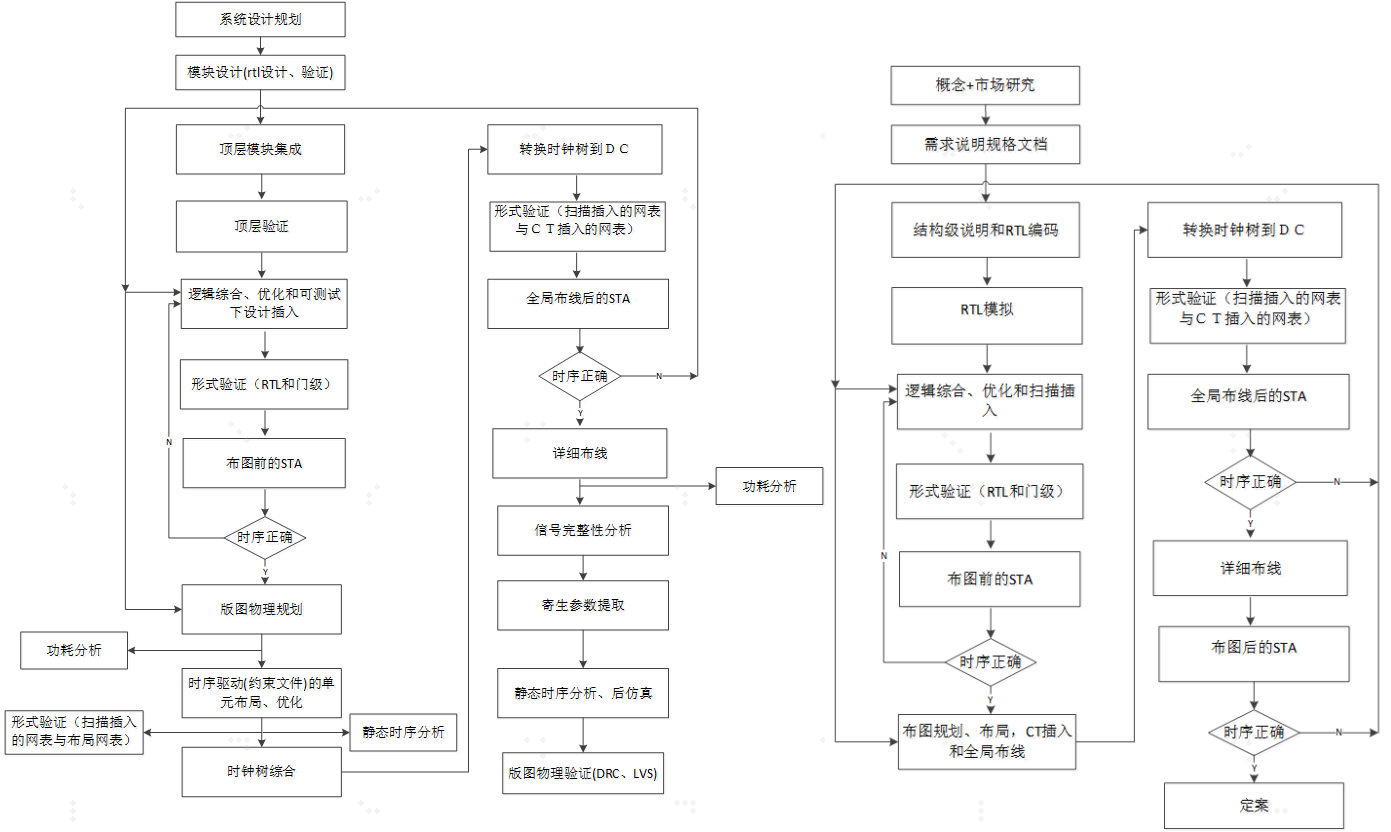
soc 芯片设计流程
1.SOC芯片介绍
SoC是系统级集成,将构成一个系统的软/硬件集成在一个单一的IC芯片里。它一般包含片上总线、MPU核(memory protect unit)、SDRAM/DRAM、FLASH ROM、DSP、A/D、D/A、RTOS内核、网络协议栈、嵌入式实时应用程序等模块,同时,它也具有外部接口,如外部总线接口和I/O端口。通常,SoC中包含的一些模块是经过预先设计的系统宏单元部件(Macrocell)或核(Cores),或者例程(Routines),称为IP模块,这些模块都是可配置的;
1.以超深亚微米VDSM(Very Deep Sub Micron)工艺和知识产权IP(Intellectual Property)核复用(Reuse)技术为支撑。
2.是当今超大规模集成电路的发展趋势,也是21世纪集成电路技术的主流,为集成电路产业提供了前所未有的广阔市场和难得的发展机遇。
3.设计中,设计者面对的不再是电路芯片;而是能实现设计功能的IP模块库。
4.设计不能一切从头开始,要将设计建立在较高的基础之上,利用己有的IP芯核进行设计重用。建立在IP芯核基础上的系统级芯片设计技术,使设计方法从传统的电路级设计转向系统级设计。
5.含有实现复杂功能的VLSI,使用嵌入式CPU和DSP,采用IP核进行设计,采用VDSM技术,具有从外部对芯片编程的功能
SOC三大支撑技术:软硬件协同设计技术;IP设计和复用技术;超深亚微米设计技术
1.1 软硬件协同设计
实际上就是一个系统的软件部分、硬件部分协同开发的过程。在整个设计过程中,考虑系统软硬件部分之间的相互作用以及探索它们之间的权衡划分,实际的软硬件协同设计覆盖设计过程中的许多问题,包括系统说明与建模、异构系统的协同仿真、软硬件划分、系统验证、编译、软硬件集成、界面生成、性能与花费评估、优化等,其中软硬件划分是协同设计中最主要的挑战,它直接影响最后产品的性能与价格。
软硬件划分,协同指标定义,协同分析,协同模拟,协同验证,接口综合
在进行软硬件划分时,通常有两个主要的任务:第一,分配(allocation),也就是选择系统部件的过程,包括选择系统部件的类型、确定每种类型的数量;第二,划分(partitioning),在选择的部件上分配系统的功能,也就是把系统的功能进行合理的分块,使每一块映射到相应合理的部件上。这两个设计任务必须满足设计限制集,包括花费、性能、尺寸、功能、向后兼容等。
1. Top-to-Down方法整体考虑了SoC芯片软/硬件系统设计的要求,将系统需求、处理机制、芯片体系结构、各层次电路及器件、算法模型、软件结构、协同验证紧密结合起来,从而用单个或极少几个芯片完成整个系统的功能。SOC平台的设计流程分为以下几个主要步骤:
(1)系统总体方案设计:芯片系统功能、指标定义、需求分析、产品市场定位、软/硬件划分、指标分解等整体方案论证。
(2)软/硬件方案设计:确定芯片系统功能的软/硬件划分,软/硬件体系结构,模块功能的详细描述及技术指标要求、时序、接口定义等工作。
(3)模块设计开发:完成硬件模块的开发、行为及时序仿真测试、底层硬件驱动程序编写、算法设计及仿真、协议和应用软件的设计与开发。对于复杂的功能模块,可进一步划分成子模块。在算法仿真时,根据系统指标的要求划分出信号处理硬件加速模块。
(4)软/硬件协同仿真测试:主要测试系统方案和软/硬件模块设计功能的正确性。
(5)软/硬件协同仿真测试:主要测试系统方案和软/硬件模块设计功能的正确性。
(6)样片的测试:基于SoC样片的系统功能及性能指标测试。
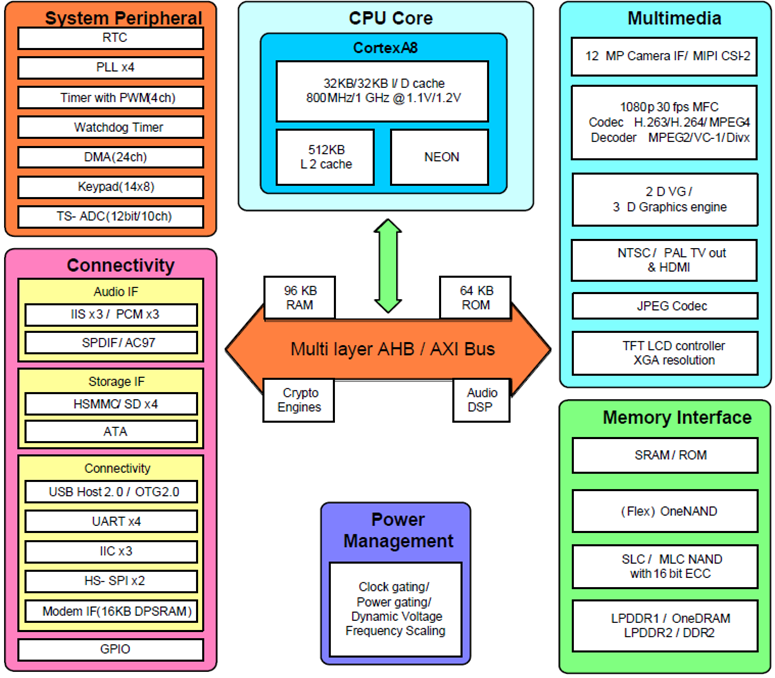
Samsung S5PV210
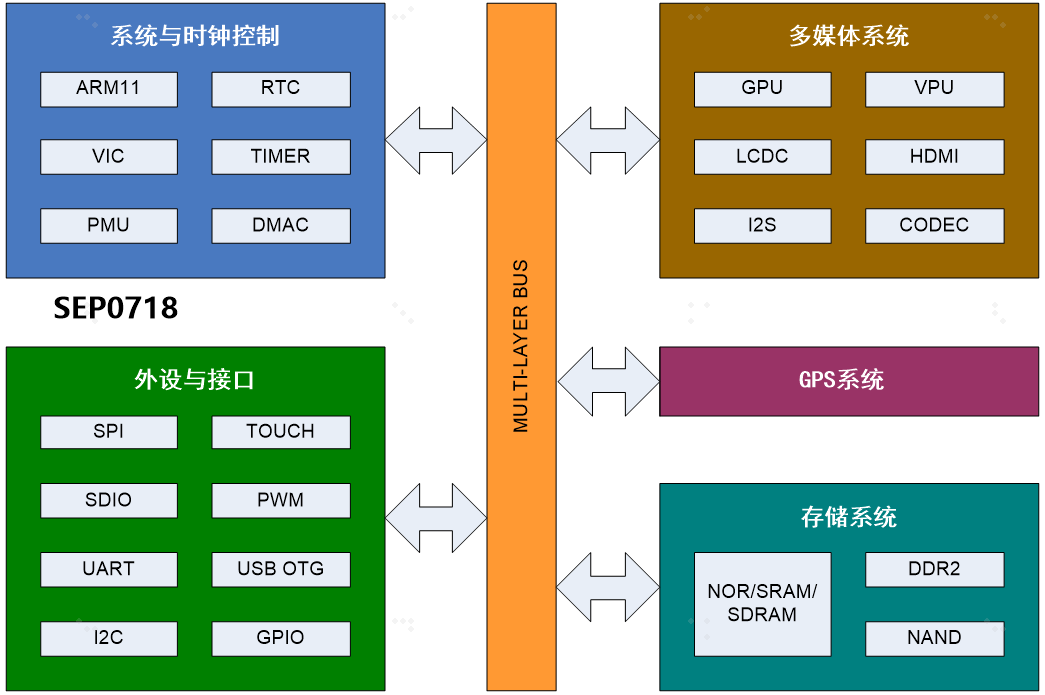
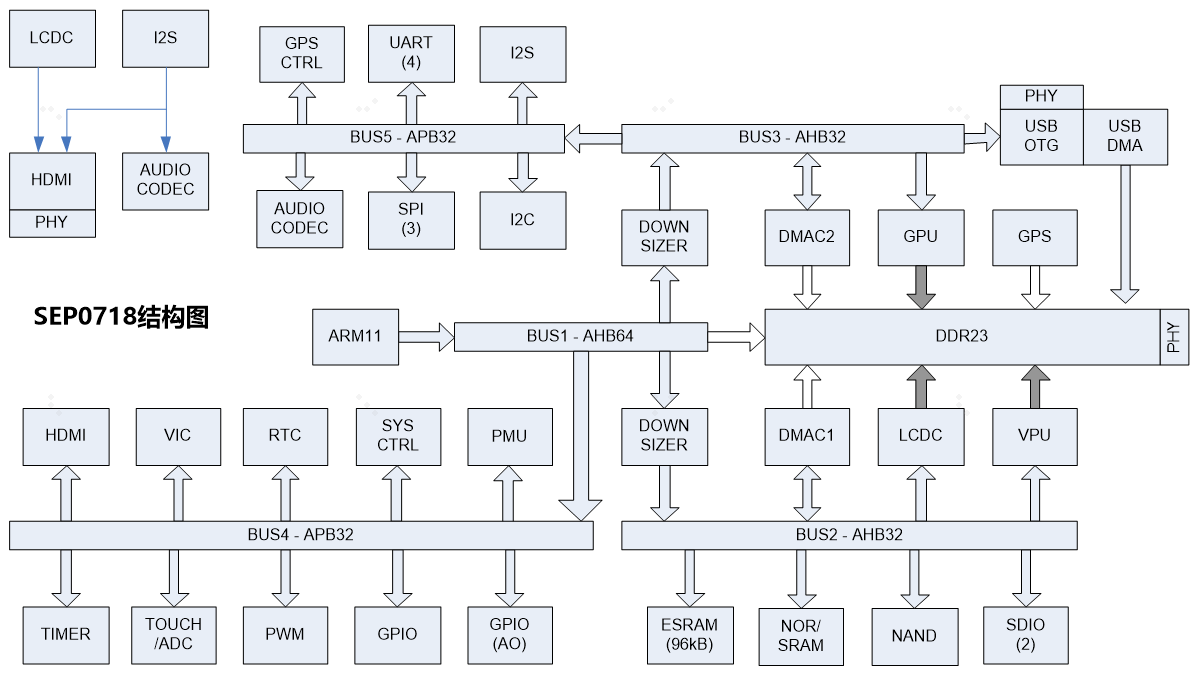
内部port通过pin_mux连接到pad上,通过GPIO的控制例如GPIO输入端口接0或者接1控制输入端口的值。
UART和GPIO可以直接挂在AHB总线上,也可以挂在APB总线上,还包括电源管理单元,时钟,复位,测试单元,和模拟模块
1.2 IP设计和复用技术
片上系统就是指在单个硅芯片上实现信号采集、转换、存储、处理和I/0等功能,或者说在单个硅芯片上集成了数字电路、模拟电路、信号采集和转换电路、存储器、微处理器MPU、微控制器MCU、数字信号处理器DSP等,实现一个系统的功能。片上系统能够在单个硅芯片上实现高层次的系统集成,但同时也对硅芯片的设计提出了巨大的挑战。因为当前的设计工具和设计方法不能完全胜任片上系统的设计。在芯片设计复杂度迅速增加的同时,熟练设计人员的增长很有限,而对设计周期的要求越来越高。
IP复用技术,是提高片上系统设计效率、缩短设计周期的一个关键。
IP复用技术的优点有三个:
重复利用IP可以提高设计能力,节省设计人员,是填平集成电路的设计与制造之间鸿沟的最有效方法之一;
能大大缩短上市周期;
可以更好地利用现有的工艺技术,降低成本。
预计在未来几年内,50%以上的片上系统设计要不同程度地以可复用IP的内核为基础。
