 会将 addr 赋给 rax 寄存器。编译器经常使用 leaq 来进行一些灵活的算术运算。
3.4 移位操作
移位操作有左移以及右移,左移指令有两个名字 SAL 和 SHL 。两者效果是 一样的,将右边填上 0。而右移指令则不同 ,SAR 执行算术移位,即右移的时候左边填充符号位的值,负数为 1 ,正数为 0 ,SHR 则执行逻辑右移,左边填充 0 。此外,由于乘法的消耗较大,所以很多时候代码中的乘法编译器可能会转换成 移位加上加减法,如 x * 3 可能转换成 x << 1 + x 。
4 控制
在 C 语言中,有一些结构,如条件语句,循环语句和分支语句,要求有条件的执行,根据数据测试的结果来决定操作执行的顺序,机器代码提供两种基本的低级机制来实现有条件的行为,测试数据值,然后根据测试的结果来改变控制流或者数据流。
4.1 条件码
除了整数寄存器,CPU 还维护着一组单个位的条件码寄存器,它们描述着最近的算术或者逻辑操作的属性。可以检测这些寄存器来执行条件分支指令。为了方便说明,假设有 t = a + b 。 然后再看执行过此等式后,常用的条件码如何生效 :
- CF : 进位标志。最近的操作使最高位产生了进位。可用来检查无符号操作的溢出。如 (unsigned) t < (unsigned) a 。
- ZF : 零标志。最近的操作得出的结果为 0 。 如 ( t == 0) 。
- SF : 符号标志。最近的操作结果为负数。如 ( t < 0 ) 。
- OF : 溢出标志。最近的操作导致一个补码正/负溢出。如 ( a < 0 == b < 0 ) && ( t < 0 != a < 0) 。
在整数算术操作指令中,只有 leaq 指令不改变任何条件码,因为它是用来地址计算的。除此之外其他的整数算术操作都会设置条件码。对于逻辑操作,例如 XOR ,进位标志和溢出标志都被设置为 0 。对于移位操作,进位标志将设置为最后一个被移出的位,而溢出标志设置为 0 。除了这些整数算术指令之外,还有两类指令只设置条件码,不影响其他寄存器,即 TEST 指令和 CMP 指令 :
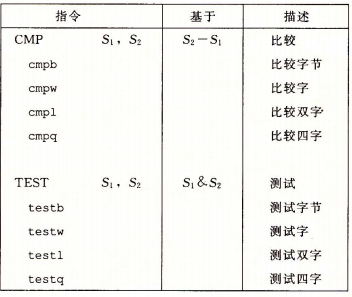
条件码通常不会直接读取,常用的使用方法有三种:
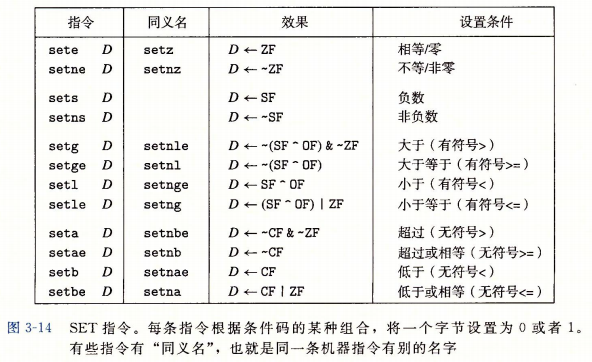
- 可以根据条件码的组合,将一个字节设置为 0 或者 1。 如下图中的 SET 指令。
- 可以条件跳转到程序的某个其他的部分。
- 可以有条件的传送数据
4.2 跳转指令
正常情况下,指令是按序执行的,跳转指令会导致执行切换到程序的另一个全新的位置。在汇编代码中,这些位置目的地通常使用一个 Label 来表示,如下 :
movq $0 , %rax jmp .L1 movq (%rax), %rdx //跳过引用空指针 .L1 popq %rdx
jmp 指令有两种跳转方式,一种是直接跳转,如上述代码,直接跳转到 label 的位置,另外一种则是间接跳转,类似于解引用指针的方法,如 jmp *%rax ,或者 jmp *(%rax) 。jmp 指令具体的条件及描述如下 :

