分库分表实践-Sharding-JDBC
最近在做一些涉及分库分表的需求,正好周末有点时间就简单做下总结,也方便自己以后查看。
本文只讲述使用Sharding-JDBC做分库分表的一些实践经验,如果有错误欢迎大家指出。
什么是Sharding-JDBC

Sharding-jdbc是当当网开源的一款客户端代理中间件。Sharding-jdbc包含分库分片和读写分离功能。对应用的代码没有侵入型,几乎没有任何改动,兼容主流orm框架,主流数据库连接池。目前属于Apache的孵化项目ShardingSphere。
Sharding-jdbc定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
官方文档地址
ShardingSphere:https://shardingsphere.apache.org/
GitHub的地址:https://github.com/apache/incubator-shardingsphere
一些建议和说明
不过我这里建议大家可以简单过下官方文档,因为文档并不全面或者说感觉并不是最新的。
建议大家重点可以放在git上官方的examples
目前官方最新的版本是4.0,如果使用springboot创建,可以使用下面的依赖即可。
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0</version>
</dependency>
Sharding-jdbc功能强大,但是本文重点在于下面几点,未涉及的地方可以翻阅文档查看。
1、单库分表
2、分库分表(含分库单表)
3、分表后的查询
4、分表事务处理
无论上述哪种分库亦或是分表类型,核心无非是下面几个配置:
1、配置数据源,明确你有多少个数据源
2、定义表名,分表的逻辑表名(t_order)和所有物理表名(t_order_0,t_order_1)
3、定义分库列以及分库算法
4、定义分表列以及分表算法
代码实现
单库分表
sharding-jdbc优势就是对代码没有侵入性,基本上不用动我们原来的代码,只是将相关数据库连接的配置更换为sharding的配置即可。
以我的个人实践项目为例:
原来不分表时的配置:
#项目配置
spring:
#数据连接配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxx.xx.xx.xx:3306/yyms?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: xxx
password: xxx
使用sharding后的配置
# 分表配置
spring:
shardingsphere:
datasource:
names: yyms
yyms:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxx.xx.xx.xx:3306/yyms?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: xx
password: xxx
sharding:
tables:
# 表名
sys_log:
actual-data-nodes: yyms.sys_log_$->{0..1}
# 分表配置,根据id分表
table-strategy:
inline:
sharding-column: id
algorithm-expression: sys_log_$->{id % 2}
# 配置字段的生成策略,column为字段名,type为生成策略,sharding默认提供SNOWFLAKE和UUID两种,可以自己实现其他策略
key-generator:
column: id
type: SNOWFLAKE
props:
sql:
show: true
上面的配置基本上就实现了单库对sys_log表的拆分,根据id取模算法,拆分为sys_log_0和sys_log_1两张表。代码层面没有任何改动就实现了拆分,拆分后效果图如下。

注意哦,sys_log表拆分后是实际不存在的。
当然了,使用官方的默认配置很多时候并不能满足我们的需求。
