
102302149赖翊煊数据采集与融合技术第三次作业

作业1
部分代码及其结果展示
点击查看代码
import os
import time
import urllib.request
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
from bs4.dammit import UnicodeDammit
class ImageDownloader:
def __init__(self):
# 基础配置
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}
self.image_dir = "images"
self.max_pages = 4 # 最大页数
self.max_images = 49 # 最大图片数
self.downloaded_count = 0 # 计数变量
os.makedirs(self.image_dir, exist_ok=True) # 自动创建目录
def _format_url(self, img_url):
"""统一图片URL格式"""
if img_url.startswith('//'):
return f'http:{img_url}'
elif img_url.startswith('/'):
return f'http://www.weather.com.cn{img_url}'
elif not img_url.startswith('http'):
return f'http://www.weather.com.cn/{img_url}'
return img_url
def download_image(self, img_url, page_url):
"""下载单张图片(带计数控制)"""
if self.downloaded_count >= self.max_images:
return False
try:
img_url = self._format_url(img_url)
req = urllib.request.Request(img_url, headers=self.headers)
with urllib.request.urlopen(req, timeout=10) as res:
img_data = res.read()
# 生成文件名
filename = os.path.basename(img_url.split('?')[0]) or f"image_{self.downloaded_count + 1}.jpg"