此外我们需要关注一下跳转指令的编码,因为这涉及到后续章节的内容,跳转指令的格式大致为 (指令码 + 目的地址), 主要有两种地址编码方式,一种是相对地址编码,即目的地址的值为跳转指令地址于目标指令地址的偏移量,另一种则是绝对地址编码,顾名思义,即目的地址的值为目标指令的地址。
4.3 条件传送指令
实现条件操作的传统方法是通过使用条件控制转移。根据条件的结果来决定程序的执行路径,在现代的处理器上,这可能会非常低效,所以另一种替代的策略是使用数据的条件转移,这种方法计算一个条件操作的两种结果,然后再根据条件是否满足从中选择一个。但是这种策略只有在某些受限制的情况才可行,我们可以用一条简单的条件传送指令来实现它,这种条件传送指令更符合现代处理器的特性。用如下代码来进行说明:
// absdiff code long absdiff(long x, long y) { long result; if(x < y) result = y - x; else result = x - y; return result; } // cmovdiff code long cmovdiff(long x, long y) { long rval = y - x; long eval = x - y; long ntest = x >= y; if (ntest) rval = eval; return rval; } // absdiff asm code absdiff : movq %rsi , %rax subq %rdi , %rax // rval = y - x movq %rdi , %rdx subq %rsi , %rdx // eval = x - y cmpq %rsi , %rdi // 比较 x 和 y cmovge %rdx , %rax // if >= , rval = eval ret
上述代码中,cmovdiff 描述了 absdiff 汇编代码所做的事情,可以看到,汇编代码中并没有做出 jmp 指令之类的跳转操作,反而出现了一条 cmovge 指令,cmovge 指令判断 cmpq 指令执行后的条件码,通过指令后缀可以看到,ge 表示大于等于,即 x >= y 的时候,将已经计算好的 eval 存在了返回值寄存器 %rax 中,这段代码是预先计算好了两个结果,然后最后做一个简单的条件判断来决定返回值。为什么这样的效率会更高呢?原因如下:
处理器通过流水线来获得更高的性能,在取一条指令的同时,执行前一条指令的算术运算,要做到这一点,要求事先能够确定要执行的指令序列,这样才能保持流水线中充满了待执行的指令,而当处理器遇到分支跳转的情况时,需要等待分支条件求值完成之后才能继续往前走,为了提高效率,处理器采用了十分精密的分支预测逻辑来猜测每条跳转指令是否会执行,只要猜测可靠,也能保证流水线中充满了待执行的指令,但是一旦猜错,需要丢掉处理器为该跳转指令所做的所有工作,相当于处理器白干了,然后再从正确的位置重新填充流水线,这个过程的消耗是十分大的(约浪费 15 ~ 30 个时钟周期)。
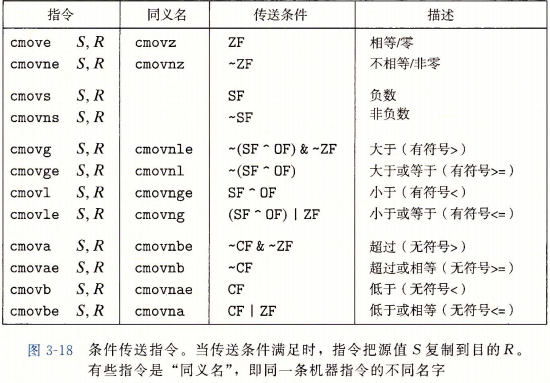
基于条件传送指令的代码,其格式都大致如下:
v = then-expr; ve = else-expr; t = test-expr; if (!t) v = ve;
可以看到,这种格式会对 then-expr 和 else-expr 进行求值,这就会出现一个问题,考虑下面这种函数实现
long cread(long *xp) { return (xp ? *xp : 0); } cread: movq (%rdi), %rax // v = *xp testq %rdi , %rdi // test x movl $0 , %edx // ve = 0 cmove %rdx, %rax // if x == 0 , v = ve ret // return ve
该函数看上去很适合使用条件传送指令的写法,但是实际上,当 xp 为 空指针时,汇编代码的第一句就会使程序产生 segment fault ,因为条件传送指令会对两个分支的结果都进行计算,所以这里必须使用分支代码的方法来编译这段代码(PS : 这里只是假设使用条件传送指令的写法,实际上编译这个函数的时候可以看到其汇编代码采用的是分支跳转的方法去实现的)。此外,个人感觉编译器在使用条件传送指令方面是比较保守的,因为经过测试,写了几种个人认为很适合用条件传送指令实现的函数,编译器都采用了条件传送的方法。
4.4 switch 语句
switch 开关语句可以根据一个整数索引值进行多重分支,在处理具有多种可能结果的测试时,这种语句是十分有用的,不仅提高了代码的可读性,而且通过使用 跳转表 这种数据结构使实现更加高效。跳转表是一个数组,表项 i 是一个代码段的地址,这个代码段实现当开关索引值等于 i 时程序应该执行的操作,程序代码用开关索引值来执行一个跳转表内的数组引用,确定跳转指令的目标。和使用一组很长的 if-else 语句相比,跳转表的优点是执行开关语句的时间与开关情况的数量无关。GCC 根据 case 的数量和以及索引值的稀疏程度来翻译开关语句,当 case 数量比较多时,如 4 个以上的 case ,并且 这些 case 的索引值跨度比较小时,就会使用跳转表。

