CUDA整理
内存分布模型
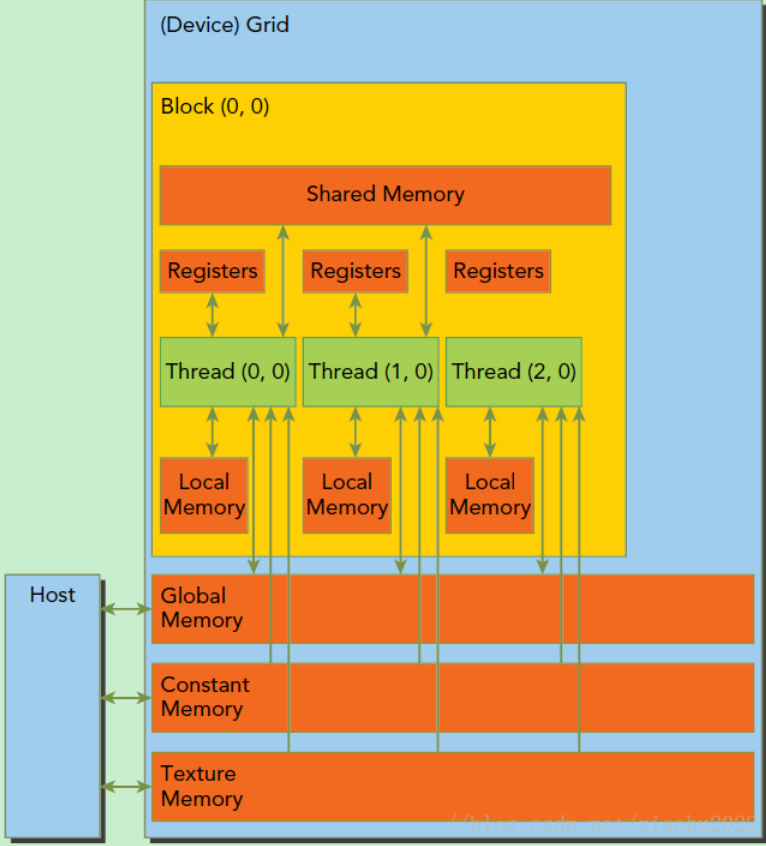
全局内存
通俗意义上的设备内存。
共享内存
1. 位置:设备内存。
2. 形式:关键字__shared__添加到变量声明中。如__shared__ float cache[10]。
3. 目的:对于GPU上启动的每个线程块,CUDA C编译器都将创建该共享变量的一个副本。线程块中的每个线程都共享这块内存,但线程却无法看到也不能修改其他线程块的变量副本。这样使得一个线程块中的多个线程能够在计算上通信和协作。
常量内存
1. 位置:设备内存
2. 形式:关键字__constant__添加到变量声明中。如__constant__ float s[10];。
3. 目的:为了提升性能。常量内存采取了不同于标准全局内存的处理方式。在某些情况下,用常量内存替换全局内存能有效地减少内存带宽。
4. 特点:常量内存用于保存在核函数执行期间不会发生变化的数据。变量的访问限制为只读。NVIDIA硬件提供了64KB的常量内存。不再需要cudaMalloc()或者cudaFree(),而是在编译时,静态地分配空间。
5. 要求:当我们需要拷贝数据到常量内存中应该使用cudaMemcpyToSymbol(),而cudaMemcpy()会复制到全局内存。
6. 性能提升的原因:
6.1. 对常量内存的单次读操作可以广播到其他的“邻近”线程。这将节约15次读取操作。(为什么是15,因为“邻近”指半个线程束,一个线程束包含32个线程的集合。)
6.2. 常量内存的数据将缓存起来,因此对相同地址的连续读操作将不会产生额外的内存通信量。
纹理内存
1. 位置:设备内存
2. 目的:能够减少对内存的请求并提供高效的内存带宽。是专门为那些在内存访问模式中存在大量空间局部性的图形应用程序设计,意味着一个线程读取的位置可能与邻近线程读取的位置“非常接近”。如下图: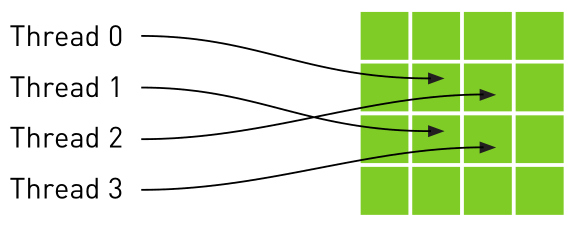
3. 纹理变量(引用)必须声明为文件作用域内的全局变量。
4. 形式:分为一维纹理内存 和 二维纹理内存。
4.1. 一维纹理内存
4.1.1. 用texture<类型>类型声明,如texture<float> texIn。
4.1.2. 通过cudaBindTexture()绑定到纹理内存中。
4.1.3. 通过tex1Dfetch()来读取纹理内存中的数据。
4.1.4. 通过cudaUnbindTexture()取消绑定纹理内存。
4.2. 二维纹理内存
4.2.1. 用texture<类型,数字>类型声明,如texture<float,2> texIn。
4.2.2. 通过cudaBindTexture2D()绑定到纹理内存中。
4.2.3. 通过tex2D()来读取纹理内存中的数据。
4.2.4. 通过cudaUnbindTexture()取消绑定纹理内存。
SM上有共享内存,L1一级缓存,ReadOnly 只读缓存,Constant常量缓存。所有从Dram全局内存中过来的数据都要经过二级缓存,相比之下,更接近SM计算核心的SMEM,L1,ReadOnly,Constant拥有更快的读取速度,SMEM和L1相比于L2延迟低大概20~30倍,带宽大约是10倍。
下面我们了解下共享内存的生命周期和读取性质。
共享内存是在他所属的线程块被执行时建立,线程块执行完毕后共享内存释放,线程块和他的共享内存有相同的生命周期。
对于每个线程对共享内存的访问请求
1. 最好的情况是当前线程束中的每个线程都访问一个不冲突的共享内存,具体是什么样的我们后面再说,这种情况,大家互不干扰,一个事务完成整个线程束的访问,效率最高
2. 当有访问冲突的时候,具体怎么冲突也要后面详细说,这时候一个线程束32个线程,需要32个事务。
3. 如果线程束内32个线程访问同一个地址,那么一个线程访问完后以广播的形式告诉大家
固定内存
1. 位置:主机内存。