if '.' not in filename:
filename += '.jpg'
filepath = os.path.join(self.image_dir, filename)
with open(filepath, 'wb') as f:
f.write(img_data)
self.downloaded_count += 1
print(f"[{self.downloaded_count}/{self.max_images}] 保存: {filename}")
return True
except Exception as e:
print(f"下载失败 {img_url}: {str(e)[:30]}")
return False
def get_images_from_page(self, url):
"""从页面提取图片URL列表"""
try:
req = urllib.request.Request(url, headers=self.headers)
with urllib.request.urlopen(req, timeout=10) as res:
data = UnicodeDammit(res.read(), ["utf-8", "gbk"]).unicode_markup
return [img.get('src') for img in BeautifulSoup(data, "lxml").find_all('img') if img.get('src')]
except Exception as e:
print(f"页面解析失败 {url}: {str(e)}")
return []
def get_target_pages(self):
"""获取目标页面列表(限制页数)"""
base = "http://www.weather.com.cn"
pages = [
base,
f"{base}/weather/101010100.shtml", # 北京
f"{base}/weather/101020100.shtml", # 上海
f"{base}/weather/101280101.shtml", # 广州
f"{base}/weather/101280601.shtml" # 福州
]
return pages[:self.max_pages]
def single_thread(self):
"""单线程下载"""
start = time.time()
self.downloaded_count = 0