上图展示了一个 switch 的例子,以及翻译成跳转表格式之后的代码,可以看到,原始的 C 代码中,索引值的区间为 [100, 106],由于跳转表是数组形式的,为了节约空间,跳转表格式的代码将范围缩减至 [0, 6] ,这样只需7个指针大小的空间就足够了,然后根据参数 n - 100 来决定执行哪个 case。下面展示使用跳转表结构的汇编代码是怎样的(PS:跳转表结构的汇编代码每个 case 的顺序应该是与原始代码一致的):

下图是跳转表的汇编声明,这些声明表示在 .rodata(read-only data)的目标代码文件的段中,有一组 7 个四字(8个字节)的数据,每个字的值都是与指定的汇编代码标号(如 L3 )相关练的指令地址。标号 L4 标记出这个分配地址的起始。与这个标号相对应的地址会作为间接跳转(第 5 行)的基地址。(PS:标号只是一个符号,其后面的数字没有任何意义,只是用来区分,L3 并不代表它是第 3 个case。)

5. 过程
过程是软件中一种很重要的抽象,它提供了一种封装代码的方式,用一组指定的参数和一个可选的返回值实现了某种功能。然后可以在程序中不同的地方调用这个函数。要提供对过程的机器级支持,需要处理许多不同的属性。为了讨论方便,假设过程 P 调用过程 Q , Q 执行后返回到 P。这些动作包含以下机制:
- 传递控制:在进入过程 Q 的时候,程序计数器(PC,寄存器则为 %rip)必须被设置为 Q 的代码的起始位置,然后在返回时,要把程序计数器设置为 P 中调用 Q 后面那条指令的地址。
- 传递数据:P 必须能够向 Q 提供一个或者多个参数,Q 必须能够向 P 返回一个值。
- 分配和释放内存:在开始时,Q 可能需要为局部变量分配空间,而返回的时候也必须要释放这些空间。
5.1 运行时栈
C 语言过程调用机制的一个关键特性在于使用了栈数据结构提供的后进先出的内存管理原则,大多数其他语言也是如此。一个典型的运行时栈结构如下图所示:
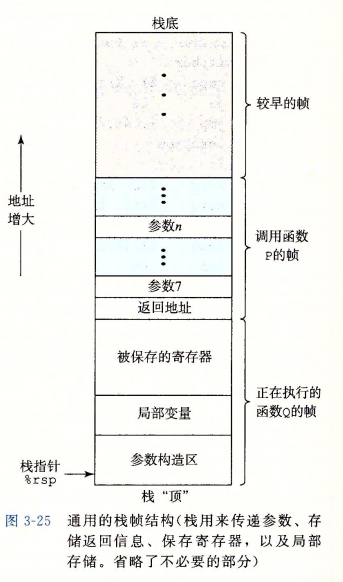
当 x86-64 过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间。这部分称为过程的栈帧。当过程 P 调用过程 Q 的时候,会将返回地址压入栈中,指明当 Q 返回时,要从 P 的哪个位置开始执行。这个返回地址属于 P 的栈帧,通常来说,大多数过程的栈帧都是定长的,在过程开始就分配好了。但是有些过程需要变长的栈帧,如在一个函数中动态分配数组(动态分配数组一般通过 malloc 或者 new ,此时是从堆上分配内存,而 alloc 可以从栈上动态分配内存,且无需手动释放),这个问题会在后面讨论。通过寄存器,过程 P 可以传递最多 6 个整数值(指针和整数),如果需要更多的参数,则需要在 P 的栈帧中保存好这些参数。这里也延申出一个问题,非整数型参数是如何传递的呢?实际上也是通过调用者的栈帧去传递的。
5.2 转移控制
将控制从函数 P 转移到函数 Q 只需要简单的把程序计数器(PC)设置为 Q 的代码的起始位置。不过,当稍后从 Q 返回的时候,处理器必须记录好它需要继续 P 的执行代码的位置。在 x86-64 机器中,这个信息是用指令 Call Q 调用过程 Q 来记录的。该指令会把地址 A (即原先过程函数 P Call Q 指令的下一条指令地址),压入栈中,并且设置 PC ,压入的地址 A 称为 返回地址 。下表为 call 和 ret 指令的一般形式:

可以看到 call 指令有一个目标,即指明被调用过程起始的指令地址。同跳转一样,调用可以是直接的,也可以是间接的。call 指令的作用是将目标指令的地址压入栈中,并且设置程序计数器,假设目标指令地址为 0x400000, 那么实际操作起来等同如下指令:
sub $0x8, %rsp mov %rip , %rsp mov *0x400000, %rip
而 ret 指令则等价于如下指令
mov %rsp , %rip add $0x8, %rsp
关于过程调用与返回更具体的例子可以参考以下代码:

