

数据采集与融合第二次作业
任务一
代码及思路
首先来看要求
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
由此可知我们要做两件事情
- 爬取天气预报的数据
- 将数据保存在数据库中
所以我设置了两个类,一个类ChinaWeatherCrawler负责爬取数据,一个类WeatherDatabase负责将数据保存在数据库中
首先我们来看类ChinaWeatherCrawler
-
建立城市与代码的对应关系
self.city_codes = { "北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601" }
例如北京为http://www.weather.com.cn/weather/101010100.shtml
-
再获取页面
request = urllib.request.Request(url, headers=self.header_info) response = urllib.request.urlopen(request).read() encoding = UnicodeDammit(response, ["utf-8", "gbk"]) html = encoding.unicode_markup soup = BeautifulSoup(html, "lxml") -
运用CSS选择器来提取各项数据
date_text = item.select_one("h1").text#获取日期
weather_desc = item.select_one("p[class='wea']").text#获取天气
temp_high = item.select_one("p[class='tem'] span")#获取最高温以及最低温
temp_low = item.select_one("p[class='tem'] i").text
temperature = f"{temp_high.text if temp_high else ''}/{temp_low}"
-
将数据插入到数据库中
self.db.insert_data(city_name, date_text, weather_desc, temperature)
我们再来看看类WeatherDatabase
-
建立数据库连接并初始化表结构
def connect_db(self): self.conn = sqlite3.connect("weather_info.db") self.cur = self.conn.cursor() try: self.cur.execute(""" CREATE TABLE forecast ( city TEXT, date TEXT, condition TEXT, temperature TEXT, PRIMARY KEY (city, date) ) """) except: # 若表已存在则清空旧数据 self.cur.execute("DELETE FROM forecast") -
插入数据
def insert_data(self, city, date, cond, temp): try: self.cur.execute( "INSERT INTO forecast (city, date, condition, temperature) VALUES (?, ?, ?, ?)", (city, date, cond, temp) ) except Exception as e: print("插入出错:", e)
结果展示

