ICLR2014_Intriguing properties of neural networks
Author
一作: Christian Szegedy (GooLeNet, BN) 三作: Ilya Sutskever (AlexNet二作,S2S) 六作:Ian Goodfellow(DL book, Maxout, GAN Bengio学生) 七作:Rob Fergus(Visualizing)
大佬们总是喜欢一块玩,┓( ´∀` )┏
Abstract
DNN的强表达性是它们成功的原因,同时也就造成了它们学习无法解释的solutions, 有着反直觉的properties.这篇论文主要report两个这样的特性。
- 根据很多不同的unit analysis发现, 高层的神经元和高层神经元的随机线性组合是没有明显差别的. 这就说明在高层的神经网络中,是space,而不是独立的个体单元,包含着语义信息
- DNN学习的input-output的映射在很大程度上是不连续的,我们能通过增加几乎不可察觉的扰动使网络误判,就是说学习到的f函数是不连续的,对于间隔部分的采样点,它不知道怎么分类
Introduction
增加的扰动不是随机的,而是通过优化input to maximize the prediction error. 并且把这些perturbed examples 叫做 "adversarial examples"
说明网络有blind spots, 而且它的结构跟数据的分布有关
这篇论文晦涩难懂,我就只了解了它的中心思想,具体的实验部分没认真看
参考链接: https://zhuanlan.zhihu.com/p/29646077
http://www.lancezhange.com/2015/11/19/adversarial-samples/
http://www.infoq.com/cn/news/2015/07/adversarial-examples
一个是在采样层内部,每个单独结点的激活程度并不能唯一对应图像的某实际特征。图像特征是存在与整个空间内的,难以分开,不能将这些信息简单的分配给各个节点。
二是对抗样本也能骗过一些用不同样本训练的其他模型,证明了这些对抗样本的健壮性。
从自觉上来看,通过大量非线性层的叠加,深度学习的模型应该有比较强的泛化能力,即对于输入图像做微小的改变不会影响其分类的结果,或者说模型的输入与输出对应的在高维空间的形状(流形)应该是平滑的。但是根据论文,发现这个形状是不连续的。这是很严重的额问题,它意味着我们无法通过简单地计算图像在样本空间的距离来比较两张图片的差异。

对抗性样本的存在说明光滑性假设(相似的样本应该以很高的概率被判为同一类别)在某种程度上被推翻了
有论文指出 Exploring the Space of Adversarial Images(ICLR 2016) (IJCNN) 证明了在图像空间中,对抗样本绝非孤立点,而是占据了很大一部分的空间
explaining and harnessing adversarial examples, ICLR2015 通过再一个线性模型中加入对抗干扰,发现只要线性模型的输入拥有足够的维度(事实上大部分情况下,模型输入的维度都比较大,因为维度过小的输入会导致模型的准确率过低,即欠拟合),线性模型也对对抗样本表现出明显的脆弱性,这驳斥了关于对抗样本是因为模型的高度非线性的解释。事实上,该文指出,高维空间中的线性性就足以造成对抗样本,深度模型对对抗样本的无力最主要的还是由于其线性部分的存在(primary cause of neural networks’ vulnerability to adversarial perturbation is their linear nature)。
这也就提供了一个修正深度模型的机会,因为可以利用对抗样本来提高模型的抗干扰能力,因此有了对抗训练的概念,通过对抗训练,相当于加了一种形式的正则,可以提高模型的鲁棒性。
Ian Goodfellow所写的 深度学习对抗样本的八个误解与事实
1. 对抗样本的确不太可能会自然发生,但是可以利用对抗样本来训练模型以提高其非对抗样本的准确性。所以说对抗样本非常重要
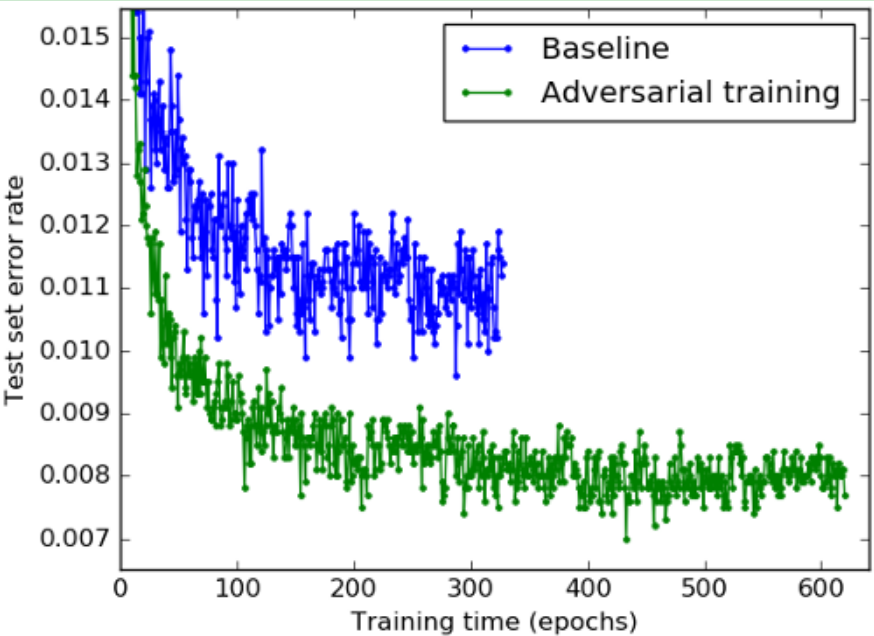
2. 几乎每个模型都有对应的对抗样本,包括像最近邻这样的最传统的机器学习模型。深度学习是目前为止对对抗训练最有抵抗力的技术
3. 对抗样本不是由极度非线性深度模型导致,相反,深度模型的表现是非常线性的,线性模型在外推远离训练数据的区域有着极度的优势
4. 对抗样本在小数据中也很容易找到,空间中大多数任意点都被误判,例如,在一个测试的网络中,有大约70%的噪声样本以高置信度归类为马
5. 拒绝处理对抗样本不是令人满意的解决方案
6. 攻击者不是必须访问到模型才能产生对抗样本,对抗样本在整个网络中扩散,用来训练执行相同的任务,即使这些模型有着不同的架构,由不同的训练数据集训练。这意味着攻击者可以训练自己的模型,产生对抗模型来对抗目标模型,然后将这些对抗样本部署到他们不能访问的模型中。
7. 在测试了多种传统的正则化策略后,都不能解决对抗样本问题。所以说对抗样本不能用标准正则技术解决
8. 人脑是不会反类似的错误
深度学习对抗样本泛化的原因