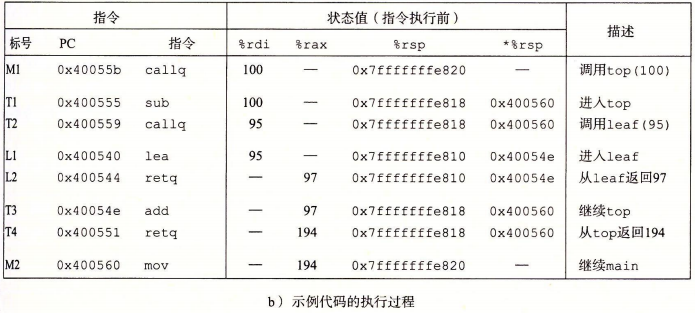
5.3 数据传送
当调用过程时,除了控制传递之外,过程调用还可能将数据作为参数传递,而从过程返回还有可能包括返回一个值。x86-64 中,大部分过程间的数据传送是通过寄存器实现的,可以通过寄存器最多传递 6 个整型(整数和指针)参数。寄存器的使用是有特殊顺序的,具体的规则如下所示:
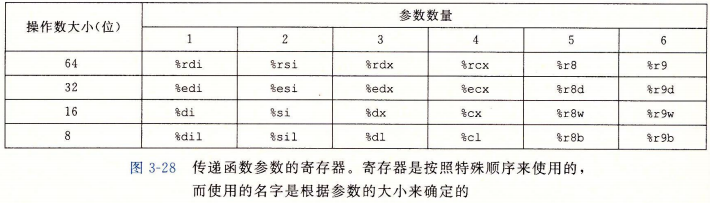
当函数参数大于 6 个整型参数时,超出部分需要通过栈来传递。假设过程 P 调用过程 Q , 有 n 个整型参数,且 n > 6。那么 P 的代码分配的栈帧必须要能容纳 7 到 n 号参数的存储空间(此时意味着,栈上可能有大约两份 7~n 号参数的变量),且参数 7 是位于栈顶,即参数是从右到左,依次入栈的。所有的数据大小都向 8 的倍数对齐。参数到位以后,程序就可以执行 call 指令进行控制转移到过程 Q 了。过程 Q 可以通过寄存器访问参数,有必要的话也可以通过栈访问。(PS: 建议实际写一个类似书中图 3-29 的函数去进行测试,查看 -Og 优化级别的汇编代码,有助于加深理解)
5.3 栈上局部存储
有些时候,局部数据必须存放在内存中,常见的情况包括:
- 寄存器不够存放所有的本地数据。
- 对一个局部变量使用地址运算符 “&” , 因此需要为它产生一个地址。
- 某些局部变量是数组或者结构,因此必须能够通过数组或结构引用被访问到。
一般来说,过程都是通过减小栈指针(%rsp)在栈上分配空间。分配的结果作为栈帧的一部分。寄存器组是唯一被所有过程共享的资源,虽然在给定时刻只有一个过程是活动的,我们仍然必须确保当一个过程(调用者)调用另一个过程(被调用者)时,被调用者不会覆盖调用者稍后会使用的寄存器值。因此,x86-64 采用了一组统一的寄存器使用惯例,所有的过程都必须遵循。
依据惯例,寄存器 %rbx, %rbp 和 %r12 ~ %r15 被划分为 被调用者保存寄存器 。当过程 P 调用过程 Q 时, Q 必须保存这些寄存器的值,保证它们的值在 Q 返回到 P 时与 Q 被调用时是一样的。过程 Q 保存一个寄存器的值不变,要么就是根本不去改变它,要么就是把原始值压入栈中(push),改变寄存器的值,然后在返回前从栈中弹出旧值(pop)。
然后其他的寄存器,除了 %rsp 栈指针 , 都分类为 调用者保存寄存器 。 这就意味着任意函数都能随意修改它们。
6. 数组分配与访问
C 语言中的数组是一种将标量数据聚集成更大数据类型的方式。 C 语言实现数组的方式非常简单,因此很容易翻译成机器代码。 C 语言的一个不同寻常的特点是可以产生指向数组中元素的指针,并对这些指针进行运算。在机器代码中,这些指针会被翻译成地址计算。
6.1 指针运算
C 语言中允许对指针进行运算,而计算出来的值会根据该指针引用的数据类型的大小进行伸缩。也就是说,如果 p 是一个指向类型为 T 的数据的指针,p 的值为 xp ,那么表达式 p + i 等价于 xp + sizeof(T) * i 。现在扩展一下这个例子,假设整型数组 E 的起始地址和整数索引 i 分别存放在寄存器 %rdx 和 %rcx 中。下面是一些与 E 有关的表达式。此外给出了每个表达式的汇编代码实现,结果存放在寄存器 %eax (结果是数据)或者 %rax (结果为指针)。