作业心得
不仅加深了对网络爬虫原理的理解,也进一步掌握了网页解析与数据库存储的综合应用。
任务二
代码及思路
同样我们从爬取和数据库两方面来进行分析
数据库方面我们不像任务一那样用封装一个类来专门进行数据库的建立和插入
我们使用SQLite来进行
conn = sqlite3.connect("stocks.db")
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
code TEXT PRIMARY KEY, -- 股票代码
name TEXT, -- 股票名称
price REAL, -- 最新价
pct REAL, -- 涨跌幅
amount REAL, -- 成交额(亿元)
update_time TEXT -- 更新时间
)
''')
conn.commit()
在爬取方面
我们先用F12寻找数据来自于哪个接口
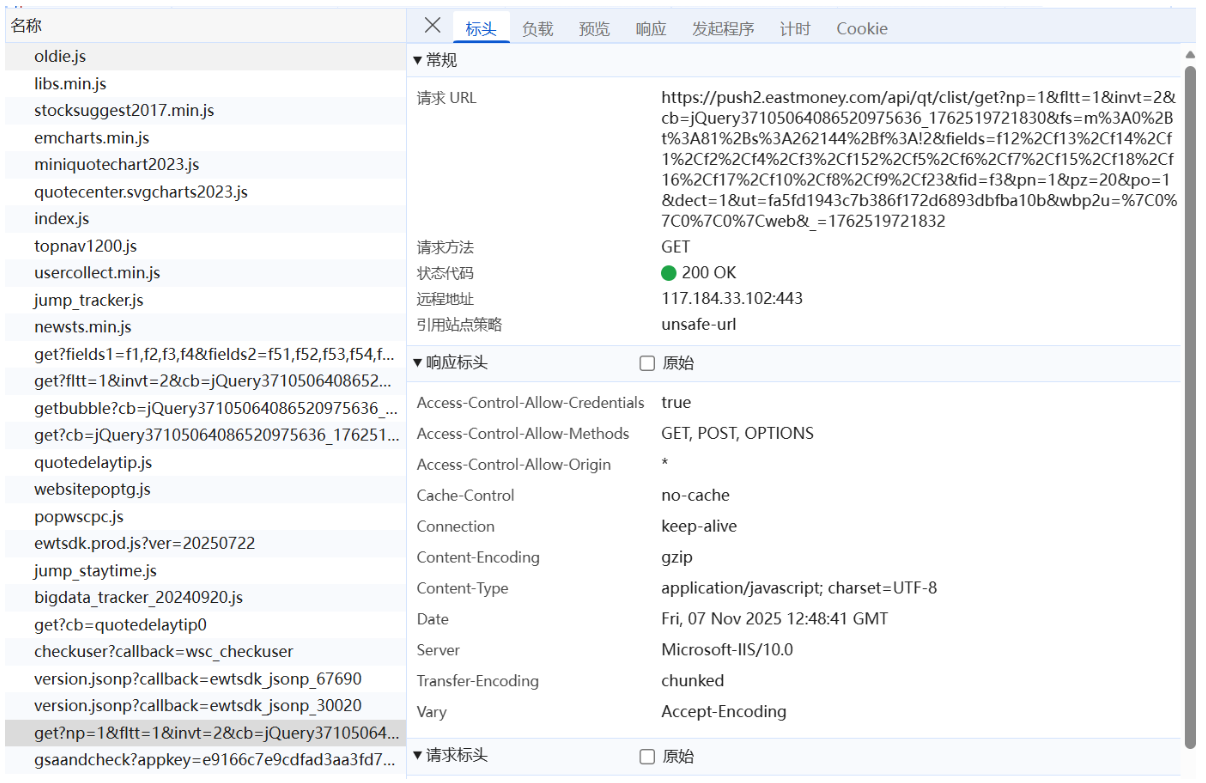
数据接口返回的是一个 JSON 格式的数据流,字段较多,因此我提前定义了请求参数和请求头
url = "https://push2.eastmoney.com/api/qt/clist/get"
base_params = {
"np": "1",
"fltt": "1",
"invt": "2",
"fs": "m:0+t:6+f:!2,m:0+t:80+f:!2,m:1+t:2+f:!2,m:1+t:23+f:!2,m:0+t:81+s:262144+f:!2",
"fields": "f12,f13,f14,f2,f3,f4,f5,f6,f15,f16,f17,f18",
"fid": "f3",
"pz": "20",
"po": "1",
"dect": "1",
"ut": "fa5fd1943c7b386f172d6893dbfba10b",
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}

再分析分析json的内容
可以发现json数据位于{}的内部,因此我们使用正则表达式来提取数据部分
通过观察数据页面的对应关系分析出字段的对应关系
代码如下
response = requests.get(url, params=params, headers=headers, verify=False, timeout=10)
text = response.text
json_str = re.search(r"\{.*\}", text).group()
data = json.loads(json_str)
stocks = data["data"]["diff"]
for s in stocks:
code = s.get("f12")
name = s.get("f14")
price = s.get("f2", 0)
pct = s.get("f3", 0)
amount = s.get("f6", 0) / 1e8
update_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print(f"{code:<8}{name:<10}{price:<10.2f}{pct:<12.2f}{amount:<12.2f}")
# 插入数据库(重复则更新)
cursor.execute('''
INSERT INTO stocks (code, name, price, pct, amount, update_time)
VALUES (?, ?, ?, ?, ?, ?)
ON CONFLICT(code) DO UPDATE SET
name=excluded.name,
price=excluded.price,
pct=excluded.pct,
amount=excluded.amount,
update_time=excluded.update_time
''', (code, name, price, pct, amount, update_time))
页数由pn参数决定
params = base_params.copy()
params["pn"] = str(page)
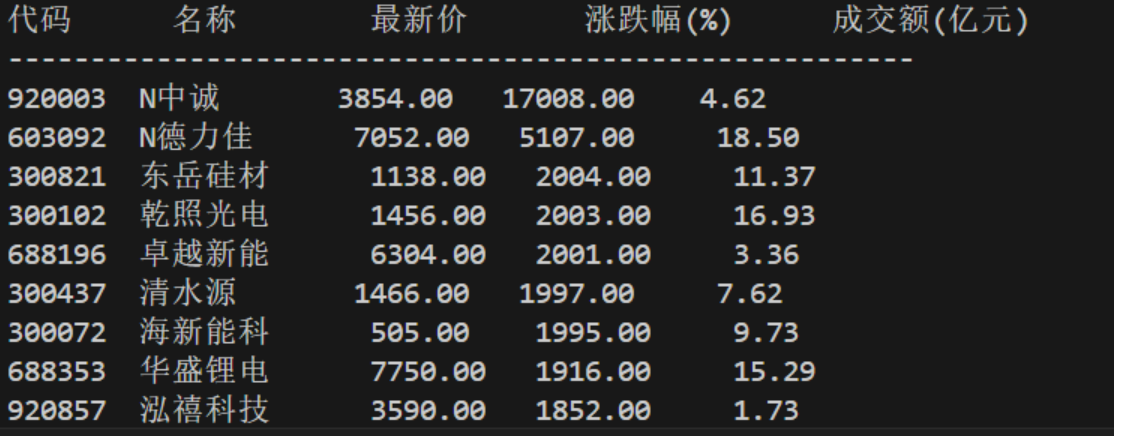
部分结果如下
作业心得
让我深入理解了网络数据接口(API)的调用、正则表达式提取、JSON 数据解析以及数据库的增量更新操作
任务三
代码及思路
同样的我们先来找负责数据的API接口

