

爬虫概述 & web请求全过程剖析 & 反爬虫的一般手段 & 常见HTTP状态码
爬⾍合法么
爬⾍分为善意的爬⾍和恶意的爬虫
善意的爬⾍
不破坏被爬取的⽹站的资源(正常访问, ⼀般频率不 ⾼, 不窃取⽤户隐私)
恶意的爬⾍
影响⽹站的正常运营(抢票, 秒杀, 疯狂solo⽹站资源 造成⽹站宕机)
综上, 为了避免进xx,我们还是要安分守⼰,时常优化⾃⼰的爬⾍程序 避免⼲扰到⽹站的正常运⾏。并且在使⽤爬取到的数据时,发现涉及到 ⽤户隐私和商业机密等敏感内容时, ⼀定要及时终⽌爬取和传播。
爬取的一定是看得见的东西,公开的东西,爬取vip的东西属于违法的。
爬⾍的⽭与盾
反爬机制
⻔户⽹站,可以通过制定相应的策略或者技术⼿段,防⽌爬⾍程序进⾏⽹站数据的爬取。
反反爬策略
爬⾍程序可以通过制定相关的策略或者技术⼿段,破解⻔户⽹站中具备的反爬机制,从⽽可以获取⻔户⽹站中相关的数据。
robots.txt协议
君⼦协议。规定了⽹站中哪些数据可以被爬⾍爬取 哪些数据不可以被爬取
如B站: https://www.bilibili.com/robots.txt

第一个爬虫程序开发:
from urllib.request import urlopen
resp = urlopen("http://www.baidu.com") # 打开 百度
print(resp.read().decode("utf-8")) # 打印 抓取到的内容
我们可以把抓取到的html内容全部写到文件中, 然后和原版的百度进行对比, 看看是否一致
from urllib.request import urlopen
resp = urlopen("http://www.baidu.com") # 打开 百度
# print(resp.read().decode("utf-8")) # 打印 抓取到的内容
with open("baidu.html",mode="w", encoding="utf-8")
as f: # 创建文件
f.write(resp.read().decode("utf-8")) # 保存在文件中
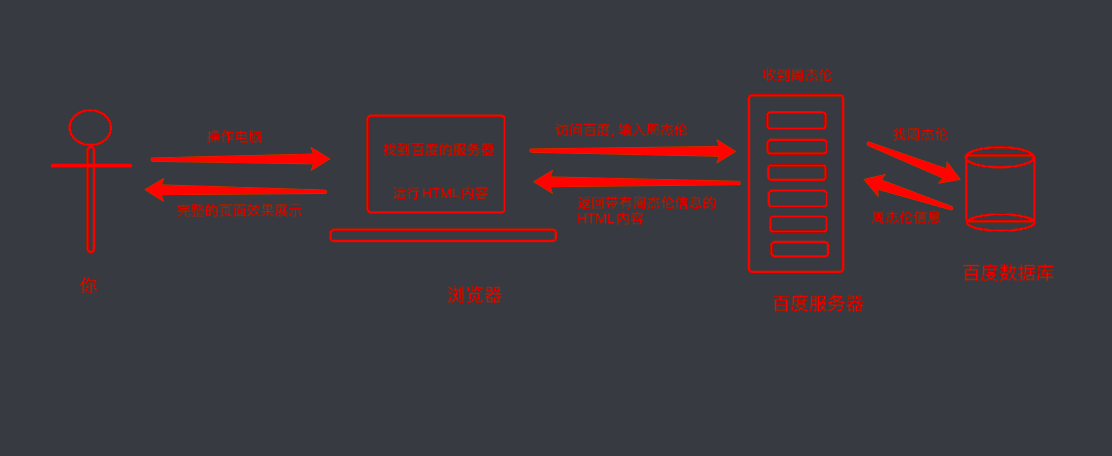
我们浏览器在输入完网址到我们看到网页的整体内容, 这个过程中究竟发生了些什么?
