

脑裂是什么
脑裂现象
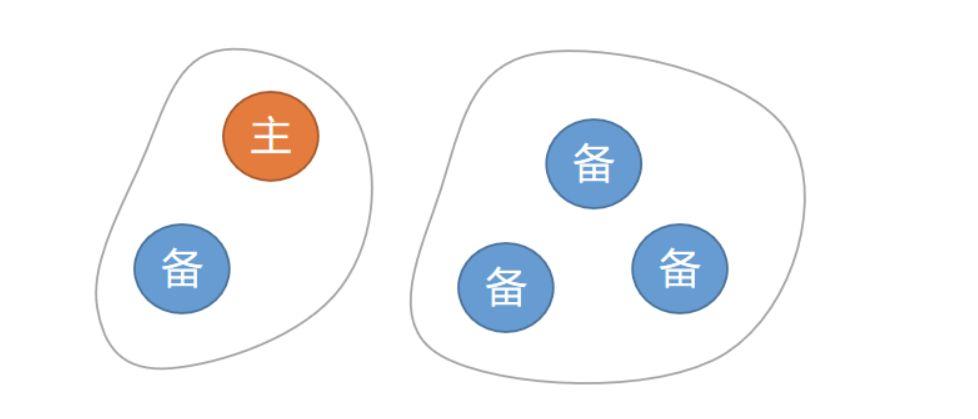
正常情况下,HA集群包含一个主机,若干个备机。其中主机提供读写服务,备机同步主机数据,作为数据冗余,也可以提供只读服务。如果主机宕机,可以将一个备机failover,让其升为主机,继续提供读写业务。
脑裂现象是指出现了多个主机提供服务的情况,这种现象会造成数据丢失或者不一致问题。例如:在旧主机上提交的事务,新主机上不存在,数据丢失。旧主机降备后,redo日志与新主机不匹配,无法和新主机建立正常的主备关系。

脑裂原因
脑裂发生的前提是发生了failover,某个备机升为新主机,但是旧主机还能提供服务。
- 人为执行failover,只要确保旧主机已经宕机,就不会发生脑裂。但是如果误操作,就可能发生脑裂
- 自动执行failover,是备机认为主机已经发生故障,自动将自己升主。主机和备机一般是通过心跳来确认对方存活状态的,当备机长时间收不到主机心跳,有可能是主机已经宕机,也可能是主机和备机之间的网络出现故障。在后面这种场景下,客户端可能连接着原主机,继续执行业务,此时备机升主就会脑裂
如何解决脑裂问题
脑裂问题是同时有多个主机提供写服务造成的,解决方案就是保证同一时刻只能有一个主机。但是在网络分区的情况下,可能原主机网络发生隔离,其他备机无法判断主机是否存活,也没有办法关闭原主机,就无法保证同一时刻只有一个主机。所以解决方案需要加个条件:
保证同一时刻只能有一个主机能写服务
网络分区后,只要让旧主机不再提交新的事务,即使旧主机还存活,也不会导致脑裂。一般采用Quorum机制来确保只有一个节点能提交事务
- 主机提交事务,要保证对应的日志在多数节点落盘
- 备机回放日志,要保证该日志在多数节点落盘
- 要升主的备机,必须是多数节点里日志最多的一个
这里的多数节点,包含了主机和备机,比如1主2备3节点,多数节点就是2个或3个,1主3备4节点,多数节点是3个或4个。
约束1保证了网络分区场景下,如果原主机所在的分区,不满足多数节点,其事务无法提交.
如下图,5节点集群,主机和其他3个备机网络隔离,日志无法发送到多数节点上,主机事务将无法提交,一般采用hang住的处理方法,不能返回报错,因为有可能在多数派落盘了,但是备机回复ACK的时候网络故障
约束2保证了,只有多数派落盘的事务,才是可见的,否则可能出现主机上事务还没提交,备机上却能查到的不一致问题。
如上图,主机和备机1处于一个网络分区,主机提交事务,会先将日志本地落盘,然后发送给所有备机,但是只有备机1能收到,并且回复了ACK。此时主机事务会hang住,不会提交,其他session对该事务不可见,如果备机1将该日志回放,那么在备机1上就能看到该事务,所以只有多数节点落盘后,备机才可以回放该日志。
如果没有约束2,可能会出现已提交事务,在新主上丢失的问题,比如上图,如果在右边3个备机里选择一个升主,在它上面没有备机1的一些日志,新主机也不会将这些日志回放,造成事务丢失的现象。
约束3下,最多只有一个备机能成功升主,而且这个备机包含了所以已提交的事务。
因为约束1保证了已提交事务的日志,在多数节点落盘了,而升主的备机,是多数节点里日志最多的。
在约束3下,如果集群里存活的节点个数不满足大多数,是无法选出新主的。
业界一般采用Paxos或Raft算法实现Quorum机制,其中Raft算法是通过心跳超时来检测leader是否正常,如果心跳接收超时,则认为leader异常,follower发起选举,如果得到多数节点的投票,就可以升为新的leader
总结
Quorum机制下,集群中多数节点不可用的情况下,系统将无法提供写服务,所以Quorum是牺牲可用性来确保一致性的,只适用于至少包含3个节点的集群。因为在1主1备场景下,多数节点是2个,主机和备机宕机,系统都不可用,所以1主1备场景一般会采用最大可用或者最大性能模式,牺牲数据一致性,提高可用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号