很多的时候,两个模型即使有不同的结构并在不同的训练集上被训练,一种模型的对抗样本在另一个模型中也同样会被误分,甚至它们还会将对抗样本误分为相同的类。这是因为对抗样本与模型的权值向量高度吻合,同时为了训练执行相同的任务,不同的模型学习了相似的函数。这种泛化特征意味着如果有人希望对模型进行恶意攻击,攻击者根本不必访问需要攻击的目标模型,就可以通过训练自己的模型来产生对抗样本,然后将这些对抗样本部署到他们需要攻击的模型中。
Karpathy blog Breaking Linear Classifiers on ImageNet
because Deep Learning models use linear functions to build up the architecture, they inherit their flaw In fact, Deep Learning offers tangible hope for a solution
如何产生fooling image: 原来是固定输入,update 模型的参数, 现在固定模型的参数,我们update pixel
Creating fooling images: “What happens to the score of (whatever class you want) when I wiggle this pixel?”
Intrguing中就是使用梯度下降的方法伪造样本,这种方法也就说明了传统的模型也仍然可以成功地伪造样本
convNets中从输入到分类结果的映射不是线性的,但是构成网络的部分是线性的,卷积操作就是线性操作,矩阵乘积也是线性操作
这里考虑fool 线性分类器, 直接用一层的全连接层+softmax

ConvNets still work very well in practice. Unfortunately, it seems that their competence is relatively limited to a small region around the data manifold that contains natural-looking images and distributions, and that once we artificially push images away from this manifold by computing noise patterns with backpropagation, we stumble into parts of image space where all bets are off, and where the linear functions in the network induce large subspaces of fooling inputs.
With wishful thinking, one might hope that ConvNets would produce all-diffuse probabilities in regions outside the training data, but there is no part in an ordinary objective (e.g. mean cross-entropy loss) that explicitly enforces this constraint. Indeed, it seems that the class scores in these regions of space are all over the place, and worse, a straight-forward attempt to patch this up by introducing a background class and iteratively adding fooling images as a new background class during training are not effective in mitigating the problem.
It seems that to fix this problem we need to change our objectives, our forward functional forms, or even the way we optimize our models. However, as far as I know we haven’t found very good candidates for either. To be continued.
Karparthy认为一种比较好的解决方法是希望卷积神经网络能够生成均匀的概率分布在数据空间汇总,包括训练样本之外的区域,一种好的办法就是设置一个背景类别,当在训练数据外的数据就预测成这种类别,但是不好实现,而且需要给目标函数增加一个类,这都是不太实际的。
所以说要想解决这个问题,必须要改变我们的目标函数,前向传播的函数形式,甚至我们的优化方法也要改变,目前还还有很好的替换方法,未来还需努力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号