

scrapy框架第二天
1.scrapy数据分析
2.scrapy持久化存储
3.全站数据爬取
4.请求传参 + 五大核心组件
- 创建scrapy工程 scrapy startproject ProName - 切换到工程目录下 cd ProName - 创建spider文件夹 scrapy genspider SpiderName www.xxx.com
-settings里面的一些设置
- LOG_LEVEL = 'ERROR'
- USER_AGENT='JHJAJHHJKAFHJFHJ'
- ROBOTSTXT_OBEY = False
-运行spider scrapy crawl SpiderName
- scrapy的数据解析
- 在scrapy中使用xpath解析标签中的文本内容或者标签属性的话,最终获取的是一个Selector的对象,且我们需要的字符串数据全部被封装在了该对象中
- 如果可以确定xpath返回的列表只有一个列表元素则使用extract_first(),否则使用extract()
- scrapy的持久化存储
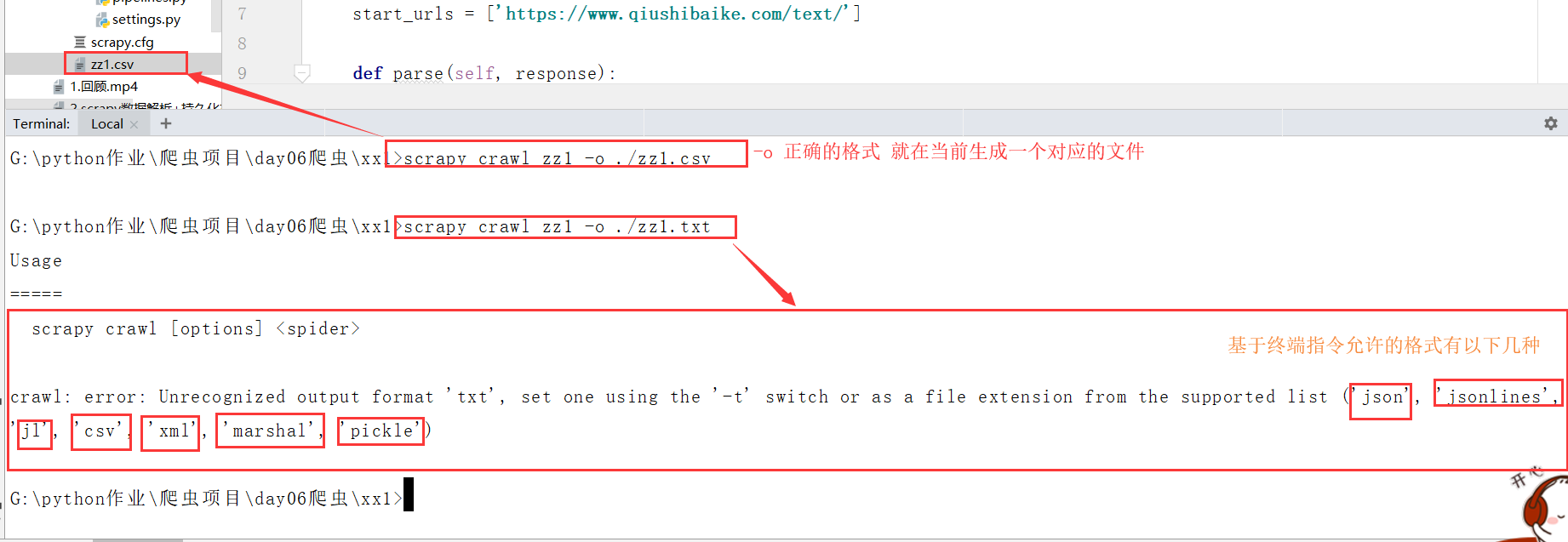
- 基于终端指令:
- 可以将parse方法的返回值对应的数据进行本地磁盘文件的持久化存储
- scrapy crawl SpiderName -o filePath
- 优点:便捷
- 缺点:局限性较强(数据不可以存储到数据库,数据存储文件的后缀有要求)
- 基于管道:
-编码流程:
- 1.数据解析
- 2.在item类中进行相关属性的封装
- 3.实例化一个item类型的对象
- 4.将解析的数据存储封装到item类型的对象中
- 5.将item提交给管道
- 6.在配置文件中开启管道
- 注意事项:
- 爬虫文件提交的item只会传递给第一个被执行的管道类
- 在管道类的process_item方法中的return item,是将item传递给下一个即将被执行的管道类
- 习惯:每一个process_item中都需要编写return item
爬取糗百数据一:
1.存放在start_urls中的url会被scrapy自动的进行请求发送
2. def parse(self, response): 这个函数下面操作代码的数据解析
3.response.xpath() scrapy用来定位标签的xpath,用法和etree的xpath差不多,但是response.xpath是scrapy自己封装的
4.scrapy的数据解析
- 在scrapy中使用xpath解析标签中的文本内容或者标签属性的话,最终获取的是一个Selector的对象,且我们需要的字符串数据全部被封装在了该对象中
- 如果可以确定xpath返回的列表只有一个列表元素则使用extract_first(),否则使用extract()
5.运行之前,settings里面的一些参数需要设置
# -*- coding: utf-8 -*- import scrapy from qiubaiPro.items import QiubaiproItem class QiubaiSpider(scrapy.Spider): name = 'qiubai' #允许的域名,一般注释掉 # allowed_domains = ['www.xxx.com'] # 存放在该列表中的url都会被scrapy自动的进行请求发送 start_urls = ['https://www.qiushibaike.com/text/'] # 基于终端指令的持久化存储:可以将parse方法的返回值对应的数据进行本地磁盘文件的持久化存储 def parse(self, response): all_data = [] #数据解析response.xpath:作者and段子内容 div_list = response.xpath('//div[@id="content-left"]/div') for div in div_list: #在scrapy中使用xpath解析标签中的文本内容的话,最终获取的是一个Selector的对象,且我们需要的字符串数据全部被封装在了该对象中 #如果可以确定xpath返回的列表只有一个列表元素则使用extract_first(),否则使用extract() author = div.xpath('./div[1]/a[2]/h2/text()').extract_first() content = div.xpath('./a/div/span/text()').extract() dic = { 'author':author, 'content':content } all_data.append(dic) # print(author,content) return all_data
scrapy基于终端指令的持久化存储
scrap基于管道的持久化存储
1.开启管道settings设置里面 需要手动打开管道
ITEM_PIPELINES = { 'qiubaiPro.pipelines.QiubaiproPipeline': 300, # 'qiubaiPro.pipelines.mysqlPileLine': 301, 'qiubaiPro.pipelines.redisPileLine': 302, #300表示的是优先级,数值越小优先级越高 }
2.
- 爬虫文件中获取文件信息
- 创建一个item的类对象 item = QiubaiproItem()
- 将解析数据存储到item对象中 item['author'] = author
- 将item提交给管道类 yield item