这里我们以百度为例,在访问百度的时候,浏览器会把这一次请求发送到百度的服务器(百度的一台电脑), 由服务器接收到这个请求,然后加载一些数据,返回给浏览器,再由浏览器进行显示。注意, 百度的服务器返回给浏览器的不直接是页面,而是页面源代码(由html, css, js组成)。由浏览器把页面源代码进行执行,然后把执行之后的结果展示给用户。
具体过程如图
接下来就是一个比较重要的事情了,所有的数据都在页面源代码里么?
非也~ 这里要介绍页面渲染数据的过程, 我们常见的页面渲染过程有两种
1. 服务器渲染
这个最容易理解, 也是最简单的. 含义呢就是我们在请求到服务器的时候,服务器直接把数据全部写入到html中, 我们浏览器就能直接拿到带有数据的html内容,比如由于数据是直接写在html中的,所以我们能看到的数据都在页面源代码中能找得到的这种页面般都相对比较容易就能抓取到页面内容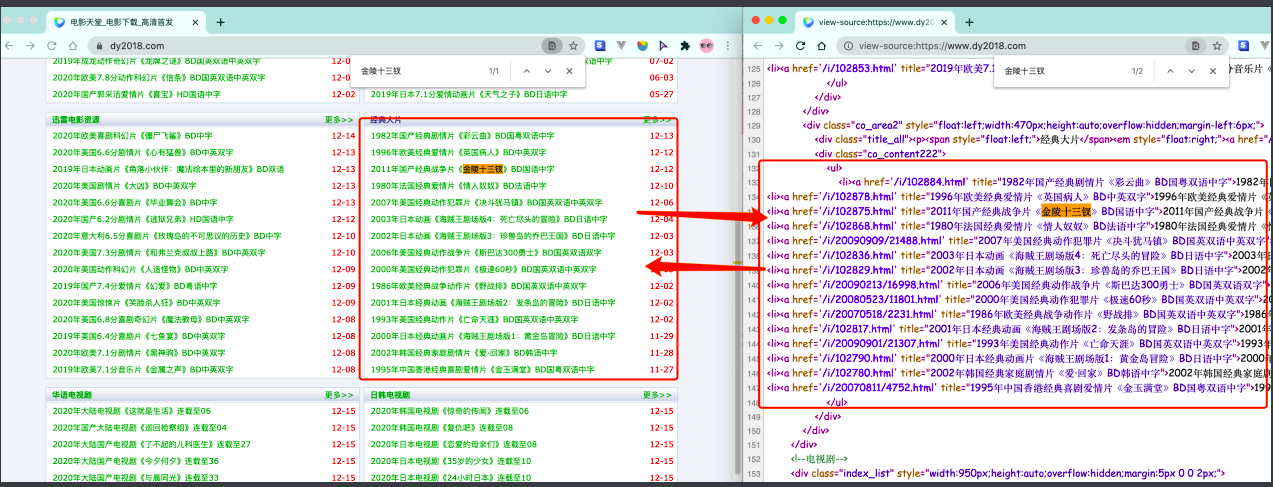
2. 前端JS渲染
这种就稍显麻烦了,这种机制一般是第一次请求服务器返回一堆HTML框架结构,然后再次请求到真正保存数据的服务器,由这个服务器返回数据, 最后在浏览器上对数据进行加载,就像这样
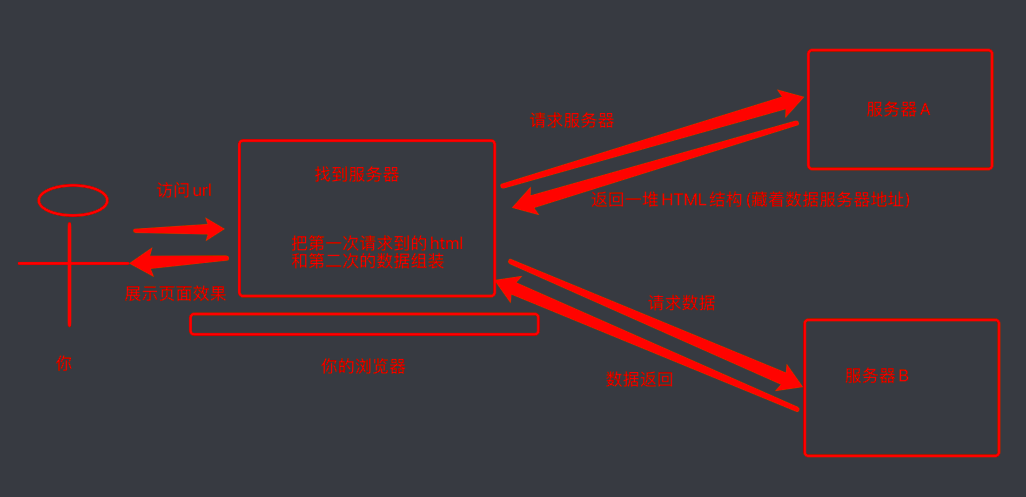
这样做的好处是服务器那边能缓解压力,而且分工明确,比较容易维护,典型的有这么一个网页。
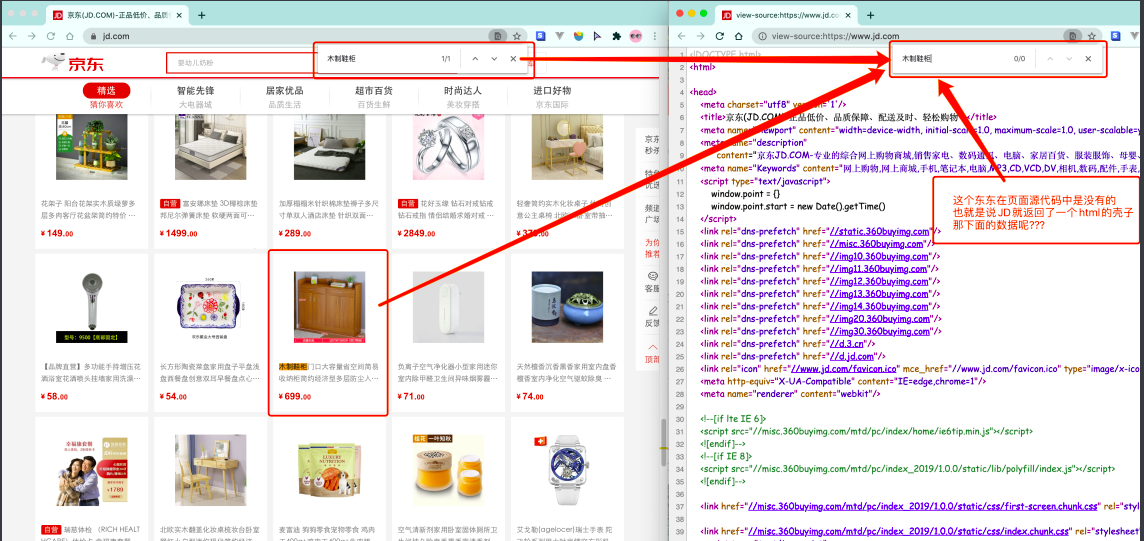
那数据是何时加载进来的呢? 其实就是在我们进行向下滚动的时候,jd就在偷偷的加载数据了, 此时想要看到这个页面的加载全过程,我们就需要借助浏览器的调试工具了(F12)。