pages = self.get_target_pages()
print(f"单线程模式:{len(pages)}页,最多{self.max_images}张图")
for page_url in pages:
if self.downloaded_count >= self.max_images:
break
print(f"\n处理页面: {page_url.split('/')[-1]}")
for img_url in self.get_images_from_page(page_url):
if not self.download_image(img_url, page_url) or self.downloaded_count >= self.max_images:
break
print(f"\n单线程完成:{self.downloaded_count}张,耗时{time.time()-start:.2f}秒")
def multi_thread(self, threads=5):
"""多线程下载"""
start = time.time()
self.downloaded_count = 0
pages = self.get_target_pages()
print(f"多线程模式({threads}线程):{len(pages)}页,最多{self.max_images}张图")
with ThreadPoolExecutor(threads) as executor:
for page_url in pages:
if self.downloaded_count >= self.max_images:
break
print(f"\n处理页面: {page_url.split('/')[-1]}")
for img_url in self.get_images_from_page(page_url):
if self.downloaded_count >= self.max_images:
break
executor.submit(self.download_image, img_url, page_url)
print(f"\n多线程完成:{self.downloaded_count}张,耗时{time.time()-start:.2f}秒")
if __name__ == "__main__":
downloader = ImageDownloader()
# 先运行单线程再运行多线程
downloader.single_thread()