6.2 嵌套数组
当我们定义一个二维数组 int A[5][3] ,我们可以用 A[0][0] 到 A[4][2] 来引用。数组元素在内存中按照 “行优先” 的顺序排列,所以可以得出下图:

通常来说,对一个声明为 T D[R][C] 的数组,他的数组元素 D[i][j] 的内存地址为 &D[i][j] = xD + sizeof(T) * (C * i + j)。考虑前面定义的 5 * 3 的整型数组 A 。假设 xA , i 和 j 分别在寄存器 %rdi ,%rsi 和 %rdx 中。然后,可以用下面的代码将数组元素 A[i][j] 复制到寄存器 %eax 中。可以看到,这段汇编代码的计算公式为 xA + 12 * i + 4 * j = xA + 4 * (3 * i + j) 。
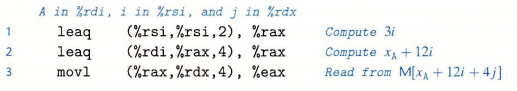
定义一个数组的时候,我们通常都是诸如 int A[5] 这样的形式,实际上我们可以使用类似下面的代码:
#define N 5 typedef int A[N]
这样如果需要修改这个值,只需简单修改 define 声明即可。那么这里又引申出一个问题,为什么不使用 const 来定义 N 呢,因为 C 语言的 const 和 define 还是有些区别的,具体可以参考 https://stackoverflow.com/questions/4024318/why-do-most-c-developers-use-define-instead-of-const 。
7. 异质的数据结构
C 语言提供了两种将不同对象组合到一起创建数据类型的机制,结构(struct)和 联合(union)。结构可以将多个对象集合到一个单位中,而联合允许使用几种不同的类型来引用一个对象。
7. 1 结构
struct 可以把几种不同的对象聚合到一个对象中,用名字来引用结构的各个组成部分。类似于数组的实现,结构的所有组成部分都存放在内存中一段连续的区域内,而指向结构的指针就是结构第一个字节的地址。编译器维护关于每个结构类型的信息,指示每个字段的字节偏移。它以这些偏移作为内存引用指令中的位移,从而产生对结构元素的引用。
考虑这样的结构声明:
struct rec{ int i; int j; int a[2]; int *p; };
这个结构的结构图大致如下:

为了访问结构的字段,编译器的代码要在结构的地址上加上适当的偏移,例如,假设 struct rec* 类型的变量 r 放在寄存器 %rdi 中。那么下面的代码将元素 r->i 复制到元素 r->j :
// %rdi = r ,r 是指针 movl (%rdi), %eax // 获取 r->i movl %eax, 4(%rdi) // r->j = r->i
再举一个例子,r->p = &(r->a[r->i + r->j]) ,其汇编代码如下:
// %rdi = r movl 4(%rdi), %eax // 获取 r->j addl (%rdi), %eax // r->j = r->j + r->i cltq // 符号扩展%eax 到 64 位 leaq 8(%rdi, %rax, 4), %rax // 计算 &r->a[r->i + r->j] movq %rax, 16(%rdi) // 结果保存到 r->p
7. 2 联合
联合提供了一种方式,允许以多种类型来引用一个对象。联合声明的语法与结构的语法一样,只不过语义相差比较大。它们是用不同的字段来引用相同的内存块。考虑下面的声明:
struct S3{ char c; int i[2]; double v; }; union U3{ char c; int i[2]; double v; }
编译后,字段的偏移量,数据类型 S3 和 U3 的完整大小如下:

