
大数据理论学习,还未实战
这段时间里,上午给我弟弟补习功课,平时管理一日三餐,晚上打游戏,也就下午有时间学习一会儿。简单总结一下
首先学习了linux基础,常用的命令例如cd pwd ll grep more tail systemctl xsync等用的较为熟练
其次学习了Hadoop基础,了解到HDFS文件管理系统的高可靠性,高可用以及分布式的概念,其中NameNode和DataNode组件的关系,有了一定的了解
MapReduce是一个计算的引擎,后面有Spark还没学到,通过WordCount案例知道了MapReduce分为Map阶段和Reduce阶段,整个流程如下所示
首先是InputFormat读取数据,然后进行切片,多个切片对应多个MapTask,输入输出都有键值对,map阶段的键值对为LongWritable Text Text IntWritable(序列化,不同于java里面的序列化)
· 然后的Shuffle阶段,首先进行一次快排还有一次归并排序,经过环形缓冲区之后分成多个文件,然后是Reduce阶段,Reduce阶段分为三部分,首先是拉取数据阶段(不同节点需要用到网络)
然后是排序阶段,在java代码中也就是一个key对应一个value数组,我们可以在reduce方法中执行相应逻辑,后面还学到自定义outPutFormat,小文件的combine切片,就不说了。
最后是Yarn任务调度,默认是容量调度器,基于FIFO,然后还有公平调度器,适用于并发性高的情况。后面各种配置参数早就忘干净了,都是一些理论,面试考。
接着说完Hadoop基础,我又学习了Hive,Hive不能称之为关系型数据库,它是一个数据仓库,用于存储海量的数据,内部也是存储于HDFS中,所以需要在xml配置文件中设置hadoop路径
在hive中有CIL模式,还有hiveServer2(用于远程访问hive,比如IDEA,DATAGRIP) 然后还有metastore ,一开始默认是嵌入式的,为了高并发,我们将元数据存储于mysql中
其次hive中的sql语法,基础方面和mysql sqlserver大差不差,join where select group by order by having count(*)等等
当然也有不同的地方,比如一些字符串日期逻辑函数,然后还有窗口函数,炸裂函数,排序,分区表分桶表等等,这些用的较少,后面做hivesql的时候再来总结吧。
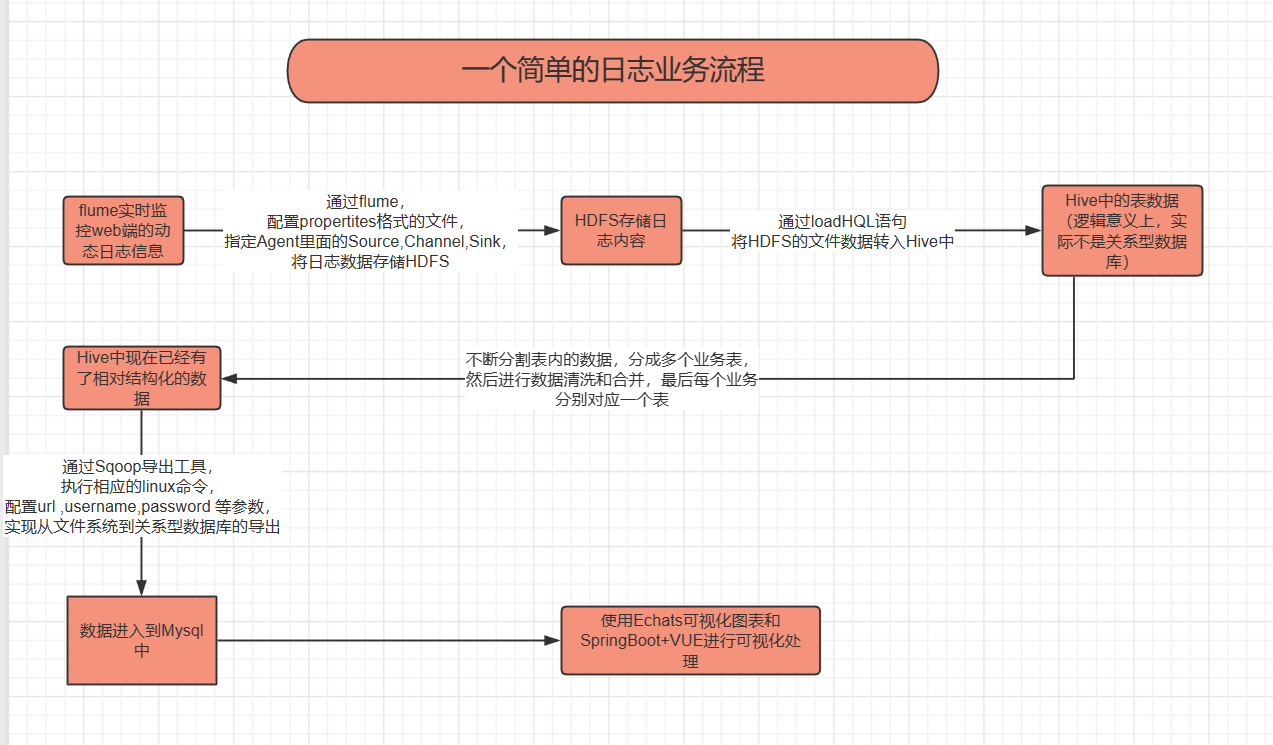
其次快速的学习了flume 、sqoop、azkaban三个小工具,这些学起来很简单(看教程两天就够了),比较繁琐的就是配置文件,简单介绍一下作用
flume可以监听网络套接字,文件,文件内容变化的信息,然后存储到hdfs中
sqoop可以实现mysql 和hive数据之间的转化
azkaban是一个任务调度工具,类似于linux中的cronta定时执行任务,azkaban为我们提供了web页面,操作起来很方便。
最后附一张我总结的工作流程,刚学,还是啥也不会,争取再多看看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号