downloader.multi_thread()
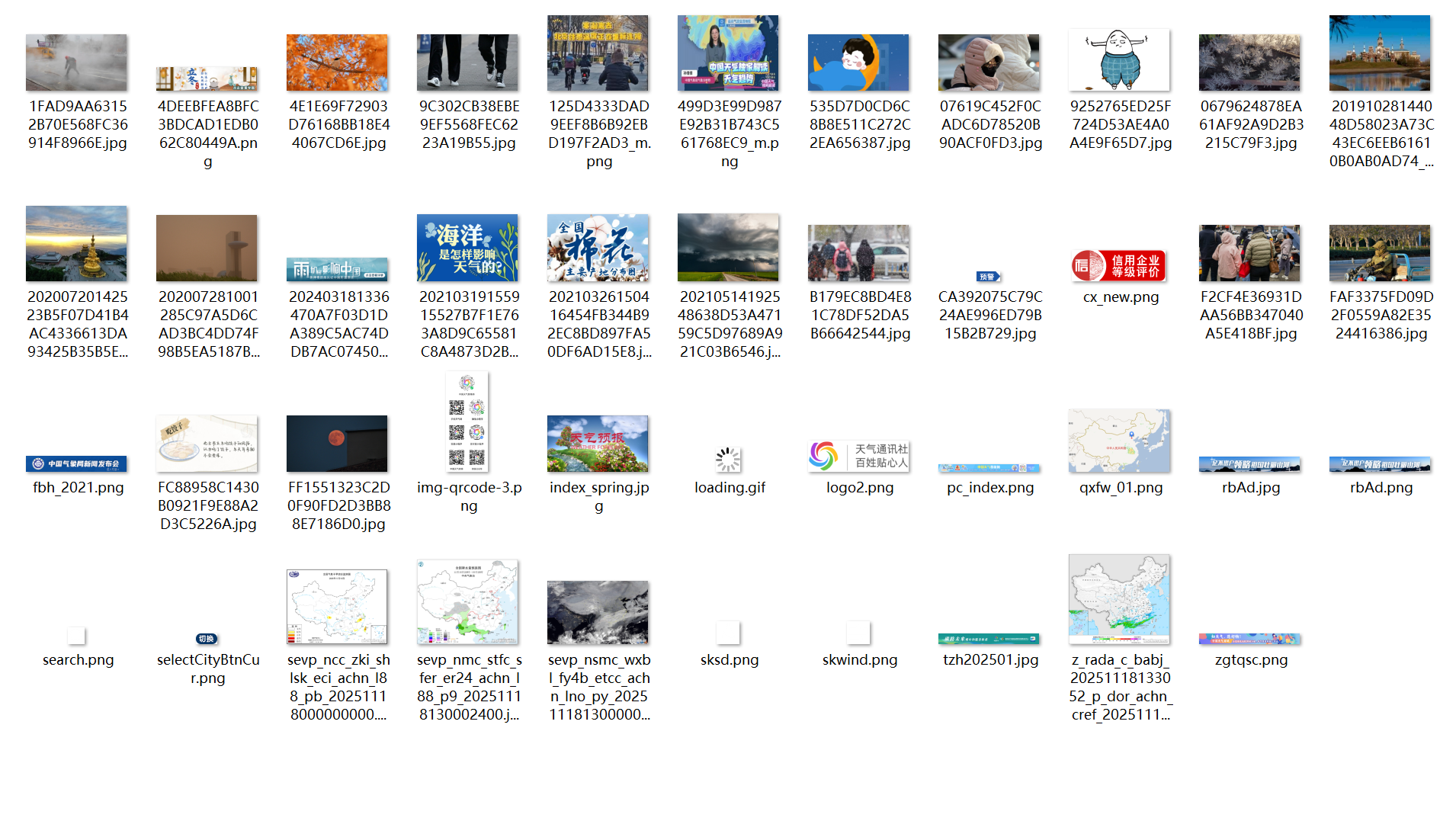
心得体会
通过本次作业,我巩固了网络请求、HTML 解析、多线程编程等技能,提升了问题排查与需求落地能力。同时也发现不足:缺乏图片去重机制、多线程未完全规避共享变量冲突、应对反爬能力有限。
此次实践让我深刻体会到,编程学习需理论结合实际,只有在解决具体问题的过程中,才能真正掌握技术的核心逻辑与应用场景。
作业2
部分代码及其结果展示
点击查看代码
import scrapy
from eastmoney_stock.items import EastmoneyStockItem
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['eastmoney.com']
start_urls = ['https://quote.eastmoney.com/center/gridlist.html#hs_a_board']
def parse(self, response):
stock_rows = response.xpath('//tbody/tr')
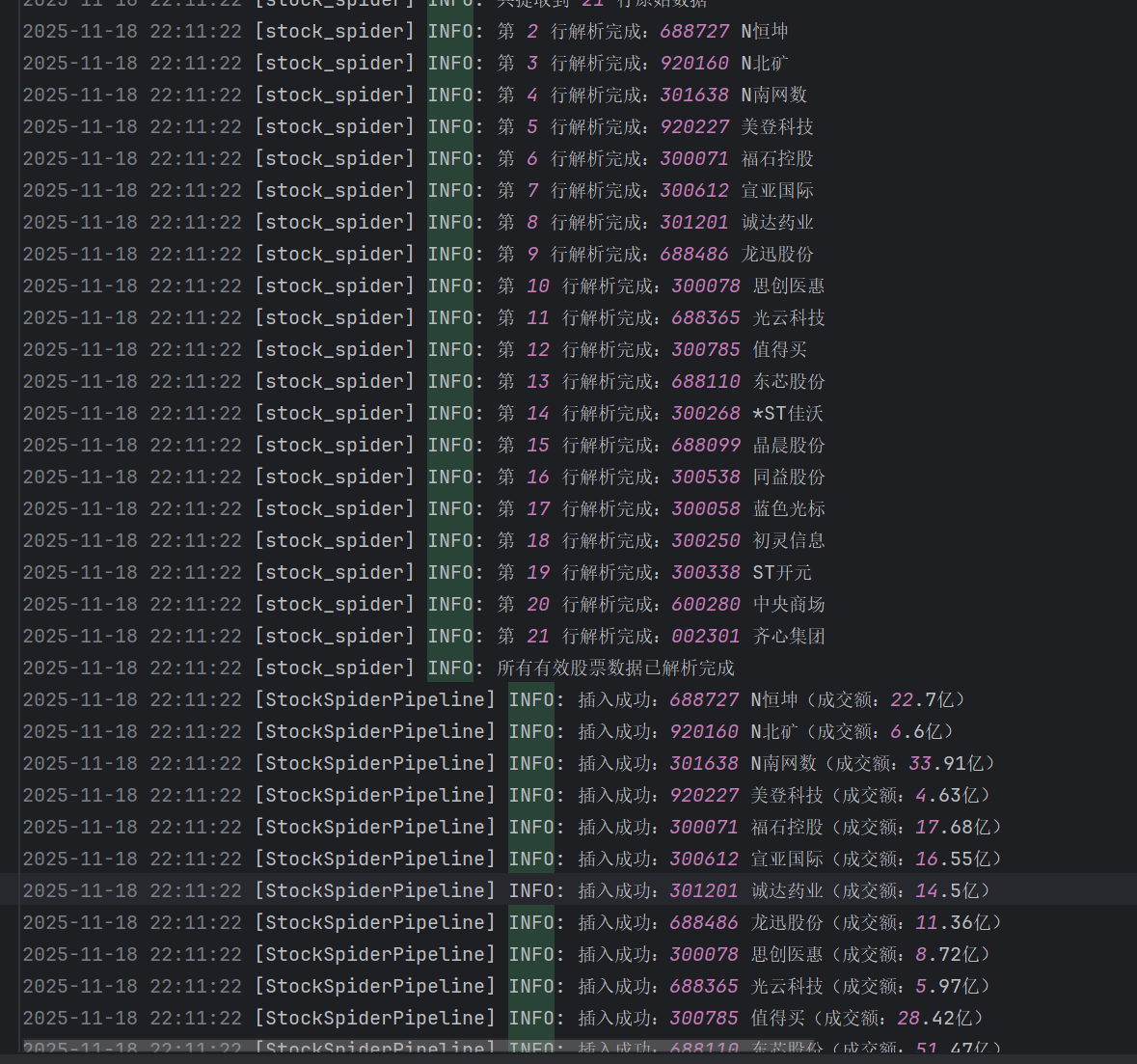
self.logger.info(f"共提取到 {len(stock_rows)} 行原始数据")
for row_idx, row in enumerate(stock_rows, 1):
columns = [col.strip() for col in row.xpath('./td//text()').getall() if col.strip()]
self.logger.debug(f"第 {row_idx} 行原始列数据:{columns}(共 {len(columns)} 列)")
if row_idx == 1:
self.logger.debug(f"第 {row_idx} 行,跳过")
continue
if len(columns) != 20:
self.logger.debug(f"第 {row_idx} 行列数异常({len(columns)}列),跳过")
continue
item = EastmoneyStockItem()
item['serial_id'] = columns[0] # 序号
item['stock_code'] = columns[1] # 股票代码
item['stock_name'] = columns[2] # 股票名称