可以观察得出,不管访问 U3 的哪个字段,都是从起始位置开始,此外,一个联合的总大小等于它最大字段的大小。假如我们实现知道对一个数据结构中的两个不同字段的使用是互斥的,那么将两个字段声明为 union 可以减少分配的空间的总量。
联合还可以用来访问不同的数据类型的位模式,例如,假设我们使用简单的强制类型转换将一个 double 类型的 值 d 转换为 unsigned long 类型的值 u , unsigned long u = (unsigned long) d; 值 u 会是 d 的整数表示。除了当 d = 0.0 之外,u 的位表示与 d 的很不一样。再看下面这段代码,从一个 double 产生一个 unsigned long 类型的值:
unsigned long double2bits(double d){ union{ double d; unsigned long u; } temp; temp.d = d; return temp.u; }
此时得到的 u 会与 d 具有相同的位表示,但是值 u 就不会是值 d 的整数表示了。再举另一个例子:
double uu2double(unsigned word0, unsigned word1){ union{ double d; unsigned u[2]; }temp; temp.u[0] = word0; temp.u[1] = word1; return temp.d; }
假如在小端法机器上,参数 word0 是 d 的低位 4 个字节,而 word1 是高位 4 个字节,大端法机器上则相反。因为 temp 数组的赋值已经决定了它的两个元素的地址了,word0 存放在起始位置,word1 顺延起始地址存放,而小端法是解读地址较小一端为低位字节。
8. 数据对齐
许多计算机系统对基本数据类型的合法地址做出了一些限制,要求某种类型对象的地址必须是某个值 K (通常是 2 ,4 或者 8 )的倍数。这种对齐限制简化了形成处理器和内存系统之间接口的硬件涉及。例如,假设一个处理器总是从内存中取 8 个字节,则地址必须为 8 的倍数。如果我们能保证将所有的 double 类型数据的地址对齐成 8 的倍数,那么就可以用一个内存操作来读或者写值了。否则,我们可能需要执行两次内存访问,因为对象可能被放在两个 8 字节内存块中。
虽然无论数据是否对齐,x86-64 都能正常工作,但是对齐数据有利于提高内存系统的性能。对齐原则是任何 K 字节的基本对象的地址必须是 K 的倍数。可以看到这条原则会得到如下对齐:

对于结构体,编译器可能需要在字段的分配中插入间隙,以保证每个元素都满足对齐要求,以下面的代码举例:
struct S1{ int i; char c; int j; };
假如在不对齐的情况下,那么这个结构体的大小为 9 字节,结构图如下:
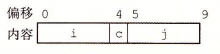
这样的结构无法满足字段 i 和 j 的 4 字节对齐要求。因此编译器在字段 c 和 j 之间插入一个 3 字节的间隙:

此时, j 的偏移量为 8 ,整个结构体的大小扩大为 12 个字节,保证了这个结构体是对齐的。此外,编译器需要保证 struct S1 * 类型的指针 p 都满足 4 字节对齐。因为其首字段 i 是 int 类型,大小为 4 个字节,这样能保证 p->i 总是满足 4 字节对齐的。
假如我们改变结构体字段定义的顺序成如下代码:
struct S1{ int i; int j; char c; };
那么此时的结构体无需插入在中间插入无用的间隙,只要保证结构体的起始位置满足 4 字节的对齐要求,那么仍然能满足对齐,但是假如定义了一个该结构体的数组。那么此时需要在结构末尾增加 3 个字节,如下图所示:

因为分配 9 个字节无法满足数组的每个元素的对齐要求,假如为 9 个字节,那么元素的地址分别为 x, x + 9 , x + 18 , x + 27。但是如果多分配了 3 个字节,那么此时数组元素的地址分别为 x, x + 12 , x + 24 , x + 36 ,在 x 的地址为 4 的倍数的情况下,显然只有后者可以满足对齐限制。
10. 缓冲区溢出攻击
假设有如下代码:
char *gets(char *s) { int c; char *dest = s; while((c = getchar()) != '\n' && c !=EOF) *dest++ = c; if (c == EOF && dest == s) return NULL; return s; } void echo() { char buf[8]; gets(buf); puts(buf); }
可以看到,gets 函数从标准输入中读取一行,在遇到换行回车字符或者错误情况是停止。它将这个读取的字符串复制到 s 指明的位置,并且在字符串结尾加上 null 字符。gets 的问题在于它无法确定是否有足够的空间保存字符串,在 echo 函数中,我们分配了一个很小的空间区调用 gets 。下面是 echo 的汇编代码以及 echo 的栈帧:

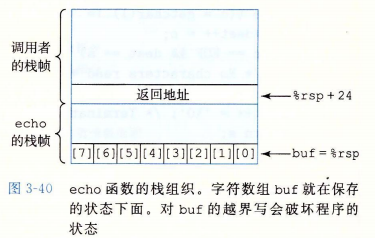
当我们输入的字符数量过多时,就会破坏 echo 栈帧的结构,下图时输入字符的数量以及对应造成的破坏效果:

