

requests模块处理cookie相关的请求
为了能够通过爬虫获取到登录后的页面,或者是解决通过cookie的反扒,需要使用request来处理cookie相关的请求
爬虫中使用cookie的利弊
-
带上cookie的好处
-
能够访问登录后的页面
-
能够实现部分反反爬
-
-
带上cookie的坏处
-
一套cookie往往对应的是一个用户的信息,请求太频繁有更大的可能性被对方识别为爬虫
-
那么上面的问题如何解决 ?使用多个账号
-
requests处理cookie的方法
使用requests处理cookie有三种方法:
-
cookie字符串放在headers中
-
把cookie字典放传给请求方法的cookies参数接收
-
使用requests提供的session模块
cookie添加在heades中
headers中cookie的位置
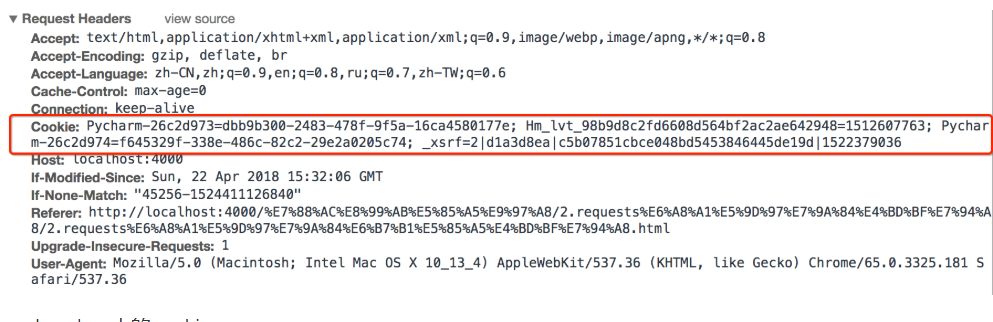
-
headers中的cookie:
-
使用分号(;)隔开
-
分号两边的类似a=b形式的表示一条cookie
-
a=b中,a表示键(name),b表示值(value)
-
在headers中仅仅使用了cookie的name和value
-
cookie的具体组成的字段

由于headers中对cookie仅仅使用它的name和value,所以在代码中我们仅仅需要cookie的name和value即可
在headers中使用cookie
复制浏览器中的cookie到代码中使用
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Cookie":" Pycharm-26c2d973=dbb9b300-2483-478f-9f5a-16ca4580177e; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1512607763; Pycharm-26c2d974=f645329f-338e-486c-82c2-29e2a0205c74; _xsrf=2|d1a3d8ea|c5b07851cbce048bd5453846445de19d|1522379036"}