自动综合工具与硬件描述语言HDL (Hardware Description Language)一起将设计复用提升到更高的抽象级别,实现了设计复用的自动化,同时提高了设计的效率和质量。HDL能够实现设计的模块化、参数化,方便进行子模块的选择、加入和排列等操作。自动综合工具则根据具体应用优化设计并直接映射到相应的工艺库。通过上述手段,大大增强了IP的可复用性。硬件设计复用正逐渐采用软件方法,如编程、编译、库技术等,从硬件设计模式向软件设计模式转变。
IP核
IP(Intellectual Property)是具有知识产权的、已经设计好并经过验证的、可重复利用的集成电路模块。
软核(Soft IP core):IP软核通常是用HDL文本形式提交给用户,它经过RTL级设计优化和功能验证,但其中不含有任何具体的物理信息,例如可以直接通过C语言完成设计,利用HLS将c语言转化为verilog语言,此时的代码人完全看不懂。
固核( Firm IP core):IP固核的设计程度则是介于软核和硬核之间,除了完成软核所有的设计外,还完成了门级电路综合(DC)。设计在门级综合后生成门级网表(netlist),即以门级电路网表的形式提供给用户。
硬核( Hard IP Core):IP硬核是基于半导体工艺的物理设计,已有固定的拓扑布局和具体工艺,并已经过工艺验证,具有可保证的性能。其提供给用户的形式是电路物理结构掩模版图和全套工艺文件,是可以拿来就用的全套技术,即流片用的GDS II格式文件。所以会提供行为级模型用于验证。
DesignWare IP:是SoC/ASIC设计者最钟爱的设计IP库和验证IP库。DesignWare IP产品系列包括逻辑库、嵌入式存储器、PVT、模拟IP、接口IP、安全IP、嵌入式处理器和子系统,一个独立于工艺的、经验证的、可综合的虚拟微架构的元件集合,超过140个模块。DesignWare和 Design Compiler的结合可以极大地改进综合的结果,并缩短设计周期。Synopsys在DesignWare中还融合了更复杂的商业IP(无需额外付费)目前已有:8051微控制器、PCI、PCI-X、USB2.0、MemoryBIST、AMBA SoC结构仿真、AMBA总线控制器等IP模块。
DesignWare中还包括一个巨大的仿真模型库,其中包括170,000多种器件的带时序的功能级仿真模型,包括FPGAs (Xilinx, Altera,…), uP, DSP, uC, peripherals, memories, common logic, Memory等。还有总线(Bus-Interface)模型PCI-X, USB2.0, AMBA, Infiniband, Ethernet, IEEE1394等,以及CPU的总线功能仿真模型包括ARM, MIPS, PowerPC等。
在RTL设计中,经常要用到一些标准的cell(单元),有一些很简单,如普通的加法器,寄存器,常用的组合逻辑等等。这些一般的我们都直接用语言直接描述出来。但是对于一些复杂的逻辑功能,往往设计起来比较麻烦,或者自己设计出来的综合后时序比较差。比如,超前进位加法器,全加器,乘法器(各种结构的乘法器),优先级编码器等等。
synopsys公司技术人员,针对复杂和时序要求高的功能模块,直接设计/优化最底层的版图,将其中的延迟优化到最小,逻辑功能可以支持到速度更高的芯片。所以,designware在DC综合的时候没有多少优化的余地,因为DC调用的已经是designware的版图。仿真的时候都是调用synopsys提供的designware仿真库,是没办法综合的。
SoC芯片包括的模块:系统总线,嵌入式微处理器内核,中断控制器,存储器/存储器控制器,锁相环,DMA控制器,电源管理模块,定时器,通信控制,通用GPIO,RTC
1.3 超深亚微米设计
由于超深亚微米设计时互连线延迟是主要延迟因素,而延迟又取决于物理版图。
因此传统的自上而下的设计方法只有在完成物理版图后才知道延迟大小。如果这时才发现时序错误,则必须返回前端,修改前端设计或重新布局,这种从布局布线到重新综合的重复设计可能要进行多次,才能达到时序目标。
随着特征尺寸的减少,互连线影响越来越大。传统的逻辑综合和布局布线分开的设计方法已经变得无法满足设计要求,必须将逻辑综合和布局布线更紧密的联系起来,用物理综合方法,使设计人员同时兼顾考虑高层次的功能问题、结构问题和低层次上的布局布线问题。物理综合过程分为初始规划、RTL规划和门级规划三个阶段。
物理综合过程
1-初始阶段
在初始规划阶段,首先完成初始布局,将RTL模块安置在芯片上,并完成I/O布局、电源线规划。根据电路时序分析和布线拥挤程度的分析,设计人员可重新划分电路模块。通过顶层布线,进行模块间的布线并提取寄生参数,生成精确线网模型,确定各个RTL模块的时序约束,形成综合约束。
2-RTL规划阶段
RTL规划阶段是对RTL模块进行更精确的面积和时序估算。通过RTL估算器快速生成门级网表,再进行快速布局获得RTL模块更精确的描述,并基于这种描述对布局顶层布线、引脚位置进行精细调整。最后获得每一RTL模块的线负载模型和精确的各模块的综合约束。
3-门级规划
