
1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系,为什么要引入Yarn和Spark。
Spark作为计算引擎,是承载大数据操作的框架媒介。作为程序体的框架,调用配置所处位置下的机器的硬件设施来实现调用配置。HBase作为数据库,是大数据存储和读取的存储(读取)媒介。Hadoop作为分布式系统架构,则是对大量机器进行管理控制的管理者。Spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储系统,可融入Hadoop生态。
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是--Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Mapduce(分布式计算框架)源自于Google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是Google Reduce 克隆版。MapReduce是一种分布式计算模型,用以进行海量数据的计算。它屏蔽了分布式计算框架细节,将计算抽象成Map 和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
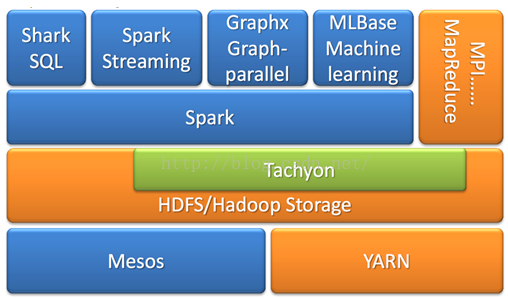
2.请简述Spark生态系统。
3. 用图文描述Spark运行架构和运行流程。

1、为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控
2、资源管理器为Executor分配资源,并启动Executor进程
3、SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理。
Executor向SparkContext申请Task,TaskScheduler将Task发放给Executor运行并提供应用程序代码。
4、Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