2. 概念:也称为页锁定内存或者不可分页内存,操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中。因此操作系统能够安全地使某个应用程序访问该内存的物理地址,因为这块内存将不会破坏或者重新定位。
3. 目的:提高访问速度。由于GPU知道主机内存的物理地址,因此可以通过“直接内存访问DMA(Direct Memory Access)技术来在GPU和主机之间复制数据。由于DMA在执行复制时无需CPU介入。因此DMA复制过程中使用固定内存是非常重要的。
4. 缺点:使用固定内存,将失去虚拟内存的所有功能;系统将更快的耗尽内存。
5. 建议:对cudaMemcpy()函数调用中的源内存或者目标内存,才使用固定内存,并且在不再需要使用它们时立即释放。
6. 形式:通过cudaHostAlloc()函数来分配;通过cudaFreeHost()释放。
7. 只能以异步方式对固定内存进行复制操作。
常量内存和只读缓存:
– 对于核函数都是只读的
– SM上的资源有限,常量缓存64KB,只读缓存48KB
– 常量缓存对于统一读取(读同一个地址)执行更好
– 只读缓存适合分散读取
流
1. 扯一扯:并发重点在于一个极短时间段内运行多个不同的任务;并行重点在于同时运行一个任务。
2. 任务并行性:是指并行执行两个或多个不同的任务,而不是在大量数据上执行同一个任务。
3. 概念:CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。我们可以在流中添加一些操作,如核函数启动,内存复制以及事件的启动和结束等。这些操作的添加到流的顺序也是它们的执行顺序。可以将每个流视为GPU上的一个任务,并且这些任务可以并行执行。
4. 硬件前提:必须是支持设备重叠功能的GPU。支持设备重叠功能,即在执行一个核函数的同时,还能在设备与主机之间执行复制操作。
5. 声明与创建:声明cudaStream_t stream;,创建cudaSteamCreate(&stream);。
6. cudaMemcpyAsync():前面在cudaMemcpy()中提到过,这是一个以异步方式执行的函数。在调用cudaMemcpyAsync()时,只是放置一个请求,表示在流中执行一次内存复制操作,这个流是通过参数stream来指定的。当函数返回时,我们无法确保复制操作是否已经启动,更无法保证它是否已经结束。我们能够得到的保证是,复制操作肯定会当下一个被放入流中的操作之前执行。传递给此函数的主机内存指针必须是通过cudaHostAlloc()分配好的内存。(流中要求固定内存)
7. 流同步:通过cudaStreamSynchronize()来协调。
8. 流销毁:在退出应用程序之前,需要销毁对GPU操作进行排队的流,调用cudaStreamDestroy()。
9. 针对多个流:
9.1. 记得对流进行同步操作。
9.2. 将操作放入流的队列时,应采用宽度优先方式,而非深度优先的方式,换句话说,不是首先添加第0个流的所有操作,再依次添加后面的第1,2,…个流。而是交替进行添加,比如将a的复制操作添加到第0个流中,接着把a的复制操作添加到第1个流中,再继续其他的类似交替添加的行为。
9.3. 要牢牢记住操作放入流中的队列中的顺序影响到CUDA驱动程序调度这些操作和流以及执行的方式。
技巧
1. 当线程块的数量为GPU中处理数量的2倍时,将达到最优性能。
2. 核函数执行的第一个计算就是计算输入数据的偏移。每个线程的起始偏移都是0到线程数量减1之间的某个值。然后,对偏移的增量为已启动线程的总数。
参考资料:
【1】https://blog.csdn.net/xiaohu2022/article/details/79599947
【2】https://blog.csdn.net/ren1335654481/article/details/54405769
【3】CUDA教程https://face2ai.com/category/cuda/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号