requests.get(url,headers=headers)注意:
cookie有过期时间 ,所以直接复制浏览器中的cookie可能意味着下一程序继续运行的时候需要替换代码中的cookie,对应的我们也可以通过一个程序专门来获取cookie供其他程序使用;当然也有很多网站的cookie过期时间很长,这种情况下,直接复制cookie来使用更加简单
使用cookies参数接收字典形式的cookie
-
cookies的形式:字典
cookies = {"cookie的name":"cookie的value"}-
使用方法:
requests.get(url,headers=headers,cookies=cookie_dict}-
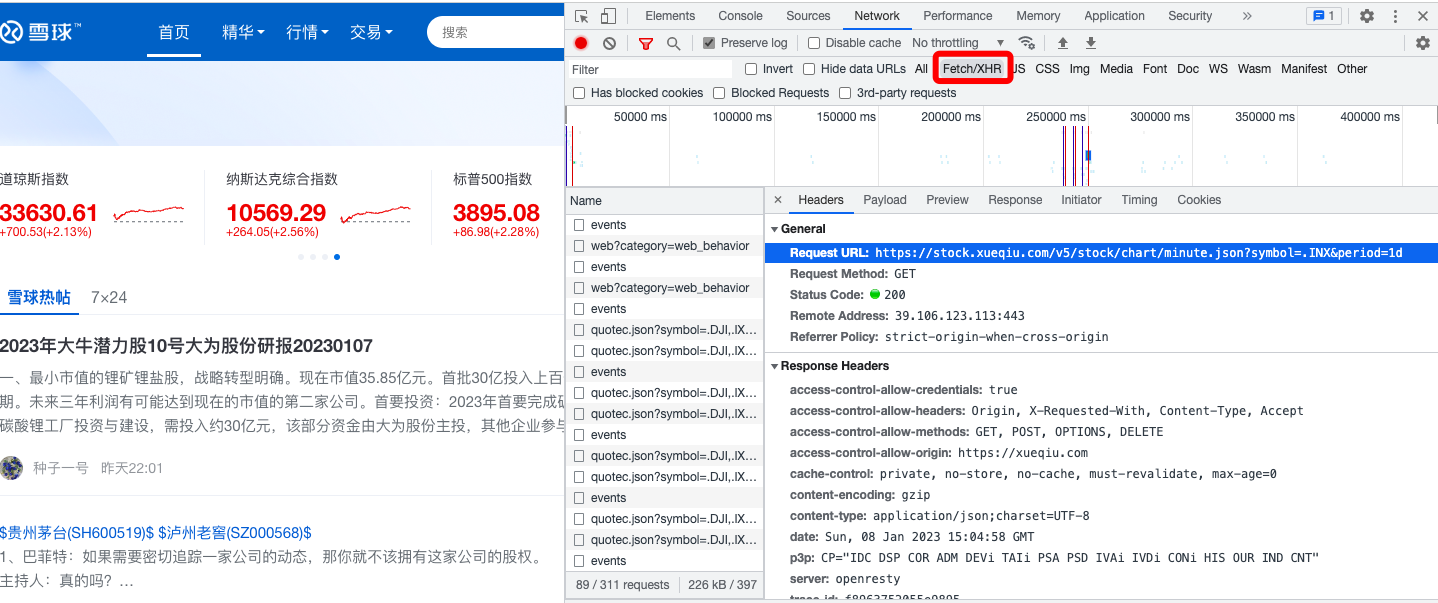
实例(爬取雪球网)
在网络中找到当前请求的网址 点击cookies 将当前的k,value复制到代码中
![]()
![]()
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36', 'Referer': 'https://xueqiu.com/u/1990923459', 'cookie': 'device_id=08b44b5869899303a4d735621df8c4d4; Hm_lvt_1db88642e346389874251b5a1eded6e3=1673183274; remember=1; snbim_minify=true; s=bt1c6hkm25; bid=af8fd9a2a4582356ca74aff7fac9e0c9_lcnhd0dh; xq_a_token=140b9d69cb9f100ad486013ceeb783e9bb0696f5; xq_r_token=51944912a96da76eef33a19d179cbfa8812d17e8; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTY3NDc3ODgwNiwiY3RtIjoxNjczMTg5OTgyMTYzLCJjaWQiOiJkOWQwbjRBWnVwIn0.F2QY71nh2ahy4p62KCKZ64ZLu-biTcPcRi_asDx1tKBXSOC7uFtxfmjOmZ7rBMkv6ufu6cuw1cfKdvPDU9-yaE7BLFMzd6Wjtfj3fsd1Bp78uT2YmFs6xh9RJqlsJVbKe1WVD2wgiyRVgzgoNOV_1tB3IEyAm7H-AkvbvHnLVAlrcUTYgyvj-2O0FwJdLbyXmtTlYU3-4iRUxlMVtPmjuemGEEHZzLqt_uAp2vUSAfp0BwNA3_vhdRf2mXkHbADijR7ct-Zia5AFZ0ROqzlP3ZLxmXR0btLAQKyX6g9VH-4CvF49WWzsv0TbINY-uff1jkzoV0Snn1a1SoEMCGd0iQ; u=751673190028910; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1673190051' } url = 'https://stock.xueqiu.com/v5/stock/hot_stock/list.json?size=8&_type=10&type=10' response = requests.get(url, headers=headers) print(response.text)
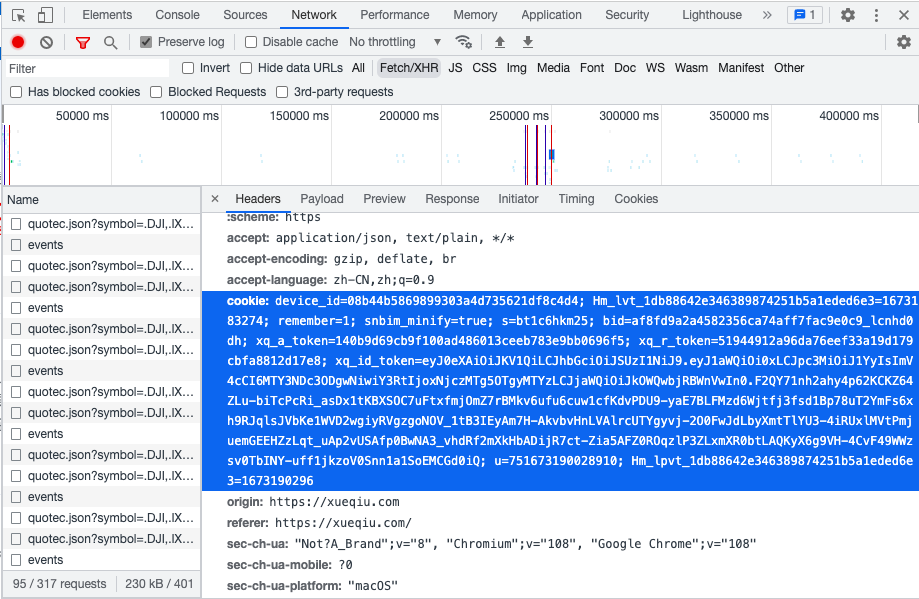
自动获取cookie并携带
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Referer': 'https://xueqiu.com/',
}
url = 'https://xueqiu.com/'
response = requests.get(url, headers=headers)
cookies = dict(response.cookies) # cookie对象转换为字典
url = 'https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=414873&size=15'