假如在栈可执行的情况下,我们可以在栈上注入攻击代码,然后通过覆盖调用者的栈帧的返回地址,来达到调用我们的攻击代码的目的。如果说栈不可执行的情况下,我们也可以通过覆盖返回地址,进行 ROP 攻击,更多关于缓冲区攻击的内容,建议完成本书对应的 attack lab , 会大有收获。
那么如何多抗缓冲区溢出攻击呢,主要有几种机制:
- 栈随机化:
为了注入攻击代码,攻击者除了插入代码,还需要插入指向这段代码的指针,这个指针也是攻击字符串的一部分,意味着这个指针是存放在栈上的,过去,栈的位置是相当固定的,因此指针的值可以直接写死在字符串中。
栈随机化使栈的位置每次运行都会变化,这意味着每次运行程序的时候,注入代码的位置是会改变的,这样攻击者如果直接在字符串中写入地址,是很难直接调用到注入的攻击代码的。
这个机制的实现方式是在程序开始时,在栈上分配一段 0 ~ n 字节之间的随机大小的空间,可以使用 alloca 函数进行分配,然后不使用这块空间,n 的设计也需要合理,才不至于浪费空间,又能保证栈地址变化难以预测。
但是这种机制仍有方法进行破解,通过在实际的攻击代码之前注入很长的一段 nop 指令,这条指令除了使程序计数器加一,使之指向下一条指令之外,没有其他效果,这个 nop 指令序列被称为 nop sled ,这样我们覆盖返回地址的时候,只要预测的地址刚好落在 nop sled 上,那么程序就会一直执行 nop 指令直到我们的攻击代码处。
假设我们建立一个 256(2^8) 字节的 nop sled ,那么枚举 32768(2 的 15 次方)个起始地址,就能破解 n = 2^23 的随机化(32 位 linux 的地址变化范围大小约为 2^23 , 64 位为 2^32)。
- 栈破坏检测:
计算机能检测到栈何时被破坏,其思想是在栈帧任何局部缓冲区与栈状态之间存储一个特殊的 canary 值,如下图所示:
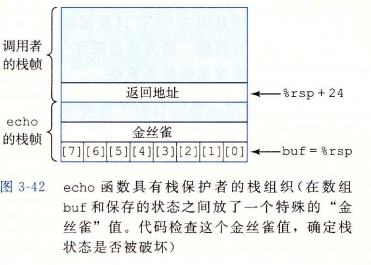
由于这个值实在程序每次运行时随机产生的,因此攻击者没有简单的方法能够获取它,在恢复寄存器状态和从函数返回之前,程序会检查这个值是否被改变了,如果是,则程序异常终止。( PS:可以通过 “-fno-stack-protector” 来阻止这种代码产生)
由于该值被存放在一个特殊的段中,标志为只读,所以攻击者不能覆盖存储的值,在返回的时候,函数会校验栈上的这个值与它存放在特殊段中的值。这种栈保护机制很好的防止了缓冲区溢出攻击破坏存储在程序栈上的状态。只会带来很小的性能损失,而且 GCC 只会在函数中有局部 char 类型缓冲区的时候才插入这样的代码。
- 限制可执行代码区域
虚拟的内存空间分为页,典型的每页具有 2048 或者 4096 个字节。许多系统允许控制三种访问形式:读(从内存中读数据),写(存储数据到内存)和执行(将内存的内容看作机器级代码)。之前 x86 体系将读和执行访问控制合并为一个 1 位的标志,这样可读的页也是可执行的。而栈必须是可读写的,故栈上也是可执行的。而最近 AMD 和 intel 引入了不可执行的位,将读与执行分开,因此栈可以被标记为可读写不可执行。这种机制可以让注入的攻击代码无法被执行。
11. 变长栈帧
假设有如下代码:

为了管理变长栈帧,x86-64 使用寄存器 %rbp 作为帧指针,使用帧指针时,上述代码的栈帧结构如下:

可以看到代码必须把 %rbp 之前的值先 push 到栈中,因为它是一个被调用者保存寄存器。然后在函数的整个执行过程中,都使得 %rbp 指向那个时刻栈的位置,然后用固定长度的局部变量相对于 %rbp 的偏移量来引用它们。
12. 浮点代码
处理器的浮点体系结构包括以下几个方面:
- 如何存储和访问浮点数值。通常时通过某种寄存器方式来完成。
- 对浮点数据操作的指令。
- 向函数传递浮点数参数和从函数返回浮点数结果的规则。
- 函数调用过程中保存寄存器的规则(调用者保存和被调用者保存)。
12.1 YMM 寄存器

