1 简介
第1章简介....................................................................................................................................3
1.1 计算机网络,分组报文和协议........................................................................................3
1.2 关于地址............................................................................................................................6
1.3 关于名字............................................................................................................................8
1.4 客户端和服务器................................................................................................................8
1.5 什么是套接字....................................................................................................................9
1.6 练习..................................................................................................................................10
这一章的主要内容总结:
1、socket是什么?
socket是一个抽象层,应用程序通过它来在网络中发送和接收数据,由一个TCP/IP套接字由一个互联网地址,一个端对端协议(TCP或UDP协议)以及一个端口号唯一确定。
Java语言从一开始就是为了让人们使用互联网而设计的,它为实现程序的相互通信提供了许多有用的抽象应用程序接口(API, Application Programming Interface),这类应用程序接口被称为套接字(sockets)。
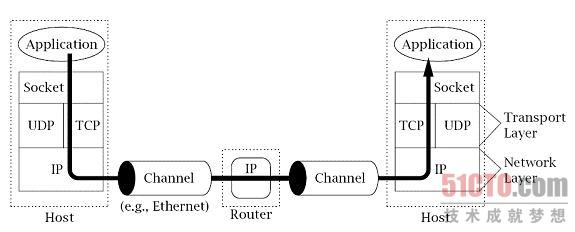
IP协议层之上称为传输层(transport layer)。
它提供了两种可选择的协议:TCP协议和UDP协议。
这两种协议都建立在IP层所提供的服务基础上,但根据应用程序协议(application protocols)的不同需求,它们使用了不同的方法来实现不同方式的传输。
TCP协议和UDP协议有一个共同的功能,即寻址。
回顾一下,IP协议只是将分组报文分发到了不同的主机,很明显,还需要更细粒度的寻址将报文发送到主机中指定的应用程序,因为同一主机上可能有多个应用程序在使用网络。
TCP协议和UDP协议使用的地址叫做端口号(port numbers),都是用来区分同一主机中的不同应用程序。
TCP协议和UDP协议也称为端到端传输协议(end-to-end transport protocols),因为它们将数据从一个应用程序传输到另一个应用程序,
而IP协议只是将数据从一个主机传输到另一主机。
TCP协议能够检测和恢复IP层提供的主机到主机的信道中可能发生的报文丢失、重复及其他错误。TCP协议提供了一个可信赖的字节流(reliable byte-stream)信道,这样应用程序就不需要再处理上述的问题。
TCP协议是一种面向连接(connection-oriented)的协议:在使用它进行通信之前,两个应用程序之间首先要建立一个TCP连接,这涉及到相互通信的两台电脑的TCP部件间完成的握手消息(handshake messages)的交换。
使用TCP协议在很多方面都与文件的输入输出(I/O, Input/Output)相似。实际上,由一个程序写入的文件再由另一个程序读取就是一个TCP连接的适当模型。