# 使用cookies参数携带cookie
response = requests.get(url, headers=headers, cookies=cookies)
print(response.text)使用requests.session处理cookie
前面使用手动的方式使用cookie,那么有没有更好的方法在requets中处理cookie呢?
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持
会话保持有两个内涵:
-
保存cookie,下一次请求会带上前一次的cookie
-
实现和服务端的长连接,加快请求速度
使用方法
session = requests.session()
response = session.get(url,headers)session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Referer': 'https://xueqiu.com/',
}
url = 'https://xueqiu.com/'
session = requests.Session() # 创建session对象 会自动处理cookie
session.get(url, headers=headers)
url = 'https://stock.xueqiu.com/v5/stock/hot_stock/list.json?size=8&_type=10&type=10'
# 使用cookies参数携带cookie
response = session.get(url, headers=headers)
print(response.text)动手练习:模拟登陆
-
17k小说网 https://passport.17k.com/
在登陆界面,输入一个错误的账号密码,然后点击登陆,然后就拿到了登陆的URL以及携带post的表单数据。
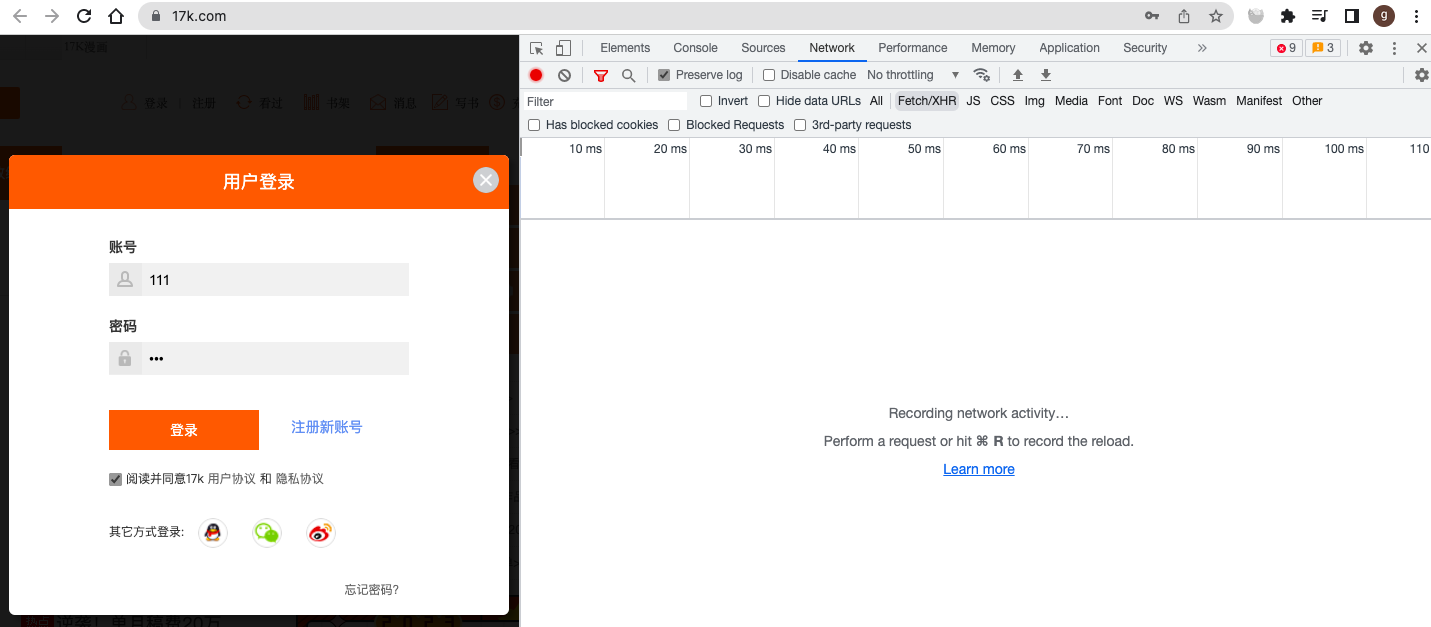