门级规划是对每一RTL级模块独立地进行综合优化,完成门级网表,最后进行布局布线。**对每一RTL模块和整个芯片综合产生时钟树,还进行时序和布线拥挤程度分析,如果发现问题,可进行局部修改。由于物理综合过程和前端逻辑综合紧密相连,逻辑综合是在布局布线的基础上进行,因此延迟模型准确,设计反复较少。在超深亚微米设计过程中,除了连线延迟大于单元延迟引起的一系列问题仍然困扰着设计人员外,还要考虑信号完整性等其他问题。所以,有必要对这些经典问题作一个仔细的分析。
2、设计迭代
以布尔代数为基本理论基础的现代数字IC设计技术面向的是系统的逻辑设计,布尔代数定义的各种基本逻辑运算所描述的是一个系统的输出对输入的逻辑关系。这种逻辑关系以一组包含“0”和“1”两个基本逻辑值的逻辑向量来表示。现代IC设计的核心问题就是解决如何准确地实现这种用二值逻辑确定的系统功能,或者说找到一组正确描述系统功能的逻辑表达式。
显然,在具体实现中,采取哪种实现方法在逻辑表达式中没有表示。理论工作的贡献在布尔代数上得到了巨大的体现。如果没有布尔代数,今天我们赖以生存的IC工业也就失去了它的理论基础。
3、信号完整性问题
在超深亚微米IC设计技术的研究中,除了要克服由于连线延迟引起的设计迭代之外,设计人员还要克服由于特征尺寸缩小、信号延迟变小、工作频率提高带来的所谓信号完整性的问题。
在芯片内部工作频率提高的同时,由于集成度的大幅度上升,单个芯片中的连线长度也随之大幅度升高。单个芯片中的连线总长将达到十几到几十千米,其中不乏有些连线的长度将达到十几米到几十米。根据物理学的基本定律,频率与波长成反比。当芯片的内部工作时钟达到几千兆赫兹的时候,相应的波长只有若干米。
再考虑到电磁场的有关理论,可以知道当连线长度达到波长的几倍时,连线将成为向外界发射电磁波的天线,同样这些连线也会成为接收电磁波的天线。考虑到IC芯片内部连线密布,在很高的工作频率下,信号的干扰将成为一个不容忽视的问题,信号的完整性将成为设计者面对的另外一个严峻挑战。所以传统的基于布尔代数的数字IC设计理论必须要从简单的面向逻辑,转向吸引其他相关领域的理论,形成新的理论体系。
2. 芯片生成流程
生产厂家根据我们后端设计完成好的GDSⅡ版图文件,进行掩模版生产;生产好的掩模版用于最后的集成电路芯片制造。
GDS: Geometry Data Standard,描述电路版图的一种格式:包括晶体管大小,数量,物理位置和尺寸信息,连接线的物理尺寸和位置信息等。
等晶体管+连接线,组成复杂庞大的电路逻辑,为二进制格式,无法用文本编辑器查看,可用calibredrv. virtuoso,laker等查看;
可以理解为,GDS包含制造一颗芯片所需的全部信息;芯片制造厂(fab)只需要IC设计公司提交GDS用于芯片生产;
版图: Layout晶体管: Transistor,连接线: interconnect/wire
封装前的芯片颗粒(Die),长满Die的晶圆(Wafer)
GDS要求:1.功能,要和RTL的一样;2.性能,要满足预定的性能目标;3.物理规则,Fab能拿它正常制造4(功耗&面积,) IR Drop满足要求功耗&面积要尽可能小;
GDS II 设计好之后,交给晶圆制造商进行晶圆制造:
Wafer Processing/Fabrication/ Manufacturing:晶圆制造(如TSMC,SMIC)也通常被称为fab而没有制造厂的IC设计公司也通常被称为 fabless公司
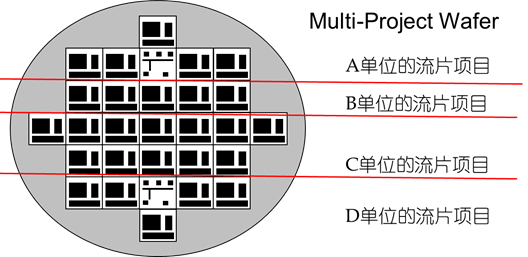
MPW叫做多项目晶圆流片:廉价,对MPW出来的晶圆要进行切割和封装,才能得到样片
2.1 OCV(On Chip Variation)
芯片在实际生产中,同一片晶圆上的不同区域的芯片,因为各种外部条件和生产条件的变化(variation),比如:工艺(Process),电压(Voltage),温度(Temperature)等,可能会产生不同的误差从而导致同一块晶圆上某些区域上的芯片里的晶体管整体速度变快或变慢,因此有了corner的概念。而与此同时,在同一块芯片上的不同区域,也会因为上述因素而有进一步的差异(variation),因此产生了OCV (On Chip Variation)的概念。
在设计中引入OCV的目的在于从设计角度考虑芯片在实际生产中可能出现的各种差异(variation),从而适度增加设计余量(margin),减少不必要的设计悲观量(pessimism)。
在理想情况下,我们假设所有cell和net在实际生产后其delay都和我们设计中通过库和rc寄生参数计算出来的数值完全一样,那么setup应满足如下条件:
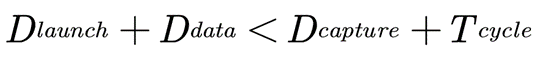
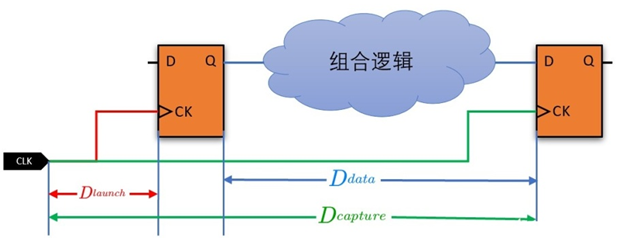
Dlaunch为launch clock 的uncertainty(skew) delay, Dcapture为capture clock 的uncertainty(skew) delay, Ddata为clock to q delay,组和逻辑的delay 以及后级触发器的setup time 之和。
然而,在实际生产中,由于各种variation可能会出现如下情况:
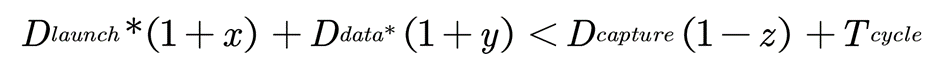
