
jdk1.8 HashMap底层数据结构:散列表+链表+红黑树(图解+源码)
一、前言
本文由jdk1.8源码整理而得,附自制jdk1.8底层数据结构图,并截取部分源码加以说明结构关系。
二、jdk1.8 HashMap底层数据结构图
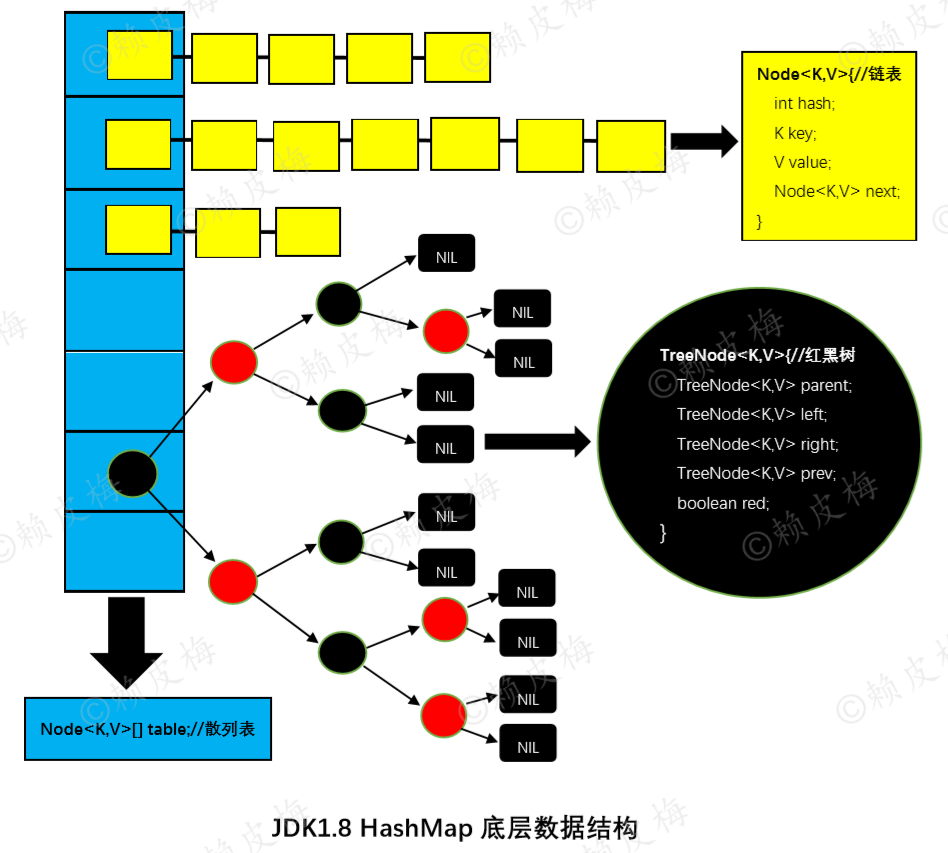
三、源码
1.散列表(Hash table,也叫哈希表):
/** * 表,第一次使用时初始化(而非实例化集合时进行初始化),并根据需要调整大小。当分配时,长度总是2的幂。(在某些操作中,我们还允许长度为零,以允许当前不需要的引导机制。)
*/ transient Node<K,V>[] table;
2.链表:
/** * Basic hash bin node, used for most entries. (See below for * TreeNode subclass, and in LinkedHashMap for its Entry subclass.) */ static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next;
…… }
3.红黑树:
/** * Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn * extends Node) so can be used as extension of either regular or * linked node. */ static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; …… }
四、问题探究
1.散列表后面跟的“链表、红黑树”是怎么来的,都解决了哪些问题?
答:
①链表的由来:Hash碰撞:不同的元素通过hash算法可能会得到相同的hash值,如果都放同一个桶里,后面放进去的就会覆盖前面放的,所以为了解决hash碰撞时元素被覆盖的问题,就有了在桶里放链表。
②红黑树的由来:假设现在HashMap集合中大多数的元素都放到了同一个桶里(由hash值计算而得的桶的位置相同),那么这些元素就在这个桶后面连成了链表。现在需要查询某个元素,那么此时的查询效率就很慢了,它是在做链表查询( O(N) 的查询效率)。为了解决这个问题,就引入了红黑树( log(n) 的查询效率):当链表到达一定长度时就在链表的后面创建红黑树。
③其实,“尽量避免hash 冲突,让元素较为均匀的放置到每个桶”才是查询效率最高的( O(1) 的查询效率),这和hash算法的实现息息相关,这里不做深究。
2.如图可知,散列表后面跟的数据结构有可能是链表,也有可能是红黑树。散列表后面跟什么数据结构是怎么确定的?
答:
①链表节点转换成红黑树节点的阈值, 节点数 >= 8 就转:
static final int TREEIFY_THRESHOLD = 8;
②红黑树节点转换链表节点的阈值, 节点数 <= 6 就转:
static final int UNTREEIFY_THRESHOLD = 6;
③转红黑树时, table的最小长度:
static final int MIN_TREEIFY_CAPACITY = 64;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号