另一方面,UDP协议并不尝试对IP层产生的错误进行修复,它仅仅简单地扩展了IP协议"尽力而为"的数据报服务,使它能够在应用程序之间工作,而不是在主机之间工作。因此,使用了UDP协议的应用程序必须为处理报文丢失、顺序混乱等问题做好准备。
在TCP/IP协议中,有两部分信息用来定位一个指定的程序:互联网地址(Internet address)和端口号(port number)。其中互联网地址由IP协议使用,而附加的端口地址信息由传输协议(TCP或IP协议)对其进行解析。
为了便于人们使用互联网地址(相对于程序内部的表示),两个版本的IP协议有不同的表示方法。
IPv4地址被表示为一组4个十进制数,每两个数字之间由圆点隔开(如:10.1.2.3),这种表示方法叫做点分形式(dotted-quad)。
点分形式字符串中的4个数字代表了互联网地址的4个字节,也就是说,每个数字的范围是0到255。
另一方面,IPv6地址的16个字节由几组16进制的数字表示,这些16进制数之间由分号隔开(如:2000:fdb8:0000:0000:0001:00ab:853c:39a1)。
每组数字分别代表了地址中的两个字节,并且每组开头的0可以省略,因此前面的例子中,第5组和第6组数字可以缩写为:1:ab:。
甚至,只包含0的连续组可以全部省略(但在一个地址中只能这样做一次)。
因此,前面的例子的完整地址可以表示为2000:fdb8::1:00ab:853c:39a1。
IPv6是16个字节,每组4个16进制数字,因为每个字节是8位,每个16进制占4位,所以ipv6每组16占也就是2个字节,所以IPv6一共8组。
一个互联网地址就能定位这条主机。但是反过来,一台主机并不对应一个互联网地址。因为每台主机可以有多个接口,每个接口又可以有多个地址。(实际上一个接口可以同时拥有IPv4地址和IPv6地址)
每个版本的IP协议都定义了一些特殊用途的地址。其中值得注意的一个是回环地址(loopback address),该地址总是被分配个一个特殊的回环接口(loopback interface)。回环接口是一种虚拟设备,它的功能只是简单地将发送给它的报文直接回发给发送者。回环接口在测试中非常有用,因为发送给这个地址的报文能够立即返回到目标地址。而且每台主机上都有回环接口,即使当这台计算机没有其他接口(也就是说没有连接到网络),回环接口也能使用。
IPv4的回环地址是127.0.0.1[ ],IPv6的回环地址是0:0:0:0:0:0:0:1。
端口号是一组16位的无符号二进制数,每个端口号的范围是1到65535。(0被保留)
IPv4地址中的另一种特殊用途的保留地址包括那些"私有用途"的地址。它们包括IPv4中所有以10或192.168开头的地址,以及第一个数是172,第二个数在16到31的地址。(在IPv6中没有相应的这类地址)这类地址最初是为了在私有网络中使用而设计的,不属于公共互联网的一部分。现在这类地址通常被用在家庭或小型办公室中,这些地方通过NAT(Network Address Translation,网络地址转换)设备连接到互联网。NAT设备的功能就像一个路由器,转发分组报文时将转换(重写)报文中的地址和端口。更准确地说,它将一个接口中报文的私有地址端口对(private address, port pairs)映射成另一个接口中的公有地址端口对(public address, port pairs)。这就使一小组主机(如家庭网络)能够有效地共享同一个IP地址。重要的是这些内部地址不能从公共互联网访问。如果你在拥有私有类型地址的计算机上试验本书的例子,并试图与另一台没有这类地址的主机进行通信,通常只有这台拥有私有类型地址的主机发起的通信才能成功。
相关的类型的地址包括本地链接(link-local),或称为"自动配置"地址。IPv4中,这类地址由169.254开头,在IPv6中,前16位由FE8开头的地址是本地链接地址。这类地址只能用来在连接到同一网络的主机之间进行通信,路由器不会转发这类地址的信息。
IPv4中的多播地址在点分格式中,第一个数字在224到239之间。IPv6中,多播地址由FF开始。
