

Scrapy介绍
# 伪代码, 只为说明
def get_page_srouce():
resp = requests.get(xxxxx)
return resp.text | resp.json()
def parse_source():
xpath, bs4, re
return data
def save_data(data):
txt, csv, mysql, mongodb
def main(): # 负责掌控全局
# 首页的页面源代码
ret = get_page_source() # 获取页面源代码, 发送网络请求
data = parse_source(ret) # 去解析出你要的数据
# 需要继续请求新的url
while:
# 详情页
ret = get_page_source() # 获取页面源代码, 发送网络请求
data = parse_source(ret) # 去解析出你要的数据
save_data(data) # 负责数据存储
# 详情页如果还有分页.
# ...继续上述操作.
if __name__ == '__main__':
main()
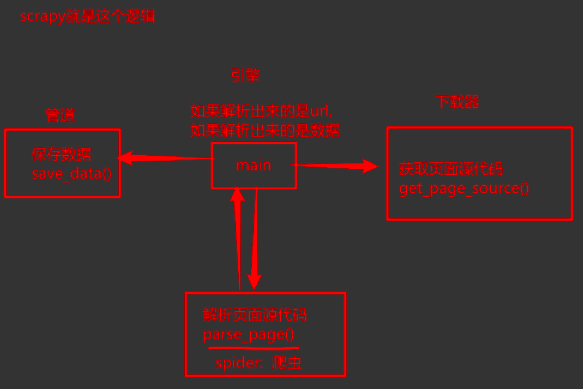
之前我们所编写的爬虫的逻辑:
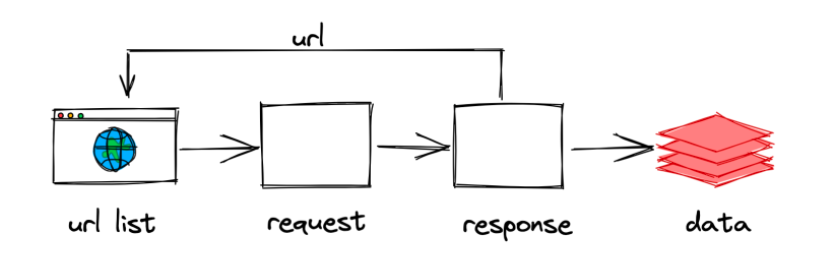
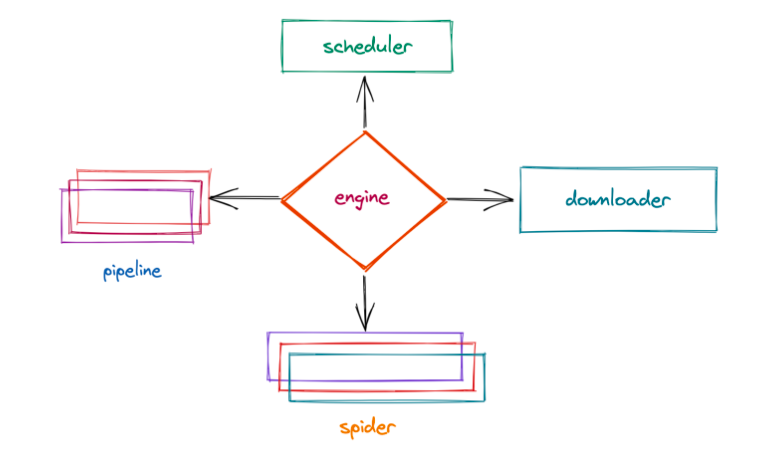
整个工作流程,
-
爬虫中起始的url构造成request对象, 并传递给调度器.
-
引擎从调度器中获取到request对象. 然后交给下载器 -
由
下载器来获取到页面源代码, 并封装成response对象. 并回馈给引擎 -
引擎将获取到的response对象传递给spider, 由spider对数据进行解析(parse). 并回馈给引擎 -
引擎将数据传递给pipeline进行数据持久化保存或进一步的数据处理. -
在此期间如果spider中提取到的并不是数据. 而是子页面url. 可以进一步提交给调度器, 进而重复
步骤2的过程
# 伪代码, 只为说明
def get_page_srouce(url, method):
if method == get:
resp = requests.get(xxxxx)
return resp.text | resp.json()
def parse_source():
xpath, bs4, re
def save_data(data):
txt, csv, mysql, mongodb
def main(): # 负责掌控全局->为了你理解
# 主页
req = spider.get_first_req()
while 1:
scheduler.send(req)
next = scheduler.next_req()
sth = downloader.get_page_source(next)
data = spider.parse(sth)
if data is 数据:
pipeline.process_item(data)
if __name__ == '__main__':
main()上述过程中一直在重复着几个东西,
-
引擎(engine)
scrapy的核心, 所有模块的衔接, 数据流程梳理.
-
调度器(scheduler)
本质上这东西可以看成是一个集合和队列. 里面存放着一堆我们即将要发送的请求. 可以看成是一个url的容器. 它决定了下一步要去爬取哪一个url. 通常我们在这里可以对url进行去重操作.
-
下载器(downloader)
它的本质就是用来发动请求的一个模块. 小白们完全可以把它理解成是一个requests.get()的功能. 只不过这货返回的是一个response对象.
-
爬虫(spider)
这是我们要写的第一个部分的内容, 负责解析下载器返回的response对象.从中提取到我们需要的数据.
-
管道(pipeline)
这是我们要写的第二个部分的内容, 主要负责数据的存储和各种持久化操作.
经过上述的介绍来看, scrapy其实就是把我们平时写的爬虫进行了四分五裂式的改造. 对每个功能进行了单独的封装, 并且, 各个模块之间互相的不做依赖. 一切都由引擎进行调配. 这种思想希望你能知道--解耦. 让模块与模块之间的关联性更加的松散. 这样我们如果希望替换某一模块的时候会非常的容易. 对其他模块也不会产生任何的影响.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号