item['latest_price'] = columns[6] # 最新价
item['price_change_rate'] = columns[7] # 涨跌幅
item['price_change_amount'] = columns[8] # 涨跌额
item['volume'] = columns[9] # 成交量(手)
item['turnover'] = columns[10] # 成交额
item['amplitude'] = columns[11] # 振幅
item['highest_price'] = columns[12] # 最高
item['lowest_price'] = columns[13] # 最低
item['opening_price'] = columns[14] # 今开
item['previous_close'] = columns[15] # 昨收
self.logger.info(f"第 {row_idx} 行解析完成:{columns[1]} {columns[2]}")
yield item
self.logger.info(f"所有有效股票数据已解析完成")
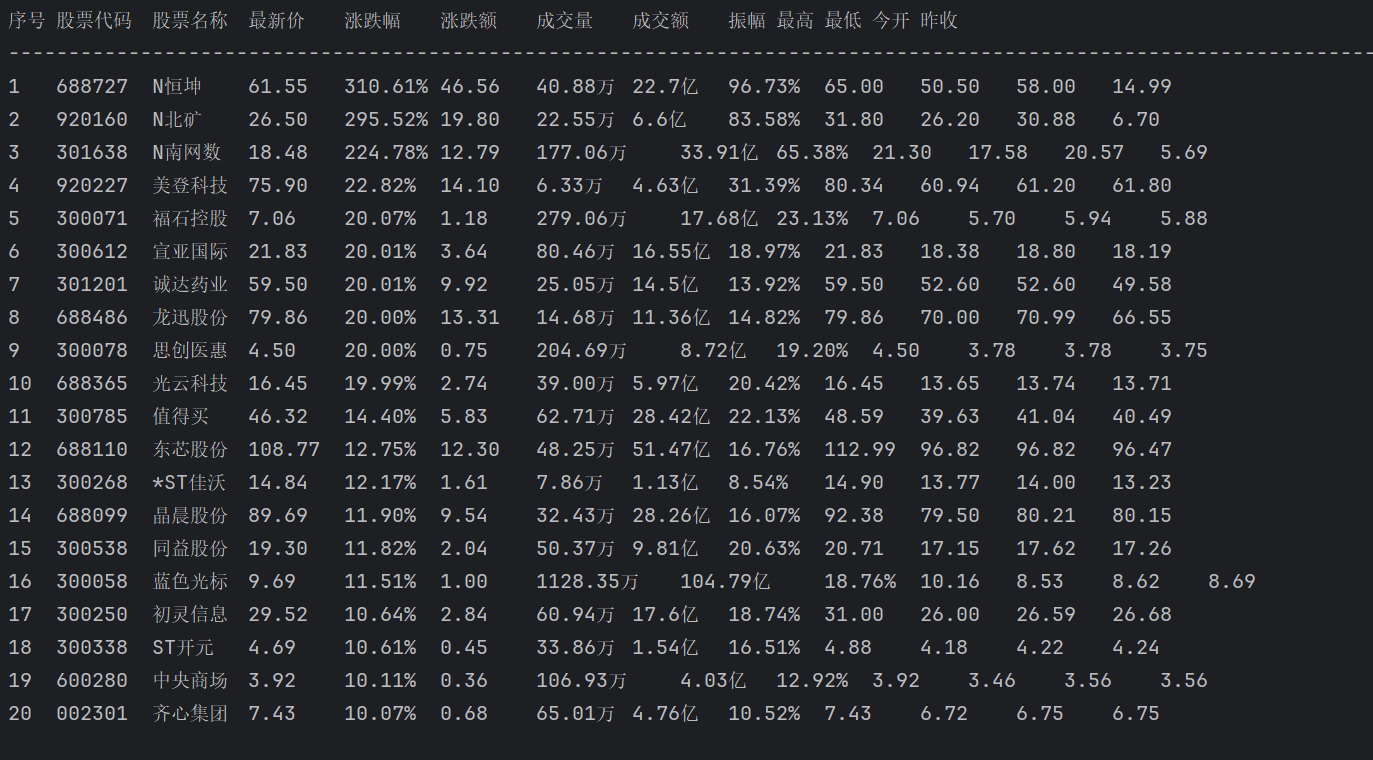
心得体会
1.在数据处理部分遇到了问题,我统一转换为以 “亿” 为单位的数值
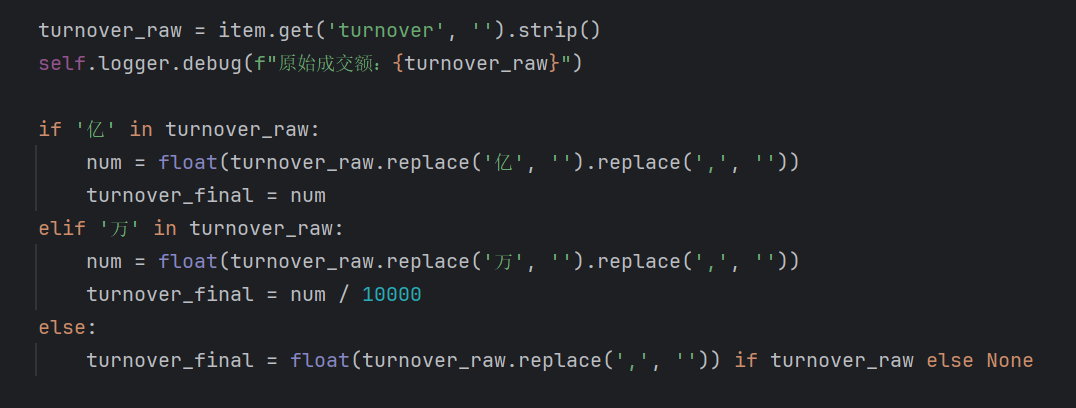
2.因为相对路径查找不到驱动,所以我使用了绝对路径来进行网页初始化。
3.由于页面内容出现需要一定时间,所以我将等待时间设为10秒,否则可能会出现爬取不到内容的问题
实验中,我用Item定义股票数据字段(如股票代码bStockNo、涨跌幅fChangeRate等),通过 XPath 精准提取页面表格数据;借助 Selenium 解决动态加载问题,确保数据完整获取;在Pipeline中实现 SQL 异步存储,同时处理数据序列化与去重。
过程中也遇到挑战:东方财富网页面动态渲染导致初始 XPath 匹配失效,通过 Selenium 等待页面加载后再解析得以解决;数据库字段类型与爬取数据格式不匹配,调整表结构并在 Pipeline 中添加数据转换逻辑后正常存储。
此次实验不仅巩固了 Scrapy 框架的使用技巧,更理解了动态页面爬取与数据持久化的完整流程,提升了问题排查与方案优化能力,为后续复杂爬虫项目积累了实践经验。
作业3
部分代码及其结果展示
点击查看代码
import scrapy
import os
from boc_exchange.items import BocExchangeItem
