
ElasticSearch倒排索引使用算法FST(Finite State Transducers)原理
ElasticSearch倒排索引使用算法FST(Finite State Transducers)--有穷状态转换器 原理
写在前面:今天整理ES知识点的时候,看到倒排索引提到了一个FST算法,没有听说过,所以找帖子弄明白了原理,还是有点绕的,在此记录一下
引用:Finite State Transducers
本文的图都来自于引用博客,侵删;另外非常感谢原博主的分享,写的很好~ 最后论文链接在此
FST算法概述:
- FST是一种类似于字典树的数据结构,但是它是k:v结构的,能够根据索引快速查询,查询速度不会超过O(索引长度),它在ElasticSearch的倒排索引中有用到
算法明细:
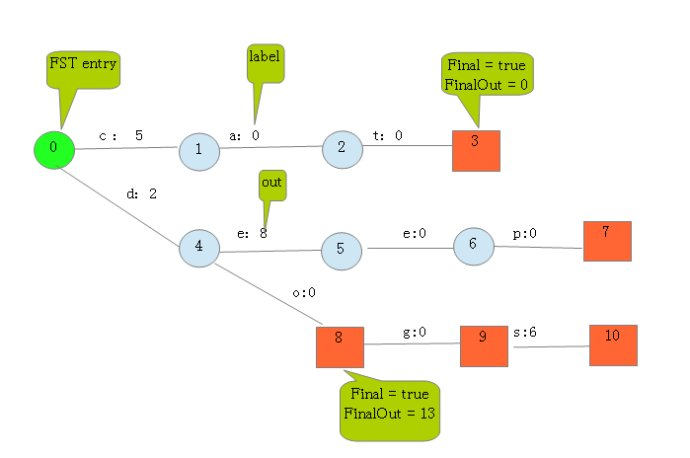
- 首先,它最终的数据结构图示如下图所示
![]()
- 在此录入的样例数据为:
sample_dict = {
"cat":5,
"deep":10,
"do":15,
"dog":2,
"dogs":8
}
-
录入步骤及解释如下:
1.从cat开始录入,查询开头是否有重合前缀,发现没有,则第一条边c的权重设置为cat对应value,然后继续插入a和t,因为cat整体value为5,所以a和t边权重为0,最后t指向一个末尾结点,该节点会被标记为末尾(因为前缀树的话会有很多重合,需要标记哪里有结尾)然后该节点会包含当前结束的索引项(cat)在所有路径权重和和初始权重的差值(这里为5-(5-0-0)=0)
![]()
2.开始录入deep,查询开头是否有重合前缀,发现没有,则依照步骤1的方法直接录入,从起点到第一个节点的路径权重为depp的value->10,然后同样,最后的末尾结点包含两个东西,一个末尾结点标记,一个余下的权重,前者为True,后者为0,图示如下
![]()
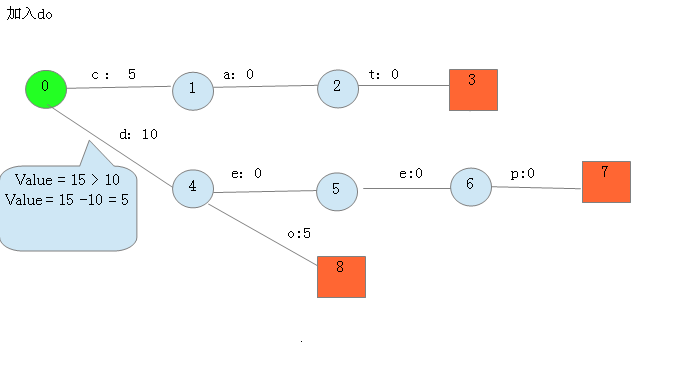