在x, y, z都是正数的时候,只满足理想状况下setup的电路是不一定能够满足上述存在variation情况下的条件的。这样就会导致实际生产出来的芯片有一定的概率不能满足需要的频率等条件,严重的甚至会导致芯片失效而降低良率。
因此我们引入OCV (On Chip Variation), 它的基本理念是,对launch, capture和data line上的cell或者net加一个固定的derate数值,使得setup和hold等时序约束比理想状况更加悲观从而能够覆盖部分实际生产中所产生的variation。实际设计中的效果如下:
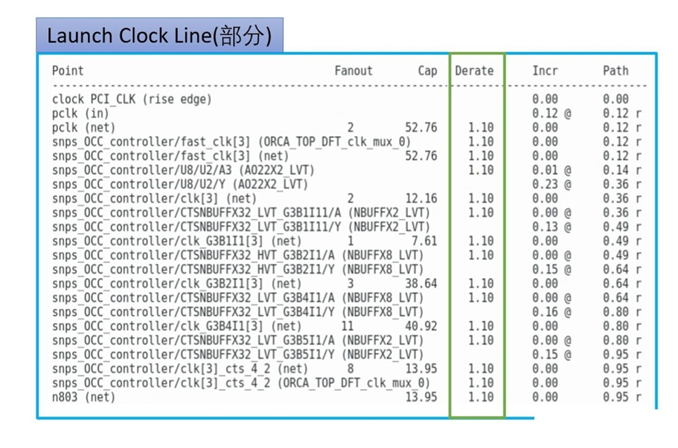
可以看到,对于launch clock,加上一个统一的大于1的derate值,就会在timing report中反映出来,相应的delay也会在原始值的基础上乘以这个derate值。
对于capture clock line,相应地就会加上一个小于1的derate来计算delay。通过这样的方法来让时序约束更加悲观,以此来覆盖生产中和实际应用中的各种variation,提高良率。
2.2 芯片制造的大致步骤
(1)掩模版(光罩版、Mask)制作,对每层版图都要制作一层掩模版,实际是光刻工序的次数,除金属层外,一般CMOS电路至少需要20层以上掩模版
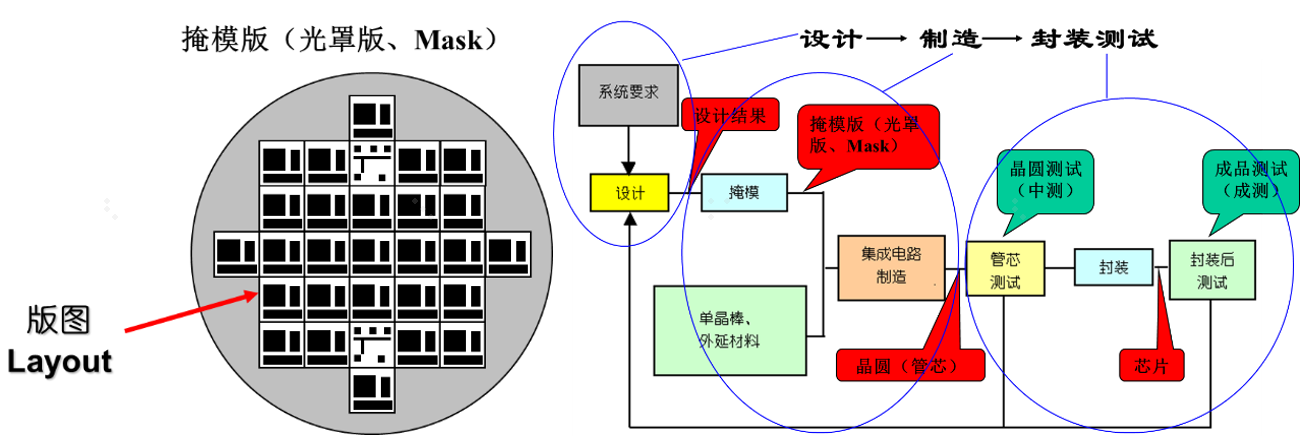
(2)晶圆制造(光刻)(Wafer Manufacturing):
(3)晶圆测试
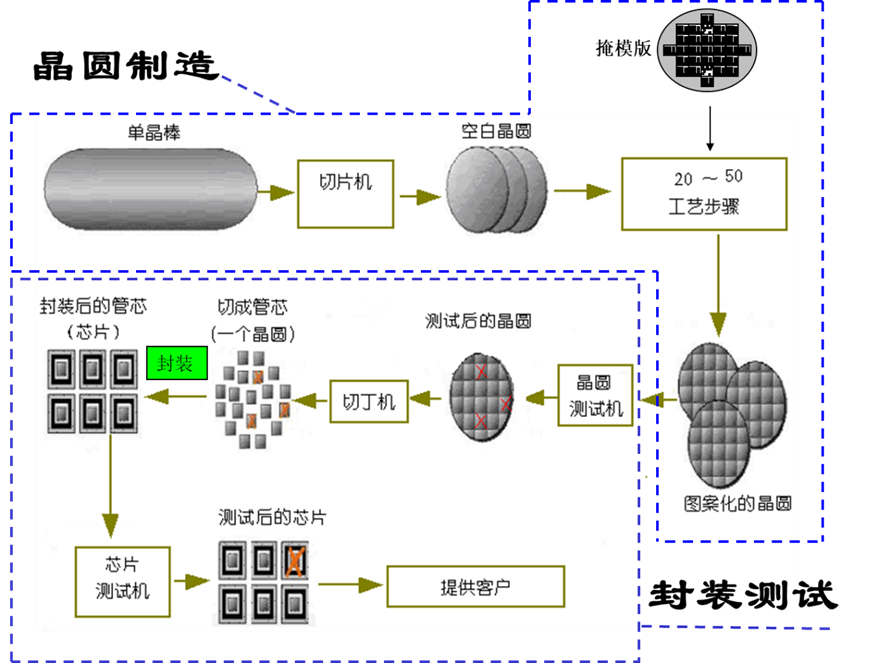
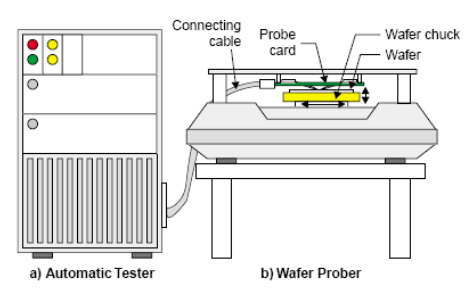
Probe Test:电性测试,半导体芯片制作工厂交付使用的产品是晶圆本身。在出货之前,需要对晶圆上的每一个芯片做电性测试。中测(晶圆测试、 Wafer Testing、CP测试):晶圆制造完成后的测试。
良率:通常晶圆上的芯片不会每一个都是可以工作的,测量所得的“可用芯片数/总芯片数”之值就是所谓“良率”(Yield)。通常只有良率达到一定值时才可以出货。由于这种测试使用探针,所以又被称为Probe Test (探针测试),测试在制造过程中形成的故障
不能测试在封装过程中形成的故障(因为此时还没有封装),所以中测以后必须进行成测;可以在封装前测试出故障芯片,避免这部分故障芯片的封装费用,适用于封装费用比较昂贵的芯片。所以,封装费用低廉的芯片可以不经过中测
自动测试仪ATE(Teaster)+自动探针台ProbeStation
(4)封装(Package):先进行晶圆切割 (Sawing Wafer);封装(Packaging)可以满足芯片的以下几个需要:给予芯片机械支撑,协助芯片向周围环境散热,保护芯片免受化学腐蚀,封装引脚可以提供芯片在整机中的有效焊接。
封装方式:DIP双列直插式;PLCC塑料有引线芯片载体;QFP塑料方型扁平式;PGA插针网格阵列;BGA球栅阵列;MCM、SIP的多芯片封装方式.

我国知名的封装厂:长电;南通富士通
Wafer Die Cut:在晶圆电性测试之后,出货到封装厂,后封装的工作真正开始。封装厂会将晶园切割成一个个小的芯片,由于在晶园上留给封装厂切割的空间只有80um,所以这也是一项非常精细的工作。然后需要把电性不良的芯片排除在外。
Wire Bonding:接着,封装厂会在切割下来的芯片上焊接上引线。这种引线的直径大约在人头发的1/3,约30um左右。引线接在芯片设计时留出的接线管脚上。任何引线之间的连接(Bridge)都将是致命的。
封装常见的工艺有 Wire Bonding,Flip-Chip等
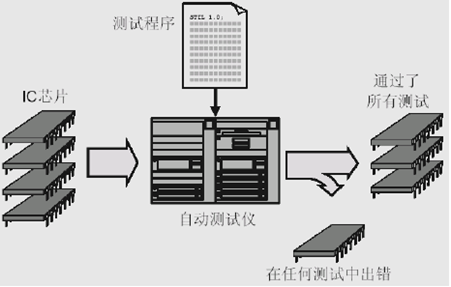
(5)成测(成品测试、Final Testing 、FT):芯片封装完成后的测试,需对每个芯片进行测试
测试在制造、封装过程中形成的故障,是必须经过的过程,但对经过中测的芯片可以相对简单
自动测试仪ATE +芯片自动分拣机(或称机械手)Handler
3. 芯片设计流程
3.1 准备需求说明规格文档
创建微体系结构文档:微体系结构文档定义了芯片的功能并划分为一些能够处理的模块;电学特性规范通过时序信息定义模块之间的关系设计。主要是对系统级,结构级和算法级的建模和规格说明。
系统级:行为和性能的描述,通常包含CPU,存储器,控制器等。初步确定应用对芯片功能和性能指标的要求,以及哪些功能可以集成,哪些功能只能外部实现,芯片工艺及工艺平台的选择,芯片管脚数量,封装形式等。
算法级:主要用于快速验证算法的正确性,不一定可以综合成实际电路结构。
结构级:更接近电路的实际结构,电路的层次化描述,类似于电路框图。
行为级:行为级是RTL级的上一层。最符合人类思维的描述方式。主要用于快速验证算法的正确性,不关注电路的具体结构,不一定可以综合成实际电路结构。注重算法。以直接赋值的形式进行,只关注结果。常采用大量运算,延迟等无法综合的语句。其目的不在于综合,而在于算法。