名字解析服务可以从各种各样的信息源获取信息。两个主要的信息源是域名系统(DNS,Domain Name System)和本地配置数据库。DNS[ ]是一种分布式数据库,它将像www.mkp.com这样的域名映射到真实的互联网地址和其他信息上。DNS协议[ ]允许连接到互联网的主机通过TCP或UDP协议从DNS数据库中获取信息。本地配置数据库通常是一种与具体操作系统相关的机制,用来实现本地名称与互联网地址的映射。
客户端(client)和服务器(server)这两个术语代表了两种角色:客户端是通信的发起者,而服务器程序则被动等待客户端发起通信,并对其作出响应。客户端与服务器组成了应用程序(application)。客户端和服务器这两个术语对典型的情况作出了描述,服务器具有一定的特殊能力,如提供数据库服务,并使任何客户端能够与之通信。
一个程序是作为客户端还是服务器,决定了它在与其对等端(peer)建立通信时使用的套接字API的形式(客户端的对等端是服务器,反之亦然)。更进一步来说,客户端与服务器端的区别非常重要,因为客户端首先需要知道服务器的地址和端口号,反之则不需要。如果有必要,服务器可以使用套接字API,从收到的第一个客户端通信消息中获取其地址信息。这与打电话非常相似:被呼叫者不需要知道拨电话者的电话号码。就像打电话一样,只要通信连接建立成功,服务器和客户端之间就没有区别了。
客户端如何才能找到服务器的地址和端口号呢?通常情况,客户端知道服务器的名字,例如使用URL(Universal Resource Locator,统一资源定位符)如http://www.mkp.com,再通过名字解析服务获取其相应的互联网地址。
获取服务器的端口号则是另一种情况。从原理上来讲,服务器可以使用任何端口号,但客户端必须能够获知这些端口号。在互联网上,一些常用的端口号被约定赋给了某些应用程序。例如,端口号21被FTP(File Transfer Protocol,文件传输协议)使用。当你运行FTP客户端应用程序时,它将默认通过这个端口号连接服务器。互联网的端口号授权机构维护了一个包含所有已约定使用的端口号列表(见http://www.iana.org/assignments/port-numbers)。
1.5 什么是套接字
Socket(套接字)是一种抽象层,应用程序通过它来发送和接收数据,就像应用程序打开一个文件句柄,将数据读写到稳定的存储器上一样。一个socket允许应用程序添加到网络中,并与处于同一个网络中的其他应用程序进行通信。一台计算机上的应用程序向socket写入的信息能够被另一台计算机上的另一个应用程序读取,反之亦然。
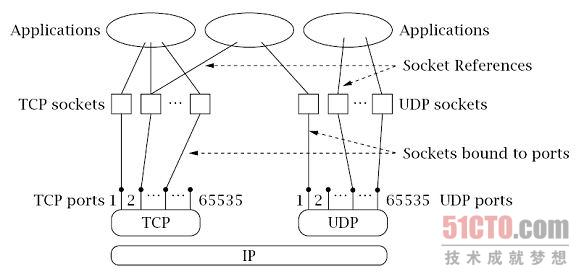
图1.2描述了一个主机中,应用程序、套接字抽象层、协议、端口号之间的逻辑关系。值得注意的是一个套接字抽象层可以被多个应用程序引用。(端口复用相关内容请参考 https://blog.csdn.net/jianchaolv/article/details/61924402)每个使用了特定套接字的程序都可以通过那个套接字进行通信。前面已提到,每个端口都标识了一台主机上的一个应用程序。实际上,一个端口确定了一台主机上的一个套接字。从图1.2中我们可以看到,主机中的多个程序可以同时访问同一个套接字。在实际应用中,访问相同套接字的不同程序通常都属于同一个应用(例如,Web服务程序的多个拷贝),但从理论上讲,它们是可以属于不同应用的。
不同类型的socket与不同类型的底层协议族以及同一协议族中的不同协议栈相关联,本书只涵盖了TCP/IP协议族的内容。现在TCP/IP协议族中的主要socket类型为流套接字(sockets sockets)和数据报套接字(datagram sockets)。
流套接字将TCP作为其端对端协议(底层使用IP协议),提供了一个可信赖的字节流服务。一个TCP/IP流套接字代表了TCP连接的一端。
数据报套接字使用UDP协议(底层同样使用IP协议),提供了一个"尽力而为"(best-effort)的数据报服务,应用程序可以通过它发送最长65500字节的个人信息。
当然,其他协议族也支持流套接字和数据报套接字,但本书只对TCP流套接字和UDP数据报套接字进行讨论。
一个TCP/IP套接字由一个互联网地址,一个端对端协议(TCP或UDP协议)以及一个端口号唯一确定

 浙公网安备 33010602011771号
浙公网安备 33010602011771号