假如拿到一条数据的id后再去计算数据在哪个库,无疑对我们日常的运维维护工作造成极大的不便。这里我们可以通过一些简单的自定义开发配置实现。
比如我想要id最后一位展示数据所处表所在序号。
多库分表
先展示个多库单表的案例
spring:
shardingsphere:
datasource:
names: ds0,ds1
ds_1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxxxxx:3306/ds1?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: xxxx
password: xxx
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxxxx:3306/ds0?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: xxxx
password: xxxx
sharding:
default-data-source-name: ds0
default-database-strategy:
inline:
sharding-column: id
algorithm-expression: ds$->{id % 2}
tables:
sys_log:
actual-data-nodes: ds$->{0..1}.sys_log
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 123
把单张表拆分到多个库,同样使用sys_log。效果图如下:
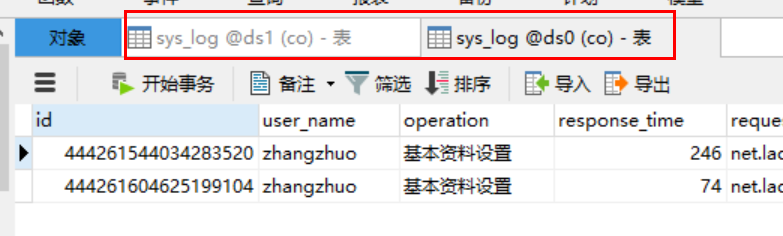
其实分库分表无非就是上面两种模式的集合,具体配置的选项,可以参考官方案例配置》》》我是链接
分库分表后的查询
select * from sys_log where id='444271380247588864'
接着上面的案例,以上面的语句为例,id为分库列,sharding经过解析后定位到对应的数据源,直接执行下面的查询。
select * from sys_log where id='444271380247588864'
假如我们的查询调节不包含分库列,以下面的语句为例:
select * from sys_log where user_name='zhangsan
执行后出现两条sql语句。我们在两个库均为5条数据,查询后的结果集为10条数据,符合我们的预期。
数据库:
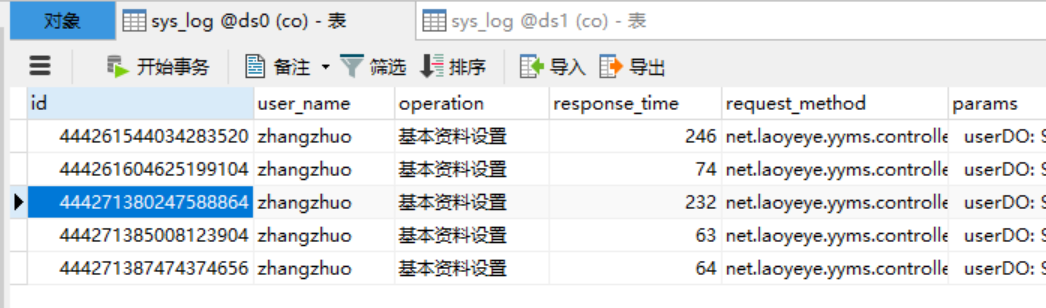
结果集:
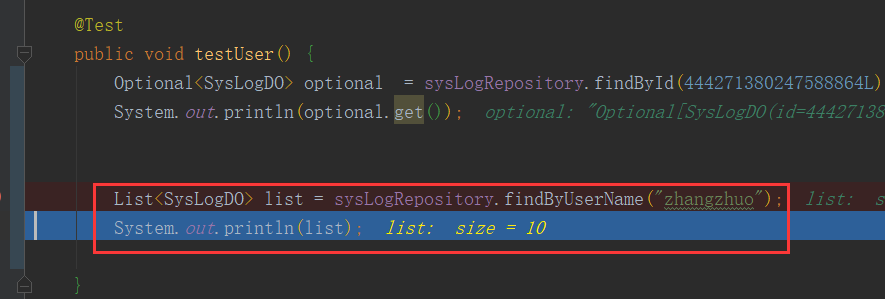
结论:当搜索条件含有分库列(分表列),这时候sharing会首先调用分库分表策略类,直接找到对应的数据库和对应子表。而当搜索条件不含有分库列时,这时候引擎就不会再调用策略类了,而是会直接认定目标库为全部库或表,上述案例中目标库就是,[ds0,ds1]两个数据源,既然目标库有两个,后面生成的DataNode,TableUnits,PreparedStatementUnit 将是以前数量的两倍,所以这回,引擎最终将会发起多个sql语句的并发执行,并合并最终的结果再返回。
分库分表不支持语法注意
https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/#不支持项
分库分表后的事务
Sharding-Sphere同时支持XA和柔性事务,它允许每次对数据库的访问,可以自由选择事务类型。分布式事务对业务操作完全透明,极大地降低了引入分布式事务的成本。
分布式事务我感觉在官方的文档和案例中写的已经是比较完善的了,这里大家可以参考:我是链接 官方案例实现,这里就不在赘述了。
最后是项目的参考代码:https://github.com/allanzhuo/yyms
❤本博客只适用于研究学习为目的,大多为学习笔记,如有错误欢迎指正,如有误导敬请谅解(本人尽力保证90%的验证和10%的猜想)。
❤如果这篇文章对你有一点点的帮助请给一份推荐! 谢谢!你们的鼓励是我继续前进的动力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号