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 保存页面HTML到本地(用于调试)
self.save_page_html(response)
# 匹配表格中所有数据行(排除表头行)
rows = response.xpath('//table/tr')[1:] # [1:] 跳过表头行(第一行是<th>)
self.logger.info(f"找到{len(rows)}行数据记录")
for i, row in enumerate(rows):
try:
# 提取货币名称(第1列)
currency = row.xpath('./td[1]/text()').get()
if not currency or currency.strip() == '':
self.logger.warning(f"第{i + 1}行无有效货币名称,跳过")
continue
item = BocExchangeItem()
# 列对应关系(根据你提供的HTML):
# 列1:货币名称 → currency
# 列2:现汇买入价 → tbp
# 列3:现钞买入价 → cbp
# 列4:现汇卖出价 → tsp
# 列5:现钞卖出价 → csp
# 列6:中行折算价(暂不提取)
# 列7:发布日期(包含日期时间)
# 列8:发布时间(暂不提取,用列7的完整时间)
item['currency'] = currency.strip()
item['tbp'] = row.xpath('./td[2]/text()').get(default='').strip()
item['cbp'] = row.xpath('./td[3]/text()').get(default='').strip()
item['tsp'] = row.xpath('./td[4]/text()').get(default='').strip()
item['csp'] = row.xpath('./td[5]/text()').get(default='').strip()
# 提取发布时间(第7列,格式:2025.11.18 20:54:39)
raw_time = row.xpath('./td[7]/text()').get(default='').strip()
item['time'] = raw_time.replace('.', '-')
self.logger.info(f"第{i + 1}行提取成功: {item}")
