


Flink资料(5) -- Job和调度
该文档翻译自Jobs and Scheduling
-----------------------------------------------
该文档简单描述了Flink是如何调度Job的,以及如何在JobManager上表现并跟踪Job状态。
一、调度
Flink通过任务槽(Task Slot)定义执行资源。每个TaskManager都有一或多个任务槽,每个任务槽都可以运行一个流水线并行任务。一个流水线包括多个连续的任务,如一个MapFunction的第n个并行实例与一个ReduceFunction的第n个并行实例的连续任务。注意,Flink通常会并发执行连续的任务,对于流数据程序来说,任何情况都如此执行;而对批处理程序,多数情况也如此执行。
图1中是具有一个数据源、一个MapFunction和一个ReduceFunction的程序。数据源和MapFunction的执行并发度都为4,而ReduceFunction的执行并发度为3。在图1中,程序以Source-Map-Reduce的执行顺序,在具有2个TaskManager的集群上运行,每个TaskManager都有3个任务槽,则程序执行情况图所述。
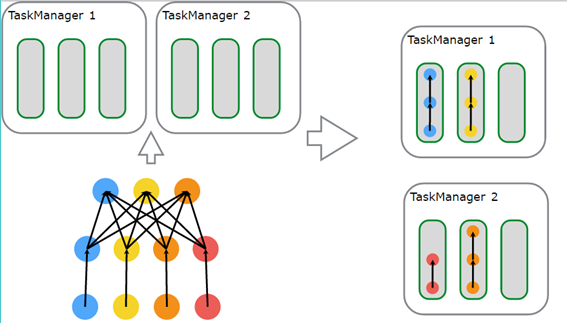
图1Flink并发运行和SlotSharing
Flink内通过SlotSharingGroup和CoLocationGroup来定义任务在共享任务槽的行为,可定义自由共享,或是严格定义某些任务部署到同一个任务槽中。
二、JobManager数据结构
在Job执行期间,JobManager将持续耿总分布式任务的执行,来决定什么时候调度下一个/下一批问题,并且对完成的或失败的任务进行响应。
JobManager接收JobGraph,JobGraph是数据流的表现形式,包括Operator(JobVertex)和中间结果(intermediateDataSet)。每个Operator都有诸如并行度和执行代码等属性。此外,JobGraph拥有一些附加的库,这些库都是在Operator执行代码时所需要的。
JobManager将JobGraph转换为ExecutionGraph。ExecutionGraph是JobGraph的并行版本:对每个JobVertex,它针对每个并行子任务都有一个ExecutionVertex。一个并行度为100的Operator将拥有一个JobVertex和100个ExecutionVertex。ExecutionVertex会跟踪其特定子任务的执行状态。来自一个JobVertex的所有ExecutionVertex都由一个ExecutionJobVertex管理,ExecutionJobVertex跟踪Operator总体的状态。除了这些节点之外,ExecutionGraph同样包括了IntermediateResult和IntermediateResultPartition,前者跟踪IntermediateDataSet的状态,后者跟踪每个它的partition的状态。
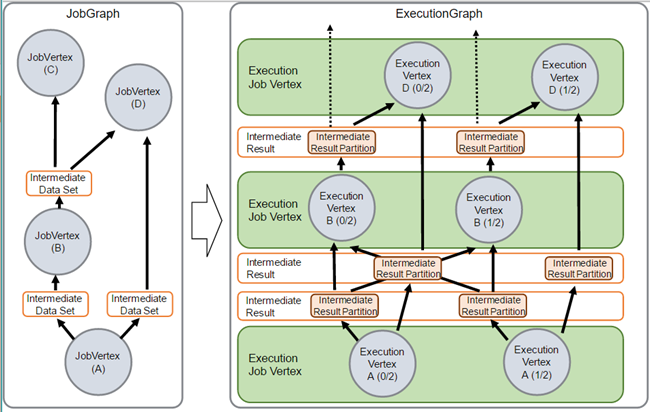
图2 JobGraph(Vertex) - ExecutionGraph(Vertex)
在程序执行期间,每个并行任务要经过多个阶段,从created到finished或failed。图3为各个状态以及它们之间可能的转换。一个任务可能被多次执行(如在失效恢复的过程中),所以我们以一个Exection跟踪一个ExecutionVertex。每个ExecutionVertex都有一个当前Execution(current execution)和一个前驱Execution(prior execution)。
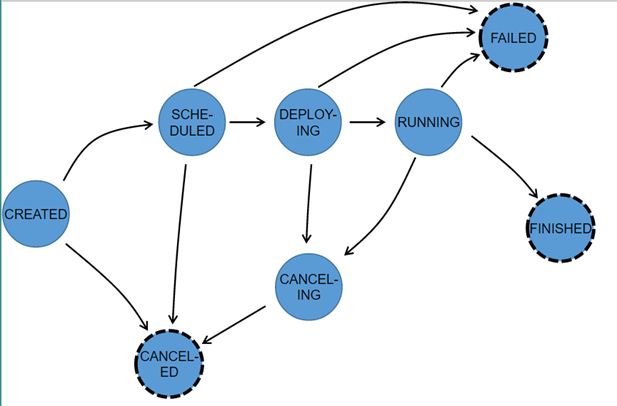
图3 执行阶段及跳转


 浙公网安备 33010602011771号
浙公网安备 33010602011771号