我们来转换下思路,先将JSON提取出来,再进行人为的分析
import requests
url = "https://www.shanghairanking.cn/_nuxt/static/1761118404/rankings/bcur/2021/payload.js"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://www.shanghairanking.cn/_nuxt/static/1761118404/rankings/bcur/2021/payload.js"
}
response = requests.get(url, headers=headers, timeout=10)
with open("payload.js", "wb") as f:
f.write(response.content)

发现这并不是一个标准的json文件,我们不能直接使用 json.loads() 解析,而需要 手动定位和提取数据部分。
首先找到数据部分
match = re.search(r'univData:\[(.*?)\],indList:', content, re.DOTALL)
然后采用计数遍历匹配手动追踪层次
for i, c in enumerate(data_str):
if c == '{':
if depth == 0:
start = i
depth += 1
elif c == '}':
depth -= 1
if depth == 0 and start >= 0:
objects.append(data_str[start:i+1])
start = -1
然后再用正则表示式提取具体的数据
name = re.search(r'univNameCn:"([^"]+)"', obj)
prov = re.search(r'province:(\w+)', obj)
cate = re.search(r'univCategory:(\w+)', obj)
scor = re.search(r'score:([\d.]+)', obj)
数据部分并不是真实的数据,还要经过映射,具体映射关系在文档的开头和结尾
通过观察获得记录表
# 省份代码对照表
provinces = {
'q': '北京', 'y': '安徽', 'D': '上海', 'k': '江苏', 'x': '浙江',
'v': '湖北', 'w': '湖南', 'F': '福建', 'u': '广东', 'B': '黑龙江',
'C': '吉林', 'r': '辽宁', 's': '陕西', 't': '四川', 'n': '山东',
'o': '河南', 'p': '河北', 'G': '山西', 'z': '江西', 'K': '甘肃',
'M': '重庆', 'N': '天津', 'H': '云南', 'I': '广西', 'J': '贵州',
'L': '内蒙古', 'O': '新疆', 'Y': '海南', 'az': '宁夏', 'aA': '青海',
'aB': '西藏'
}
# 类型代码对照表
types = {
'f': '综合', 'e': '理工', 'h': '师范', 'm': '农业', 'S': '林业'
}
最后保存到数据库中
def export_database(data, dbname='university_rankings.db'):
"""导出数据库"""
if not data:
return False
try:
conn = sqlite3.connect(dbname)
cur = conn.cursor()
# 建表
cur.execute('''
CREATE TABLE IF NOT EXISTS universities (
ranking INTEGER PRIMARY KEY,
name TEXT NOT NULL,
province TEXT,
category TEXT,
score REAL
)
''')
# 清空旧数据
cur.execute('DELETE FROM universities')
# 写入数据
for item in data:
cur.execute(
'INSERT INTO universities VALUES (?, ?, ?, ?, ?)',
(item['排名'], item['学校'], item['省市'],
item['类型'], float(item['总分']))
)
conn.commit()
conn.close()
print(f"已保存:{dbname}")
return True
except Exception as e:
print(f"保存数据库失败:{e}")
return False
作业心得
通过本次作业,我对“非标准数据解析”和“正则表达式应用”有了更深的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号