yield item
except Exception as e:
self.logger.error(f"第{i + 1}行提取失败: {str(e)}")
def save_page_html(self, response):
"""保存页面HTML到本地用于调试"""
if not os.path.exists('html_debug'):
os.makedirs('html_debug')
with open('html_debug/boc_exchange.html', 'w', encoding='utf-8') as f:
f.write(response.text)
self.logger.info("页面HTML已保存到html_debug文件夹")
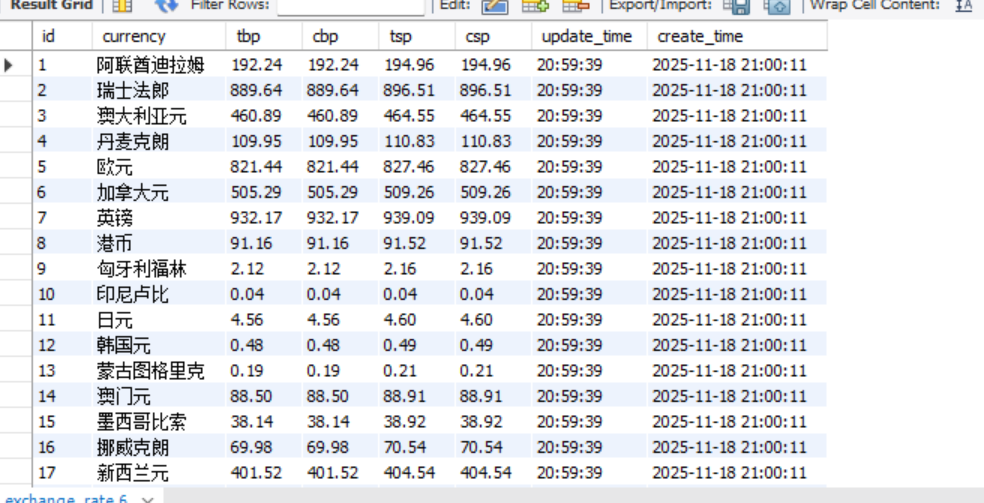
由于一开始使用body定位,但是一直爬取不到数据,所以我就把爬到到的页面源码保存下来,发现与控制台的有些许区别
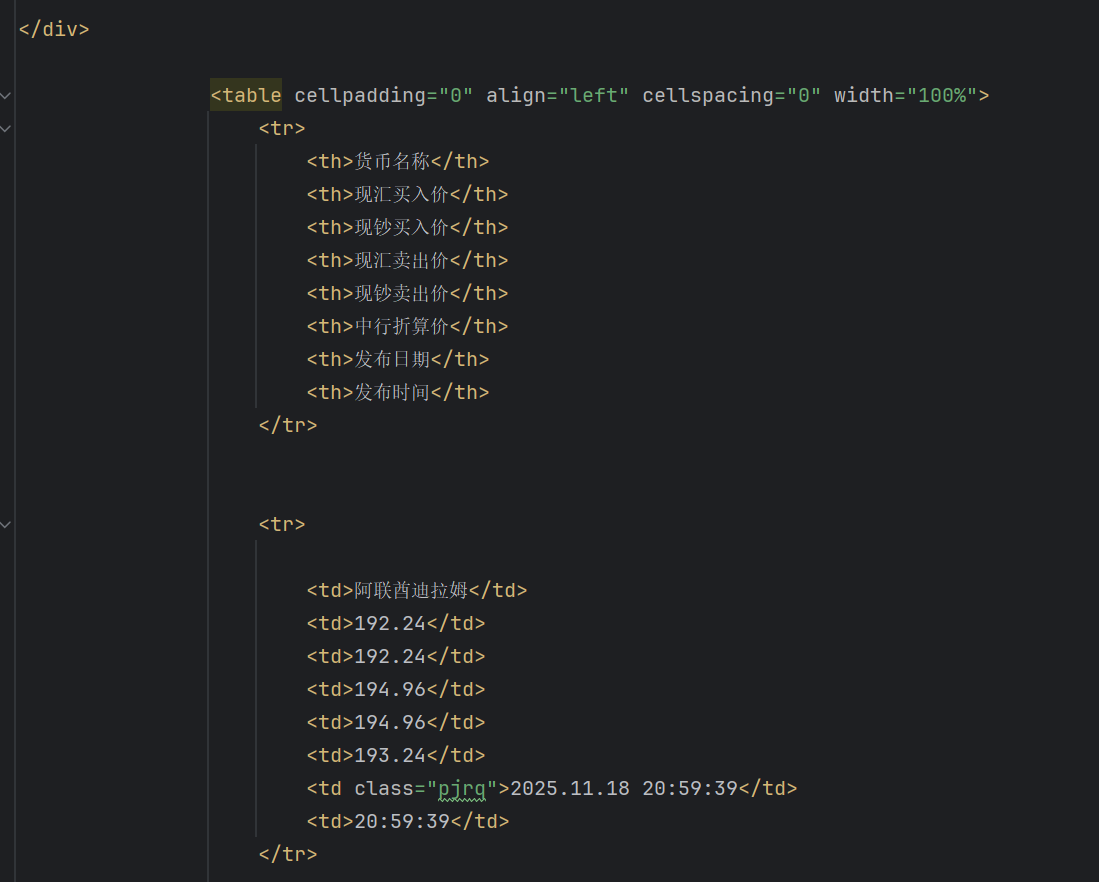
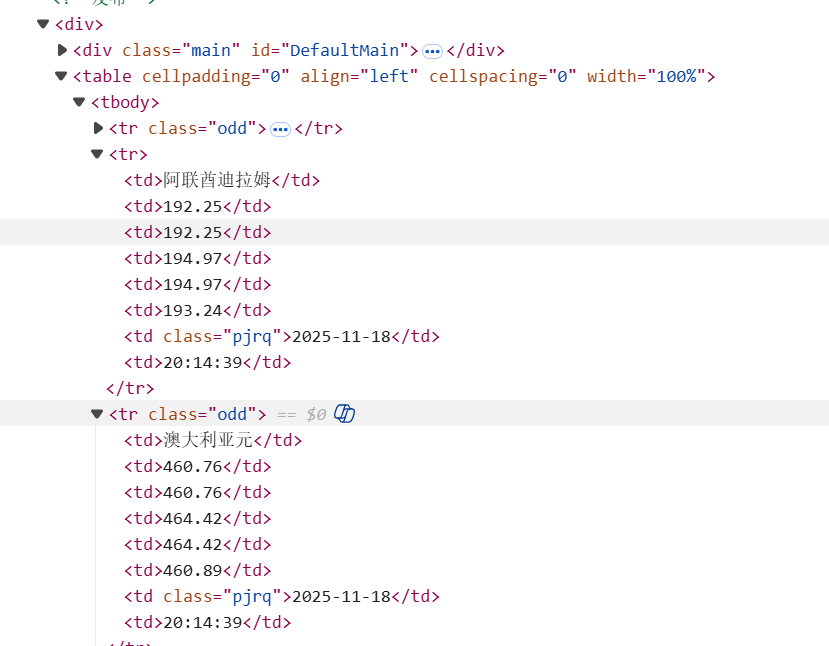
后面调整了匹配规则为//table/tr就成功爬取到内容了。
心得体会
由于一开始一直爬取不到有效信息,所以我选择先将页面源码爬取下来进行检验,发现了Xpath部分的错误,然后就爬取到了股票内容了。
本次实验采用 Scrapy+XPath+MySQL 技术路线爬取中国银行网外汇数据,熟练掌握了 Scrapy 中 Item、Pipeline 的数据序列化与存储方法,收获显著。
我通过 Item 明确定义 Currency(货币名称)、TBP(现汇买入价)等核心字段,确保数据结构规范;利用 XPath 精准定位页面表格数据,解决了 HTML 结构解析难题;在 Pipeline 中实现 MySQL 异步存储,同时处理数据序列化与重复数据更新,保障数据持久化的高效与准确。
针对网站表格动态加载与数据格式差异问题,通过优化 XPath 匹配规则、添加数据清洗逻辑得以解决。此次实践不仅巩固了 Scrapy 框架核心组件的使用技巧,更理清了 "数据提取 - 序列化 - 存储" 的完整流程,提升了动态页面爬取与数据库交互的实战能力,为后续数据采集项目奠定了坚实基础。
https://gitee.com/lai-yixuan/2025_crawl_project/tree/master/作业3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号