# -*- coding: utf-8 -*- import scrapy from qiubaiPro.items import QiubaiproItem class QiubaiSpider(scrapy.Spider): name = 'qiubai' # allowed_domains = ['www.xxx.com'] # 存放在该列表中的url都会被scrapy自动的进行请求发送 start_urls = ['https://www.qiushibaike.com/text/'] #基于管道实现持久化存储 def parse(self, response): all_data = [] #数据解析:作者and段子内容 div_list = response.xpath('//div[@id="content-left"]/div') for div in div_list: #在scrapy中使用xpath解析标签中的文本内容的话,最终获取的是一个Selector的对象,且我们需要的字符串数据全部被封装在了该对象中 #如果可以确定xpath返回的列表只有一个列表元素则使用extract_first(),否则使用extract() author = div.xpath('./div[1]/a[2]/h2/text()').extract_first() if not author: author = '匿名用户' content = div.xpath('./a/div/span/text()').extract() content = ''.join(content) #创建一个item类型的对象(只可以存储一组解析的数据) item = QiubaiproItem() #将解析到的数据存储到item对象中 item['author'] = author item['content'] = content #将item提交给管道类 yield item
3.管道pipelines.py的介绍
- 管道类里面使用数据库对爬取的文件进行存储
# -*- coding: utf-8 -*- # # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymysql from redis import Redis # 一个管道类对应一种平台的数据存储 class QiubaiproPipeline(object): fp = None #重写父类的方法:只在开始爬虫的时候被执行一次 def open_spider(self,spider): print('开始爬虫......') self.fp = open('./qiubai.txt','w',encoding='utf-8') #处理item类型的对象 #什么是处理? #将封装在item对象中的数据值提取出来且进行持久化存储 #参数item表示的就是爬虫文件提交过来的item对象 #该方法每接收一个item就会被调用一次 def process_item(self, item, spider): print('this is process_item()') author = item['author'] content = item['content'] self.fp.write(author+':'+content+"\n") #返回的item就会传递给下一个即将被执行的管道类 return item def close_spider(self,spider): print('结束爬虫!') self.fp.close() #将数据同时存储到mysql class mysqlPileLine(object): conn = None cursor = None def open_spider(self,spider): self.conn = pymysql.Connect(host='127.0.0.1',port=3306,db='spider',user='root',password='',charset='utf8') print(self.conn) def process_item(self,item,spider): sql = 'insert into qiubai values ("%s","%s")'%(item['author'],item['content']) #创建一个游标对象 self.cursor = self.conn.cursor() try: self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def close_spider(self,spider): self.cursor.close() self.conn.close() #数据存储到redis中 class redisPileLine(object): conn = None def open_spider(self,spider): self.conn = Redis(host='127.0.0.1',port=6379) def process_item(self,item,spider): dic = { 'author':item['author'], 'content':item['content'] } self.conn.lpush('qiubaiData',dic)
4.item.py的介绍
- item.py文件中定义item类型的属性
import scrapy class QiubaiproItem(scrapy.Item): # define the fields for your item here like: author = scrapy.Field() content = scrapy.Field()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号