3.开始录入do,查询开头是否有重合前缀,发现有,但是权重10小于当前词(do)的权重,所以不做处理,但是把temp权重(用于计算余下的权重)设置为5,因为有5没有分配,继续往下走,查询是否有前缀重合,发现没有,则新建结点,然后将该条路径的权重设置为5,然后末尾结点同样包含两个东西-->一个标记一个权重余量,此处为0,图示如下,
![]()
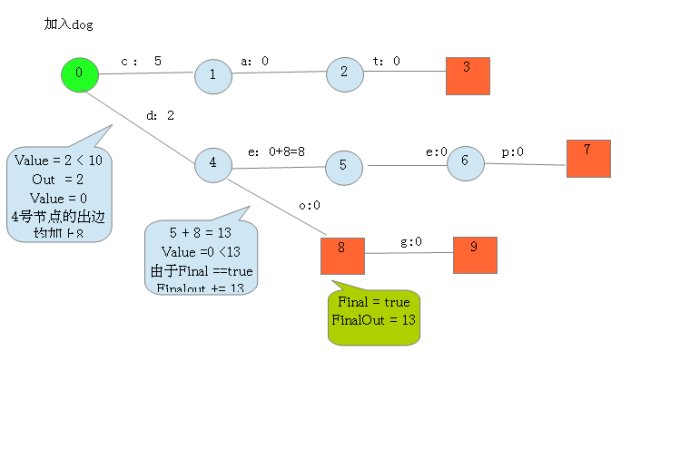
4.开始录入dog,查询开头是否有重合前缀,发现有,然后比对权重,发现当前权重2<10,按照之前的分配方式不行,所以重新设置第一个权重为2,这样会导致之前的权重分配方案失败,怎么办呢,计算改变的量,此处为8(10-2),则需要下一个的出路径权重全部加上8(当然,如果下一个节点就有被标记为末尾结点,则末尾结点的余量也要加上响应的值),这时deep中的第一个e的权重从0变成8(符合条件,所以不需要继续传播),然后do中的o权重本来为5,现在变为5+8=13,然后此时分配到了dog的o,dog中o的权重余量为0,0小于当前权重13,所以还需要继续重新赋值,所以o被重置权重为0,又因为下一个节点被标记为结尾节点,所以此节点的末尾权重余量从0变为13-->(0+13),然后继续传播,查询是否有前缀,发现没有(g),然后新建结点(因为到末尾,所以是末尾结点)设置中间路径权重为0(因为dog的余量就为0),且末尾结点的权重余量亦为0。至此dog加入完毕,目前状态图如下
![]()
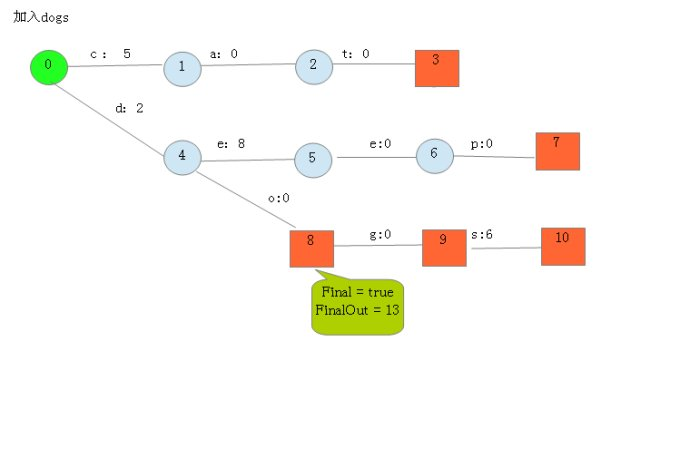
5.开始录入dogs,查询是否有前缀,发现有,2<8,此时不需要重新赋值权重,但是dogs余量变为6,继续传播-->查询是否有前缀?发现有,o,当前权重0<6,不需要重新分配,继续传播-->查询是否有前缀,发现有,g当前权重0<6,不需要重新分配,继续传播-->查询是否有前缀,发现没有,新建结点s,设置路径权重为6,并新建末尾结点,结点包含两个东西,一个末尾标记,一个权重余量,前者为true,后者为0,最终状态如图所示:
![]()
-
这就是算法的思想,根据构建出来的数据结构,我们可以根据字符串轻松查询到对应的value,复杂度不会超过key的长度


以上,
希望对后来者有所帮助

 浙公网安备 33010602011771号
浙公网安备 33010602011771号