RTL级:使用寄存器这一级别的描述方式来描述电路的数据流方式。RTL在很大程度上是对流水线原理图的描述。接近实际电路结构的描述,可以精确描述电路的原理、执行顺序等。其目的在于可综合。贴近实际电路结构的描述,描述的细节到寄存器内容传输级别,可以精确描述电路的工作原理、执行顺序,细化到寄存器级别的结构描述也就是RTL级描述,并无绝对划分标准。
门级:使用逻辑门这一级别来描述。RTL 中的寄存器和组合逻辑,其物理实现还是对应到具体门电路。但目前寄存器,组合逻辑等的电路结构基本稳定。一般EDA工具可以把RTL描述自动编译为门级描述。所以一般不直接使用门级编程。
开关级:完整描述了电路的细节,最底层的电路描述,可以描述PMOS/NMOS。
3.2 IP开发和RTL代码设计
1.RTL代码设计:结构和电学特性编码以及HDL中的RTL编码,以及IP的开发和集成,为包含存储单元的设计插入DFT memory BIST;
2.RTL仿真:为了验证设计功能,进行详尽的动态仿真
仿真验证工具:Mentor Modelsim;Synopsys VCS(VCS为编译仿真工具,Verdi为查看波形工具) Cadence NC-verilog。
3.代码规则和语法检查:检查RTL是否存在代码和语法错误,以及CDC检查(lint,spyglass),分析RTL是否可综合。
4.对所有IP进行功能验证,执行基于周期的验证(功能性),以验证RTL的协议行为,
5.执行属性检查,以验证RTL的实现和规格说明是否匹配。
3.3 逻辑综合
逻辑综合就是通过EDA工具把顶层的HDL模块,在一定的约束情况下,映射到制造厂家标准单元库元件的门级电路的过程。通过这个步骤,从HDL代码,得到了门级网表,也就是得到了电路。逻辑综合工具:Synopsys的Design Compiler。
逻辑综合的结果就是把设计实现的HDL代码翻译成门级网表netlist。综合需要设定约束条件,就是你希望综合出来的电路在面积,时序等目标参数上达到的标准。
逻辑综合需要基于特定的综合库,不同的库中,门电路基本标准单元(standard cell)的面积,时序参数是不一样的。所以,选用的综合库不一样,综合出来的电路在时序,面积上是有差异的。一般来说,综合完成后需要再次做仿真验证。
1.准备设计约束文件:时钟定义(频率/不确定性/抖动),I / O延迟定义,输出pad负载定义,designfalse/多周期路径,实际环境设置,包括将使用的工艺库及其他环境属性,通常称为SDC synopsys_constraints,特定于synopsys综合工具(designcompiler)
2.对IP进行综合,该工具的输入为库文件(需要针对性综合的库文件,该文件具有标准单元库可用的功能/时序信息,基于连接的扇出长度的线的线负载模型),RTL文件和“设计约束”文件,以便“综合”工具可以执行RTL文件的综合并映射和优化以满足设计约束的要求。
4.使用Design Compiler的内建静态时序分析进行模块级静态时序分析,检查设计是否满足时序要求;
5.可以利用netlist网表执行网表级功耗分析,以了解设计是否满足功耗目标。
6.使用综合网表执行门级仿真,以检查设计是否满足功能要求,综合后进行后仿真与前仿真工具相同。
7.一旦执行了综合,综合的网表文件(VHDL / Verilog格式)和SDC(约束文件)将作为输入文件传递到布局和布线工具,以执行后端流程。
3.4 DFT
可测性设计是指:在进行电路的前端设计时,就预先规划、设计出如何在样片中进行电路的测试方案和办法,并通过逻辑综合过程完成芯片内部专用测试结构的插入,一遍在芯片形成后能按照预先制定的方案进行相应的电路功能测试的一种设计方法。也就是进行可测性设计,就是在原有的电路中插入专门测试的电路(插入电路)。
DFT的常见方法就是,在设计中插入扫描链,将非扫描单元(如寄存器)变为扫描单元。DFT工具Synopsys的DFT Compiler
DFT:完成综合后,作为综合流程的一部分,需要根据DFT(Design for Test)要求建立扫描链连接,综合工具(testcompiler)将建立扫描链,然后使用Design Compiler工具对具有扫描插入的设计进行约束和综合设计。
在DFT工具中执行Scan-Tracing,以检查是否已根据DFT要求构建了扫描链。
3.5 形式验证
RTL与综合后的网表之间执行形式验证(功能上进行验证对比),以确认综合工具未更改功能。工具Synopsys的Formality
这也是验证范畴,它是从功能上(STA是时序上)对综合后的网表进行验证。常用的就是等价性检查方法,以功能验证后的HDL设计为参考,对比综合后的网表功能,他们是否在功能上存在等价性。这样做是为了保证在逻辑综合过程中没有改变原先HDL描述的电路功能。形式验证工具有Synopsys的Formality。
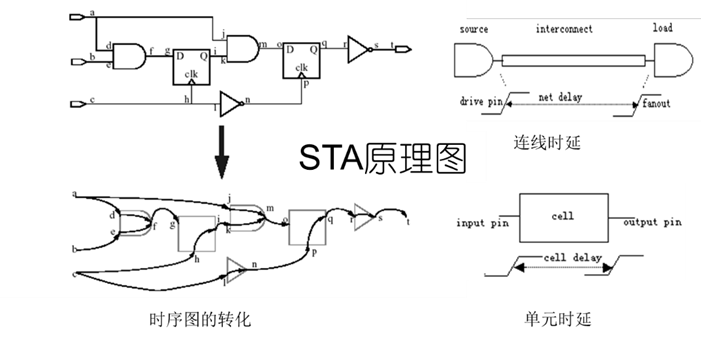
3.6 布图前的STA
静态时序分析是一个迭代过程。允许用户详细分析设计的所有关键路经并给出一个有条理的报告。对布图前后的门级网表进行静态时序分析。
它主要是在时序上对电路进行验证,检查电路是否存在建立时间(setup time)和保持时间(hold time)的违例(violation)。一个寄存器出现这两个时序违例时,是没有办法正确采样数据和输出数据的,所以以寄存器为基础的数字芯片功能肯定会出现问题。