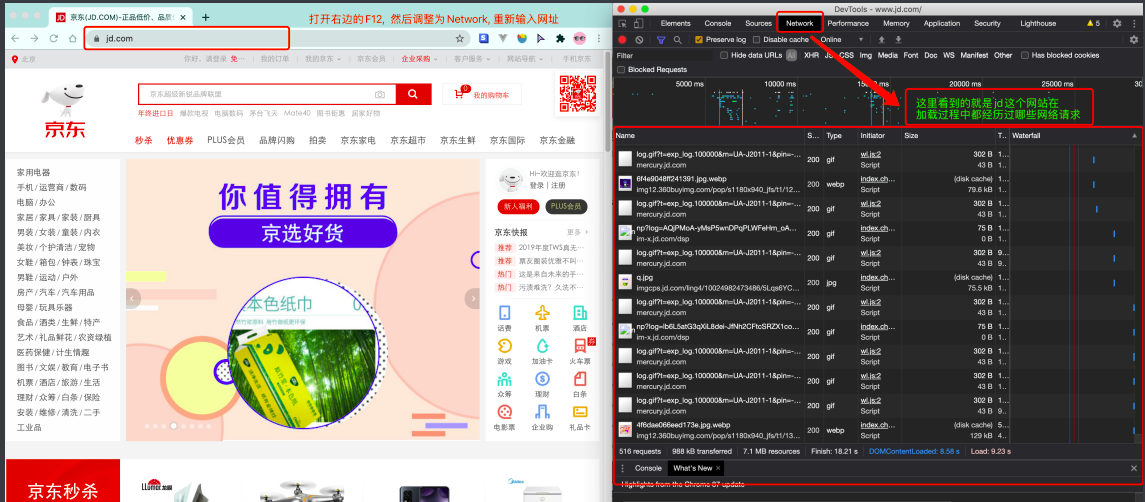
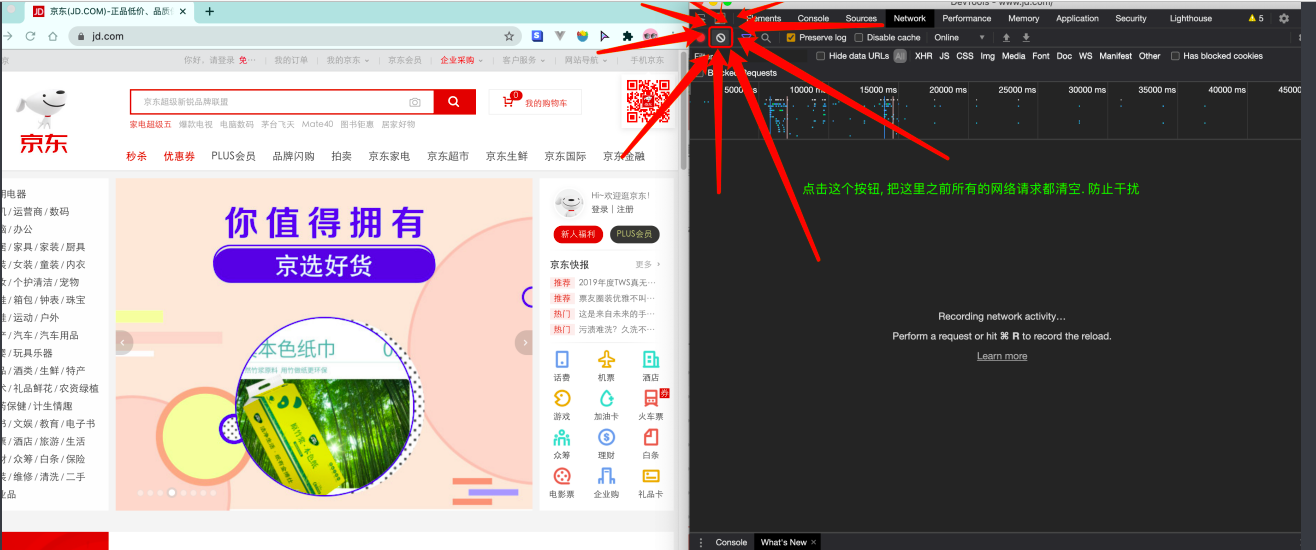
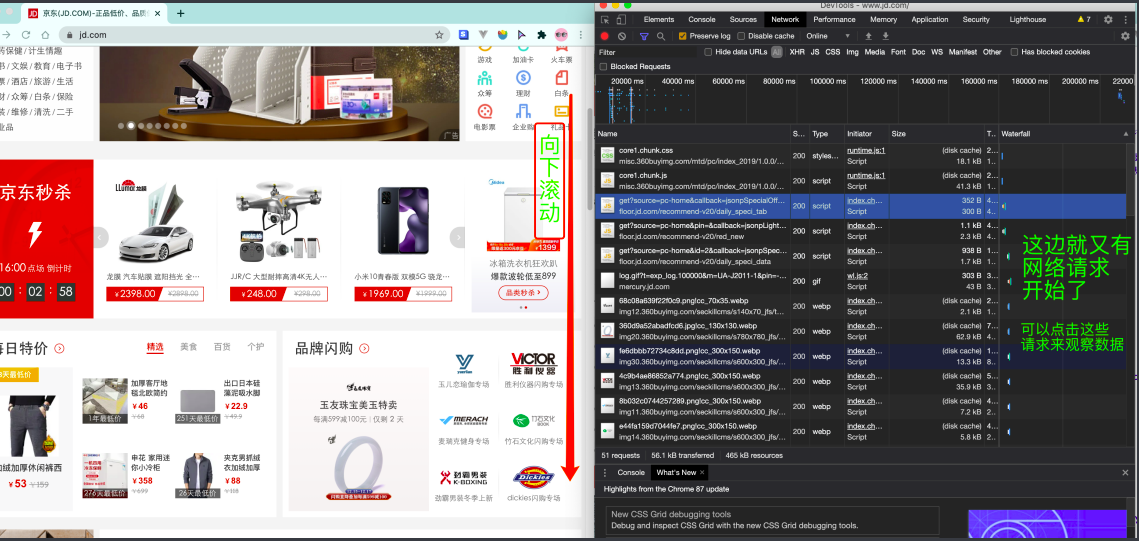
看到了吧,页面上看到的内容其实是后加载进来的。
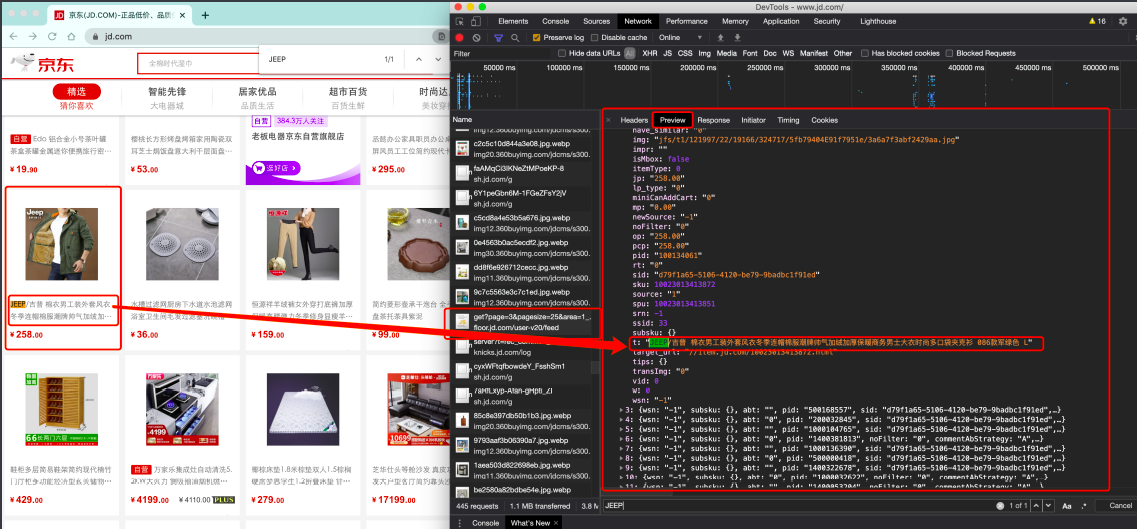
有些时候,我们的数据不一定都是直接来源于页面源代码,如果你在页面源代码中找不到你要的数据时, 那很可能数据是存放在另一个请求里。
反爬虫的一般手段
爬虫项目最复杂的不是页面信息的提取,反而是爬虫与反爬虫、反反爬虫的博弈过程
-
User-Agent
浏览器的标志信息,会通过请求头传递给服务器,用以说明访问数据的浏览器信息
反爬虫:先检查是否有UA,或者UA是否合法
-
代理IP
-
验证码访问
-
动态加载网页
-
数据加密
-
...
常见HTTP状态码
-
200:这个是最常见的http状态码,表示服务器已经成功接受请求,并将返回客户端所请
-
100-199 用于指定客户端应相应的某些动作。
-
200-299 用于表示请求成功。
-
300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
-
400-499 用于指出客户端的错误。
-
404:请求失败,客户端请求的资源没有找到或者是不存在
-
-
500-599 服务器遇到未知的错误,导致无法完成客户端当前的请求(500错误一般都无能为力)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号