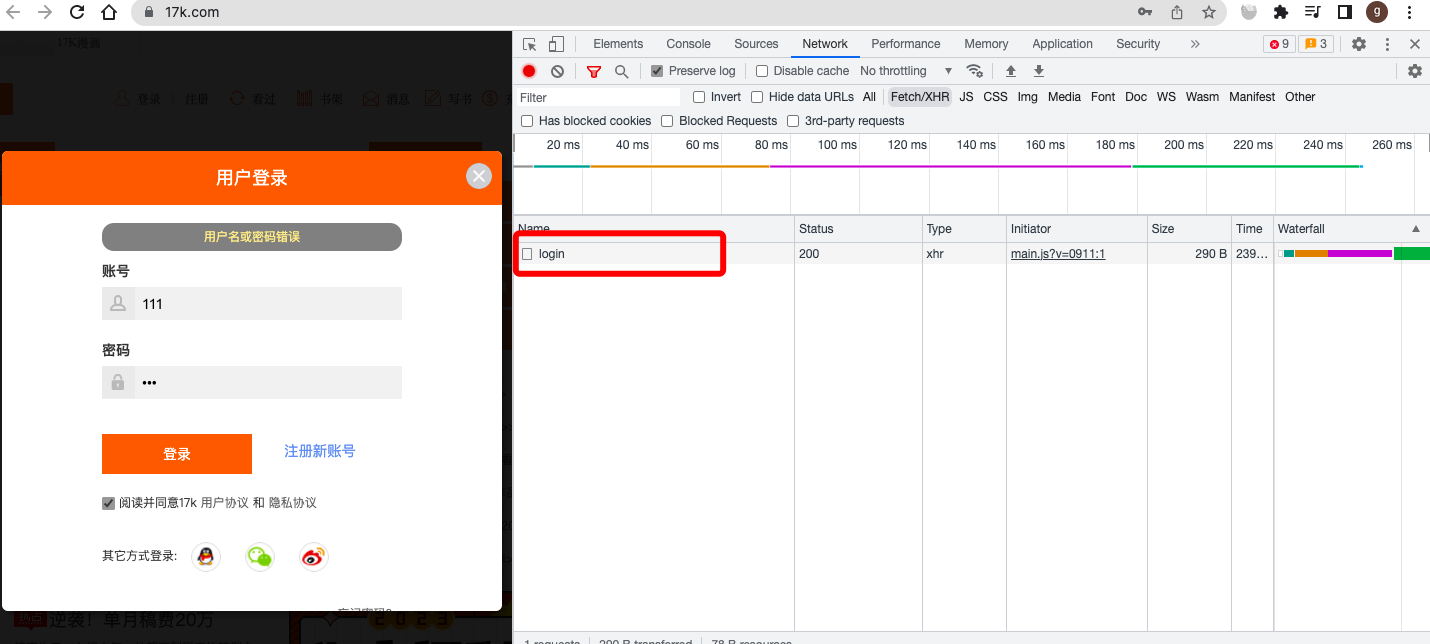
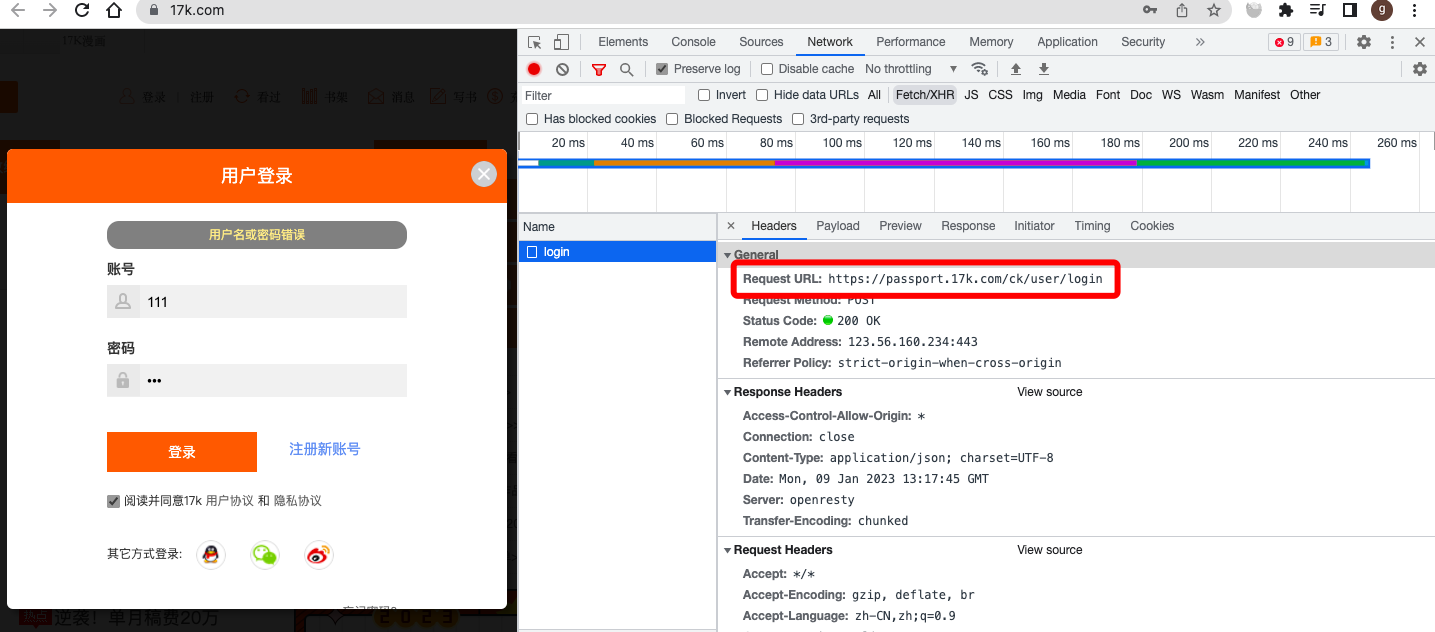
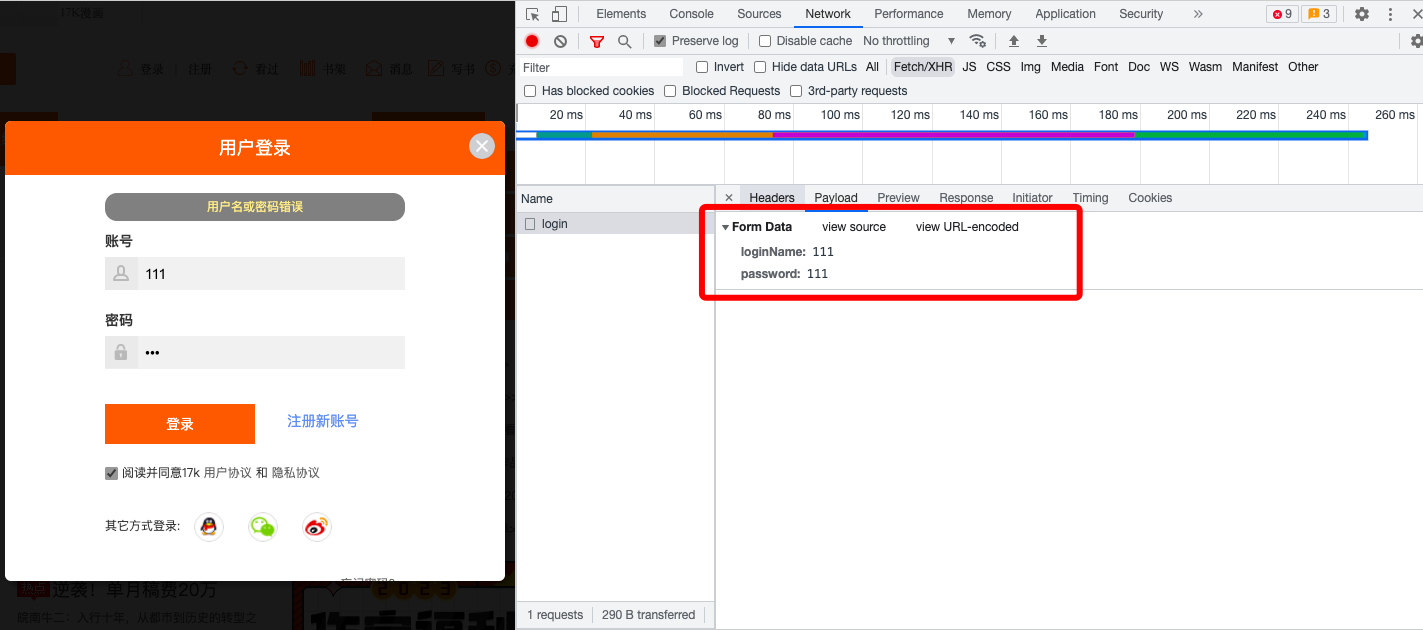
发送post请求进行登陆:
import requests
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Referer': 'https://passport.17k.com/login/index.html'
}
# 携带post的表单数据
data = {
'loginName': '17346570232',
'password': 'xlg17346570232'
}
url = 'https://passport.17k.com/ck/user/login'
response = requests.post(url, headers=headers, data=data)
print(response.text)抓取登录后的数据:
import requests
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Referer': 'https://passport.17k.com/login/index.html'
}
# 携带post的表单数据
data = {
'loginName': '17346570232',
'password': 'xlg17346570232'
}
url = 'https://passport.17k.com/ck/user/login'
response = requests.post(url, headers=headers, data=data)
cookies = dict(response.cookies) # 此刻获取到响应的cooki就是你登录后的
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Referer': 'https://user.17k.com/www/bookshelf/index.html',
}
# 登录后才能访问的地址
books = 'https://user.17k.com/ck/user/myInfo/96139098?bindInfo=1&appKey=2406394919'
response = requests.get(books, headers=headers, cookies=cookies)
print(response.text)requests.session处理登陆后的cookie:
import requests
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Referer': 'https://passport.17k.com/login/index.html'
}
# 携带post的表单数据
data = {
'loginName': '17346570232',
'password': 'xlg17346570232'
}
url = 'https://passport.17k.com/ck/user/login'
session = requests.Session()
session.post(url, headers=headers, data=data)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Referer': 'https://user.17k.com/www/bookshelf/index.html',
}
# 登录后才能访问的地址
books = 'https://user.17k.com/ck/user/myInfo/96139098?bindInfo=1&appKey=2406394919'
response = session.get(books, headers=headers)
print(response.text)
思路分析
-
准备url地址和请求参数
-
构造session发送post请求
-
使用session请求个人主页,观察是否请求成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号