在布图前,Prime Time使用由库指定的线载模型估计线网延时,在这一过程中先前输入到DC的时序约束同样也输入到 Primetime中并详细说明主要的输入输出信号和时钟的关系。如果对于所有关键路径的时序是可接受的,则由 Prime Time或DC可以得到一个约束文件,目的是为了预标注到布图工具。这个约束文件以SDF格式详细描述在布图工具中使用的每个逻辑组之间的时序,以便完成单元的时序驱动布局。
布图前的STA读入的数据包括门级网表,dc综合阶段生成的约束文件sdc。
3.7 版图物理规划(floor-plan)
通过EDA工具对输入标准单元库、标准I/O库、综合后的网表、各种约束文件等规划,让EDA工具完成各模块的位置摆放、电源网络的设定、I/O信号出口位置、同时确定面积、封装、工艺、噪声、负载能力等参数。芯片大小的规划、IO单元的规划、宏单元的规划、电源网络的设计,在总体上确定各种功能电路的摆放位置,如IP模块,RAM,I/O引脚等等。工具为Synopsys的Astro以及Cadence 的Encounter。
3.8 功耗分析(power analysis)
在完成版图物理规划后,需要进行功耗分析。功耗分析可以确定电源引脚的位置和电源线的宽度是否满足要求。对整个版图进功耗分析,即要进行动态功耗分析跟静态功耗分析,找出主要的功耗单元或者模块,以供优化。
3.9 单元布局与优化(placement & optimistic)
根据floor-plan中的布局规划,摆放网表中调用的所有标准单元,EDA工具自动根据时序约束、布线面积、布线拥堵等综合考虑标准单元的摆放,从而依靠EDA工具完成电路的布局设计和优化。EDA主要进行自动对floor-plan的具体工作的标准单元实现:确定各功能模块的位置和整个芯片的尺寸;确定I/O buffer 的位置,定义电源和地PAD的位置;定义各种物理的组、区域或模块,对大的宏单元进行放置;设计整个供电网络,基于电势降和电迁移进行拓扑优化;通过布局调整、约束修改、属性添加、密度、高速信号分析等手段达到优化的目的。
3.10 时钟树综合
(clock tree synthesis,CTS)与插入:时钟树就是分布在芯片内部的的寄存器跟数字的驱动电流构成的一种树状结构的电路。时钟树综合就是EDA工具按照约束,插入buffer,使时钟的源头(时钟根节点)到达各个需要时钟驱动的器件(各叶子节点,如触发器)的时间基本一致的过程。
由于时钟信号在数字芯片的全局指挥作用,它的分布应该是对称式的连到各个寄存器单元,从而使时钟从同一个时钟源到达各个寄存器时,时钟延迟差异最小。这也是为什么时钟信号需要单独布线的原因。
在单元布局后,布图工具将时钟树插入设计。从DC产生的最初网表(并且输入到布图工具)缺少时钟树信息(整个时钟树网络,包括缓冲器和线网),所以,时钟树一定要插入到原有的网表中并进行形式验证。
一些布图工具通过提供直接的接口给DC来完成这一步骤。时钟树综合插入通常使用EDA工具自动进行。CTS工具,Synopsys的Physical Compiler
3.11 详细布线(routing)
布线就是完成模块、节点的相互连线。EDA工具可以分成全局布线和详细布线。一般情况下先使用EDA工具布线,然后在人工干预的情况下局部自动或者手工进行连接一些比较关键地连线,进行修复连接上的问题和时序约束上的问题。注意,关键路径和时钟上的连接线要尽量最先连接,以免绕线,导致时序问题。
为使布图综合迭代的次数最小并且改进布局质量,在全局布线后,从版图提取时序信息。尽管这些延迟数据不详细布线后提取的数据准确,但它们确实提供了布线后的时序这些估计的延迟被反标注到 Primetime进行分析,并且只有当时序关系满足后,才会进行详细布线。在详细布线完成后,提取芯片的实际时间延迟并且输入到 Prime Time进行分析。IC compiler(ICC)
各种标准单元(基本逻辑门电路)之间的走线。比如我们平常听到的0.13um工艺,或者说90nm工艺,实际上就是这里金属布线可以达到的最小宽度,从微观上看就是MOS管的沟道长度。
3.12 信号完整性分析
(signal competition analysis)SI/IR drop/EM分析:信号完整性分析是通常是进行分析噪声。随着器件尺寸的下降,器件的供电电压、噪声容限均下降。也就是说,也许由于某一根导线可能电阻过大,带来的压降过大,导致器件的供电电压达不到而不能正常工作等等的一系列问题。对这些问题进行分析,是信号完整分析的一部分。
3.13 寄生参数提取
(parasitic extraction):根据布线完成的版图提前RC(电阻电容)参数文件。对EDA工具输入相应的工艺参数(厂家提供)后,EDA工具根据这些参数和版图实际几何形体的面积计算出RC值,然后提取出SPEF format(Standard parasitics Exchange Format)的RC参数,可以直接用于静态时序分析,也可以在计算出相应的路径延时时,用于反标功能后仿真。工具Synopsys的Star-RCXT
由于导线本身存在的电阻,相邻导线之间的互感,耦合电容在芯片内部会产生信号噪声,串扰和反射。这些效应会产生信号完整性问题,导致信号电压波动和变化,如果严重就会导致信号失真错误。提取寄生参数后再次进行分析验证,分析信号完整性问题是非常重要的。