12.2 浮点传送和转换操作
不论数据对齐与否,这些指令都能正确执行,但代码优化规则建议 32 位内存数据满足 4 字节对齐, 64 位数据满足 8 字节对齐。
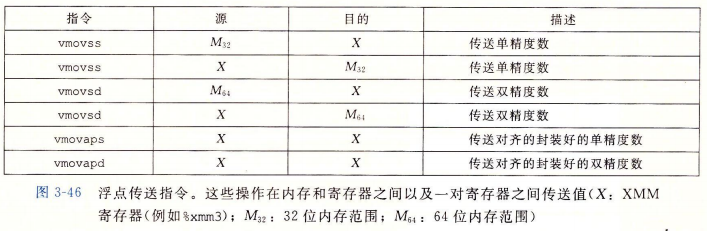
下面给出了浮点数和整数数据类型之间以及不同浮点格式之间进行转换的指令集合。把浮点数转换成整数时,指令会执行截断,把值向 0 进行舍入。
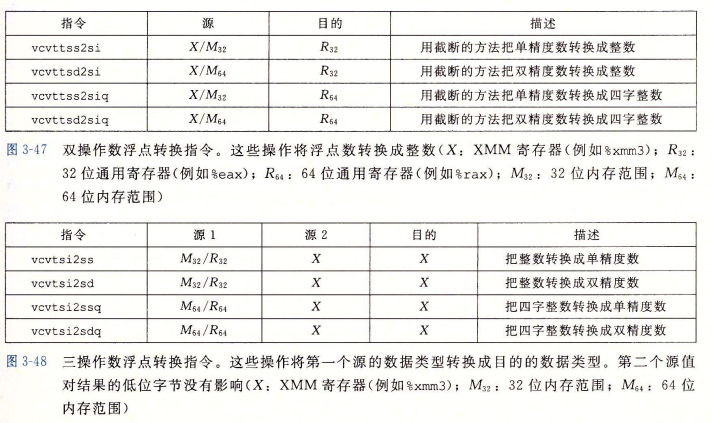 图 3-48 中的指令把整数转换成浮点数。它使用的是三操作数格式,有两个源和一个目的。第一个操作数读自于内存或者一个通用目的寄存器。这里可以忽略第二个操作数,因为它的值只影响结果的高位字节。而我们的目标必须是 XMM 寄存器。在最常见的使用场景中,第二个源和目的操作数都是一样的,如:
图 3-48 中的指令把整数转换成浮点数。它使用的是三操作数格式,有两个源和一个目的。第一个操作数读自于内存或者一个通用目的寄存器。这里可以忽略第二个操作数,因为它的值只影响结果的高位字节。而我们的目标必须是 XMM 寄存器。在最常见的使用场景中,第二个源和目的操作数都是一样的,如:
vcvtsi2sdq %rax, %xmm1, %xmm1
这条指令从 %rax 读取一个长整数,然后把它转换成数据类型 double ,并把结果存放到 %xmm1 的低字节中。
12.3 过程中的浮点代码
在 x86-64 中,有如下规则:
- XMM 寄存器 %xmm0 ~ %xmm7 最多可以传递 8 个浮点参数。按照参数列出的顺序使用这些寄存器。可以通过栈传递额外的浮点参数。
- 函数使用寄存器 %xmm0 来返回浮点值。
- 所有的 XMM 寄存器都是调用者保存。
12.4 浮点运算操作
每条指令都有一个(S1)或者两个(S1,S2)源操作数和一个目的操作数,第一个源操作数 S1 可以是一个 XMM 寄存器或者一个内存位置。第二个源操作数和目的操作数必须是 XMM 寄存器。

12.5 浮点位级操作

12.6 浮点比较操作

浮点比较指令会设置 3 个条件码,ZF(零标志位),CF(进位标志位)和 PF(奇偶标志位)。奇偶标志位比较少见,它只有在最近的依次算术或逻辑运算产生的值的最低位字节是偶校验的(即这个字节有偶数个 1)才会被设置。 条件码的设置条件如下:
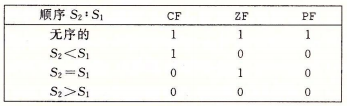
当任一操作数位 NaN 的时候,就会出现无序的情况,可以通过奇偶标志位发现这种情况。
12.7 浮点代码小结
我们可以看到,浮点数的汇编代码其实和整数的汇编代码类似,它们都使用一组寄存器来保存和操作数据值,也都使用这些寄存器来传递函数参数。
13 小结
这一章主要了解了机器级别的编程。机器级程序和它们的汇编代码表示,与 C 程序的差别很大。各种数据类型之间的差别很小。程序是以指令序列来表示的,每条指令都完成一个单独的操作。部分程序状态,如寄存器和运行时栈,对程序员来说时直接可见的,编译器必须使用多条指令来产生和操作各种数据结构,以及实现像条件,循环和过程这样的控制结构。这一章比较长,建议阅读完这一章之后去做 attack lab 以及 bomb lab ,这里附上 lab 的网址:http://csapp.cs.cmu.edu/3e/labs.html ,attack lab 可以加深对栈的理解,而 bomb lab 可以提高对汇编代码的阅读能力。在此建议使用 linux 环境来实现书中的代码,因为书中的主要实验环境也是在 linux 下,而且阿里云或者腾讯云都有学生优惠云服务器,一年 100 多,一个月不到 10块钱,性价比十足,此外,我个人推荐使用 GDB 来调试程序,GDB 的 layout 指令可以以图形界面同时查看程序的汇编代码和寄存器。并且可以单步调试汇编代码。关于这一章的笔记写的比较长,如果有什么问题可以在评论中指出,谢谢~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号