3 pyspark学习---sparkContext概述
1 Tutorial
Spark本身是由scala语言编写,为了支持py对spark的支持呢就出现了pyspark。它依然可以通过导入Py4j进行RDDS等操作。
2 sparkContext
(1)sparkContext是spark运用的入口点,当我们运行spark的时候,驱动启动同时上下文也开始初始化。
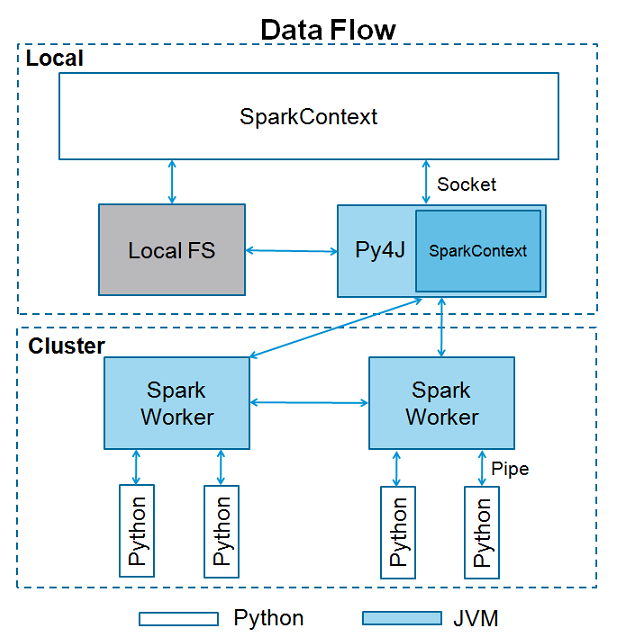
(2)sparkContext使用py4j调用JVM然后创建javaSparkContext,默认为‘sc’,所以如果在shell下就直接用sc.方法就可以。如果你再创建上下文,将会报错cannot run multiple sparkContexts at once哦。结构如下所示
(3)那么一个sparkContext需要哪些内容呢,也就是初始化上下文的时候类有哪些参数呢。
1 class pyspark.SparkContext ( 2 master = None,#我们需要连接的集群url 3 appName = None, #工作项目名称 4 sparkHome = None, #spark安装路径 5 pyFiles = None,#一般为处理文件的路径 6 environment = None, #worker节点的环境变量 7 batchSize = 0, 8 serializer = PickleSerializer(), #rdd序列化器 9 conf = None, 10 gateway = None, #要么使用已经存在的JVM要么初始化一个新的JVM 11 jsc = None, #JavaSparkContext实例 12 profiler_cls = <class 'pyspark.profiler.BasicProfiler'> 13 )
尝试个例子:在pycharm中使用的哟
1 # coding:utf-8 2 from pyspark import SparkContext, SparkConf 3 4 logFile = "./files/test.txt" 5 sc = SparkContext() 6 logData = sc.textFile(logFile).cache() 7 numA = logData.filter(lambda s: 'a' in s).count() 8 numB = logData.filter(lambda s: 'a' in s).count() 9 print "Lines with a: %i, lines with b: %i" % (numA, numB)

加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号