3.14 布图后STA
在布图后,实际提取的延迟被反标注到PrimeTime以提供真实的延迟计算。
使用SDF(标准延迟格式)执行STA(静态时序分析),对逻辑综合优化后的网表在时序上进行验证,检查电路是否存在建立时间和保持时间的违例。工具Synopsys的Prime Time。第二次时序分析。
在布图后,实际提取的延迟被反标注到 Primetime以提供真实的延退计算,这些延迟由连线电容和互连RC延迟所组成。
3.15 后仿真(post-layout simulation)
后仿真也叫门级仿真、时序仿真、带反标的仿真。它是通过采用外部激励和布局布线后产生的标准延时文件(*.sdf),对布局布线后的门级电路网表进行功能和时序验证,来检验门级电路是否符合功能要求。
第二次时序分析,在布图后,实际提取的延迟被反标注到 Primetime以提供真实的延迟计算,这些延迟由连线电容和互连RC延迟所组成。
3.16 工程更改命令(ECO)
engineering change order:在设计的最后阶段发现个别路径有时序问题或者逻辑错误时,通过芯片内部专门留下的寄存器跟组合逻辑,对设计部分进行必要的小范围的修改和重新连线。ECO在是在网表上做文章,在非必须的情况下不要进行ECO。
3.17 版图物理验证
对完成布线的物理版图进行功能和时序上的验证;如LVS(Layout Vs Schematic)网表一致性检查,就是版图与逻辑综合后的门级电路图的对比验证;DRC(Design Rule Checking):几何设计规则检查,检查连线间距,连线宽度等是否满足工艺要求, ERC(Electrical Rule Checking):电气规则检查,检查短路和开路等电气规则违例等等。工具为Synopsys的Hercules。
DRC/LVS :Mentor:calibre,Synopsys:Hercules,Cadence:Diva/Dracula.
POSTSIM:后仿真(提取实际版图参数、电阻、电容,生成带寄生量的器件级网表,进行开关级逻辑模拟或电路模拟,以验证设计出的电路功能的正确性和时序性能等),产生测试向量
实际的后端流程还包括电路功耗分析,以及随着制造工艺不断进步产生的DFM(可制造性设计)问题,在此不说了。物理版图验证完成也就是整个芯片设计阶段完成,下面的就是芯片制造了。
3.18 芯片版图数据
(GDSII) Geometry Data Standard:物理版图以GDSII的文件格式交给芯片代工厂(称为Foundry)在晶圆硅片上做出实际的电路,再进行封装和测试,就得到了我们实际看见的芯片。
模块化设计
模块的扇出是指模块的直属下层模块的个数,如图7.8所示。图7.8中,平均的扇出是2。一般认为,设计得好的系统平均扇出是3或4。
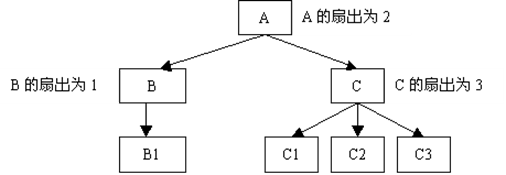
1.10.1 模块的扇出
一个模块的扇出数过大或过小都不理想,过大比过小更严重。一般认为扇出的上限不超过7。扇出过大意味着管理模块过于复杂,需要控制和协调过多的下级。解决的办法是适当增加中间层次。
一个模块的扇入是指有多少个上级模块调用它。扇入越大,表示该模块被更多的上级模块共享。这当然是我们所希望的。但是不能为了获得高扇入而不惜代价,例如把彼此无关的功能凑在一起构成一个模块,虽然扇入数高了,但这样的模块内聚程度必然低。这是我们应避免的。
设计得好的系统,上层模块有较高的扇出,下层模块有较高的扇入。其结构图像清真寺的塔,上面尖,中间宽,下面小。
4. RTL设计步骤
(1)仔细阅读设计规范,了解设计的要求,例如芯片的I/O采用何种标准,有多少PIN脚,采用何种封装形式,时序要求是多少是否需要与其他已有的产品兼容等,规范越清楚越好。
(2)了解芯片中是否用到其他IP,这些IP是否满足功能与性能的要求,这些IP是否经过了验证,如何与这些IP进行接口,这些IP是软核还是硬核。
(3)了解芯片是否需要与其他产品进行兼容, 包括与其他厂商的芯片进行兼容, 是否与以前的产品兼容。兼容性会影响到芯片的功能、寄存器设置、PIN脚分配等。
(4)了解流片所用的工艺及综合库。高水平的RTL设计者必然熟悉综合库,知道综合库中各单元能够提供怎样的性能,从而了解在设计中的一个路径上,最多可以放多少逻辑。例如,一个设计要求能运行在时钟频率100 MHz,而所用的综合库中一个二输入与非门的延迟大约为0. 2ns,则一条路径上差不多可以放50个与非门。有了这种知识,设计者可以写出更为合理的代码。特别是对于数据通路设计,对综合库的了解是很有必要的。
(5)了解芯片的外部接口。例如,与模拟部分接口是怎么样的,接口信号的确切含义是什么,系统是否有PCI或AGP之类的高速接口,这些接口需要自己来实现还是由IP来实现。
(6)了解芯片的时钟。要了解芯片中有多少个时钟,每个时钟的用途是什么,这些时钟来自锁相环还是由其他芯片提供,这些时钟有无相位关系,频率是多少以及时钟的偏差有多大,芯片中是否有分频时钟。
(7)了解芯片对功耗的要求,以决定是否采用低功耗设计技术,以及采用何种低功耗设计技术。低功耗设计技术的基本思想是尽量减少设计中的节点的翻转,例如可以采用并行计算来降低时钟频率、时钟门控(针对模块或寄存器阵列), 等等。
(8)了解芯片对可测性的要求。设计者要了解芯片是采用全扫描还是部分扫描,是否采用内建自测试的方式,是否需要JTAG, 这些对RTL设计都有影响。例如,扫描链的测试覆盖率受限于RTL设计风格。在进行RTL设计时,首先划分好设计的结构。通常来说,一个设计可以大致分为如下几个部分:I/O Pad、时钟生成电路、复位电路、JTAG电路、内核, 如下图所示。
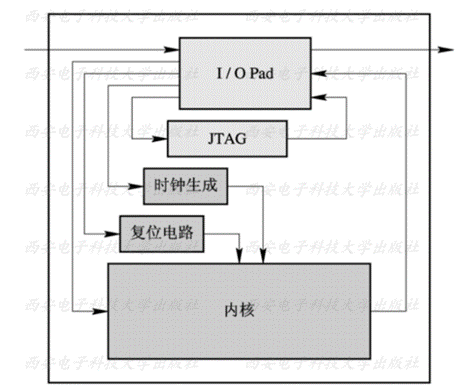
芯片的划分示意图
要与其他设计者交流以确定设计的命名规则、模块划分、各模块的接口,版本控制软件CVS
physical library 物理实现中称为milkway库
SC:standcell
LM
cellview包含cell的具体连线,阱和源漏和金属层信息,framview只有metal
4.1 波形文件
vcd,vpd,shm,fsdb
4.1.1Modelsim -WLF
(Wave Log File)示例:其中,run.do中的内容为要查看的波形信号。这个wlf文件只能由modelsim来生成,也只能通过modelsim来显示。不是一个通用的文件格式
vsim -view vsim.wlf -do run.do //打开csim.wlf
4.1.2 VCD(Value Change Dump)
IEEE1364标准(veriloghdl语言标准)中定义的一种ASCII文件,是通用的文件格式。
它主要包含了头信息,变量的预定义和变量值的变化信息。正是因为它包含了信号的变化信息,就相当于记录了整个仿真的信息,我们可以用这个文件来再现仿真,也就能够显示波形。因为VCD是 Verilog HDL语言标准的一部分,因此所有的verilog的仿真器都能够查看该文件,允许用户在verilog代码中通过系统函数来dump VCD文件。
我们可以通过Verilog HDL的系统函数dumpfile来生成波形,通过dumpvars的参数来规定我们抽取仿真中某些特定模块和信号的数据。特别说明的一点是,正是因为VCD记录了信号的完整变化信息,我们还可以通过VCD文件来估计设计的功耗,而这一点也是其他波形文件所不具备的。Encounter 和PrimeTime PX (Prime Power)都可以通过输入网表文件,带功耗信息的库文件以及仿真后产生的VCD文件来实现功耗分析。示例如下:
//在testbench中加入以下内容
initial begin $dumpfile("*.vcd"); $dumpvars(0,**); end
4.1.3 Debussy/Verdi -FSDB (Fast Signal DataBase)
Spring Soft (Novas)公司 Debussy / Verdi 支持的波形文件,一般较小,使用较为广泛,其余仿真工具如ncsim,modlesim等可以通过加载Verdi 的PLI (一般位于安装目录下的share/pli目录下)而直接dump fsdb文件。
fsdb文件是verdi使用一种专用的数据格式,类似于VCD,但是它是只提出了仿真过程中信号的有用信息,除去了VCD中信息冗余,就像对VCD数据进行了一次huffman编码。因此fsdb数据量小,而且会提高仿真速度。
我们知道VCD文件使用verilog内置的系统函数来实现的,fsdb是通过verilog的PLI接口来实现的,例如$fsdbDumpfile, $fsdbDumpvars等
initial begin $fsdbDumpfile("*.fsdb"); //*代表生成的fsdb的文件名 $fsdbDumpvars(0,**); //**代表测试文件名 end
4.1.4 vpd(VCS DVE)
vpd是Synopsys公司 VCS DVE支持的波形文件,可以用$vcdpluson产生。
先在testbench中加入如下语句:
initial begin $vcdpluson; end
命令调用vcs-compile
vcs -full64 -f file.f -debug_pp +vcd+vcdpluson
## simulate
./simv
生成名为vcdpluson.vpd的文件
3、使用dve查看波形
dve –vpdvcdpluson.vpd
vcs -full64 -f file.f -debug_pp +vcd+vcdpluson
simulate
./simv
4.1.5 fsdb转vcd

4.1.6 STA的文件
SDF、SPEF、WLM:
SDF工具抽出来的延时信息,可以直接反标到电路上,可以被工具读取,一般用于前端仿真。
SPEF抽取net的RC值,为STA计算net delay提供RC,一般用于timing signoff
WLM估算net的RC值,为STA计算net delay提供RC,用于实际绕线前。
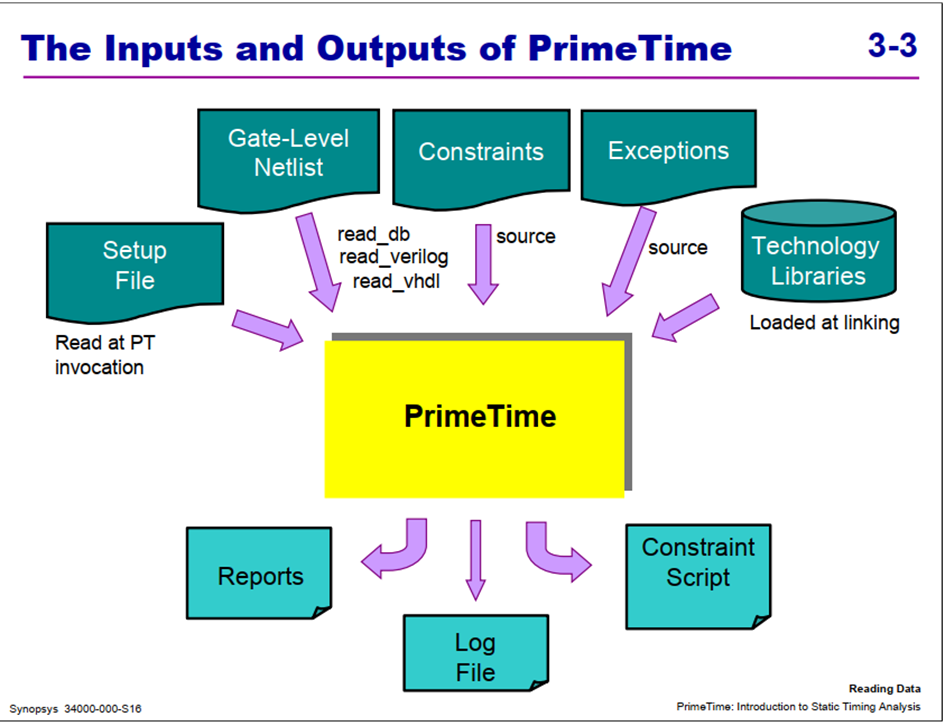
5. PT流程
PrimeTimesetup文件是 .synopsys_pt.setup,约束和例外通常放在“script(s)”中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号